ATOM User & Admin Guide
version 11.8
Table of Contents
Configuration Change Management – Create/Update/Delete32
Configure Policy50
Configure Rules51
Scenario 2: NTP Server configuration check59
Scenario 3: Interface configuration check64
Scenario 4: Enforce VTY Session Timeouts68
Scenario 5: Enforce OSPF Router Id as Loopback072
Scenario 6: BGP TTL Hop-count80
Policy creation with Xpath Expressions85
Scenario 8: IP Name-server check88
Scenario 9 : NTP server Check89
Scenario 10 : Interface Check with rule_variable91
Scenario 11 : VRF Check with rule_variable94
How to derive the X-path expressions97
Policy creation with XML Template Payload97
Scenario 12 : IP Domain name check98
Scenario 13 : IP Name Server check100
Scenario 14 : Interface check103
Scenario 15 : VRF check105
How to derive the XML Template payload109
Configure Telemetry Collection160
Create an Advanced Custom Chart176
Alert, Actions & Closed Loop Automation183
Software Image Management202
Image Upgrade Workflow
Image Repository
Software Version Compliance
Network Workflow & Low Code Automation206
Transactional control at the Service level220
Configuration Drift (Network Services)226
Resolving Service Violations231
ATOM in Multi-Tenant or Shared Mode242
Primary container load limit248
Concept Of Visibility And Usability275
Onboarding Tenants through Keycloak scripts279
Creating Authentication Mode Priority288
Workflow-User-Level-Authorization302
Integrating ATOM with Central Authentication Systems317
Managing Active Directory Users()317
Customizing the Dashboard using DSL323
Getting Started with ATOM
Intended Audience
This document is intended for Network Administrators & Operators that are using ATOM to perform Network management, configuration management, services automation and MOPs.
References
- ATOM Deployment Guide – All aspects of ATOM Deployment including sizing and deployment process
- ATOM User Guide – Master [This Document]
- ATOM User Guide – Remote Agent Deployment Guide
- ATOM User Guide – Performance Management & Alerting
- ATOM User Guide – Network Configuration Compliance, Reporting & Remediation
- ATOM API Guide – Discusses all external interfaces and integration flows
- ATOM Platform Guide – Discusses Service model, Device model and Workflow development
ATOM Solution Overview
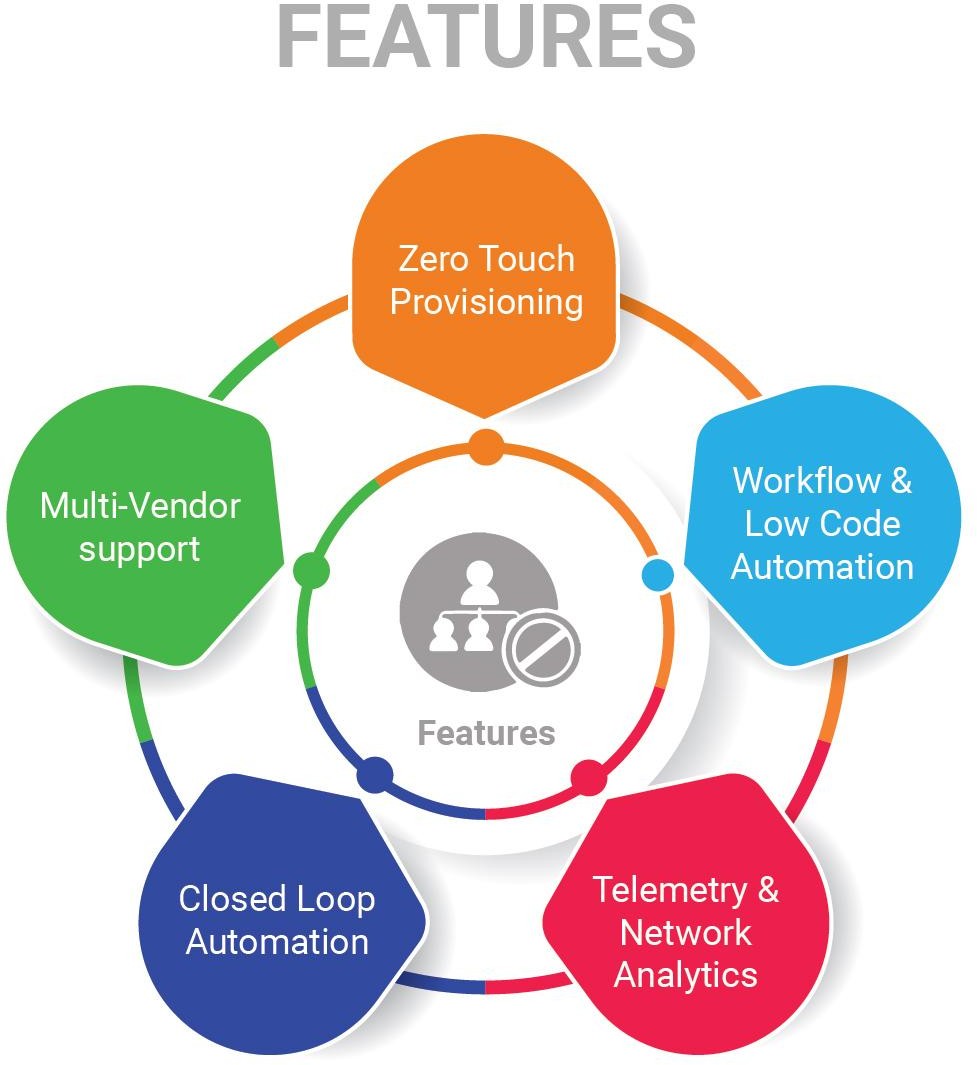
Following sections provide a brief overview of ATOM Features.
Configuration Management
ATOM provides Configuration management capabilities for a wide variety of devices. This includes configuration archival, scheduling, trigger driven configuration sync, configuration diff etc.,
Topology
ATOM provides topology discovery through CDP & LLDP. Topology can be displayed hierarchically using Resource Pools (Device Groups). Topology overlays Alarms and Performance information.
Collection & Reporting
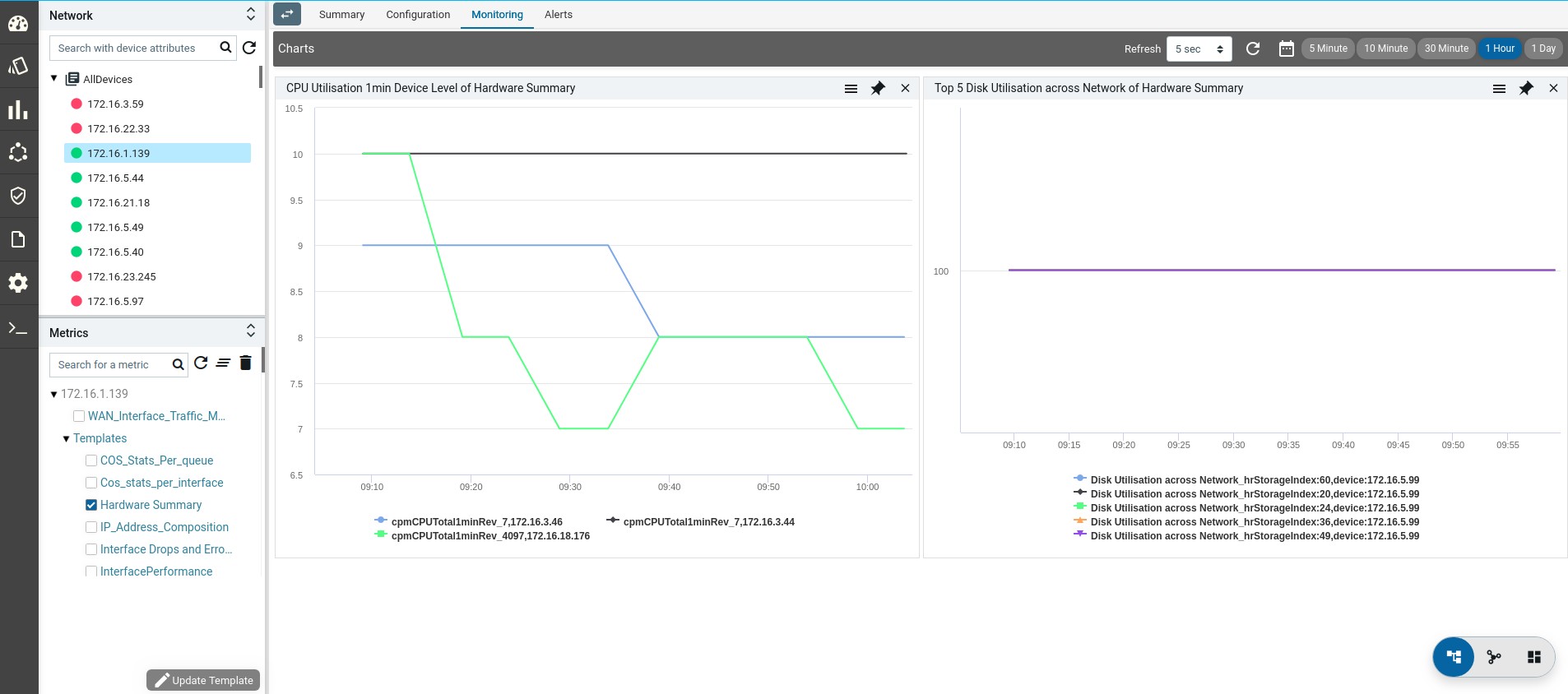
ATOM supports collection of network operational and performance data through various protocols like SNMP, SNMP Trap, Syslog & Telemetry. Such information can be visualized in ATOM as reports or can be rendered on Grafana as Charts. Admin guide discusses Report customization in further detail.
Network Automation
ATOM provides Model driven Network automation for stateful services. Stateful services involve a Service model (YANG) and some business logic. Service model development is covered in ATOM Platform guide. Admin guide discusses how to deploy & operate a service.
Workflow & Low Code Automation
ATOM provides an intuitive graphical designer to design, deploy and execute simple or complicated network operations and procedures. It allows the administrator to configure pre-checks, post-checks and approval flow. Workflow creation flows will be covered in the ATOM Platform Guide. Admin guide discusses how to deploy & operate.
Telemetry & Network Analytics
In today’s economy, data is the new oil. Anuta’s ATOM helps organizations collect a massive amount of network data from thousands of devices and generate detailed in-depth insights that will help them deliver innovative applications and solutions to their customers. ATOM can collect network data from a variety of sources including model-driven telemetry, SNMP and Syslog. The diverse data format of each source is normalized to provide a single consistent view to the administrator. Grafana is packaged as part of ATOM to view historical data, observe patterns and predict future trends. Organizations can integrate their Big Data and AI platform with ATOM to generate business insights from the network element configuration and operational state.
Procedure to Create Native Telemetry Collection
- Create a new Telemetry Collection
- Provide the name of collection
- Choose Junos as platform
- Select the transport as UDP which we will auto select the encoding as compact GPB with Dial Out Mode
- To configure resource filtering on device, select the filtering tab and choose the sensor name in dropdown & add regex pattern to configure
- Select ALL option, if we have same resource filter across sensors
- Once the telemetry collection is provisioned, users can’t edit the entry.
- Subscription is not required in this case.
Closed Loop Automation
Anuta ATOM allows administrators to define a baseline behavior of their network and remediation actions to be initiated on any violation of this behavior. ATOM collects a large amount of network data from multi-vendor infrastructure using Google Protobufs and stores it in a time series database. ATOM correlation engine constantly monitors and compares the collected data with the baseline behavior to detect any deviations. On any violation, the pre-defined remediation action is triggered thereby always maintaining network consistency.
The solution simplifies troubleshooting by providing the context of the entire network. Customers can define KPI metrics and corrective actions to automate SLA compliance.
Multi-Vendor support
Anuta ATOM has the most comprehensive vendor support. It supports thousands of devices spanning across 45+ vendors and automates all the use-cases including Data Center Automation, InterCloud,
Micro-Segmentation, Security as a Service, LBaaS, Campus/Access, Branch/WAN, IP/MPLS Edge, Virtual CPE, and NFV.
General Concepts
RBAC
Various ATOM Features and Levels of Access (Read, Create, Delete) are customized through RBAC. This is described in further Detail in User Management.
In case you are not able to access certain Feature or Policy / Data please contact your System Administrator.
Model Driven User Interface
Various ATOM Features are Model Driven or Driven by the Dynamic Pluggable Artifacts. Some of the following fall into this category:
- Device Packages
- Service Packages
- Workflow
- Reports
In case you do not find certain functionality expected in ATOM, please contact support@anutanetworks.com or your System Administrator.
Multi Tenancy
ATOM supports Multi-Tenancy across organizations and Sub-Tenancy within an Organization. This allows to vertically slice Any Data / Policies as per the business requirements of the Customer. Multi-Tenancy including Sharing, Wild Card usage to share across multiple
Sub-tenants, Users within a Sub-Tenant and more details are discussed in ATOM Multi Tenancy & Sub-Tenancy
In case you are not able to access certain Feature or Policy / Data please contact your System Administrator.
Viewing the Dashboard
Dashboard provides a simple, integrated, comprehensive view of the data associated with the resources managed by ATOM. Information about the devices, services, service approvals are available “at-a-glance” for the administrator.
Starting from the 7.x release, Dashboard, the landing page of ATOM, is organized into dashlets. A dashlet is an individual component that can be added to or removed from a dashboard. Each dashlet is a reusable unit of functionality, providing a summary of the feature or the function supported by ATOM and is rendered as a result of the custom queries written in DSL.
You can customize the look of the Dashboard, by adding the dashlets of your choice, and dragging and dropping (the extreme right corner of the dashlet) to the desired location on the dashboard.
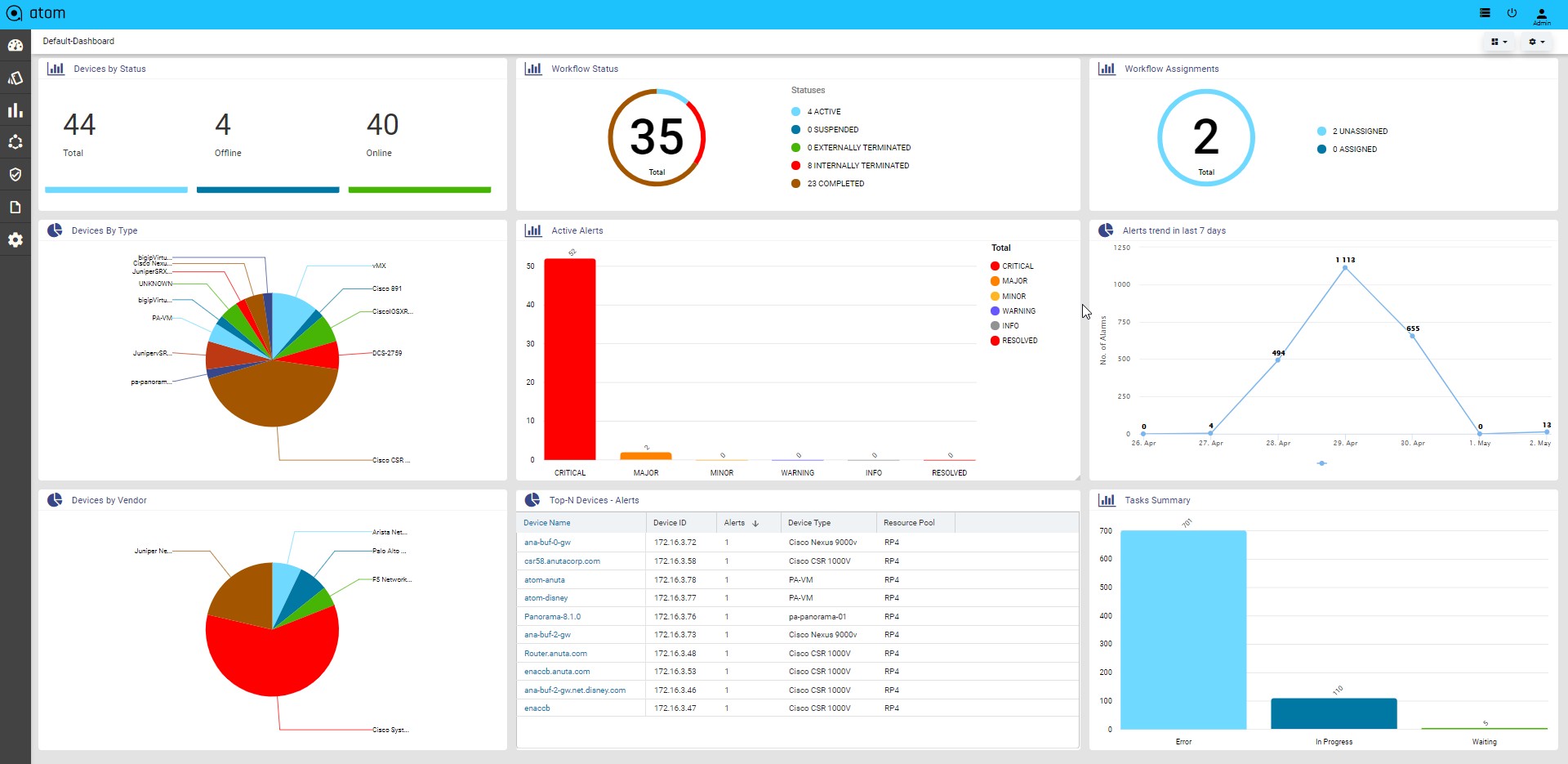
Each dashlet contains the summary or the overview of the feature or the functionality supported by ATOM.
For example, the dashlet “Device” displays the summary of devices managed by ATOM. Some of the statistics that can be of interest in this dashlet could be as follows:
- Total number of devices
- Number of online devices
- Number of offline devices
These statistics can be gathered by ATOM and displayed in the corresponding dashlet depending on the DSL query written for each of them. You can save the layout containing the dashlets of your choice and set in a particular order.
Resource Management
ATOM Resource management involves device credential management, device onboarding through discovery or manual import, configuration archival, topology discovery & visualization, resource pools (device grouping), IP Address Management etc.,
Following table provides a quick summary of the activities that can be Resource Management activities.
| Credential Sets, Credential Maps and Devices | Resource Manager > Devices |
| Device Discovery | Resource Manager > Devices > Discovery |
| Visualize Topology | Resource Manager > Network > Topology |
| Create & Visualize Logical & Hierarchical Network Device Groups/Resource Pools | Resource Manager > Network > Resource Pools |
| Create physical locations | Resource Manager > Locations |
Device Management
Device Management involves onboarding of devices and working with Device inventory, Configuration, Monitoring & Alerts. Devices can be added Manually, through an API or Automated Discovery using CDP/LLDP.
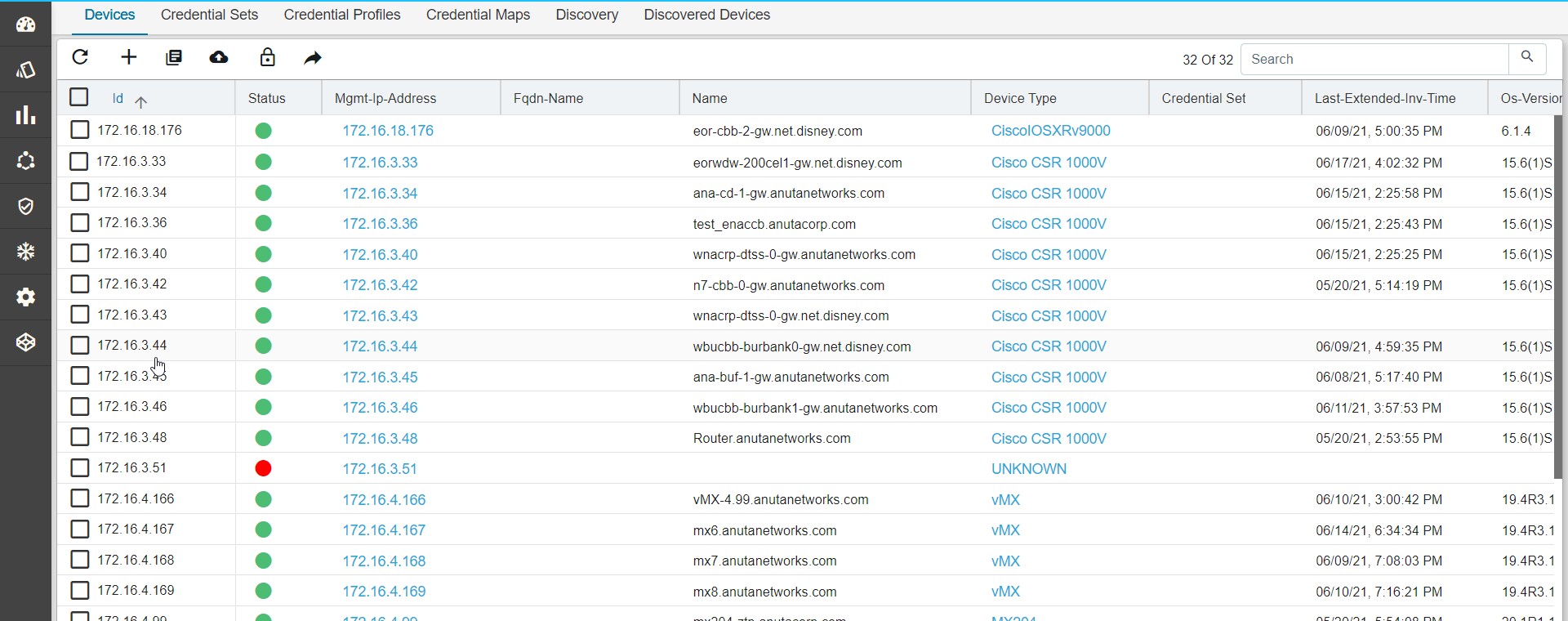
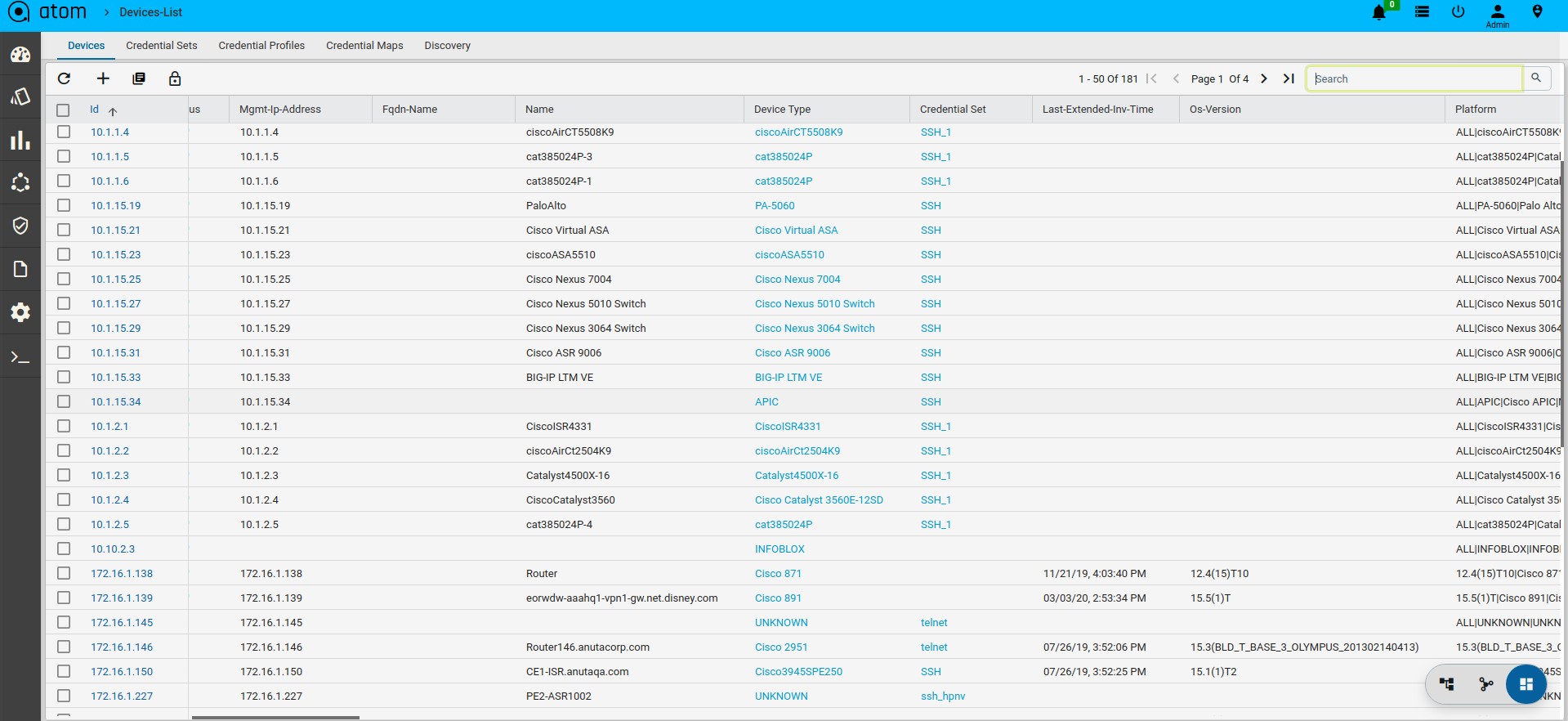
All Device Mgmt activities can be performed from Device Explorer & Grid View. Following are the three main views for a Device.
- Grid View – Grid layout of all Devices & and action on a device(s)
- Tree View – Device Group based tree view of devices that provides a much easier way to toggle between devices and inspect various device characteristics.
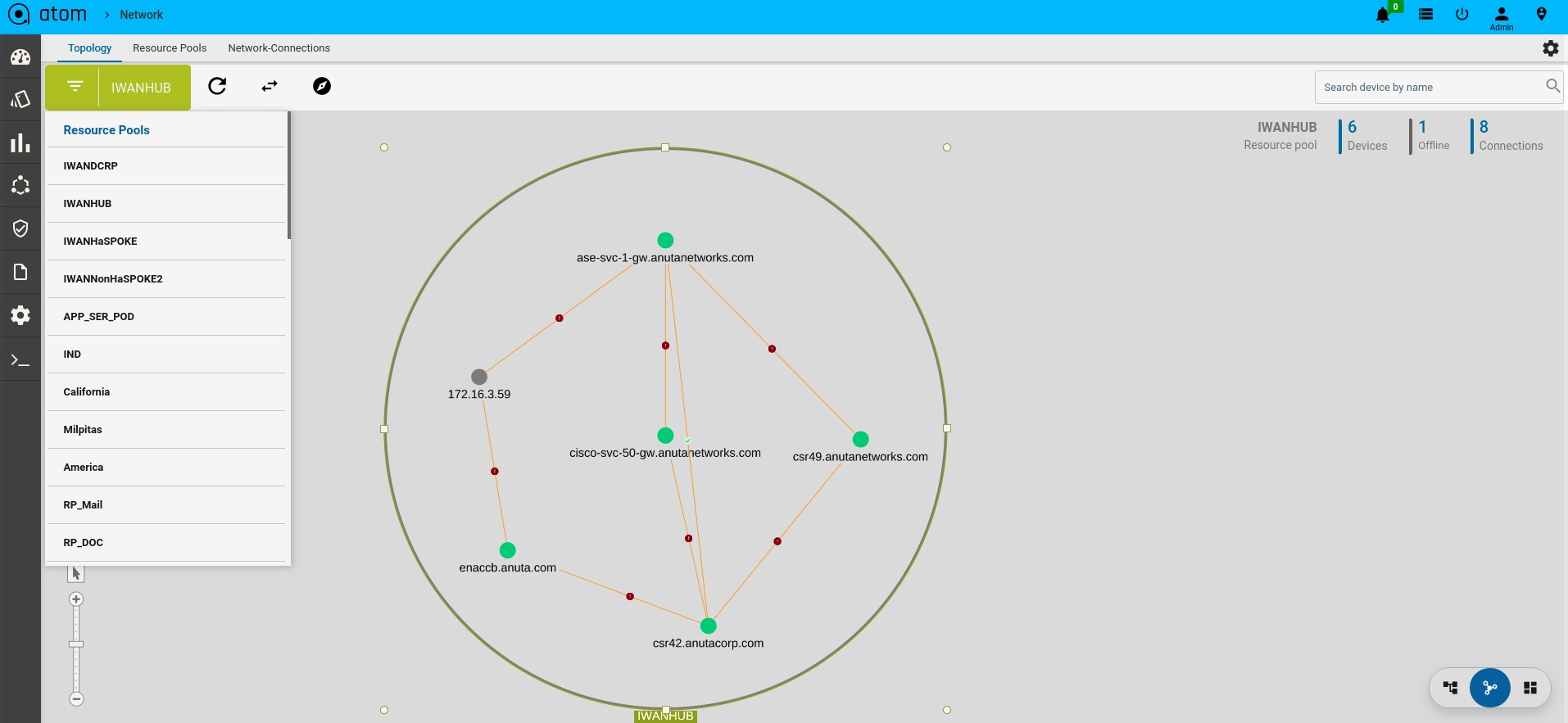
- Topology View – Devices can be visualized in a Topology view
- Device Detail View – On Clicking a Device from Tree View or Grid View a detailed view of the device is presented. This is same as the view when a device is selected from the Tree view
Grid, Tree view & Topology Views can be toggled using the view selector button available at the bottom right hand side corner of the page.
Credential Management
ATOM provides multiple functions like Provisioning, Inventory Collection etc. Function like Provisioning can be various ways – Payload (CLI vs YANG or Other) over a Given Transport (SSH, Telnet, HTTP(S), etc.,). For example, based on the use case ATOM Workflow Engine can use various Payload + Transport mechanisms to perform Provisioning actions. ATOM helps accomplish this using:
- Credential Sets – Define the Transport/Connectivity & Authentication to the devices
- Credential Profile – Maps Credential Sets to various functions in ATOM This addresses various scenarios, some as follows:
- Reuse of same SNMP Credentials across the entire Network, while retaining Device/Vendor Specific Transport for Provisioning.
- Inventory Collection Via SNMP for a Given Vendor/Device vs Telemetry for another
Credential Sets
Following section provides guidance on how to configure device credentials in ATOM.
- Navigate to Resource Manager > Devices > Grid View(Icon) > Credential Sets
- Create/Edit a Credential Set
- Name: Enter a string that will be used to identify the Credential Set
- Description: Enter a description w.r.t the created Credential Set(Optional)
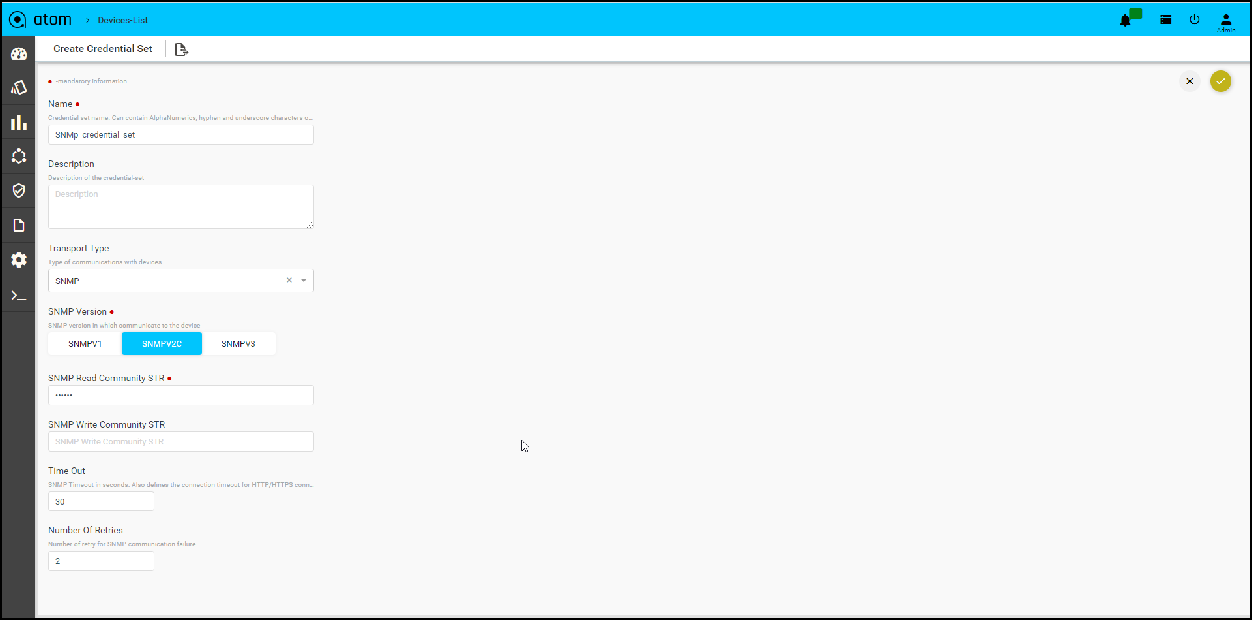
SNMP Transport credentials:
Select Transport type as “SNMP” can view below option
-
- SNMP version: Select the version of SNMP that should be used for device communication
- SNMP Read Community String: Enter the string that is used by the device to authenticate ATOM before it can retrieve the configuration from the device
- SNMP Write Community String: Enter the string that is used by the device to authenticate ATOM while writing configuration to the device
- Timeout: Enter the time taken for the response from the device in seconds.
- Number Of Retries: Enter the number of times the SNMP request is sent when a timeout occurs.
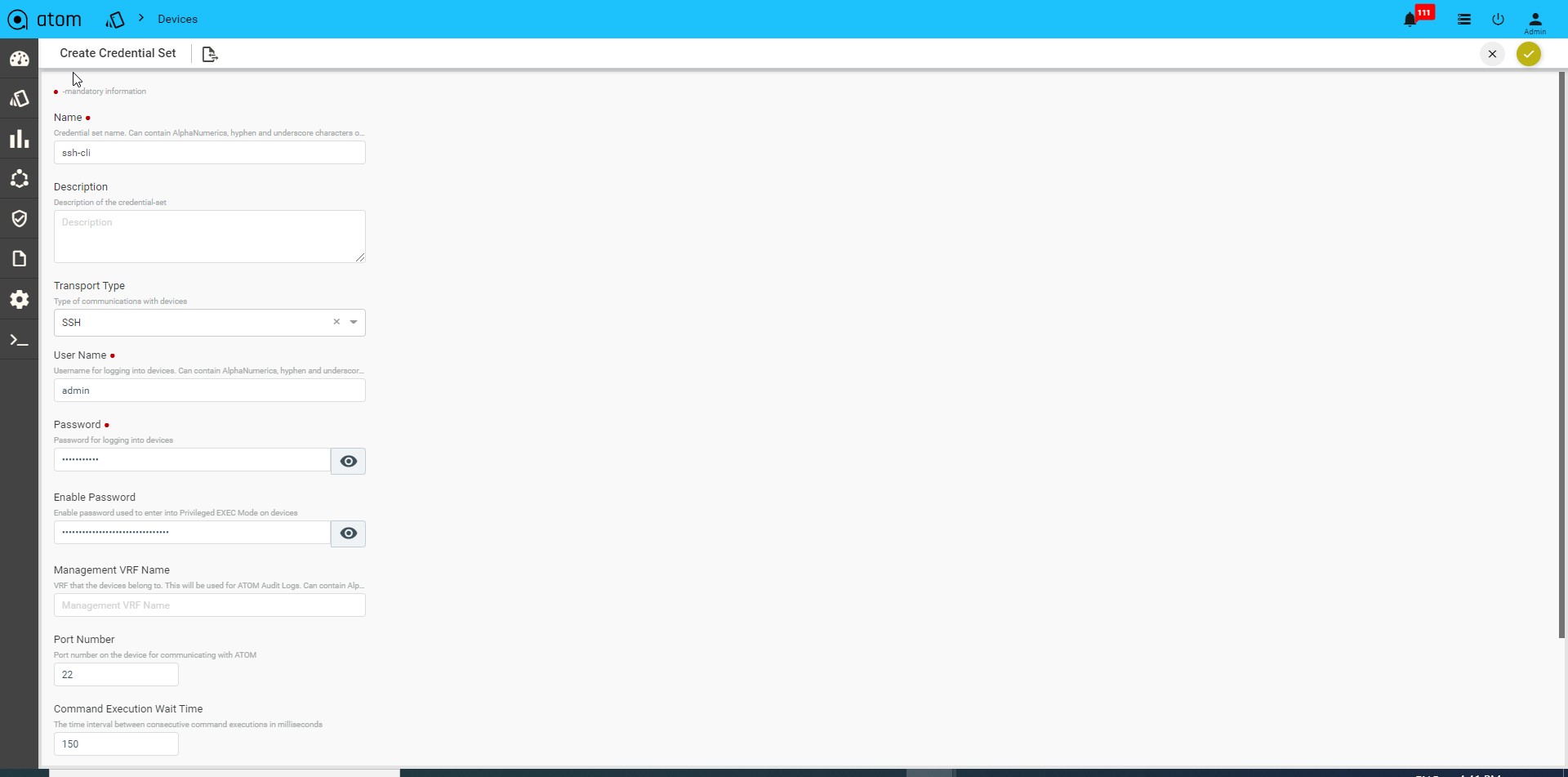
CLI Device(SSH/TELNET) Transport Credentials: Select Transport type as “SSH/TELNET”
-
- User name: Enter a string that should be used to login to the device
- Password: Enter a string that used be a password for logging into the device
- Enable Password: Enter a password to enter into the privilege exec mode of the device.
- Mgmt-VRF-Name: Enter the name of the management VRF configured on the device. This will be used by ATOM to retrieve the audit logs from the device.
-
- Port Number: Enter the number of the port on the device that should be used for communication with ATOM
- Command Execution Wait Time: Enter the number (in millisecs) that ATOM should wait for the consecutive commands to be executed on the device. Enter any number between 10 to 30000.
- CLI Configure Command TimeOut: Enter the time (in seconds) that ATOM should wait for the command line prompt on the device to appear. Enter any between 1 to 1200.
- Max Connections: Enter the number of max connections that can be opened for a given device at any time.
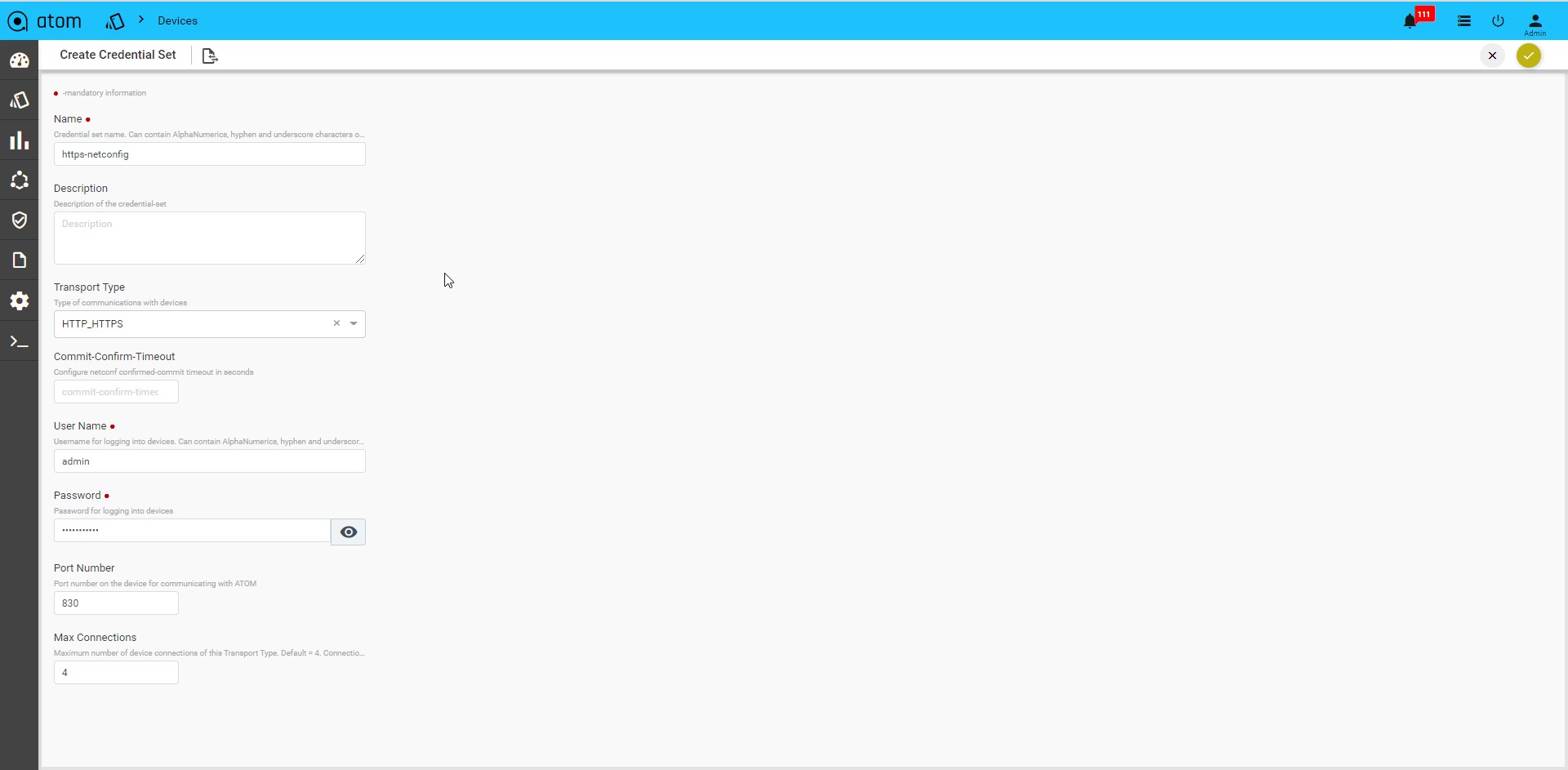
API Device Transport Credential:
Select Transport type as “HTTP_HTTPS / GRPC”
-
- User name: Enter a string that should be used to login to the device
- Password: Enter a string that used be a password for logging into the device
- Port Number: Enter the number of the port on the device that should be used for communication with ATOM.
- Max Connections: Enter the number of max connections that can be opened for a given device at any time.
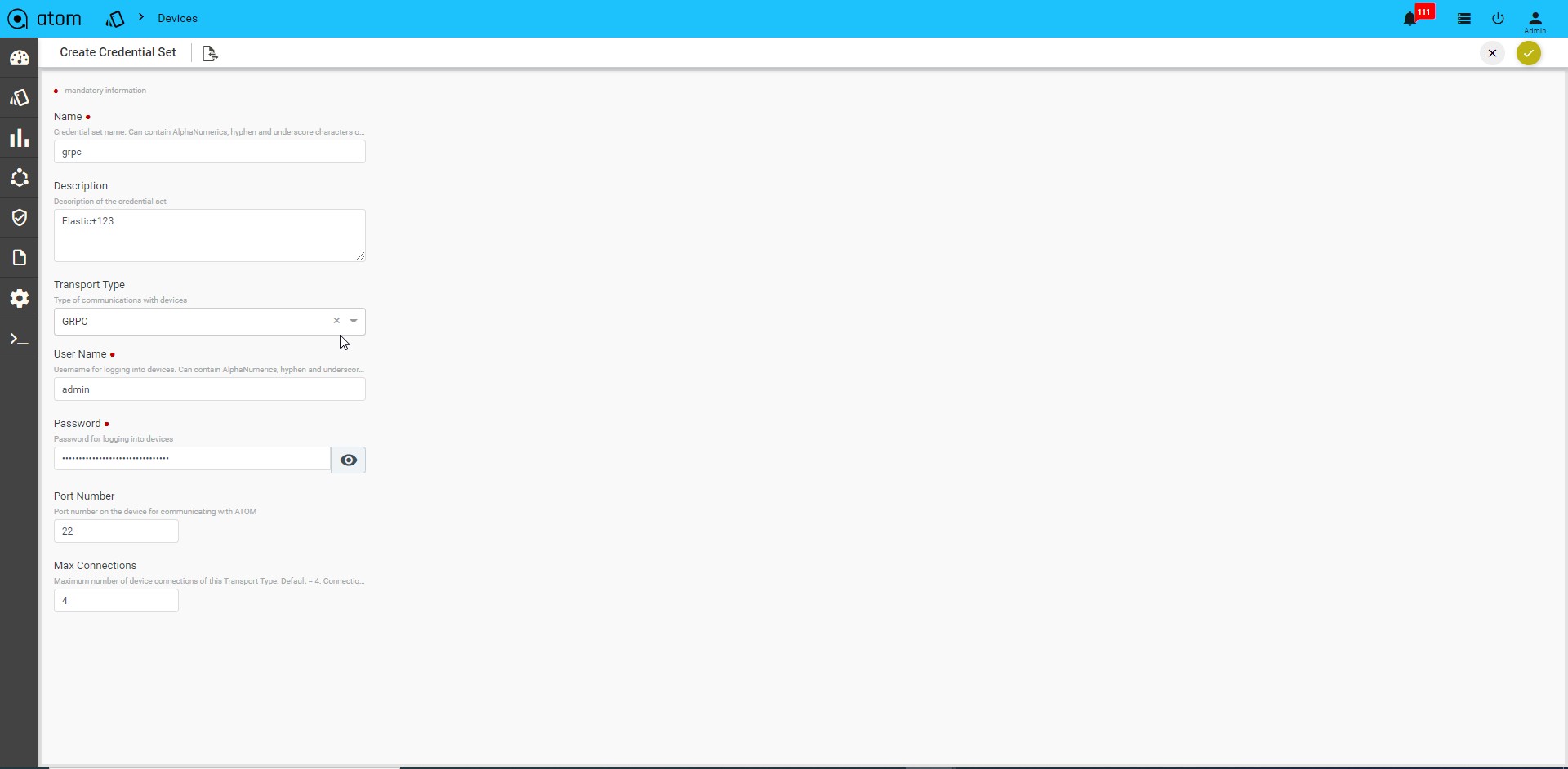
GRPC Transport credential:
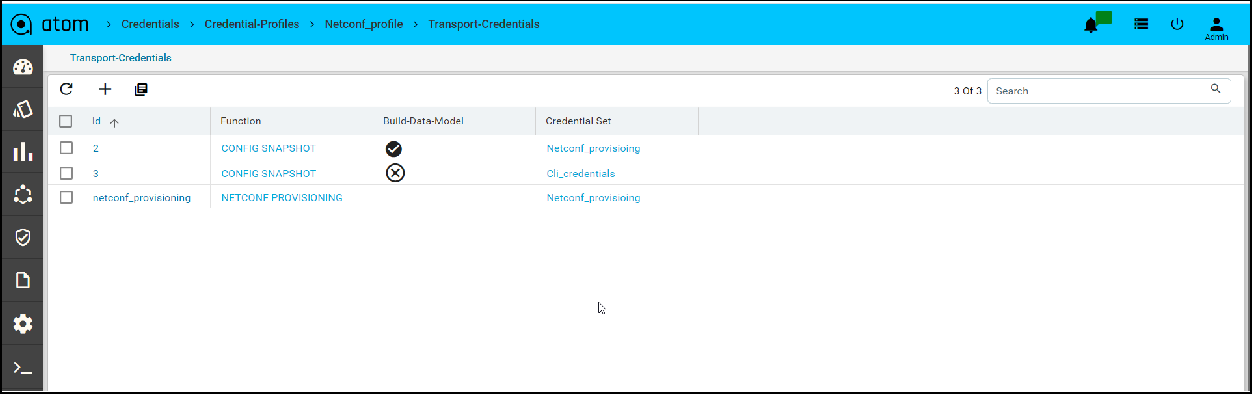
Credential Profile
By default, ATOM has the following out of the box functions:
- Config Provisioning
- SNMP
- Telemetry
- HTTP provisioning
- NETCONF provisioning
Navigate to Resource Manager > Devices > Grid View(Icon) > Credential Profile
- Here, provide the name of credential profile, description and add the transport credentials by choosing the appropriate functions.
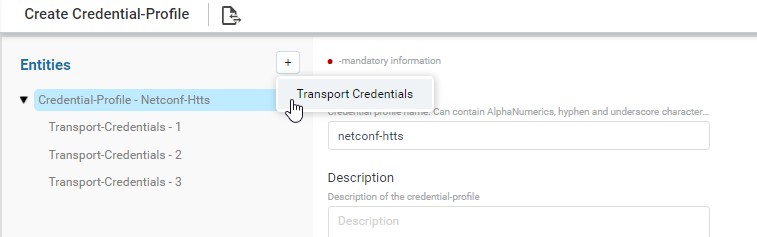
- Below is the snapshot to attach the credential set with function.

Credential profile payload in XML:
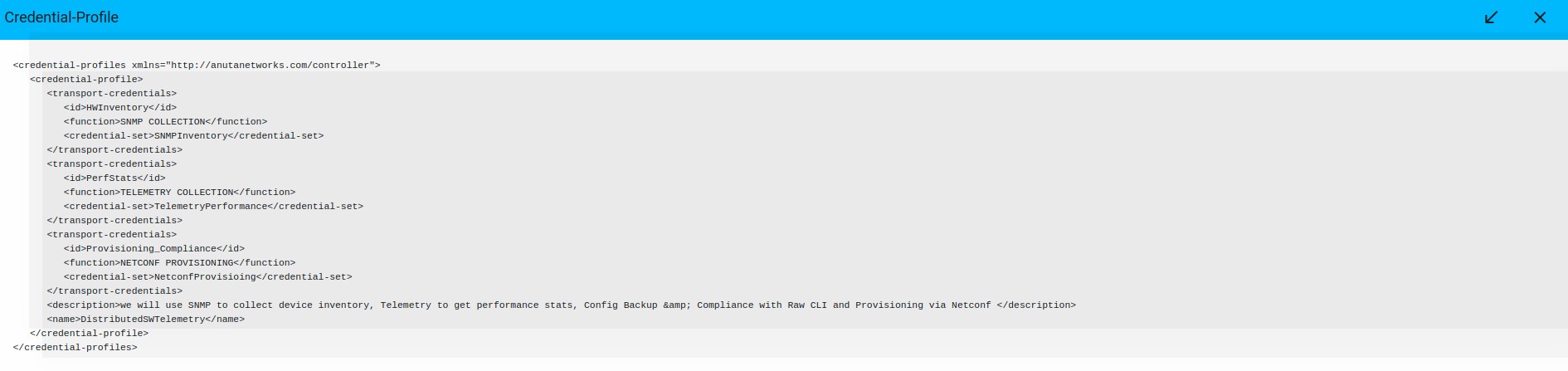
Credential Maps
Credential Map allows users to map multiple Credentials Profiles to an IP-Address range. This addresses the following use cases:
- Device Discovery – When ATOM needs to Perform Discovery using SNMP Sweep or CDP/LLDP. Since devices are yet to be onboarded, explicit assignment is not available.
- Credential profile is mandatory when onboarding a device.
When ATOM needs credentials for a device and explicit Device to Credential Profile is not available, ATOM will cycle through the IP Address range and use the first credential profile that works. The successful Credential Profile is mapped to the device. This process is repeated
whenever ATOM is unsuccessful communicating with the device using the current assigned credential profile.
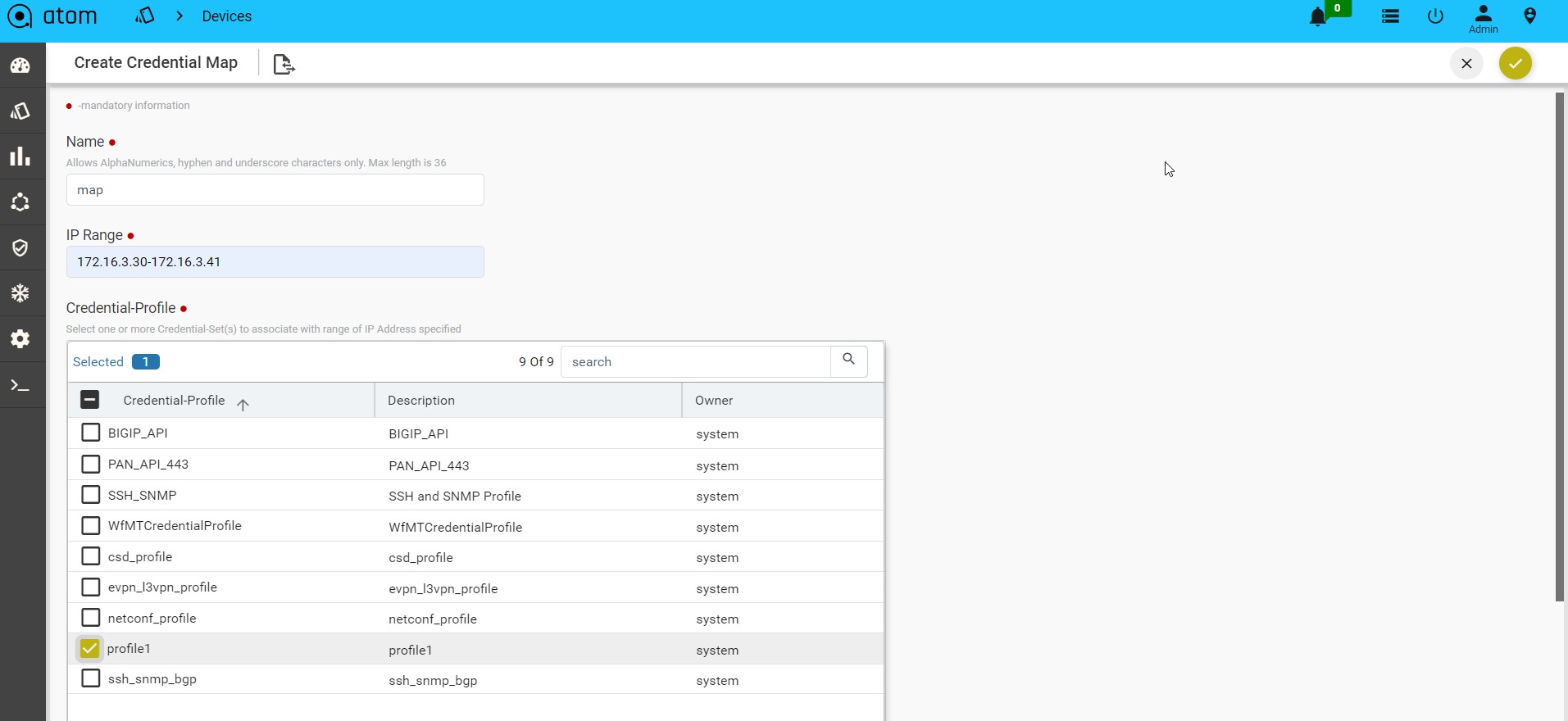
To create a Credential Map:
- Navigate to Resource Manager > Devices > Grid View(Icon) > Credential Maps
- Create/Edit Create Credential Map:
- Name: Enter a name for the Credential Map
- Start-IP-address: Enter an IP address in the range from which ATOM starts the sweep for locating the devices.
- End-IP-address: Enter an IP address in the range beyond which ATOM will not continue the sweep for locating the devices.
-
- Credential Profile: Select one or more Credential Profiles shown.
Device Onboarding
Devices can be onboarded into ATOM using an API, Manually through User Interface of Discovery using CDP/LLDP.
Discovering Devices:
Devices discovery is covered in section – Device Discovery Adding Device Manually:
We may have scenarios where device discovery is not viable. Some reasons below:
- Lack of support for Layer 2 discovery support on the device
- Operational/Administrative reason to not use LLDP/CDP
- SNMP Sweep discovery is not suitable – IP Address Range are not well defined, contiguous or some other reasons
Before you begin, it’s mandatory to define Credential Sets & Credential Profiles. To Add/Edit a Device:
- Navigate to Resource Manager > Devices (Grid View)
- Add – Select Add action
- IP address: Enter the IP address of the device
- Credential Profile: Select the Credential Profile of the device
- Driver name: Driver can be selected for API devices.
- Latitude & Longitude: is a measurement on a globe or map of location north or south of the Equator on devices
- Modify – Select Device & Select Edit action
- Delete – Select one/more device(s) and Select Delete Action
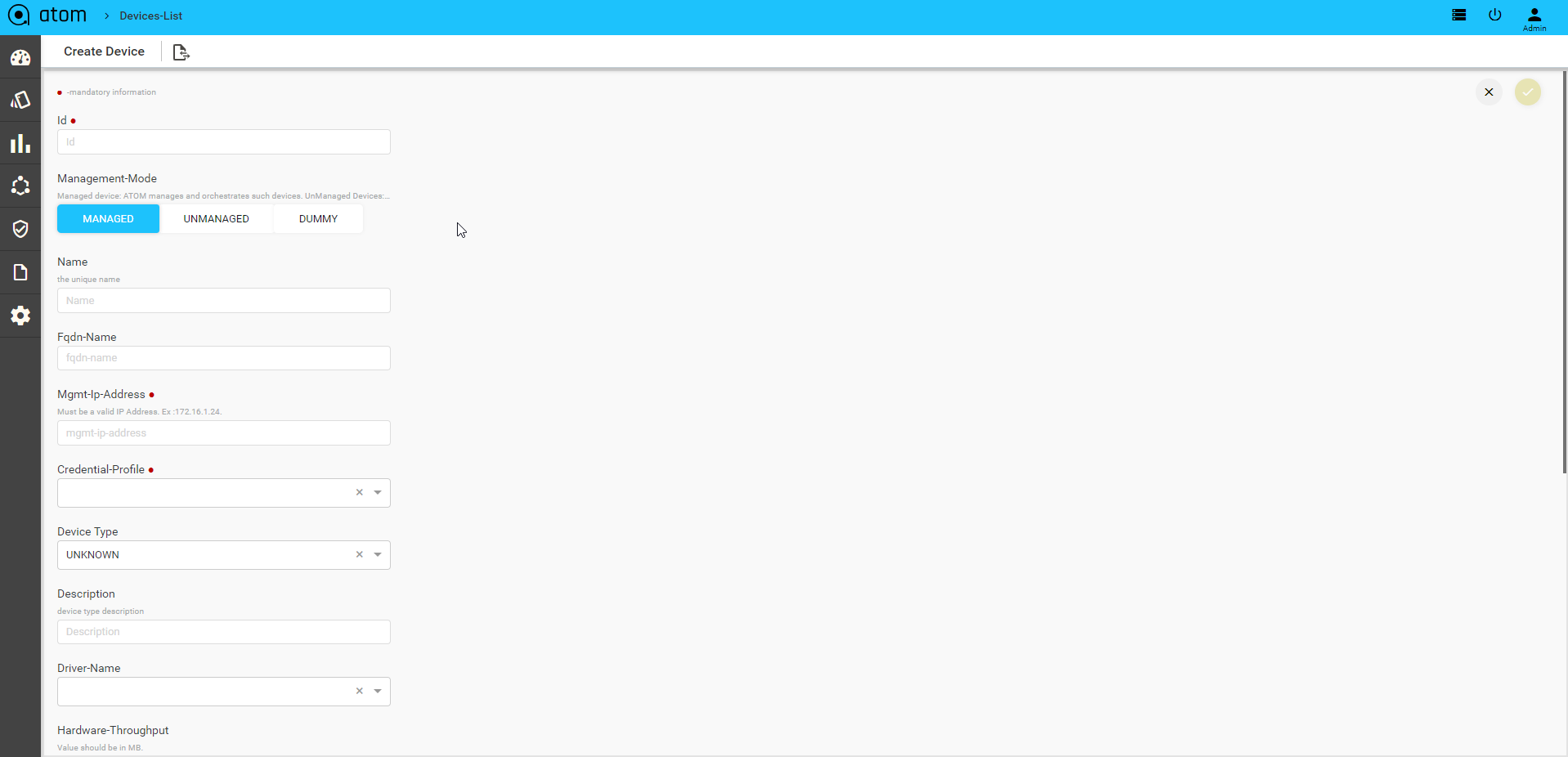
Upon device addition, ATOM will perform the following:
Added Devices are shown in Devices grid and Device status will be shown in Green if device is SNMP reachable and ATOM is able to work with the device successfully.
Device Views
ATOM has 3 views for the devices – Tree (Device Explorer), Topology and Grid.
- Tree View:
- Topology View
- Grid View:
Device Explorer
Device explorer view will provide the devices, its associated config and observability elements in logical hierarchy. This view contains the available device-groups and its associated devices . By default, all the devices are part of AllDevices Group.
Device group will have all the corresponding device details Each group and node will have the following sections:
- Summary : It provides the device platform, version, serial number, current operating OS, Device hardware health, Interface summary, Config compliance violations and Active alerts and recent activity.
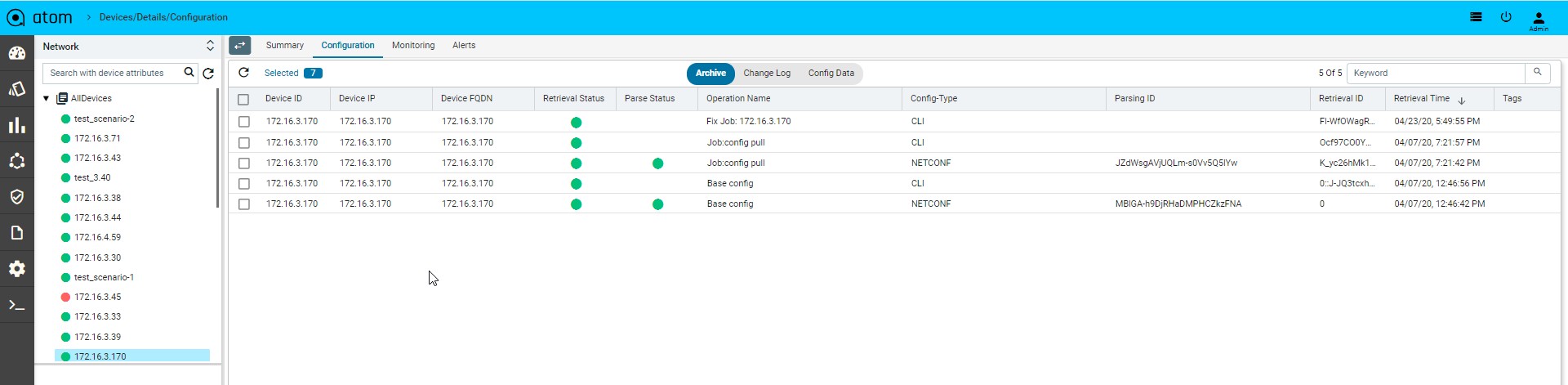
- Configuration : it provides the entire summary of config related operations.
- Config Archive : It shows the each config retrieval, type, retrieval & parsing status.
- Changelog : provides the summary of change in configuration such as number of lines added, deleted or modified and at what time & corresponding changes.
- Config Data : it will provide the entire config tree through YANG models parsing. This is not applicable for any device group as they can have heterogeneous models based on the grouping criteria & provisioning interface such as ATOM abstract device models, OC or Native models.
- Monitoring : It contains all possible templates & charts through inheritance from its group or node level. It will show the default template by default as its monitoring summary. Refer Monitoring Guide for more details.
- Alerts : It will show the all active alerts and its history by default. Alert filter view is also available to search & prioritise the alerts. Refer Alerting Guide for more details.
Each device-group view will have a Summary dashboard which can be customizable.
Device Actions
ATOM supports common actions on Device. These actions can be performed from Device Grid view on one or more devices or from within the Device specific view and will be discussed in Device Summary section.
Jobs & Subscriptions
Various Collection & Diagnostics jobs can be invoked.
- Navigate to Devices > select one or more devices
- Click on the Jobs and select the job to run
- Jobs action -> Run Device Inventory
- Jobs action -> Run Extended Inventory
- Jobs action -> Run Topology Inventory
- Jobs action -> Retrieve Configs
- Jobs action -> Run Diagnostics
- Jobs action -> Run Policy
- Jobs action -> Run Profile
- Click on the Subscriptions to configure Syslog Subscription on the Devices
- This will result in ATOM being configured as a Syslog receiver and is a configuration change on the device.
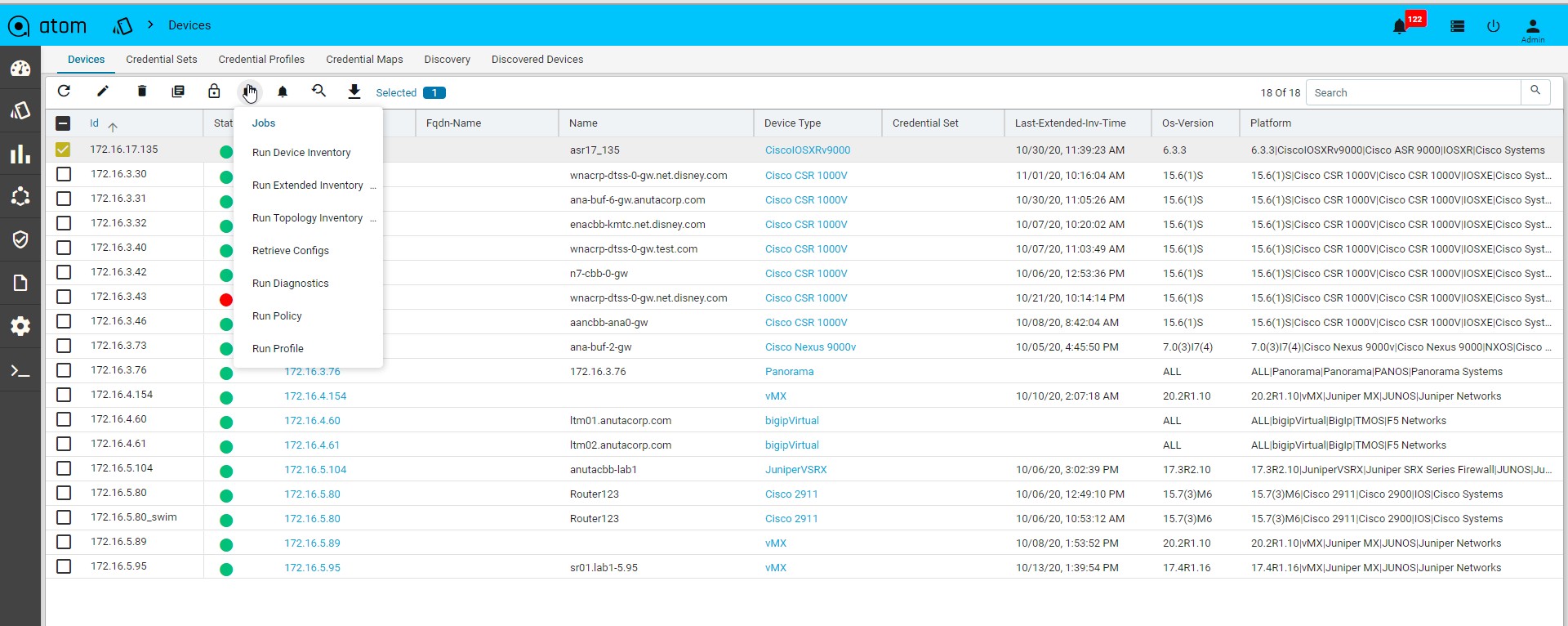
Exporting Device Information:
You can export the device information of the devices either in the XML or JSON format.
- Navigate to Resource Manager > Devices > Grid View(Icon) > Devices
- Select one or more devices
- Click the View/Download button and select either the XML or JSON
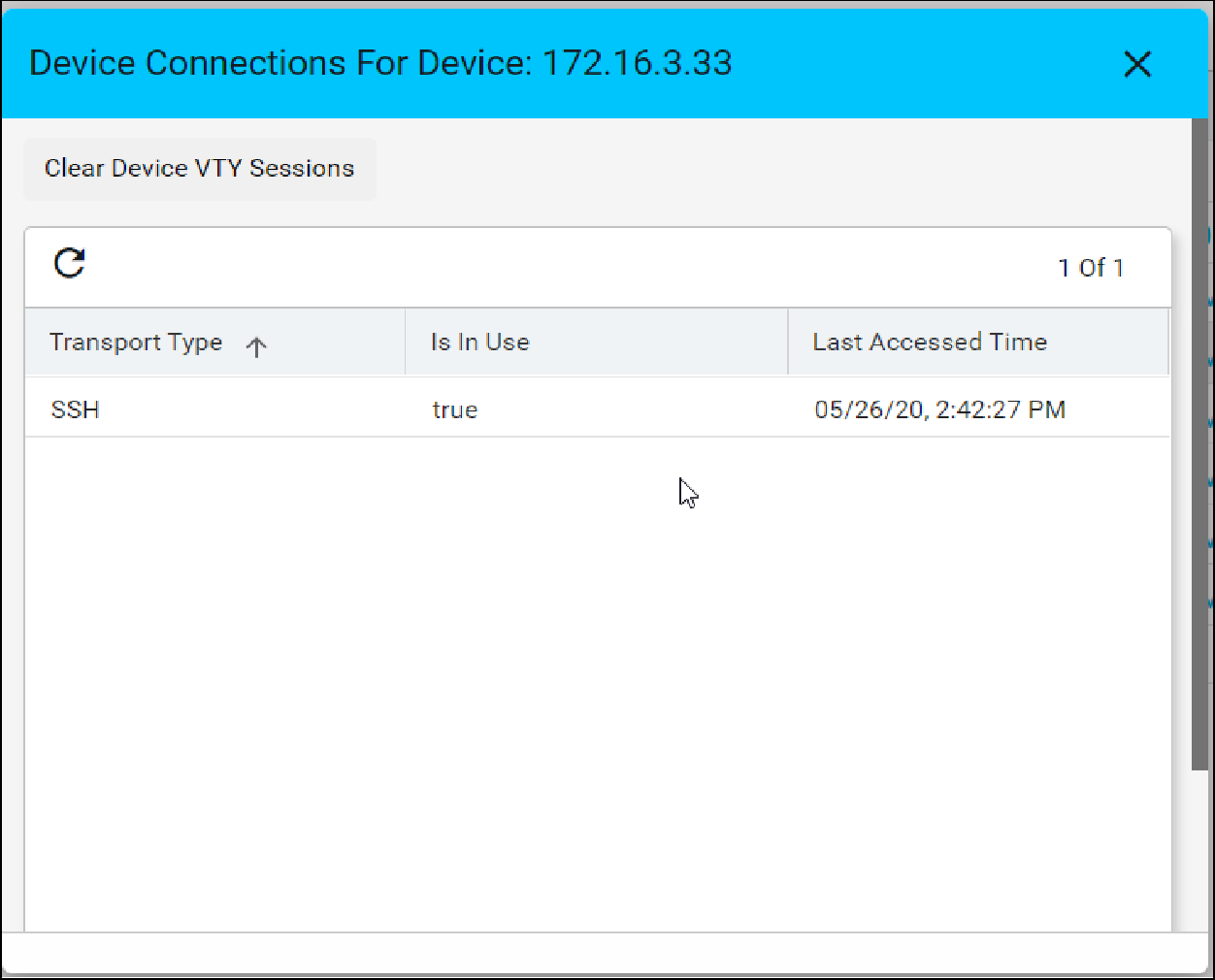
VTY Sessions
This is used to view the active vty sessions.
- Navigate to Resource Manager > Devices > Grid View(Icon) > Devices
- Select any device
- Click the VTY Sessions button
Default Jobs
Below are the jobs which run during the device onboarding process in the mentioned order.
-
- Device Inventory : It gathers the Platform, OS Version through SNMP and gets the Device to ONLINE. If the platform is not found in ATOM then check Platform guide on
- Device Extended Inventory : It collects the Serial Number, Interface performance, health, availability etc.,
- Device Diagnostics : ATOM will perform the reachability check through Ping, SNMP and Telnet/SSH if they are applicable.
- Base Config Pull or Config Retrieval : It will retrieve the configuration and persist in the database. Configuration will be collected if the credential function is set to Config SNAPSHOT or any of the PROVISIONING functions. Build data model flag is used to parse the configuration into YANG entities from the specified config source snapshot.
Below is the example, to backup cli and netconf xml config and parse the xml version.
Config Type column will show us the source of config retrieval.
All the above operations can be customized for any platform as required and scheduled similar to other collection jobs.
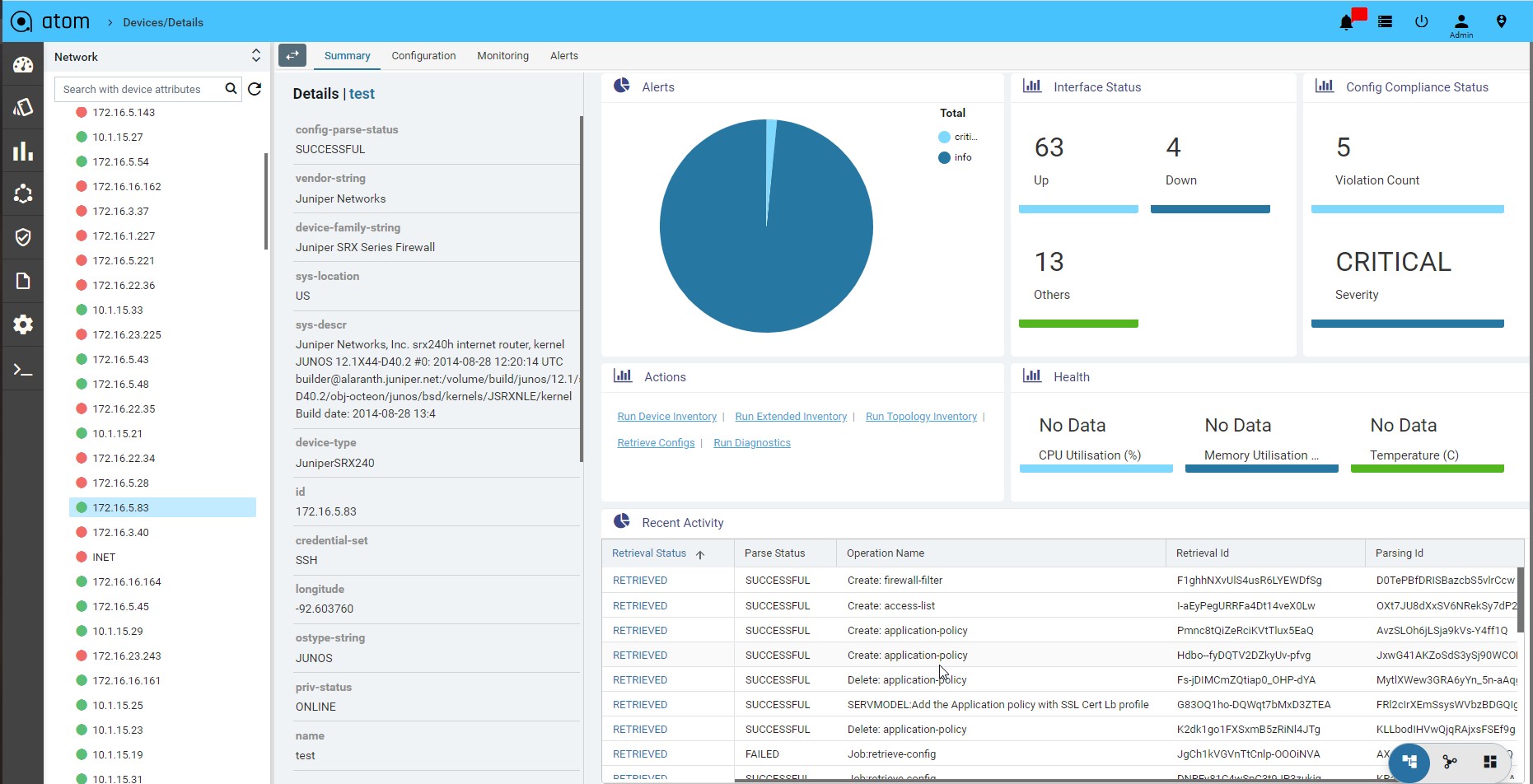
Device Summary
Device summary view provides a quick snapshot of important device attributes including Alarm summary, interface summary, recent configuration change history and health.
Device Summary also provides access to most popular device actions and quick links to frequently used activities.
- Navigate to Devices > select a device
- Click on the Device > Summary> to view the details associated with each attribute.
Configuration Management
Configuration Archive
ATOM Collects Network or Server Configuration through API, NETCONF or CLI over Telnet or SSH. ATOM Provides the following Configuration Management relations functions:
- Fetch, archive, and deploy device configurations
- Build Stateful Configuration Model for:
- Devices that support YANG Over NETCONF
- Devices where Device YANG Model is mapped to Concrete API or CLI
- Stateful Configuration – Support Create, Update, Delete
- Stateful Configuration – Configuration Drift & Transactions
- Compare Startup vs Running
- Compare Running vs Latest Archived
- Compare Two Versions of the Same Device
- Compare Two Versions of Different Devices
- Base Config vs Latest Version of Multiple Devices
- Search and generate reports on archived data
- Compare and label configurations, compare configurations with a baseline, and check for compliance.
- You can use the Baseline template to compare with other device configurations and generate a report that lists all the devices that are non-compliant with the Baseline template.
- You can easily deploy the Baseline template to the same category of devices in the network with dynamic inputs.
- You can import or export a Baseline template/Config archives.
- Set Up Event-Triggered Archiving
- Synchronize Running and Startup Device Configurations
- Deploy an External Configuration File to a Device
- Roll Back a Device’s Configuration To an Archived Version
ATOM Collects Device configuration periodically as configured in Jobs->Configuration or upon a config change event from the device. To trigger configuration collection through config change notification, ATOM should be configured to receive config change notification through SNMP Trap or Syslog.
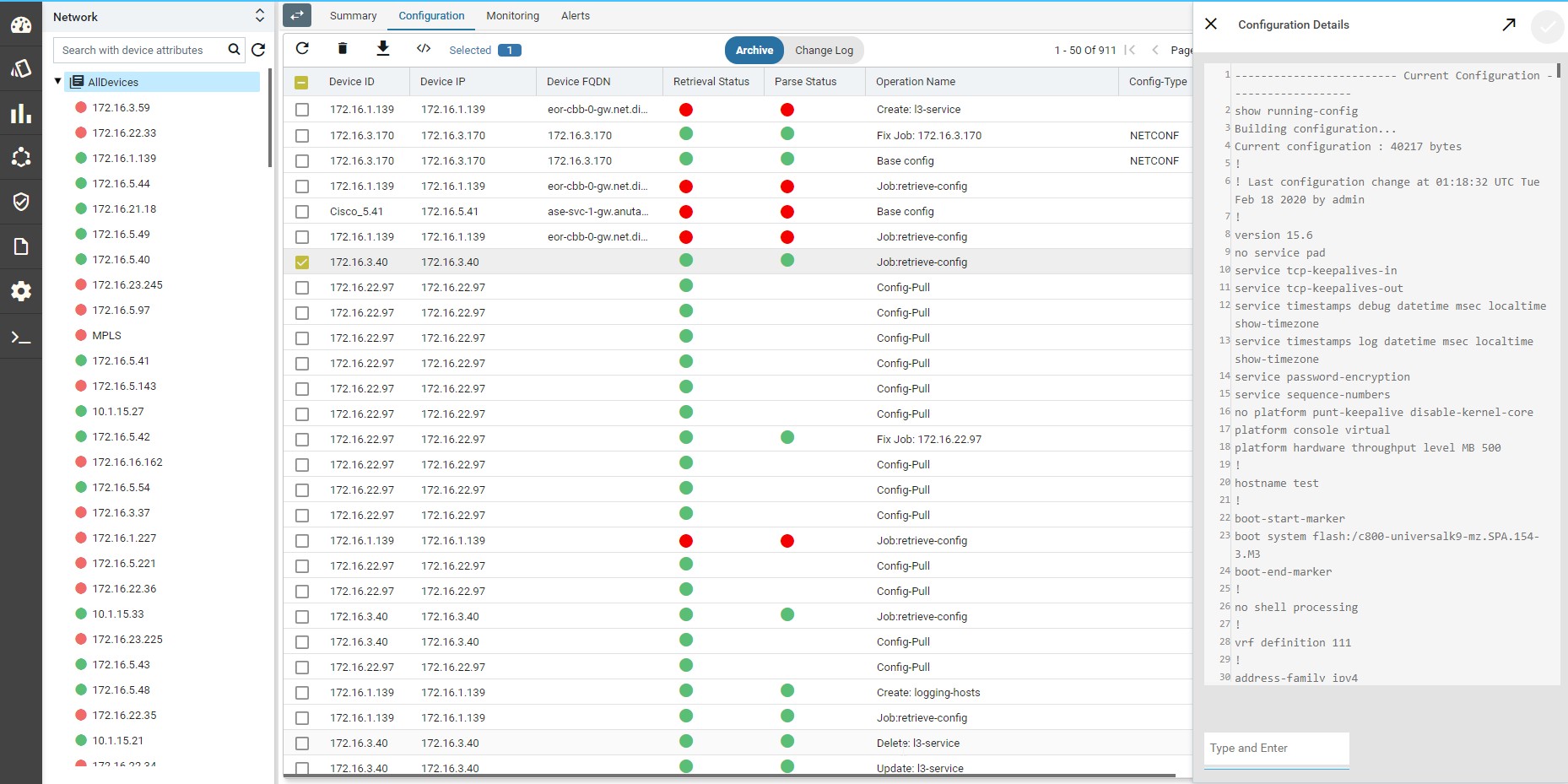
- To view Device(s) Configuration – Navigate to Devices > select a device(s)
- Click on the “Configuration > Archive” Tab
- Select an Entry in the Grid
- In Details view – CLI/XML Configuration is displayed
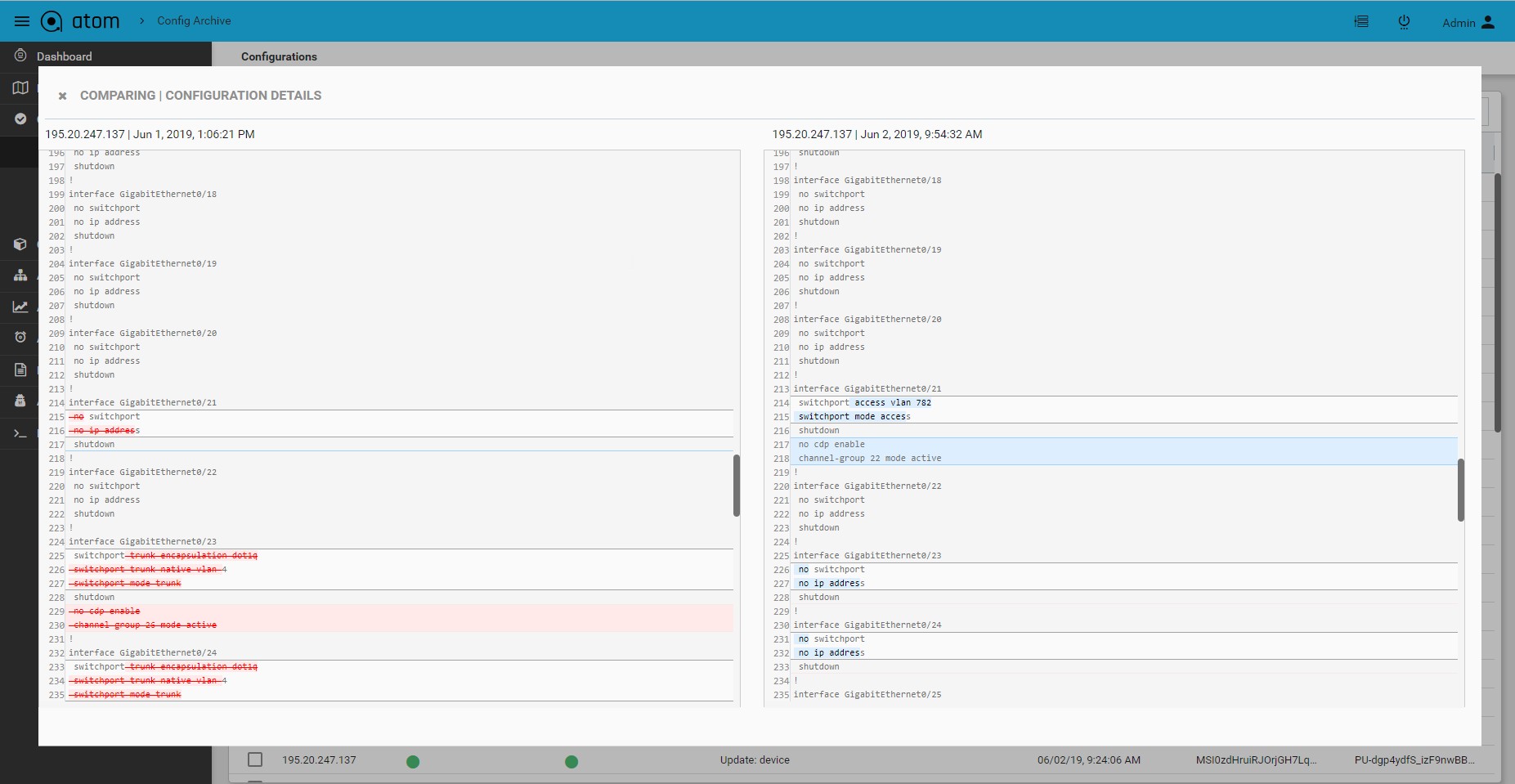
Configuration Diff:
Configuration differences across various revisions can be viewed by selecting two versions from the Configuration archive grid.
- To view Device(s) Configuration – Navigate to Devices > select a device(s)
- Click on the “Configuration > Archive” Tab
- Search configuration grid using tags or other attributes
- Select two configuration revisions
- Click on “Compare” to launch configuration diff view
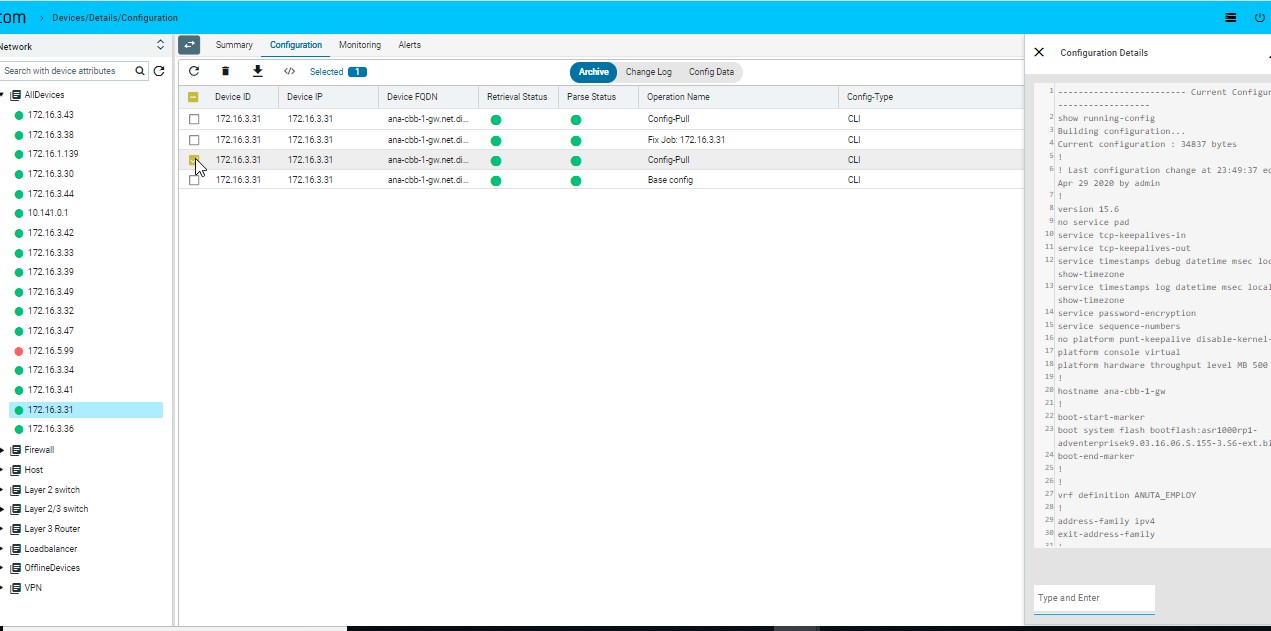
Configuration Tagging:
Configuration version can be tagged using user provided flags or tags. This can be used for filtering and comparison of configuration revisions.
- To view Device(s) Configuration – Navigate to Devices > select a device(s)
- Click on the “Configuration > Archive” Tab
- Select an entry from the configuration revision grid
- Click on “Update Tags”
- Enter one or more tags in the lower right of the configuration details view
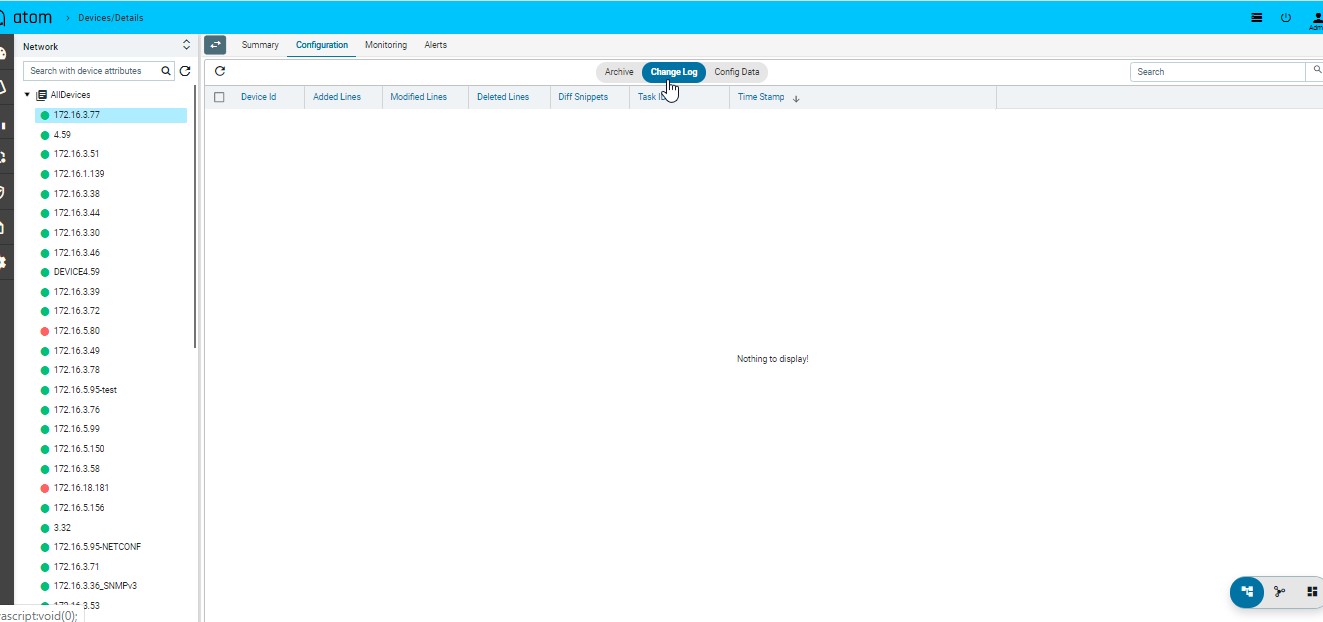
Configuration Change Log
Configuration archive provides full comparison of device configuration changes across revisions. ATOM provides another view to see only config modifications only.
This can be enabled from Admin Settings.
- Administrations > System> General settings> Admin settings
- Edit “Admin Settings”
- Set “generate-config-inventory-event” to true Config change history for devices can be tracked as follows:
- Navigate to Devices (Tree View) > select device(s)
- Click on the “Configuration” Tab
- Click on the “Change Log” Tab
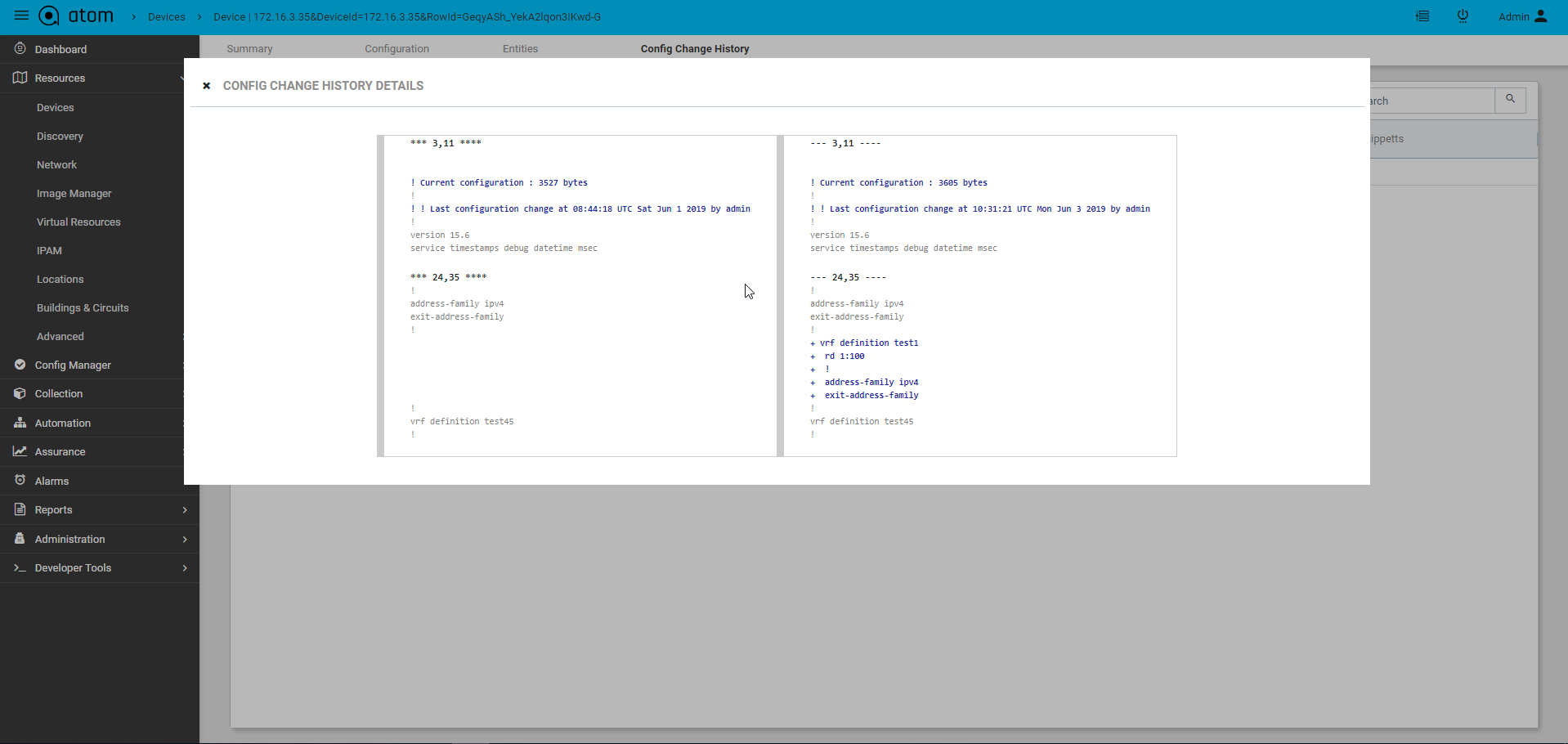
Configuration Change Management – Create/Update/Delete
Configuration archive discussed in the “Configuration Management” section provides a Read-Only view of Device CLI configuration. Additionally, ATOM provides Model driven configuration for create, update & delete. This includes the following:
- Discovery of Device configuration
- Show a tree view of the configuration
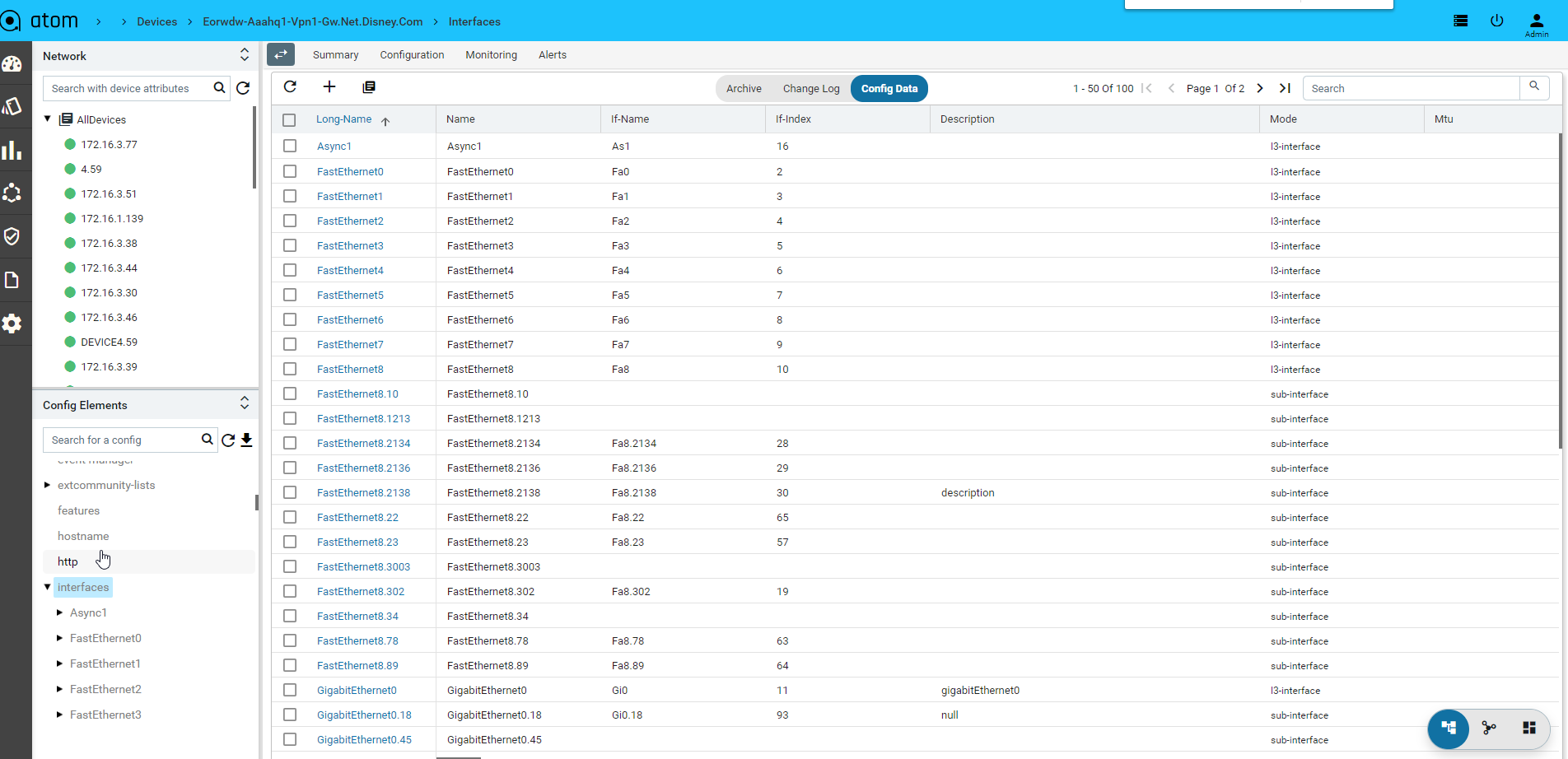
- Create/Edit/Delete of Device configuration Configuration Editing can be done from “Config Data” view:
- To view Device Configuration – Navigate to Devices > select a device
- Click on the Configuration> Config Data Tab
- From the Tree view select a node and possible operations are shown on the right hand side
Note: Create/Edit/Delete from here will send configuration instructions to the device. ATOM should be set to interactive mode from the Administration page.
Device Inventory (SNMP)
All Device inventory collected through SNMP Collection job is shown in Entities view. Following provides guidance on
- To view Device Configuration – Navigate to Devices > select a device
- Click on the “Monitoring” Tab
- Collected data will be shown under MIB-name
Adding Unmanaged devices
Some devices, with feature capabilities such as L2 only, L2 and L3 both, L3 only, can be manually added to the Devices table. Such devices are not managed by ATOM and it does neither generate configurations nor push any configurations on them. Multiple unmanaged devices can be on-boarded into the resource pool and each such device can be used during service instantiation.
To add an Unmanaged device, do the following:
- Navigate to Resources > Devices > Add Device
- In the Create device screen, select the Unmanaged option Enter values in the following fields:
- Host Name: Enter a name for the device
- Device Capability: Select one or more capabilities from the available list.
For example, if you want the device to behave as a L3 device, choose L3Router
from the list.
-
- Device Type: Select the category of the device that it belongs to. 3. Add network connections between the null device and it’s peer device as follows:
- Source Interface: Select the interface, on the null device, from which the network connection should originate.
- Peer Device: Select the device, managed by ATOM, as the peer device.
- Peer Interface: Select the interface on the peer device where the network connection should terminate.
Adding Dummy devices
In some scenarios, you may have to create devices for which configurations are created as a part of a service but are not pushed to any actual device. These logical entities are termed Dummy Devices and they do not have any real world counterparts with a pingable IP address.
Network Topology
Network Connections
Network connectivity is discovered between devices using Layer 2 discovery protocols – CDP & LLDP. In cases where CDP/LLDP is not supported or enabled on the device, Network connections can be added Manually using Network connections .
NOTE: Network connections should be added manually between the devices that have LACP port channels configured on them.
To add a Network Connection, do the following:
- Go to Resource Manager > Network
- Click Network Connections and click Add.
- In the Create Network Connection screen, enter the values in the following fields:
- Unique ID: This is a system-generated ID for a network connection.
- Source Device: Select a Device (origin of the network connection)
- Source Interface : Enter a name for the interface on the source device
- Destination Device: Select a Device (the end of the network connection)
- Destination Interface: Enter a name for the interface on the destination device. A Network Connection is established between the interfaces of the source and the destination devices.
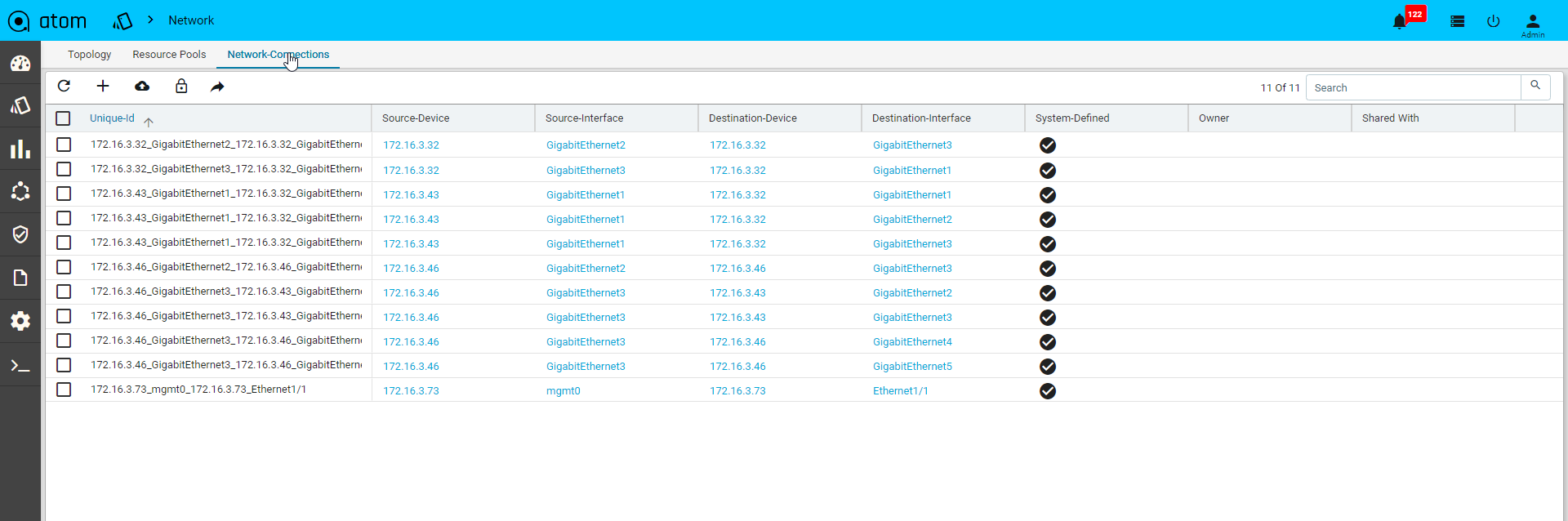
Network Topology
All the devices for each of which network connections are available are displayed in the topology view.
Resource Pools
A resource pool is a logical abstraction for flexible management of resources managed by ATOM. A resource pool can contain child resource pools and you can create a hierarchy of shared resources. The resource pools at a higher level are called parent resource pools. Users can create child resource pools of the parent resource pool or of any user-created child resource pool. Each child resource pool owns some of the parent’s resources and can, in turn, have a hierarchy of child resource pools to represent successively smaller units of resources.
Resource pools allow you to delegate control over the resources of a host and by creating multiple resource pools as direct children of the host, you can delegate control of the resource pools to tenants or users within the organizations.
Using resource pools can yield the following benefits to the administrator:
- Flexible hierarchical organization
- Isolation between pools, sharing within pools
- Access control and delegation Creating a Resource Pool
- Navigate to Resource Manager > Network > Resource Pools
- In the right pane, click the Add Resource Pool button to create a Resource Pool
- In the Create Resource Pool, enter values in the fields are displayed: .
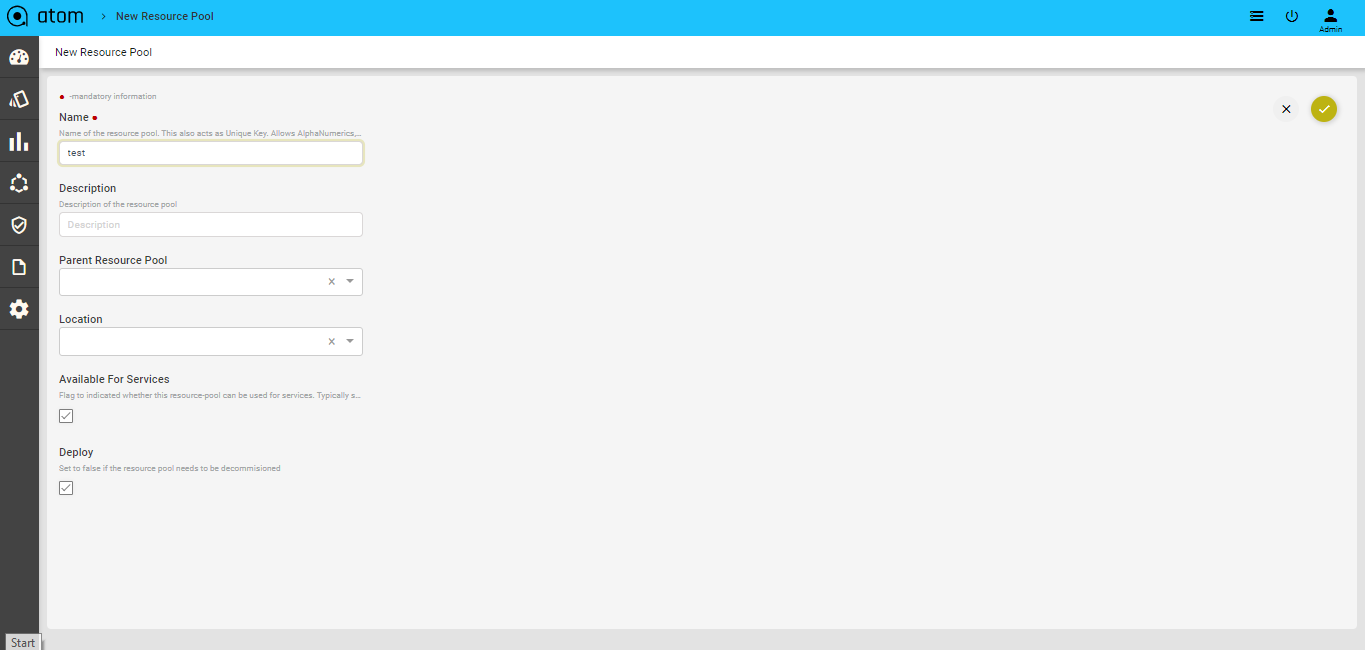
- Name: Enter a name for the resource pool
- Description: Enter some descriptive text for the created resource pool
- Available for Services: Select this option if the resource pool can be used for creating services.
- Parent Resource Pool: Select a resource pool that should act as the parent for this resource pool that is being created.
- Location: Select the name of the site or the geographical location where this resource pool should be created. See the section, “Locations” for more information about creating Locations and Location types.
- Deploy: Select this option if the resource pool should be deployed or used in services.
Adding Devices to a Resource Pool
- Click the created resource pool to add the required devices to it.
Select Resource pool > Add Devices
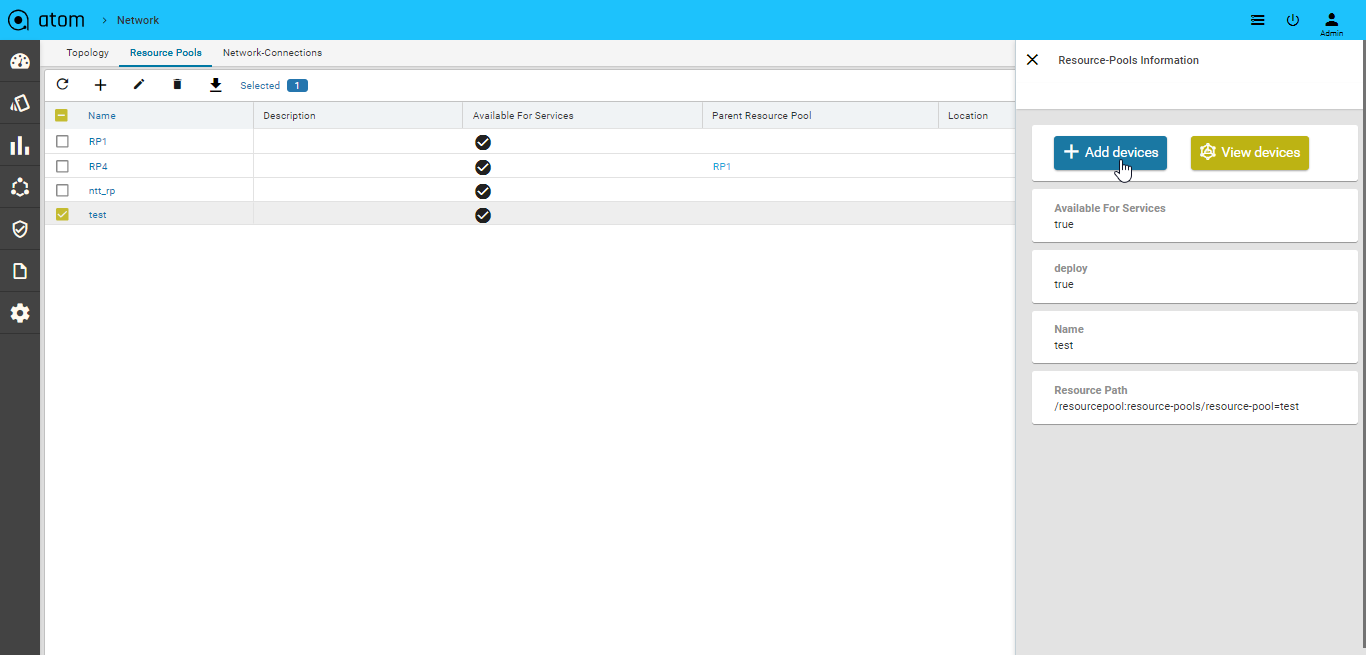
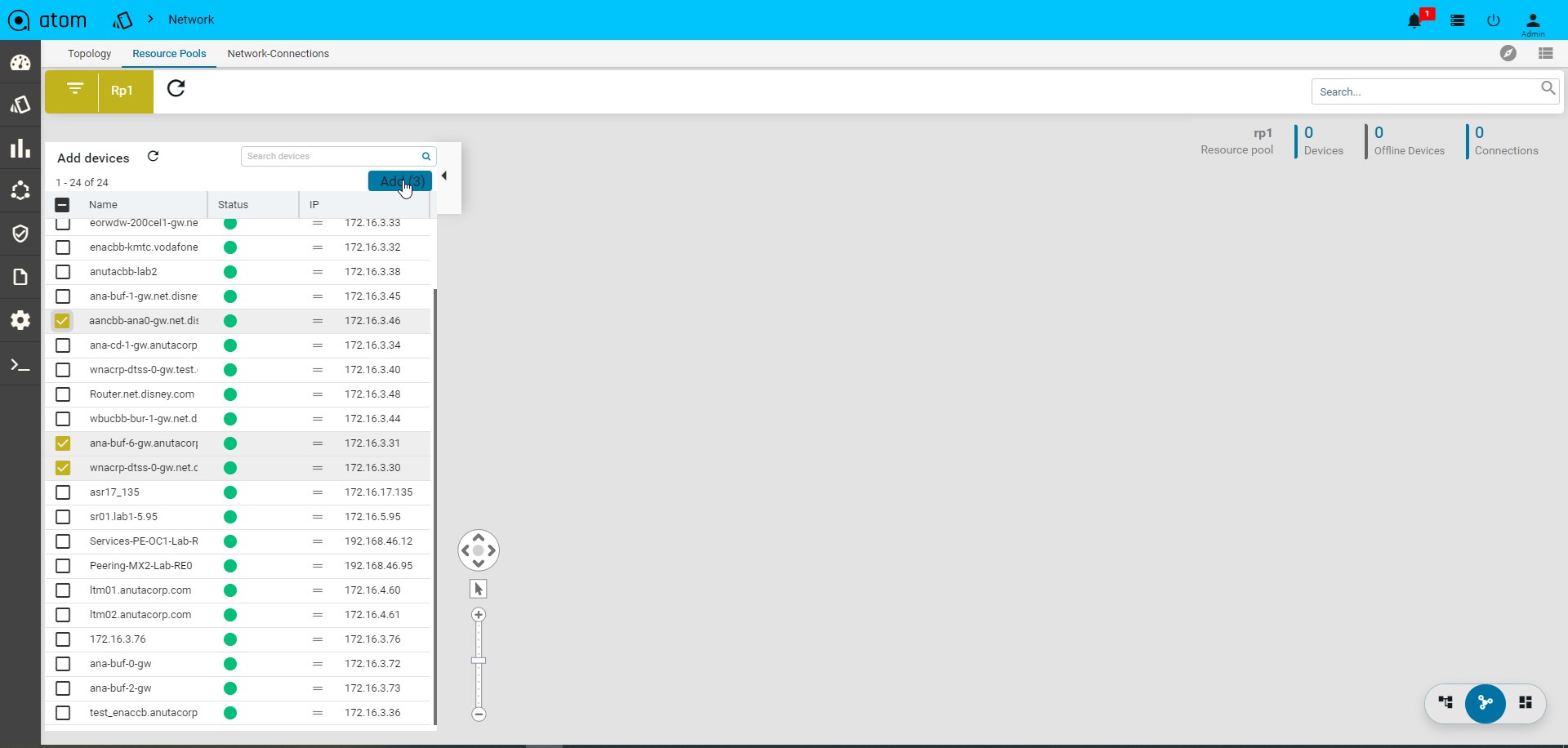
- All the devices available in ATOM are displayed in the left pane.
- Click Add to include the required devices in the resource pool
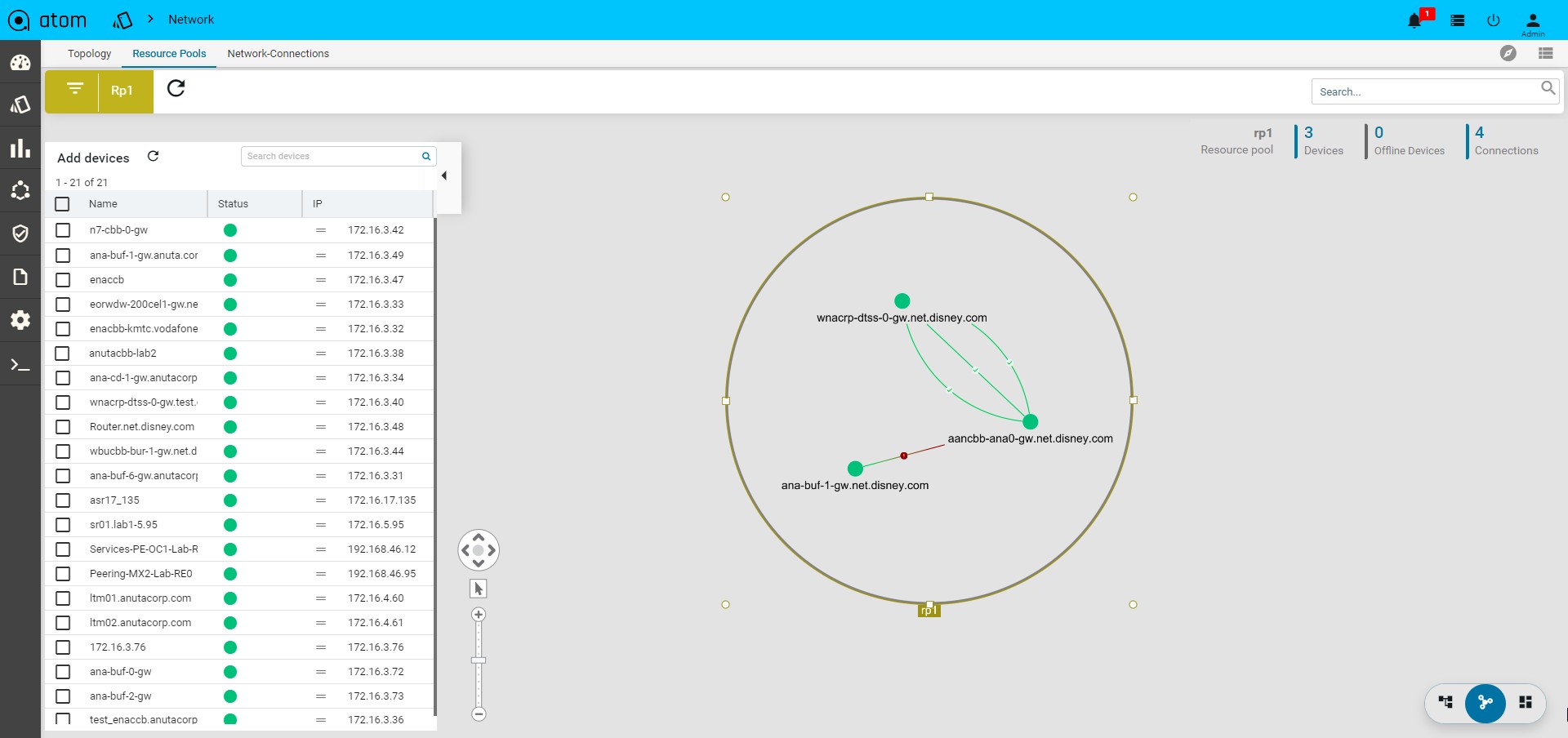
- Select the device from the Drag and Drop the devices pane to the right pane All the selected devices are now part of the resource pool created earlier.
Locations
Devices & Resources Pools can be attached to a Physical Location. Location tagging allows devices and resource pools to be visualized on a Geographical Map in topology view.
- To Create/Edit a Location – Resource Manager > Locations > Resources-Location >click
Add Location
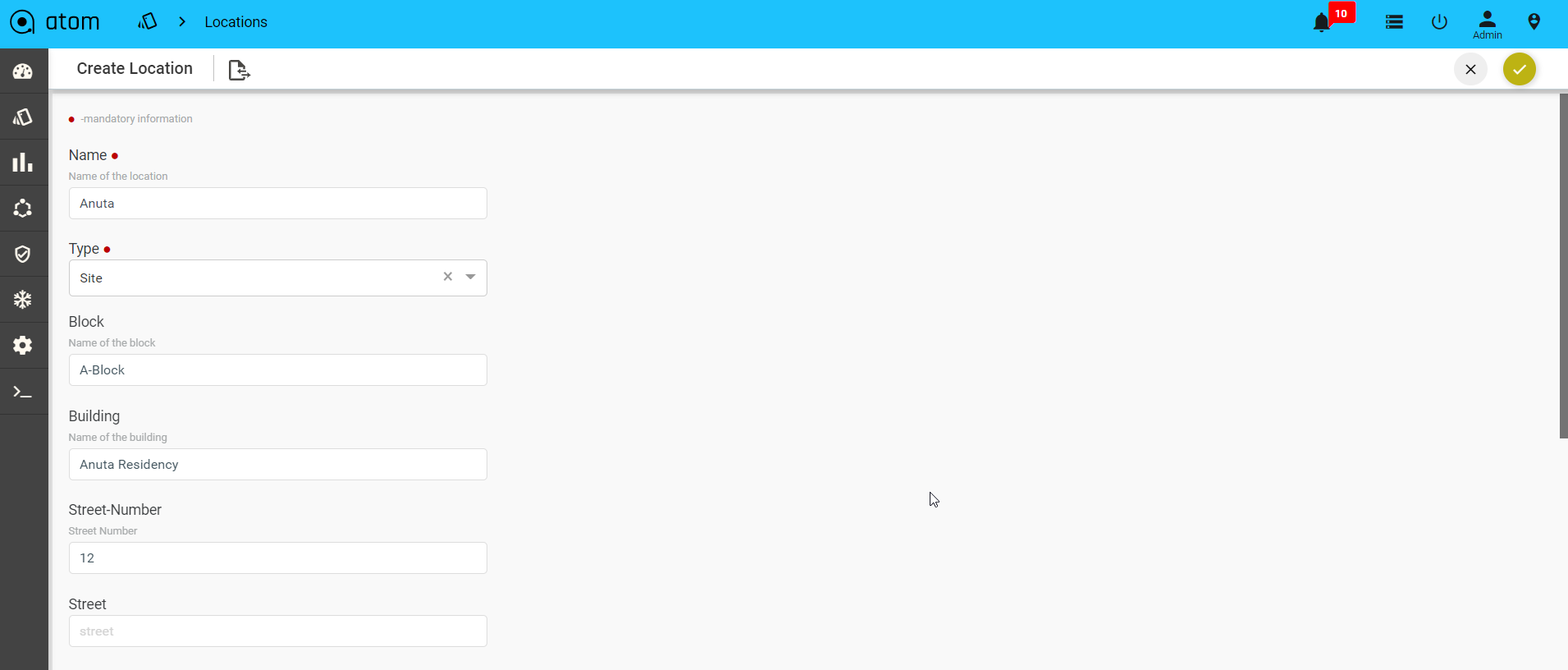
- In the Create Location screen, enter values in the fields described:
- Name: Add the name of for the data center or the site that you want to create.
- Type: Select from the pre-defined location types from the drop-down menu. (preferably select Site)
- Block: Enter the name of the block where the location is situated
- Building: Enter the name of the Building
- Street Number: Enter the number of the street where the Building is located
- Latitude: Enter the latitude of the site.
- Longitude: Enter the longitude of the site.
- Street: Enter the street name where the building is located.
- Country: Select a country from a pre populated list available in ATOM
- City: Select a specific city contained in the chosen country.
- State: Enter the name of the State or province to which the city belongs.
- Zip Code: Enter the zip code of the City where the Site is located.
- Parent Location: Select one of the predefined locations (of the type, Region or Country) defined earlier.
For assigning the created Location to a Resource pool, refer to section, “Creating a Resource Pool”.
After the successful allocation of the Resource Pool to the given Location, you can view it on the map. Select the created Resource Pool and click View on Map
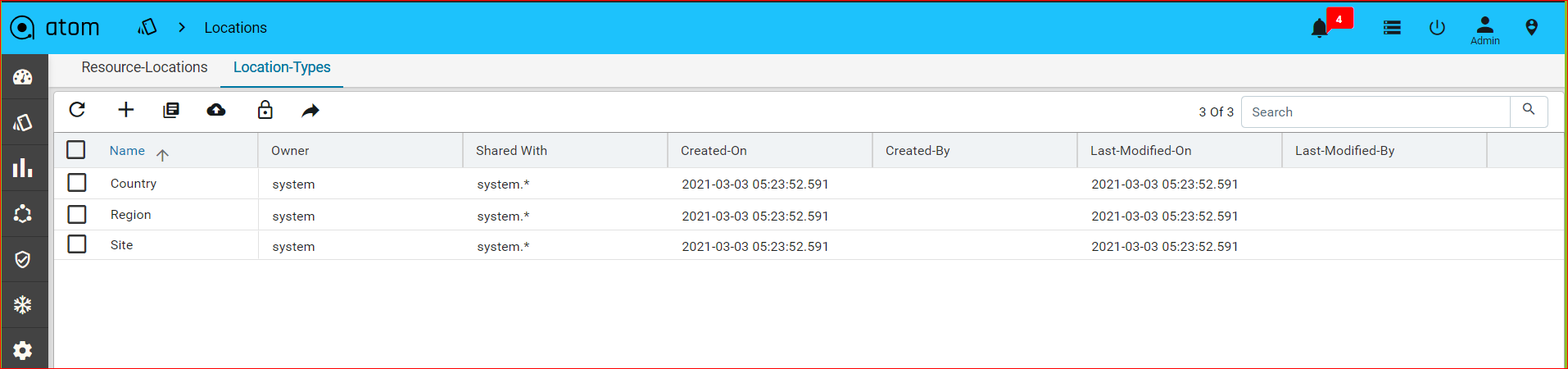
Location Types
Add the types of the location that should be associated with a Location. Navigate to Resource Manager > Locations > Location Types.
The default location types available in ATOM are Region, Country, and Data Center
IPAM
IP Address Pool Group
For effective management of IP addresses, you can arrange IP addresses as an ordered collection and use them while instantiating a service.
- Navigate to Resource Manager > IPAM > IP Address Pool Groups
- Click Add IP Address Pool Group in the right pane
- In the Create IP Address Pool Group screen, enter values in the fields:
- Name: Enter the name of the IP address pool group
- Label: Enter the name of the label that describes the IP address pool group
- Click Add to add IP Address Pools to be included in the IP Address Pool Group
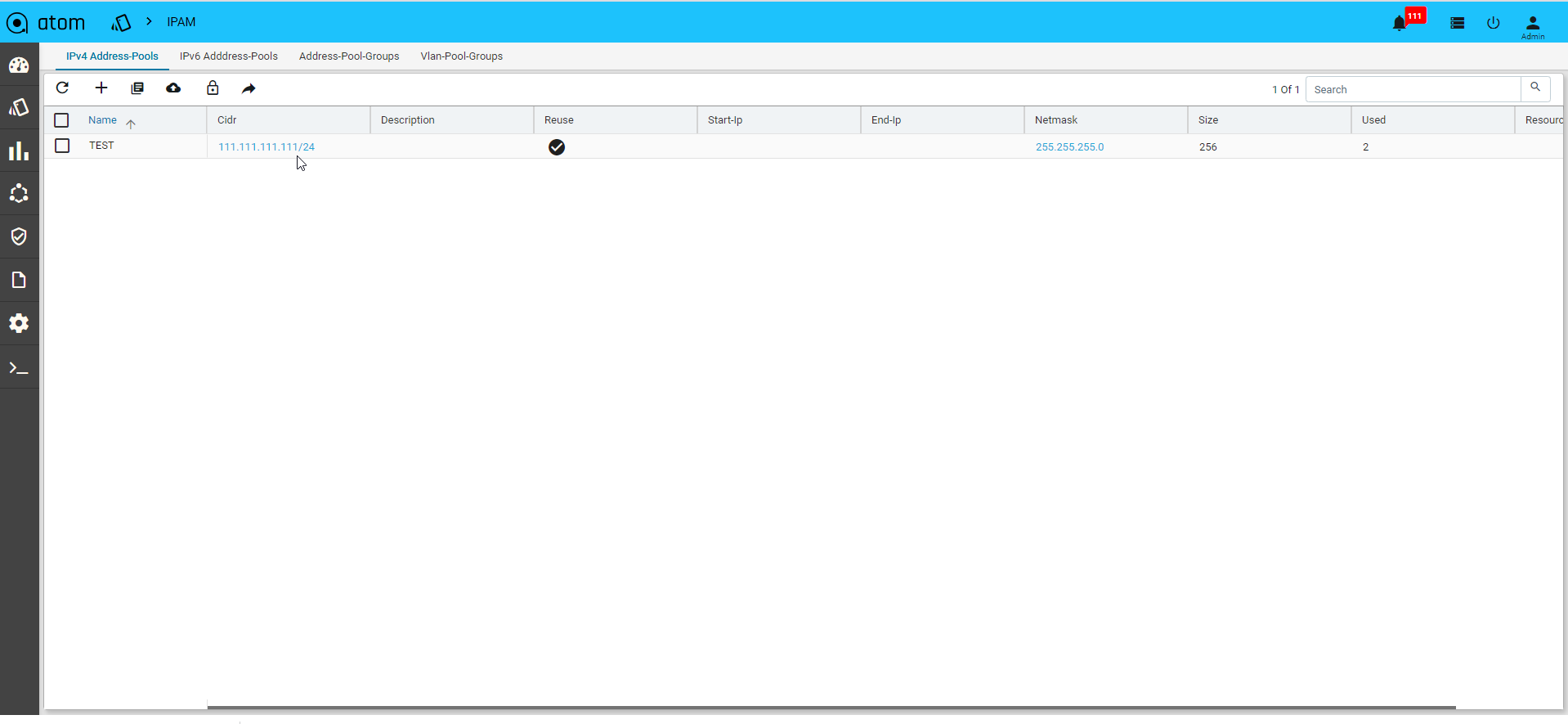
IP Address Pools
A range of IP addresses can be assigned to a pool and associated with a resourcepool.All these IP addresses will be used during the instantiation of the service.
- Navigate to Resource Manager > IPAM > IP4- Address Pools
- Click Add IP Address Pool on the right pane and enter values in the following fields:
- Name: Enter a unique name for the IP address pool
- CIDR: Enter the CIDR (IP address followed by a slash and number)
- Description: Enter the description for the created IP Address Pool
- Reuse: Select this option if the IP addresses contained in this pool should be reused across different services.
- Start IP:Enter the start IP address of the range of IP addresses
- End IP: Enter the last IP address in the IP address range.
- Resource Pool: Select the Resource pool to which these IP addresses should be assigned. All the services that are created in these Resource Pools will use these IP addresses.
Creating IP address entries
IP Address entries are the IP Address Pools that have been reserved for a service.
-
-
- Click IP address pool > Action > IP address entries
-
IPV4
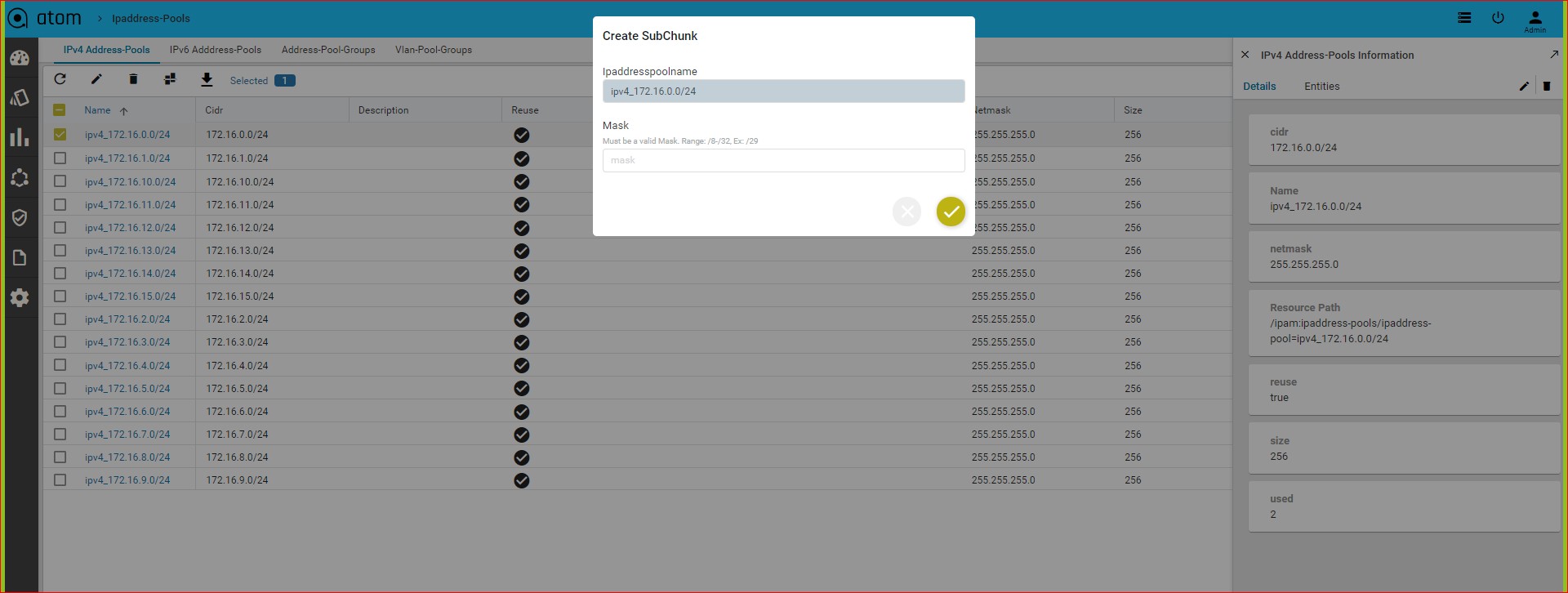
Creating Sub Chunks of the IP Address Pools:
The network contained in an IP address pool can be divided into two or more networks within it. The resulting sub chunks can be used for different services to be configured on a resource pool tied with the parent IP address pool.
IPV6:
Resource Manager > IPAM > IP6- Address Pools
Address-pool-Groups
VLAN Groups
You can define VLAN groups and VLAN pools and define them as resource boundaries for a tenant in such a way that these VLAN Pools can be used during service instantiation on a resource pool.
Adding VLAN Groups
- Navigate to Resources > IPAM > VLAN Groups
- In the right pane, click Add VLAN Pool Group
- In the Create VLAN Pool Group screen, enter values in the following fields:
- Name: Enter a name for VLAN Group
- Description:
- Click Actions > vlan pools > vlan pool to create VLAN pools in the VLAN group:
- Enter values in the following fields:
- Start VLAN: Enter a number from the valid VLAN range. (1-4096)
- End VLAN: Enter a number from the valid range (1-4096)
- Click Add to add the required resource pools to the VLAN Pools
- Click the vlan pool > click Actions to add allocated VLAN.
Configuration Compliance
Configuration Compliance feature allows users to Define & Enforce Configuration Compliance Standards. This is realized within ATOM using the following primitives.
- Policies – Define Configuration standards & Remediation Policy by Device Family, Device Type, OS Type etc.,
- Profiles – Group multiple policies and apply configuration standards on one or more devices
- Reports – Comprehensive compliance reporting view at device level
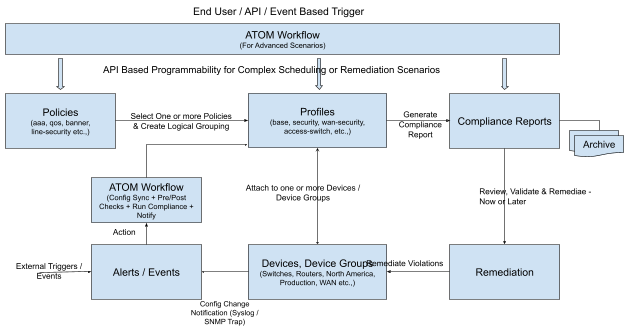 Remediation – Fix Policy Violations on one or more devices Following diagram summarizes the overall flow.
Remediation – Fix Policy Violations on one or more devices Following diagram summarizes the overall flow.
Configuration Compliance Can address the following scenarios:
- Check If a particular configuration is present
- Check If a particular configuration contains a given pattern / should NOT contain a given pattern.
- Check If a particular configuration contains stale/unwanted configuration.
- Check for User defined parameterized values (Dynamic inputs) in configuration.
- Arithmetic checks to enforce thresholds on resource usage and capacity planning. Example:- Per device Max 100 vrfs to be configured or 20 Vlans to be enabled or 10 bgp sessions per vrf
- Group parameterized values to apply the policy. Example valid Values: ‘Any’, ‘AnyEthernet’, ‘FastEthernet0/.*’ etc.
- Regex and Jinja2 Parsers In & Between conditions
- Apply filters on configuration to categorize config blocks. Ex:- Access vs trunk based on link speed, Ports description satisfying regex classifiers,Ports which are admin up and contain IP.
- Inventory checks for NETCONF/YANG parameters using XPath based expressions.
- Parse as Blocks to split the entire running configuration into blocks and search for the condition match criteria value within each block.
- Custom Block split definitions based on the start and end expressions you provide in the Block Start Expression and Block End Expression text boxes.
- Evaluate each block against a set of conditions with individual actions/severities by using the Condition Scope as Previously Matched Blocks to parse.
- Raise single violations for condition violation by any block or multiple violations per block of violation with individual remediation actions defined.
ATOM supports Configuration Compliance for the following Vendors:
-
- Cisco Systems
- Juniper Networks
- Fortinet
- Force10 Networks
- Brocade
- PaloAlto Networks
- Riverbed Technology
- F5 Networks
Policies
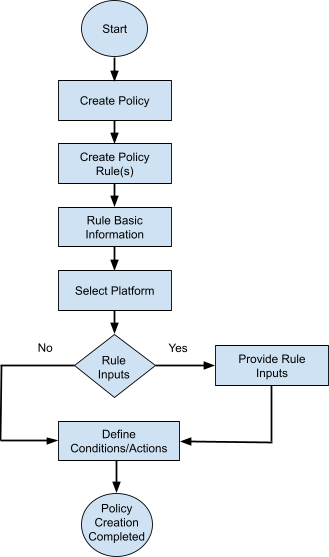
Compliance policy allows configuration standards to be defined in CLI format and YANG format(x-path or xml). Following provides a high level overview of a Policy:
-
- Policy is a collection of Rules
- A Rule contains one or more Conditions
- Condition describes
- Expected Configuration. Configuration can be parameterized through Rule Variables.
- Action to be taken on a condition evaluation includes CLI commands or Netconf XML RPC format to be used to remediate a violation.
-
- A Rule can be attached to one or More device platforms – Vendor, OS Type, Device Family, Device Type and OS Version
Use Cases
| # | Configuration Standard Style | Example | Reference |
|
1 |
Static Configuration |
Example: All Devices in Target Network should Contain a specific Domain Name
Expected Configuration: ip domain-name anutacorp.com Fix Configuration: <<If missing, configure the above command>> |
Scenario1 |
| XPath Expression | Xpath Expression:
Cisco-IOS-XR-native:native/ip/domain/name=`anutacor p.com’ |
Scenario6 | |
|
XML Template Payload |
Template Payload:
<native xmlns=”https://cisco.com/ns/yang/Cisco-IOS-XE-native“ > <ip> <domain> <name>net.disney.com</name> </domain> </ip> </native> |
Scenario11 |
|
|
2 |
Dynamic Configuration with User provided values |
Example: Devices in Target Network should have a specific Loopback interface – Loopback0 or Loopback1 based on user input.
Expected Configuration: interface {{ interface_name }} Fix Configuration: <<If missing, Configure the specific Loopback interfaces>> |
Scenario3 |
| X-path | Xpath Expression: | Scenario9 |
| Expression | Cisco-IOS-XE-native:native/interface/Loopback/name=’ | ||
| 0′ and | |||
| Cisco-IOS-XE-native:native/interface/Loopback[name=0 | |||
| ]/ip/address/primary/address='{{ lo0_ipv4addr }}’ and | |||
| Cisco-IOS-XE-native:native/interface/Loopback[name=0 | |||
| ]/ip/address/primary/mask=’255.255.255.255′ and | |||
| Cisco-IOS-XE-native:native/interface/Loopback[name=0 | |||
| ]/ipv6/address/prefix-list/prefix='{{ lo0_ipv6addr }}’ | |||
|
XML Template Payload |
Template Payload:
<native xmlns=”http://cisco.com/ns/yang/Cisco-IOS-XE-native” > <interface> <Loopback> <ip> <address> <primary> <address>10.100.99.98</address> <mask>255.255.255.255</mask> </primary> </address> </ip> <ipv6> <address> <prefix-list> <prefix>2605:30C0::3B/128</prefix> </prefix-list> </address> </ipv6> <name>0</name> </Loopback> </interface> </native> |
Scenario13 |
|
| Configuration | Example: All the VTY lines should have specific | ||
| with Patterns, | exec-timeout and session-timeout configured. | ||
| 3 | Wildcards,
etc.that |
Expected Configuration: | Scenario4 |
| require Regular
expressions |
line vty (.*)
session-timeout 10 |
| exec-timeout 10 0
Fix Configuration: <<If missing, Configure the timeouts under all matching VTY lines>> |
|||
|
4 |
Configuration with sub-modes |
Example: The physical Interface should not be shut down and show be in auto-negotiation mode
Expected Configuration: interface {{ interface_name }} no shutdown negotiation auto Fix Configuration: <<If missing, Configure the above commands for one or more interfaces>> |
Scenario3 |
|
5 |
Removing unwanted extra configuration |
Example: Finding the Devices having extra ntp-server addresses configured and removing those other than expected server addresses.
Expected Configuration: ntp-server 10.1.1.1 Fix Configuration: << Configure above ntp-server if not found. Remove any ntp server other than 10.1.1.1 >> |
Scenario2 |
| Example: Finding the devices in the network which | |||
| doesn’t contain the OSPF router-id configured as per | |||
| loopback0 ip address. | |||
|
6 |
Advanced: Presence of an entity value from one block in another | Expected Configuration:
interface Loopback0 ip address 45.45.45.5 255.255.255.255 ! router ospf 100 router-id 45.45.45.5 |
Scenario5 |
| Fix Configuration:
router ospf 100 |
| router-id 45.45.45.5 |
Scenario 1: IP Domain Name
Scenario: Network Devices must have domain name configured. In this example we are looking for the domain name as anutacorp.com across all devices in the lab.
Platform:
Cisco IOS-XE
Expected Configuration:
ip domain-name anutacorp.com
Fix-CLI Configuration:
ip domain-name anutacorp.com
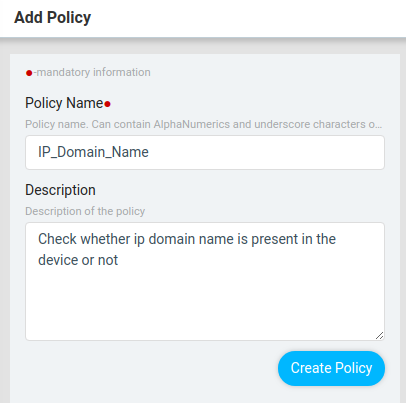
Follow the steps below to configure Compliance Policy for the above scenario.
- Configure Policy
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name
- Description
- Configure Rules
One or more rules can be configured to express configuration standards. Based on the complexity of the scenario, configuration standards can be broken up into more than one condition.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Create/Select a Policy
- Click ‘+’ to create new Rule
- ATOM opens up new wizard as shown below

-
- Rule has four components
- Basic Information
- Platform Selection
- Rule Variables
- Conditions & Actions
- Rule has four components
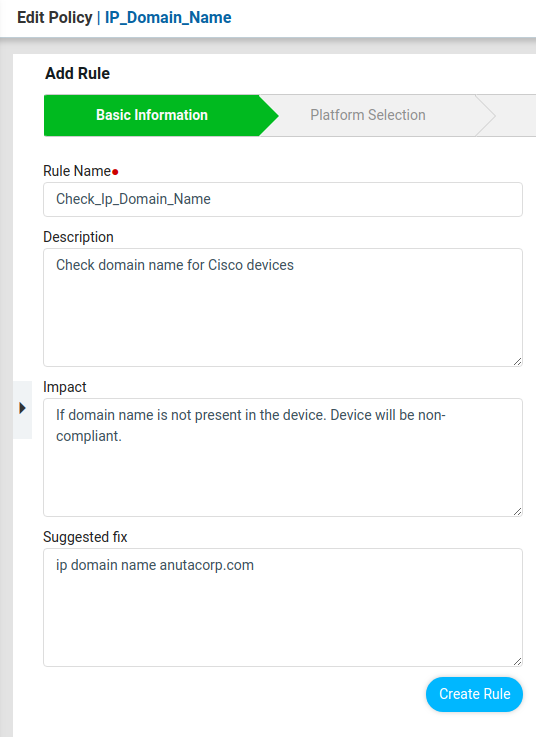
Basic Information
Provide basic information as described below. Information provided here is for documentation purposes only.
Rule Name: Provide any Name
Description: Brief explanation of the configuration evaluation that the rule is going to perform.
Impact: If the device configuration does not meet the rule or rules in the policy, type it in the Impact field.
Suggested Fix: Using which non-compliance can be corrected and device returns to a state of Compliance.
Platform Selection
Rules contain configuration standards expressed in CLI Configuration format. Configuration standard can be at Vendor level, Device Type, Device Platform, OS Type or OS Version.
Steps:
-
- Navigate to Config Manager > Config Compliance -> Policies -> Rules
- Create/Select a Rule & Provide the following information
- Vendor
- OS type
- Device Family
- Device Type
- OS Version
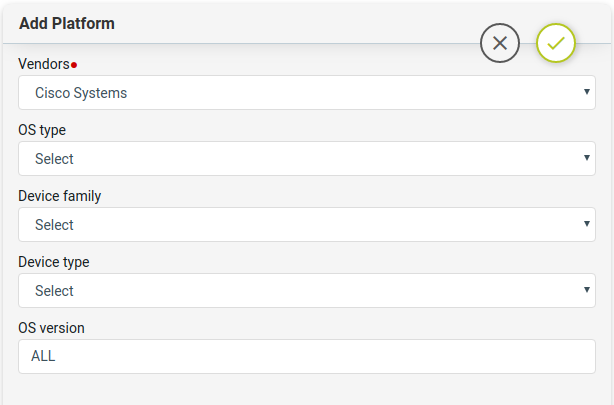
Note: Platform Selection will be used during Policy execution. Devices that don’t match the above criteria are skipped.
Note: It’s not common to have more than one Platform
Rule Variables
Rule variables allow configuration to be parameterized.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules
- Create/Select a Rule Variables
- Key – Provide unique name to identify rule variable
- Description – Describe rule-input configuration
- Default Value – Default value. Can be overridden during Policy execution time
Conditions and Actions
Expected configuration & actions to be taken when violations are detected are specified in the
Conditions & Actions section.
Based on the complexity of the scenario, configuration standards can be broken up into more than one condition.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules
- Create/Select Conditions & Actions
- Condition Details – Described Below
- Action Details – Described Below
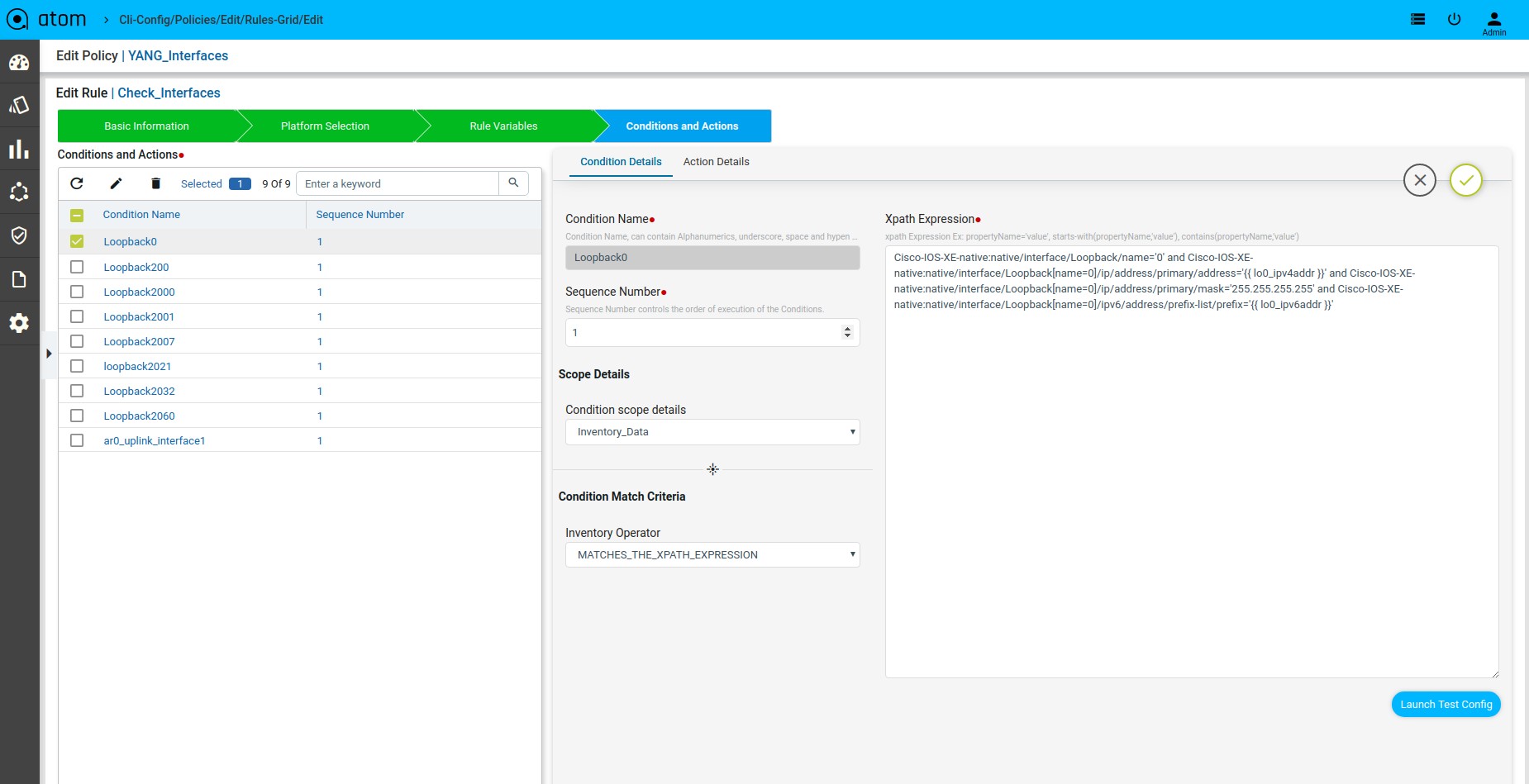
Condition Details
Condition section provides users to specify the expected configuration and various options on how to match the expected configuration including option to identify sub mode configuration blocks.
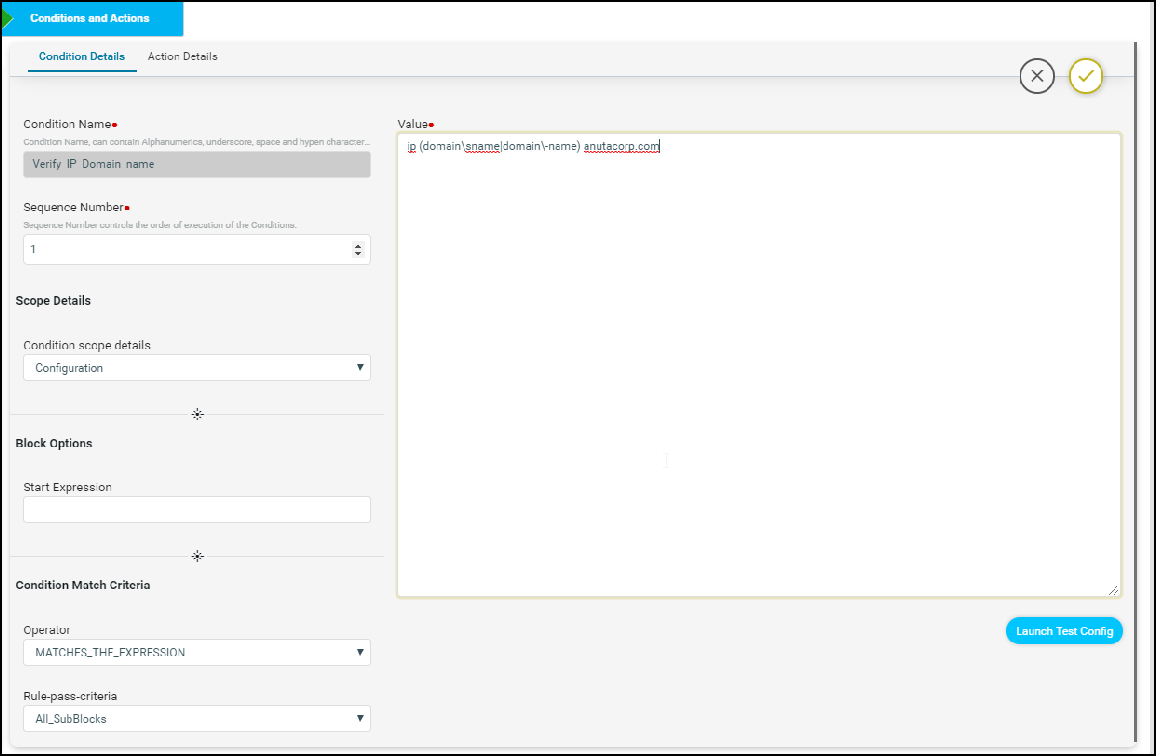
Condition Name: Name of the Condition
Sequence Number : Order of the condition execution.
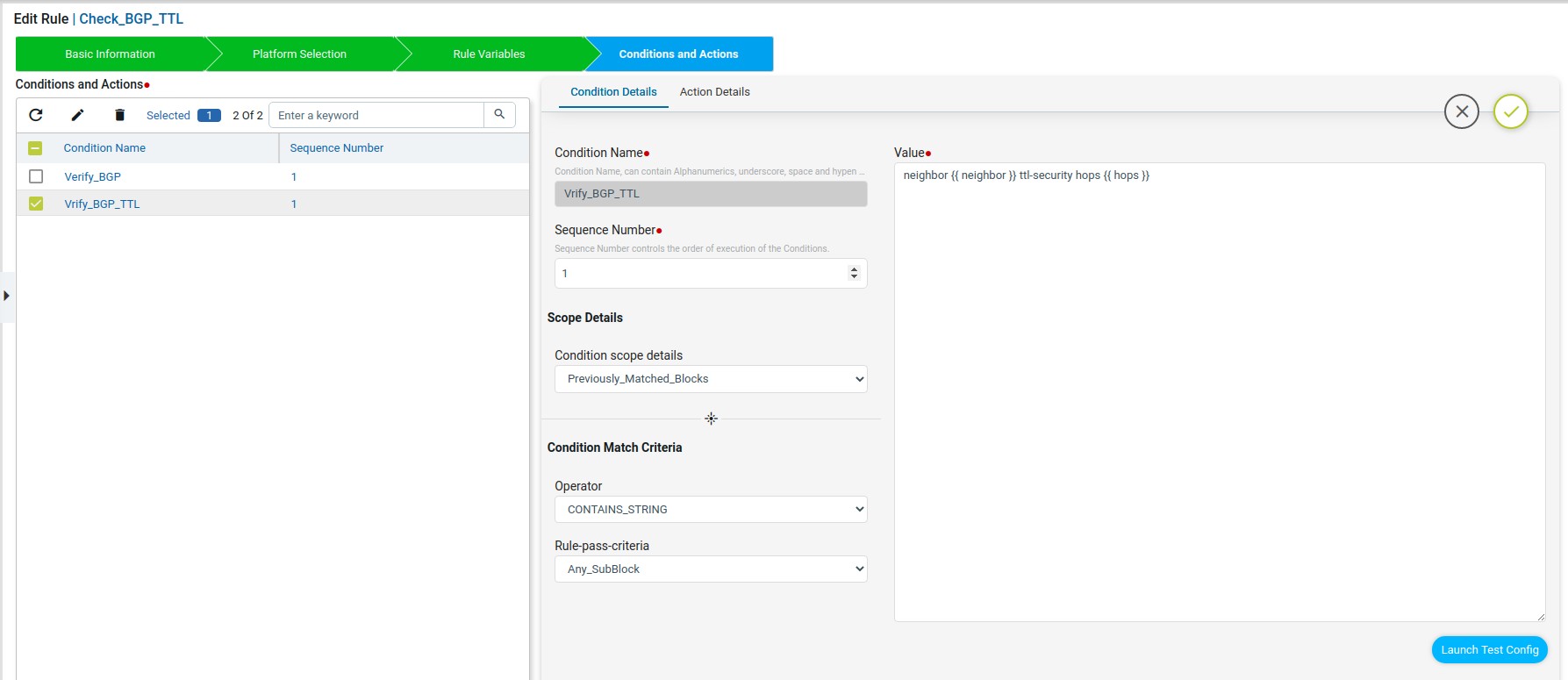
Scope Details
Condition scope details: Scope could be either full configuration copy or configuration matched in prior condition.
- Configuration – Full Configuration
- Previously_Matched_Blocks – Subset of configuration matched by prior condition
Block Options
Start Expression – Regular expression indicating the start of the sub-block.
End Expression – Regular expression indicating the end of the sub-block.
Condition Match Criteria Operator:
MATCHES_THE_EXPRESSION – Checks whether the condition value exactly matches with device configuration or not.
DOESNOT_MATCHES_THE_EXPRESSION – Checks whether the condition value does not match with the device configuration or not.
CONTAINS_STRING – Checks whether the device configuration contains condition value config or not.
Rule-Pass-Criteria:
All_SubBlocks – Checks whether the condition value matches in all the blocks or not. Any_SubBlock – Checks whether the condition value matches in any of the blocks or not.
Value: Value field accepts Configuration Standard as CLI Configuration. Following types of configuration can be provided:
-
- Static Configuration
- Dynamic/Parameterized Configuration
- Configuration with Regular Expressions
- Configuration coupled with Jinja2 Templating
Note: For some Vendor Configurations like Cisco IOS-Style, whitespace in command prefix is mandatory to identify commands at sub-mode level.
For Scenario 1 – Provide value as ip domain-name anutacorp.com to search for a given domain name in the running configuration.
Test Config
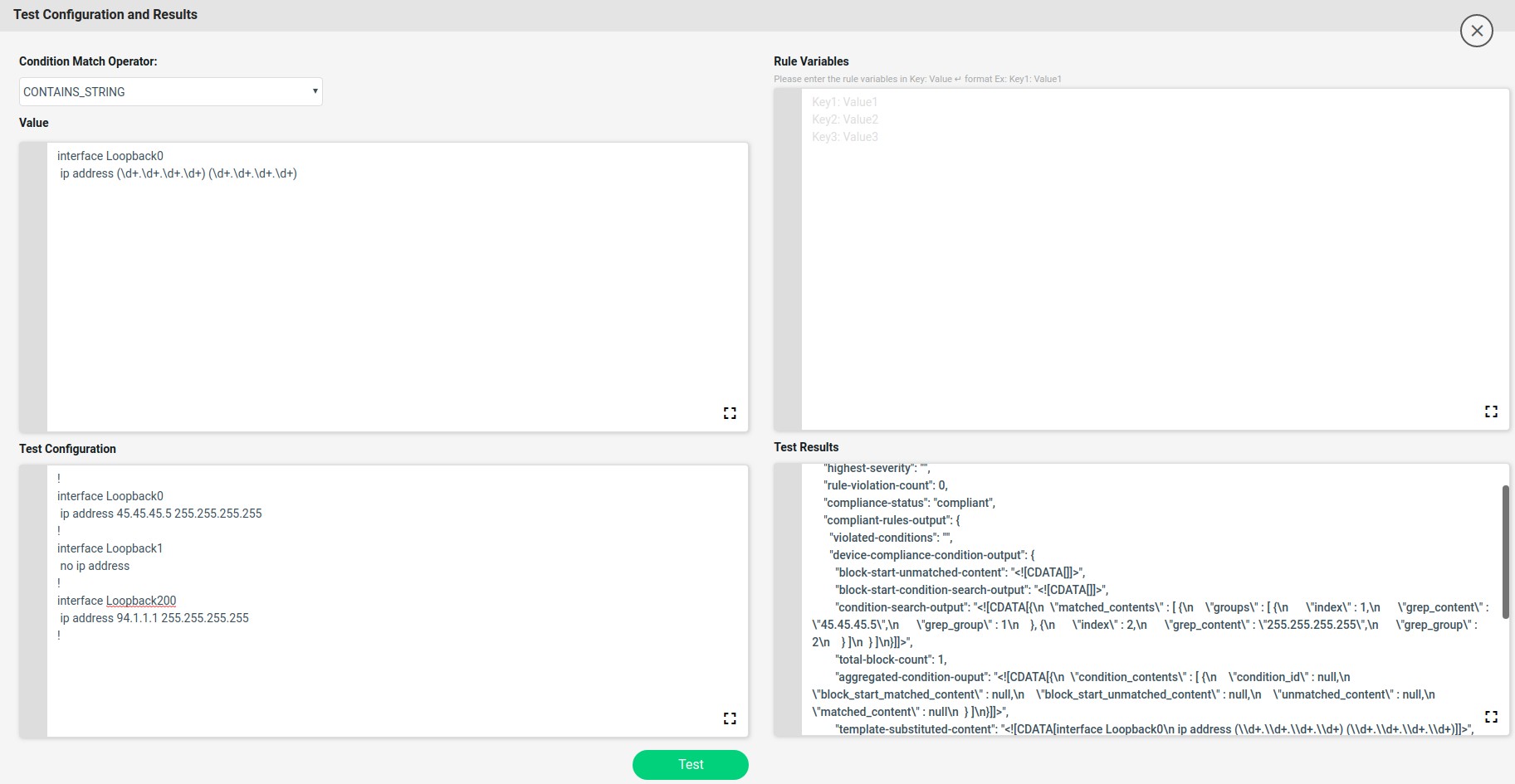
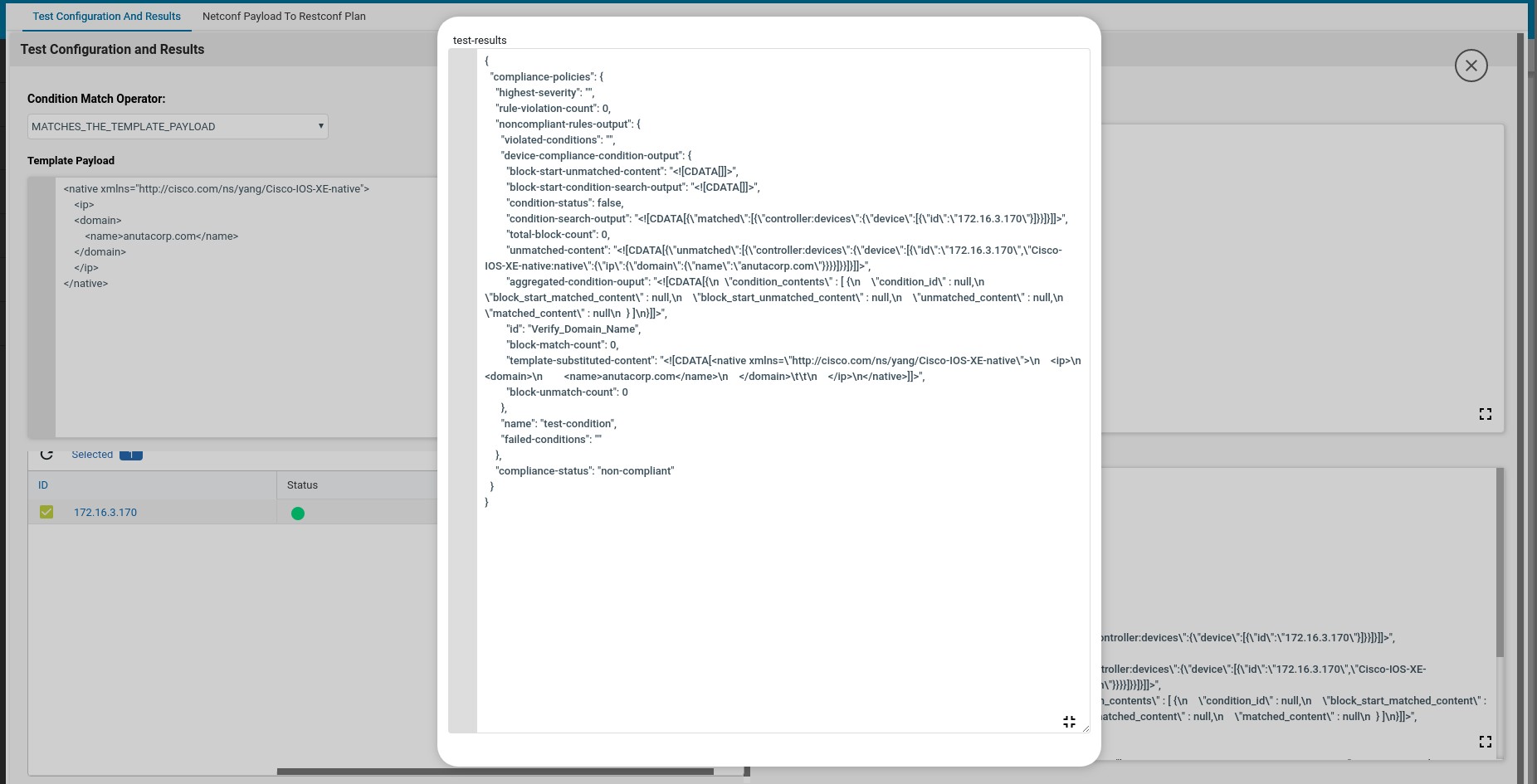
Based on the complexity of the configuration standard, Value may be complex and may need to build up iteratively. Test Config utility helps the CLI configuration condition to be validated against Test Configuration.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules –>
- Create/Select Conditions & Actions
- Click “Launch Test Config” will launch a form to Test Condition
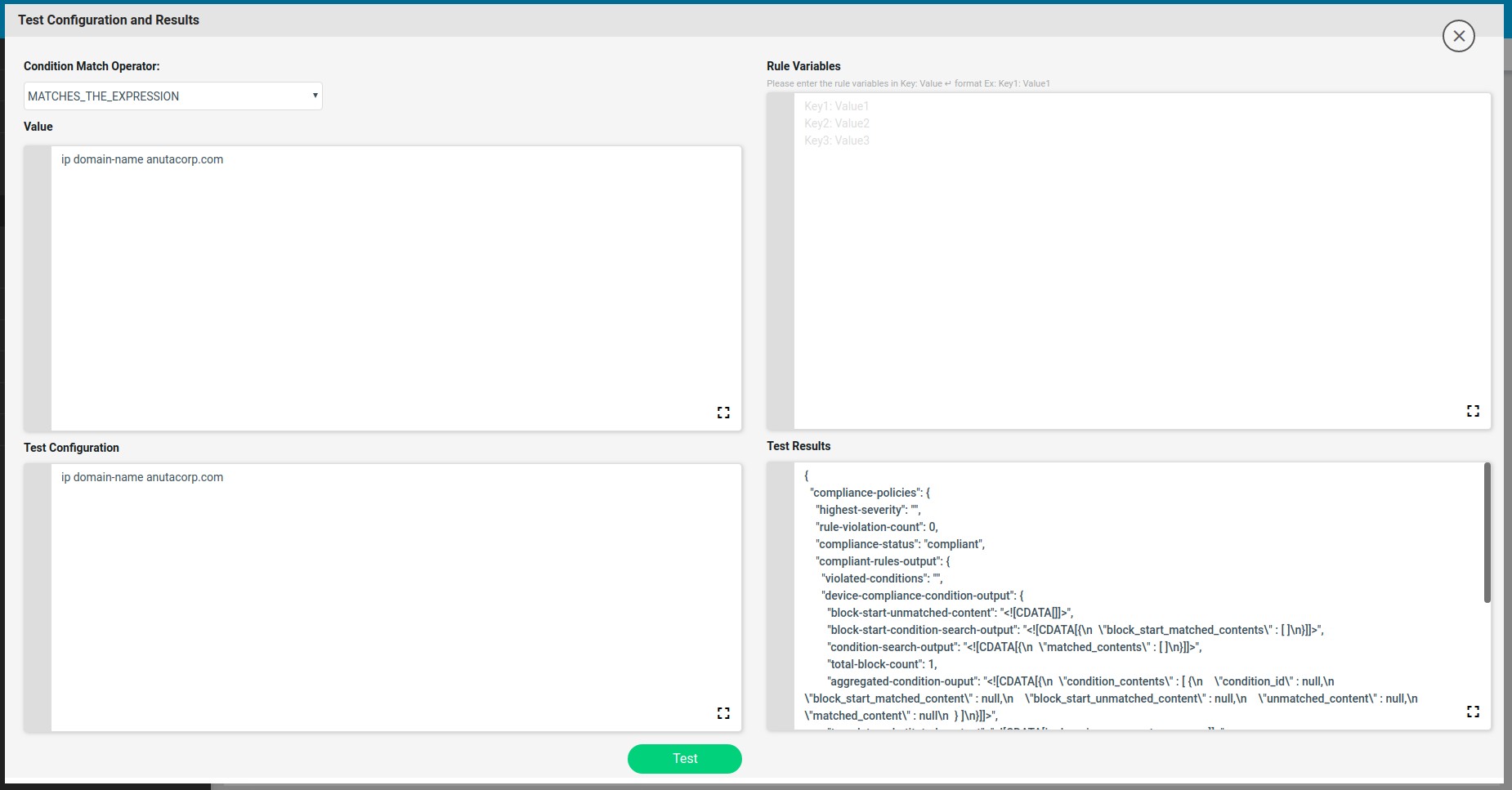
Condition Match Operator: MATCHES_THE_EXPRESSION DOESNOT_MATCHES_THE_EXPRESSION CONTAINS_STRING
Value: Sample configuration to be tested. Value will be shown from the Condition Details. Value can be further refined
Note: Any Edits to Value will reflect in the Condition Details -> Value and Vice-versa.
Test Configuration: Sample device configuration
Rule Variables: The rule variables created in the rule will be shown here with default values. Values can be modified.
Note: Any Edits to Values will not be reflected in the Rule Variable default values provided in Rule Variables Section.
Test Results: Based on Condition Match Operator test results will be shown on the right hand side
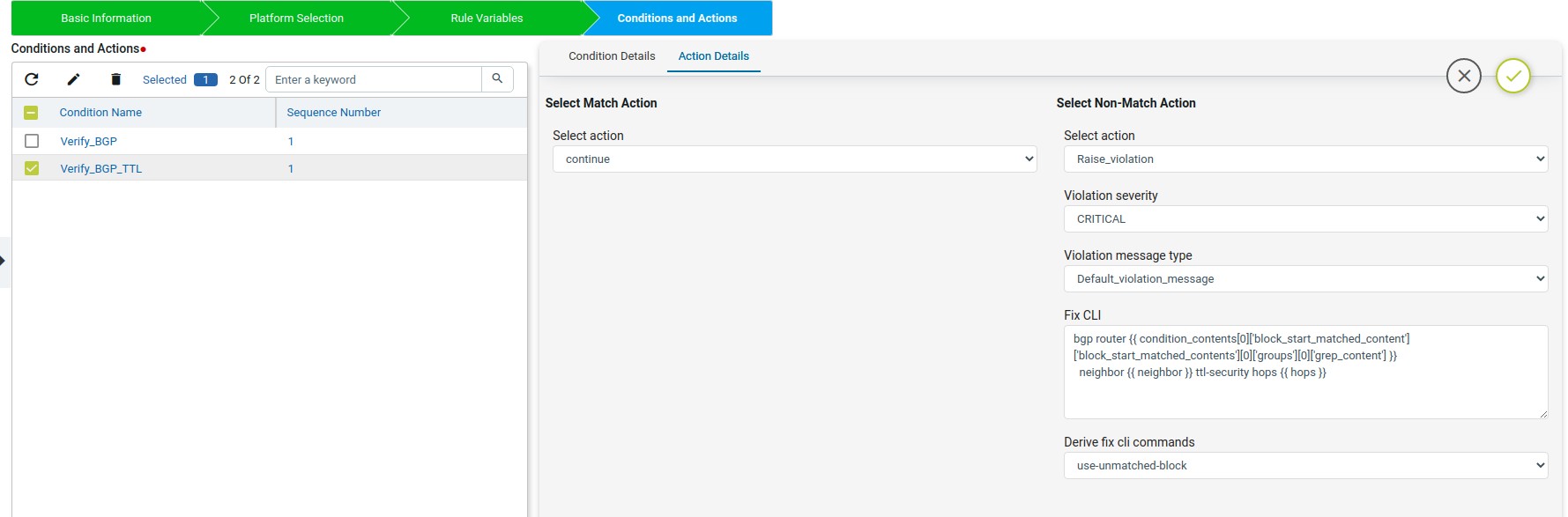
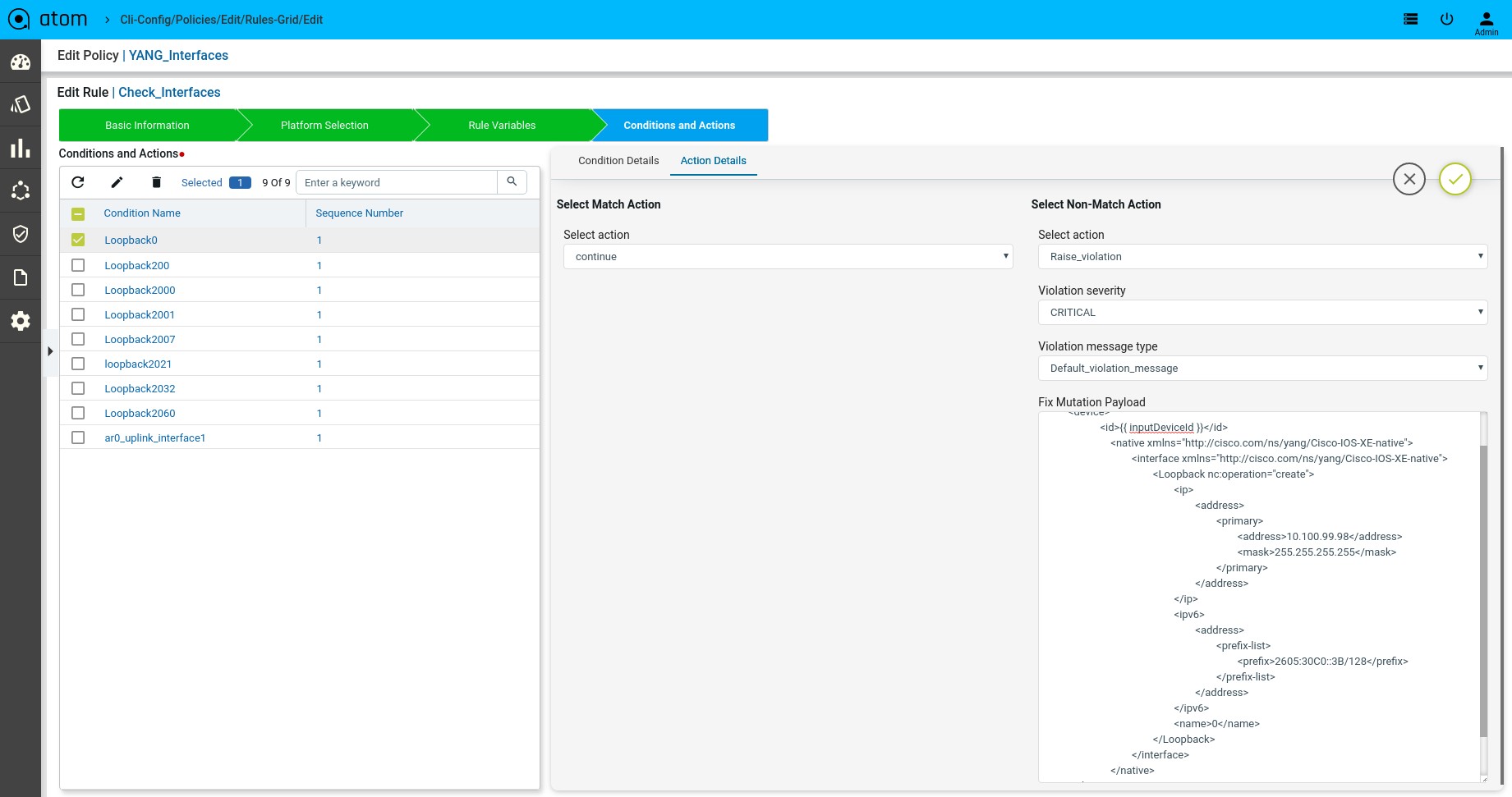
Action Details
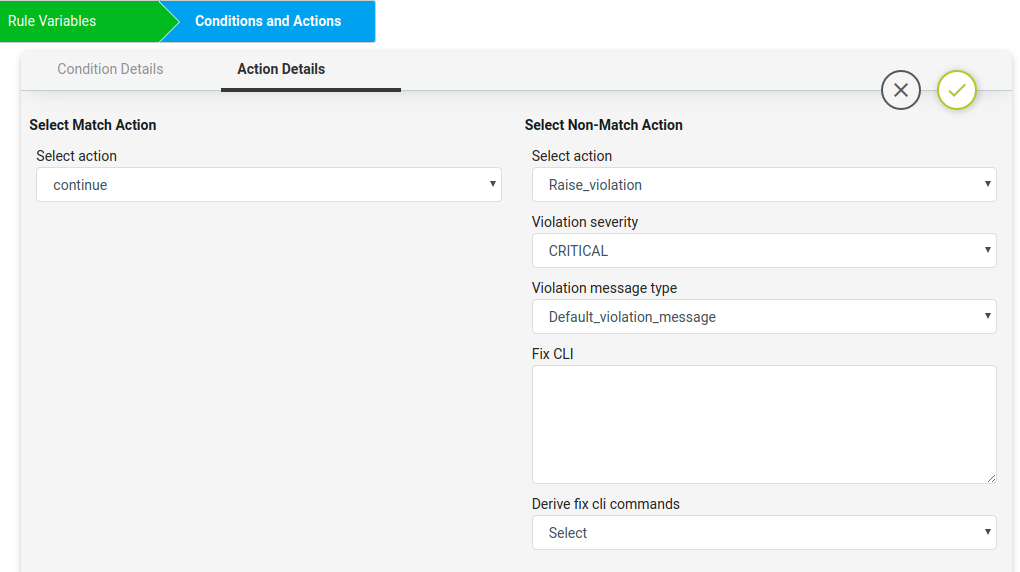
Action can be taken after Condition evaluation. Condition can result in either a “Match” or “Non-Match”. Depending on the scenario one or both criteria may apply.
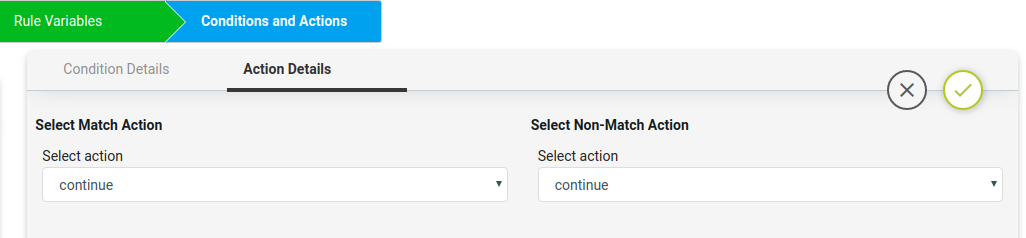
Select Match Action – This option is applicable when Condition evaluates to a Match
Select action:
Continue – continue execution to next condition Donot_raise_violation – skip execution and don’t raise violation
Raise_violation_and_continue – raise violation and continue execution to next conditions Raise_violation – raise violation and skip execution
For Scenario 1, no action needs to be taken during a match condition, so select continue
as action.
Violation severity: LOW MEDIUM HIGH CRITICAL
Violation message type:
Default_violation_message User_defined_violation_message
Derive fix cli commands:
Use_unmatched_block – unmatched config from the block Use_matched_block – matched config from the block Use_complete_block – total block config
Select Non-Match Action Select action:
Continue
Don’t raise violation
Raise violation and continue Raise violation
For Scenario 1, Action is required when Condition is not matched. Select Raise violation and continue.
Violation severity: LOW MEDIUM
HIGH CRITICAL
Violation message type:
Default_violation_message User_defined_violation_message
Fix CLI: Provide the CLI Configuration to be used for remediation. Fix CLI can be either provided here or derived.
Option – 1 – Explicit Remediation / Fix CLI
For Scenario 1, Provide “ip domain-name anutacorp.com” in Fix CLI.
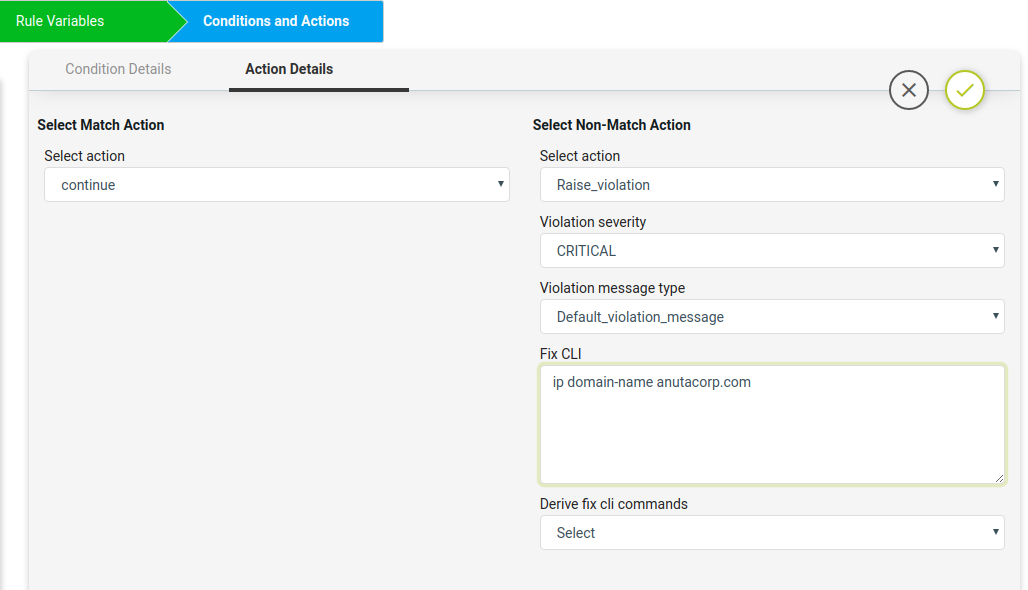
Option – 2 – Remediation Commands can be derived from Condition evaluation.
Derive fix cli commands:
Options below:
Use_unmatched_block Use_matched_block Use_complete_block
For Scenario 1, Select “Use_unmatched_block”. Since this is non-match Action, unmatched_block will be Condition Details->Value and can be used as Fix CLI.
Scenario 2: NTP Server configuration check
Scenario:
- All devices in the network should contain the designated ntp server.
- Remove all other ntp servers
- In this example
- Expected ntp-server = 10.0.0.1
Platform:
Cisco IOS-XE
Expected Configuration:
ntp server 10.0.0.1
Fix-CLI Configuration:
ntp server 10.0.0.1
<<Remove Any Other ntp server other than 10.0.0.1>>
This use case uses regular expressions and contains two conditions.
- Condition-1 – Check for expected config & if not found remediate using Fix CLI.
Fix-cli Configuration :
ntp server 10.0.0.1
- Condition 2- Check for unwanted ntp-servers and remove them.
Fix-cli Configuration :
no ntp server 10.0.0.2 //Derived no ntp server 10.0.0.3 //Derived
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name – NTP_Common_Peer_Configuration
- Description
- Select the Policy and Click ‘+’ to create new Rule
- Rule Name – Check_NTP_Common_Peer_Configuration
- Navigate to Config Manager > Config Compliance -> Policies -> Rules
- Select a Rule & Provide the following information
- Vendor – Cisco Systems
- OS type – IOSXE
- Device Family – ALL
- Device Type – ALL
- OS Version – ALL
- Rule variables are not required for this scenario.
- Now fill the Conditions and Actions
Condition1
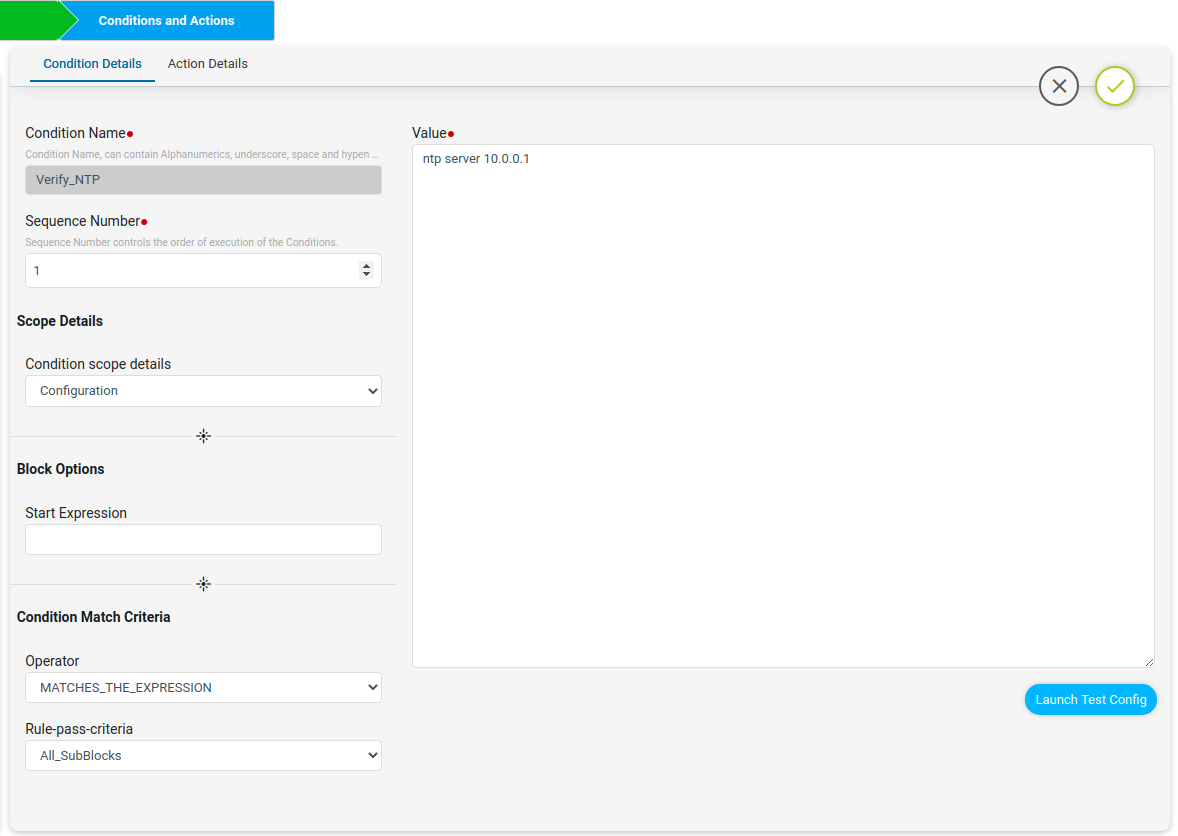
The Verify_NTP condition will check if the NTP server config is present in the device or not.
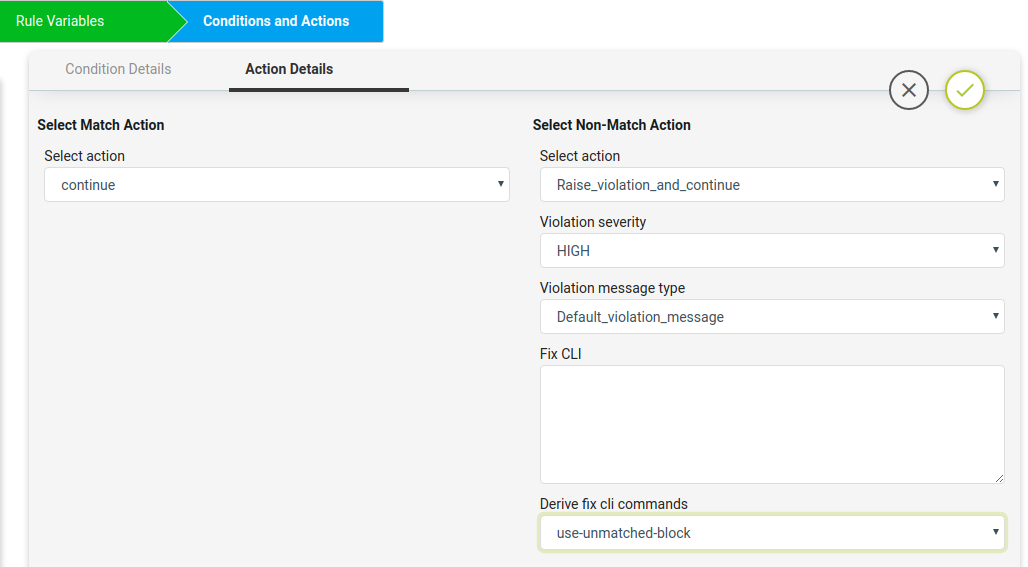
Here Non-Match Action can be done either using the commands in Fix CLI or using the Derive fix cli commands.
-
- Using the Fix CLI user needs to provide the configuration commands manually.
- Using the Derive Fix CLI Commands user needs to select the use_unmatched_block as shown below.
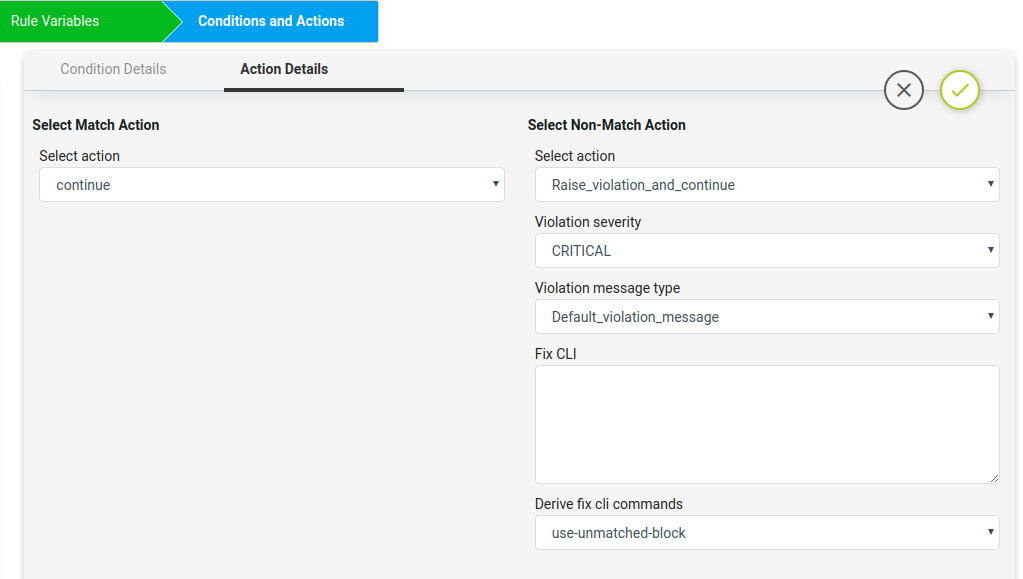
Here on Match Action it will Continue and on Non-Match Action the Derive fix cli commands uses the use-unmatched-block to remediate the device.
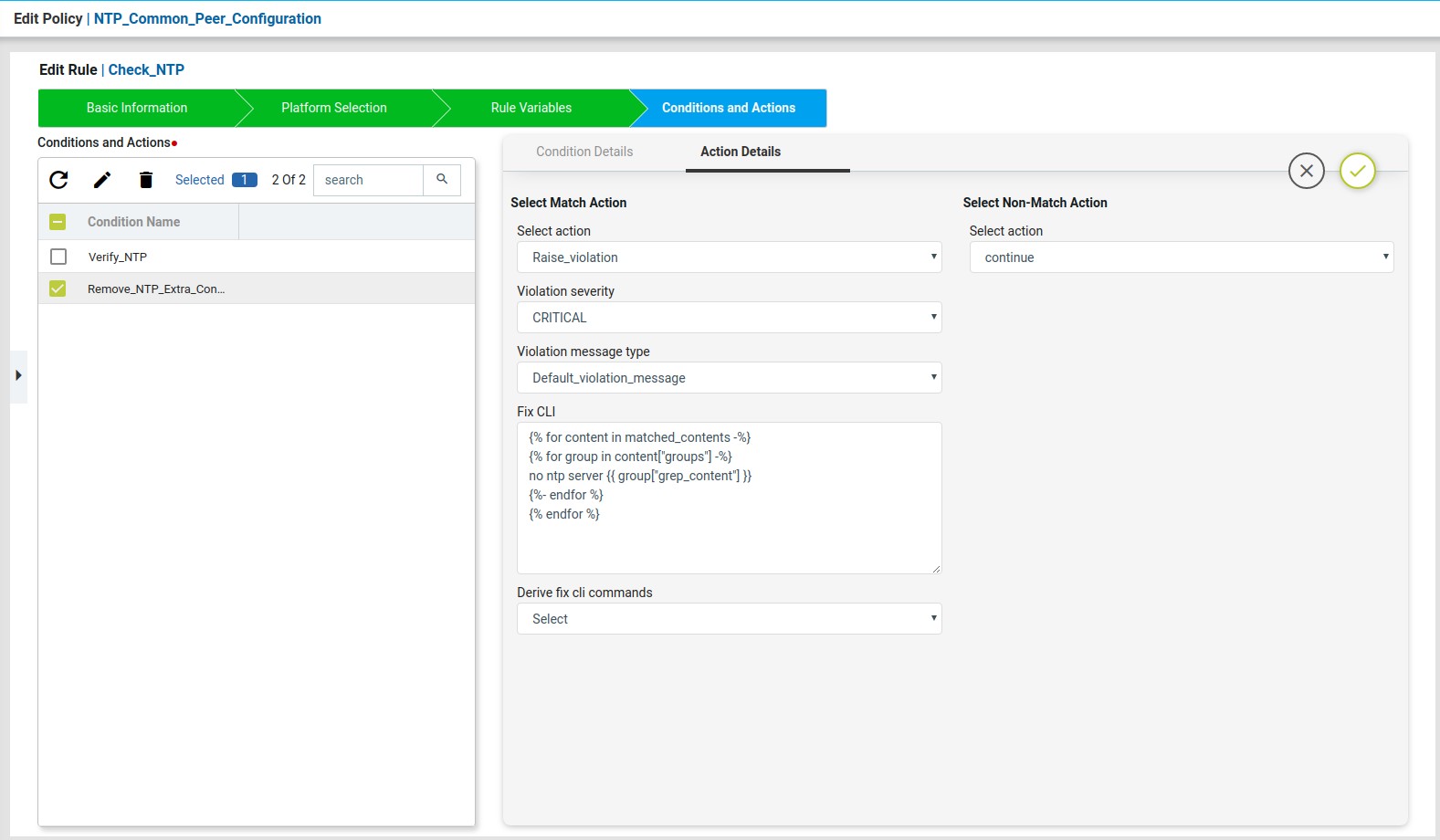
Condition2
Remove_NTP_Extra_Config condition will use the regex to match and capture the extra NTP server ip configured in the device other than the expected ip.
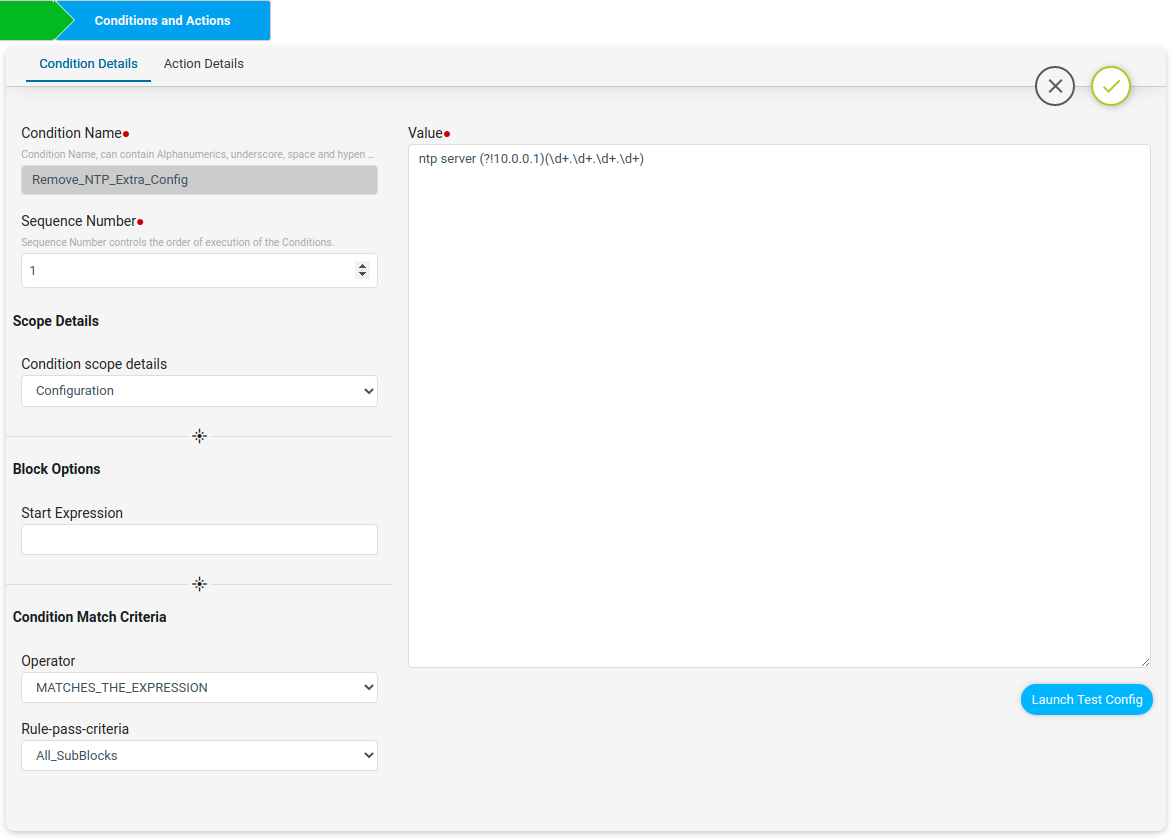
The extra NTP server ip captured will be stored in the backend data structure which is shown in the Test Results tab.
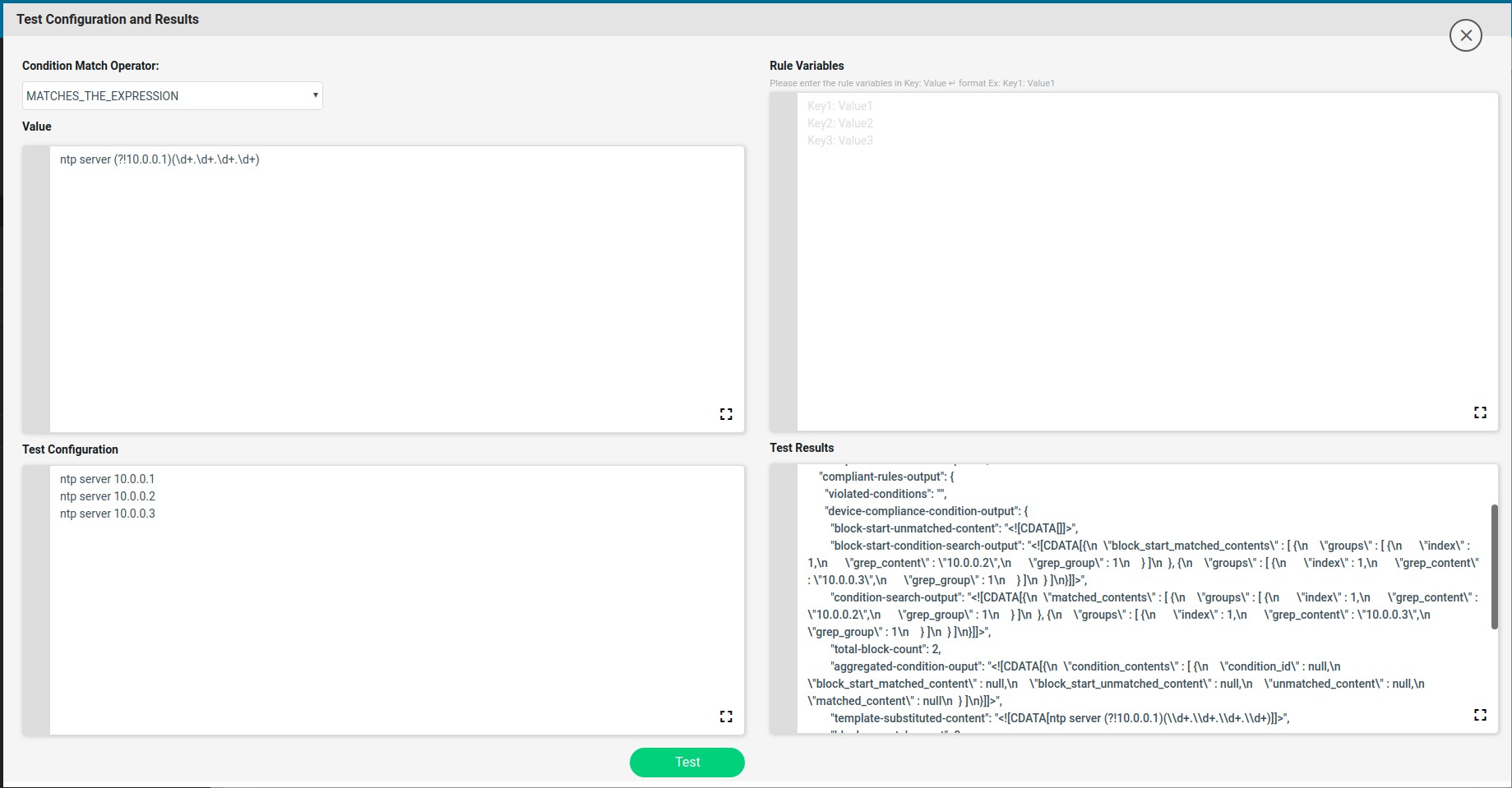
The captured data will be stored in the condition-search-output
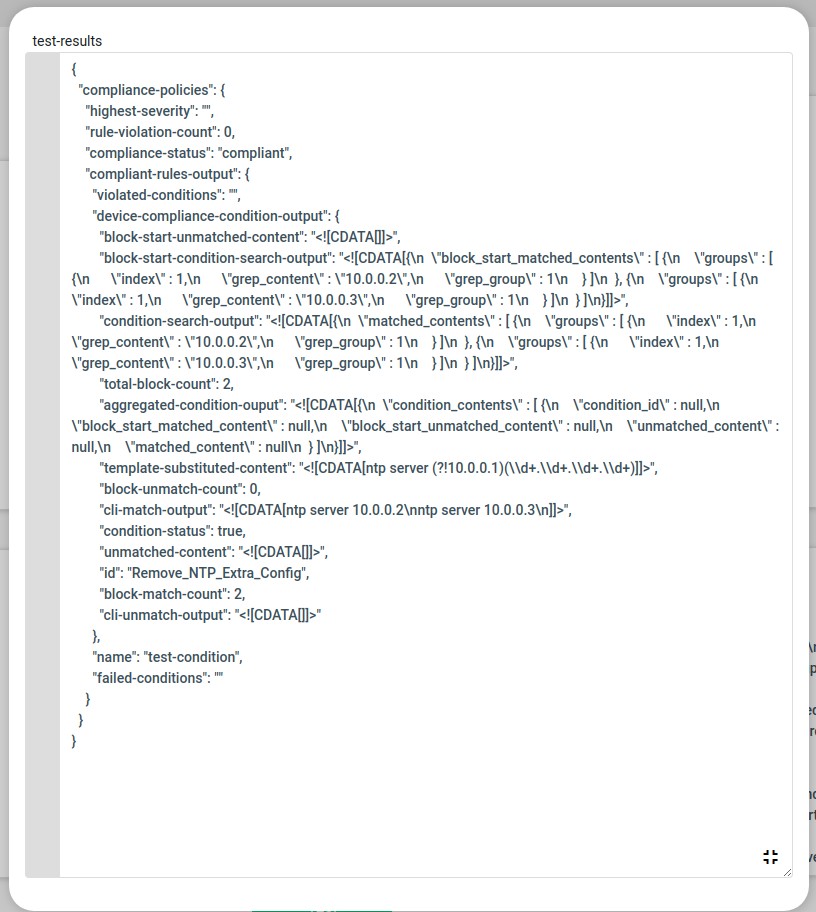
On Match Action write a jinja2 configuration template to remove the extra ip’s captured using the above test-result data structure.
Finally if different NTP servers are present on the device, for Non-Compliant device Fix CLI will show up as below

Scenario 3: Interface configuration check
Scenario: All devices in the network should have a specific interface in no shutdown state with auto negotiation enabled. The interface block can have extra configuration commands under it but should be in no shutdown state and auto negotiation enabled.
Platform:
Cisco IOS-XE
Expected Configuration:
interface {{ interface_name }} no shutdown
negotiation auto
Fix-CLI Configuration:
interface {{ interface_name }} no shutdown
negotiation auto
This use case is an interface block configuration having rule variables. In this use case as no shutdown is generally not visible on device running config, we will check whether the interface is in shutdown or not. If shutdown it will remediate to no shutdown.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name – Interfaces
- Description
- Select the Policy and Click ‘+’ to create new Rule
- Rule Name – Check_Interfaces
- Navigate to Config Manager > Config Compliance -> Policies -> Rules
- Select a Rule & Provide the following information
- Vendor – Cisco Systems
- OS type – IOSXE
- Device Family – ALL
- Device Type – ALL
- OS Version – ALL
- Now create the Rule variables for this scenario.
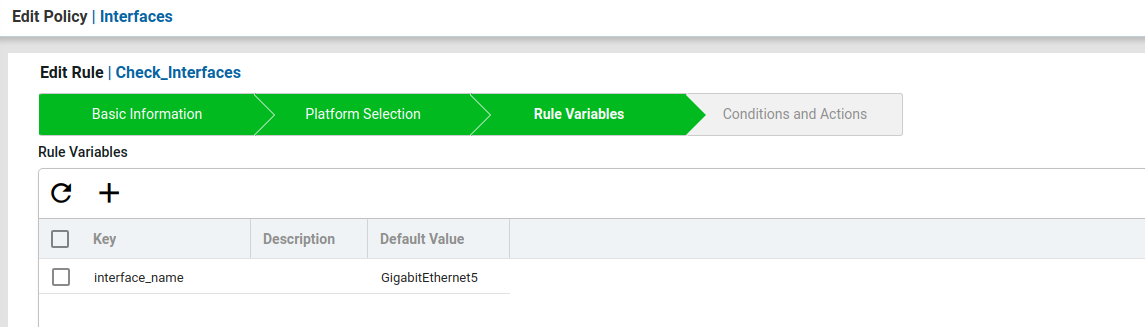
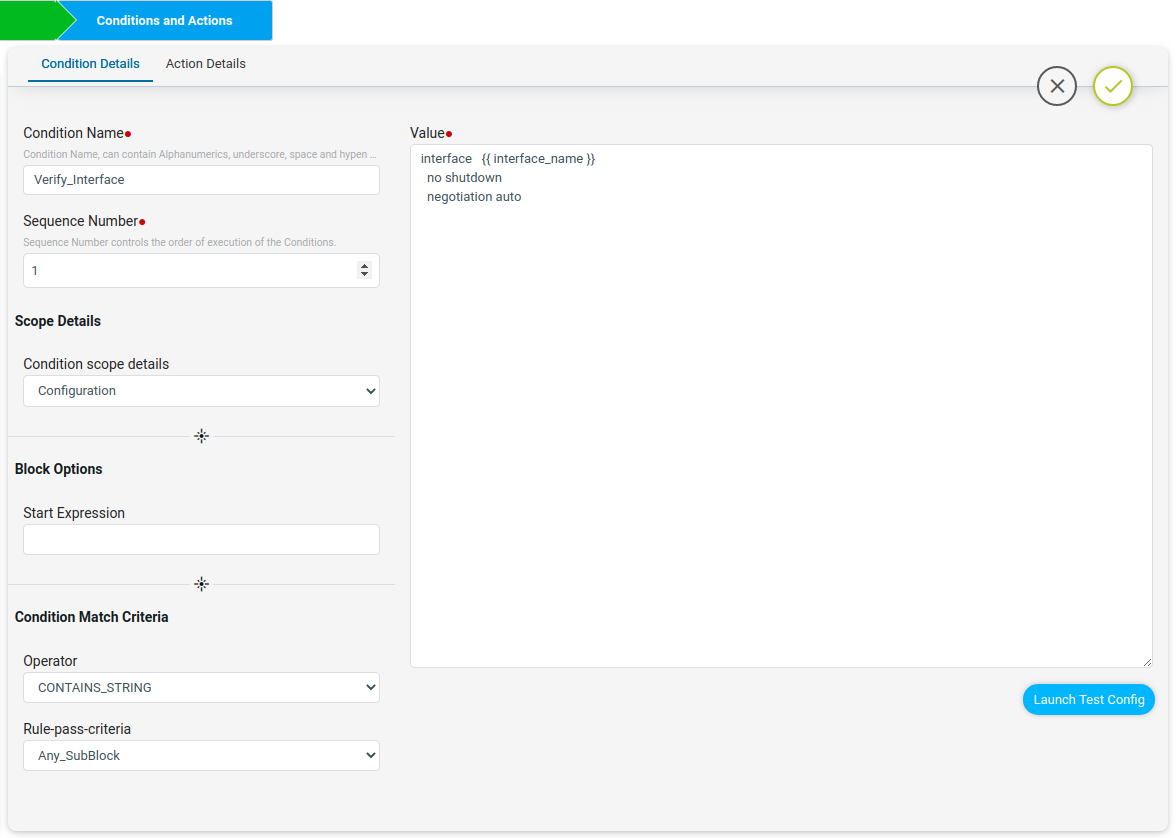
In the policy we will have a jinja rule variable interface_name. Here Verify_Interfaces condition will check if the interface block config is present in the device or not and under that interface if no shutdown and negotiation auto is present.
For Scenario3 Condition Match Operator as CONTAINS_STRING will check whether the device configuration contains condition value or not. If device configuration contains value, the result will be Compliant, else Non-Compliant.
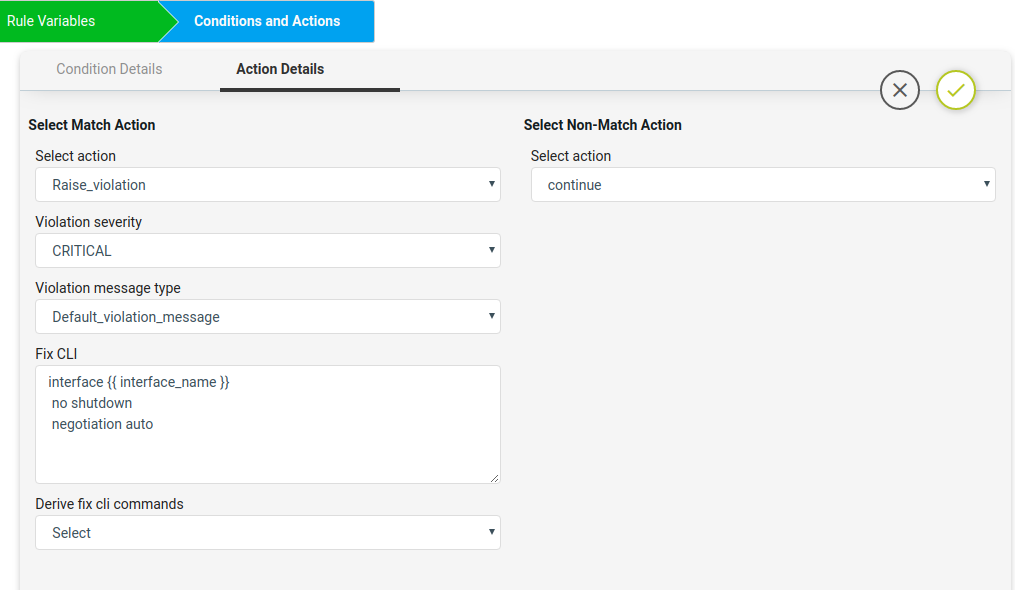
Here on Non-Match Action select Continue and on Match Action add Fix cli commands to remediate on the device
 For Non-Compliant devices Fix CLI will show up later-on as below.
For Non-Compliant devices Fix CLI will show up later-on as below.
Scenario 4: Enforce VTY Session Timeouts
Scenario: All devices in the network should contain the network admin preferred VTY
session-timeout and exec-timeout on all vty lines. If VTY session-timeout and exec-timeout is not configured on the device or mis-match with the network admin preferred timeouts, ATOM CLI compliance can configure the devices with the user preferred VTY timeouts on all the vty lines.
In this example we are considering the VTY session-timeout and exec-timeout as 10 sec.
Platform:
Cisco IOS-XE
Expected Configuration:
line vty (.*)
session-timeout 10
exec-timeout 10 10
Fix-CLI Configuration:
line vty <>
session-timeout 10
exec-timeout 10 10
This use case is using the regex and rule variables and uses jinja2 template for fix-cli configuration.
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name – Enforce_VTY_Session_Timeouts
- Description
- Select the Policy and Click ‘+’ to create new Rule
- Rule Name – Check_Enforce_VTY_Session_Timeouts
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules
- Select a Rule & Provide the following information
- Vendor – Cisco Systems
- OS type – IOSXE
- Device Family – ALL
- Device Type – ALL
- OS Version – ALL
- Now create the Rule variables for this scenario.
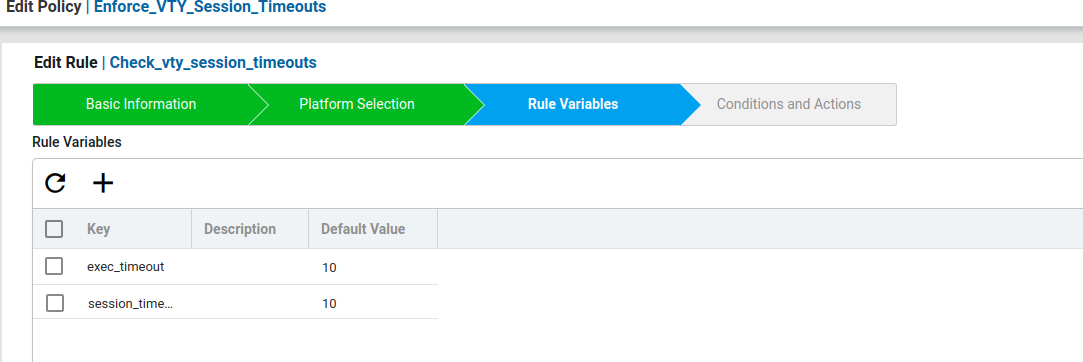
Here created user defined rule variables vty_exec_timeout and vty_session_timeout with default timeout as 10. These rule variables will be used in the condition value.
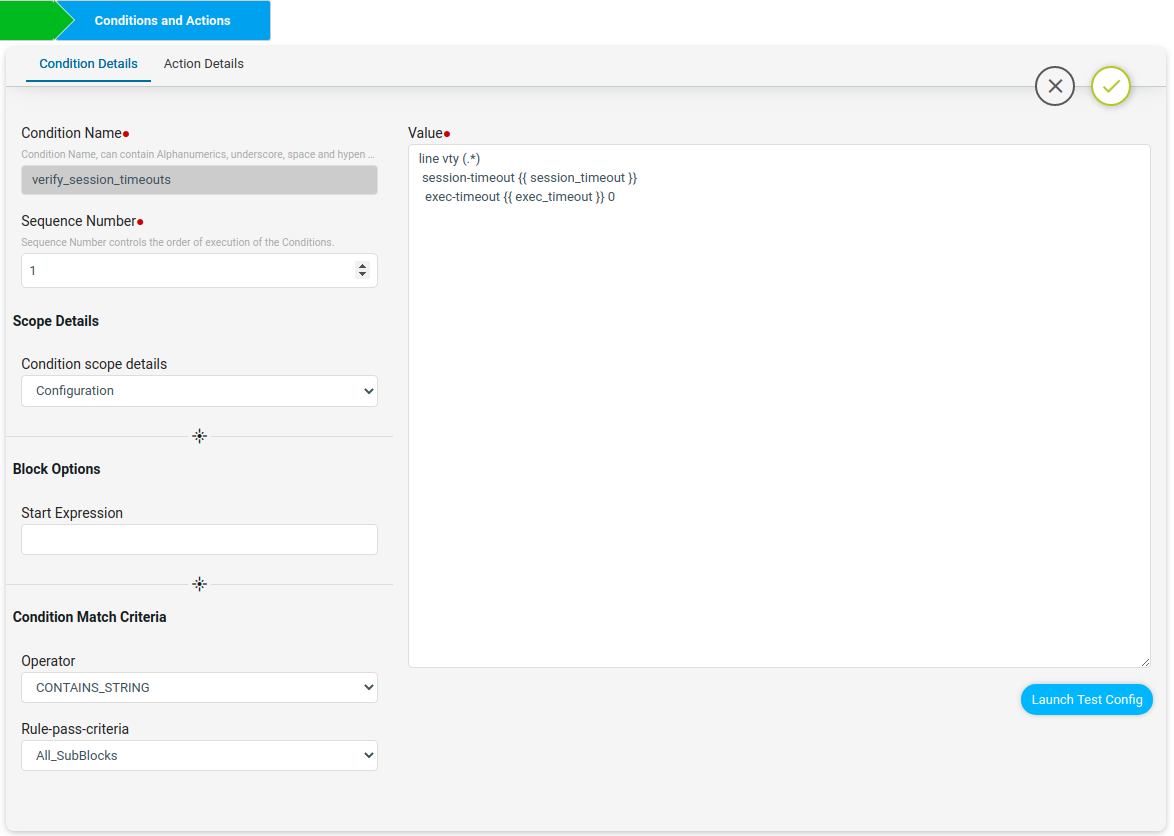 The verify_session_exec_timeouts condition will check whether the device in the network is configured with user preferred VTY timeouts or not.
The verify_session_exec_timeouts condition will check whether the device in the network is configured with user preferred VTY timeouts or not.
Here under Condition Match Criteria the Operator used was CONTAINS_STRING to check for session-timeout and exec-timeout in line vty config.
Here Rule-pass-criteria used All_SubBlocks to check the condition config in all line vty configurations of the device. If all the line vty is matching with the condition then compliant. If any of the line vty is not matching then non-compliant.
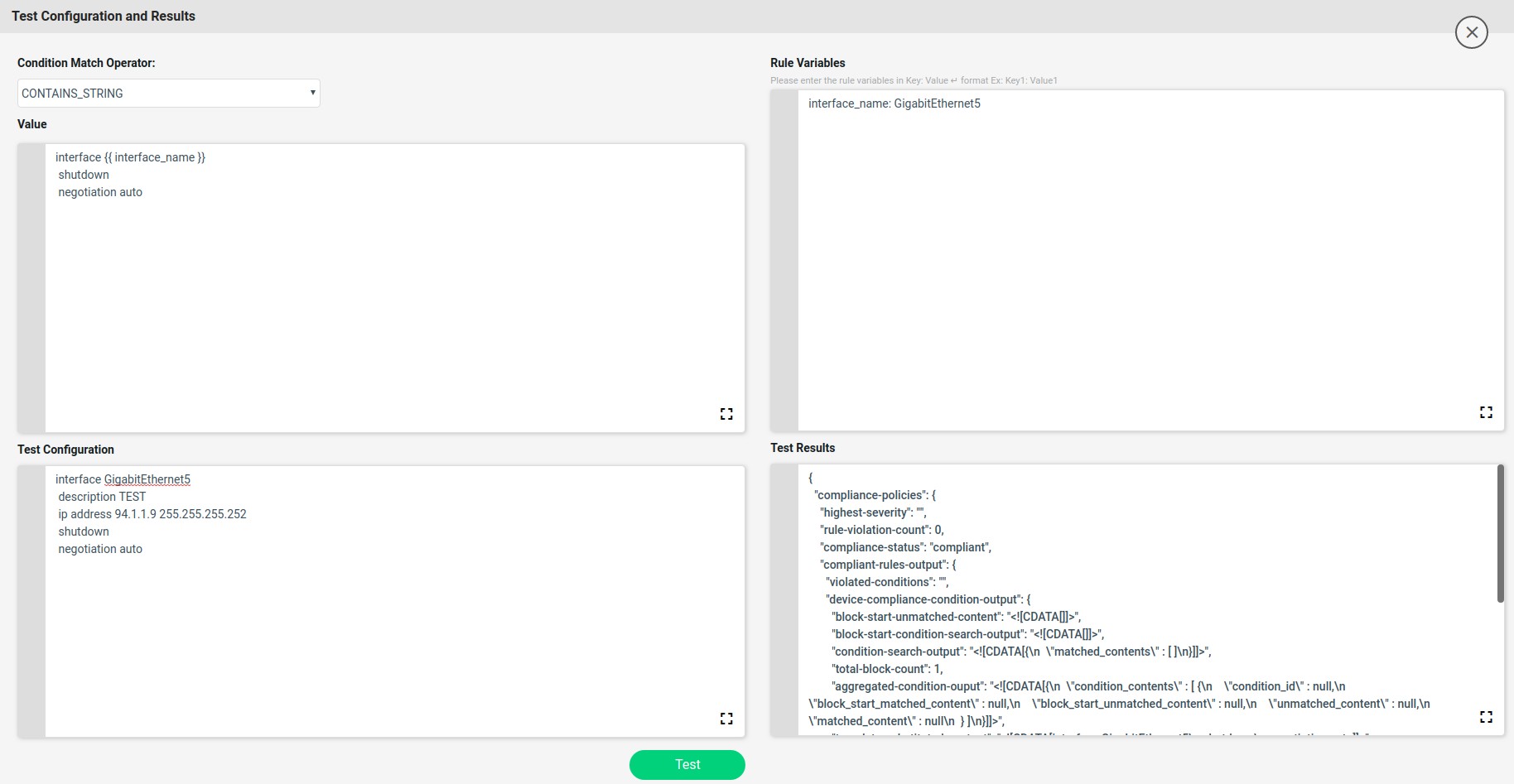
The launch Test Config will check values with the Test configuration and gives the Test Result whether compliant or not.
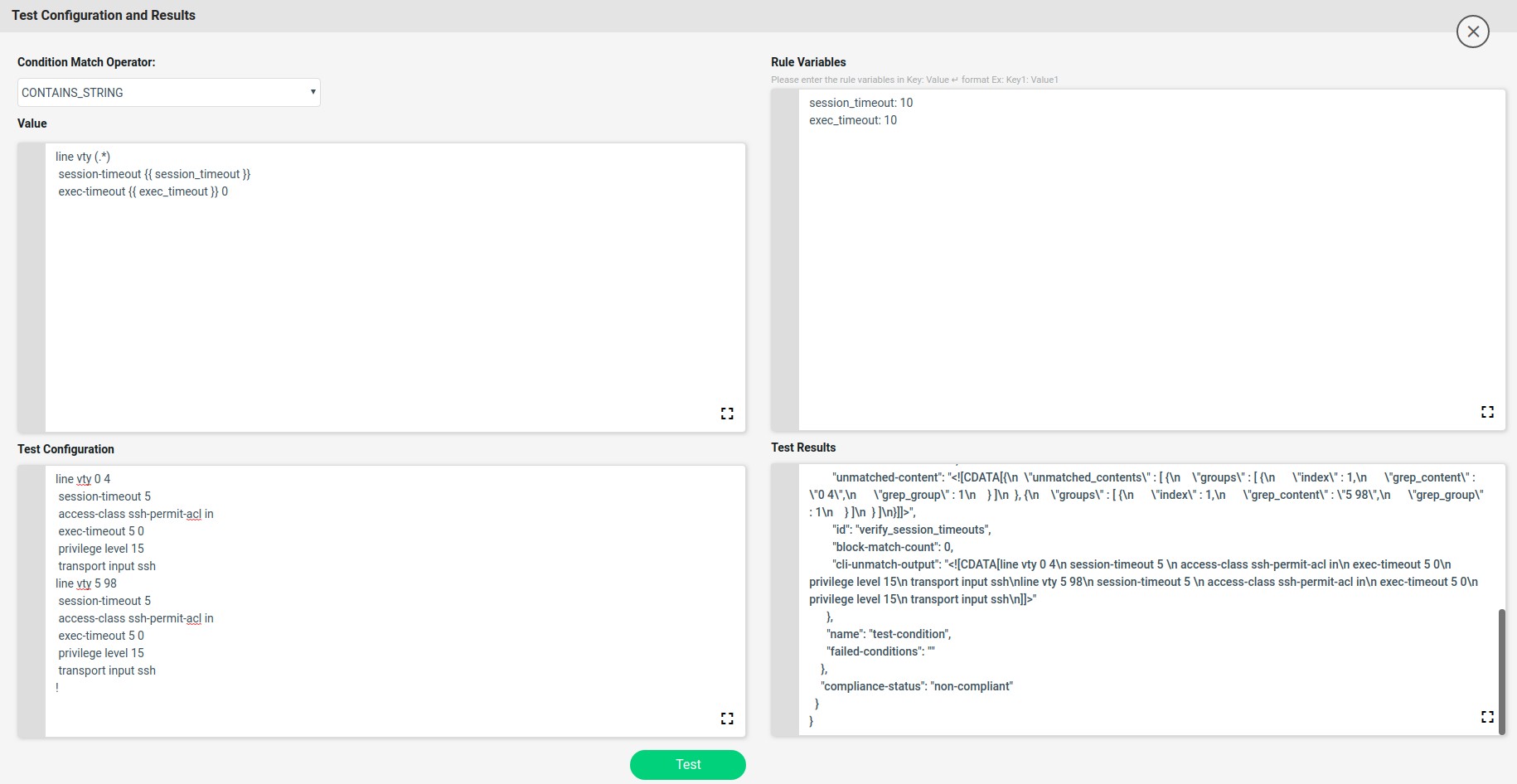
Here the unmatched line vty will be captured and stored in the backend data structure. The captured data structure maximizes the view shown below.

On Match action will continue and on Non-Match Action fix-cli will use the jinja2 template configuration written based on the above captured data structure.
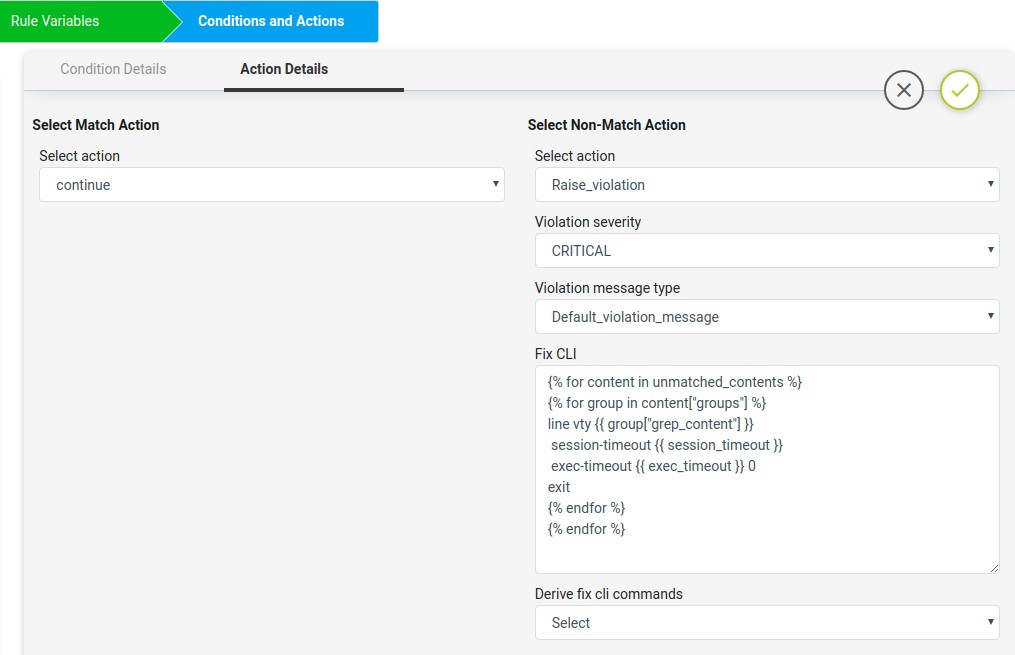
 The Non-compliant device fix-cli configurations derived from above jinja2 snippet will look like below.
The Non-compliant device fix-cli configurations derived from above jinja2 snippet will look like below.
Scenario 5: Enforce OSPF Router Id as Loopback0
Scenario: All devices in the network should contain the OSPF router-id configured with loopback0 ip address. If OSPF router-id is not configured on the device it will configure the OSPF router-id with the value of loopback0 ip address on the devices.
Platform:
Cisco IOS-XE
Expected Configuration:
interface Loopback0
ip address 45.45.45.5 255.255.255.255
!
router ospf 100
router-id 45.45.45.5
Fix-CLI Configuration:
router ospf 100
router-id 45.45.45.5
This use case is using the regex and contains two conditions.
- First condition is to capture and store loopback0 ip address. It will not have a fix-cli configuration as the intention of the condition is to capture loopback0 ip address. Fix-cli Configuration :
<< no fix cli configuration >>
- Second condition will check whether the OSPF router id is the same as the first condition’s captured loopback0 ip address or not. if not matching then it will configure the OSPF router id with loopback0.
Fix-cli Configuration : router ospf 100
router-id 45.45.45.5
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name – Enforce_OSPF_Router_Id_as_Loopback
- Description
- Select the Policy and Click ‘+’ to create new Rule
- Rule Name – Check_OSPF_Router_Id_Cisco
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules
- Select a Rule & Provide the following information
- Vendor – Cisco Systems
- OS type – IOSXE
- Device Family – ALL
- Device Type – ALL
- OS Version – ALL
- Rule variables are not required for this scenario.
- Now fill the Conditions and Actions
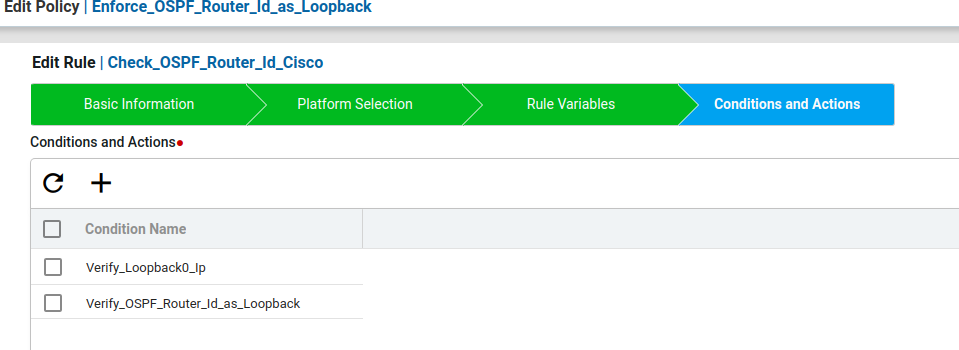
Condition1
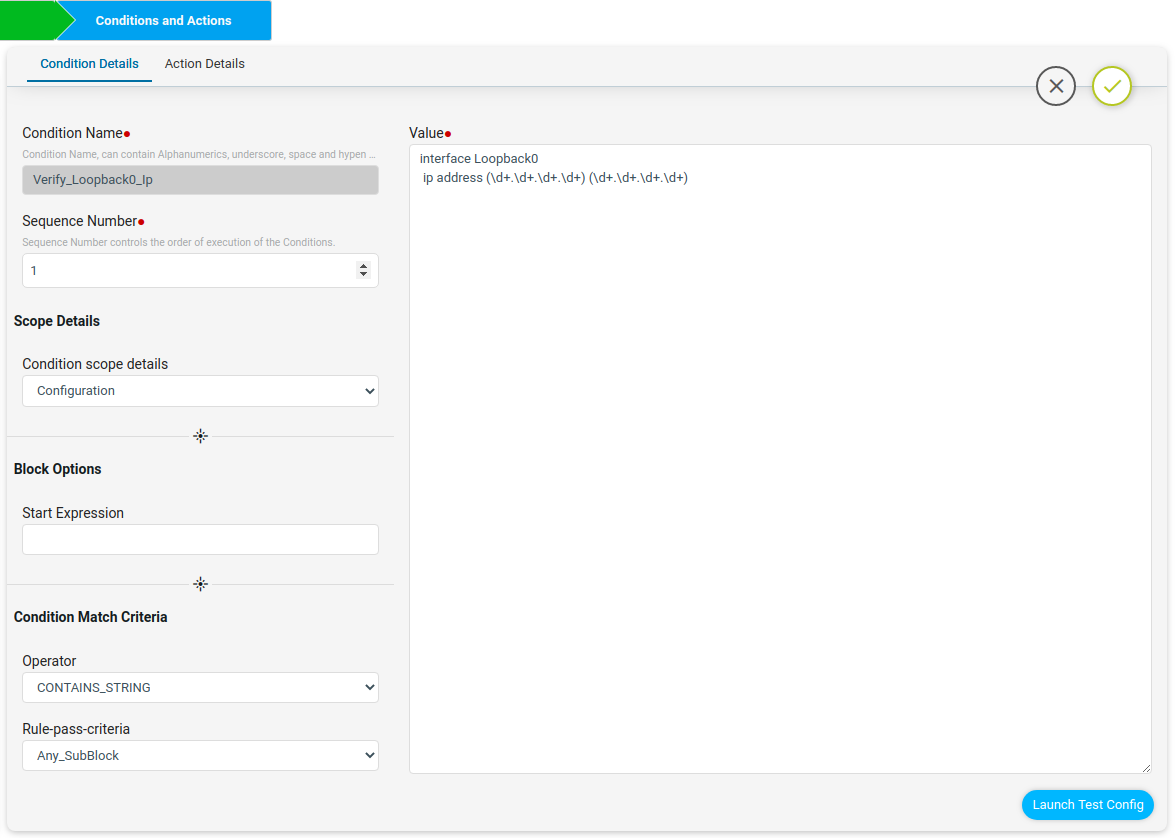
Another way of writing the above block configuration using the Block Options Start Expression is shown below.
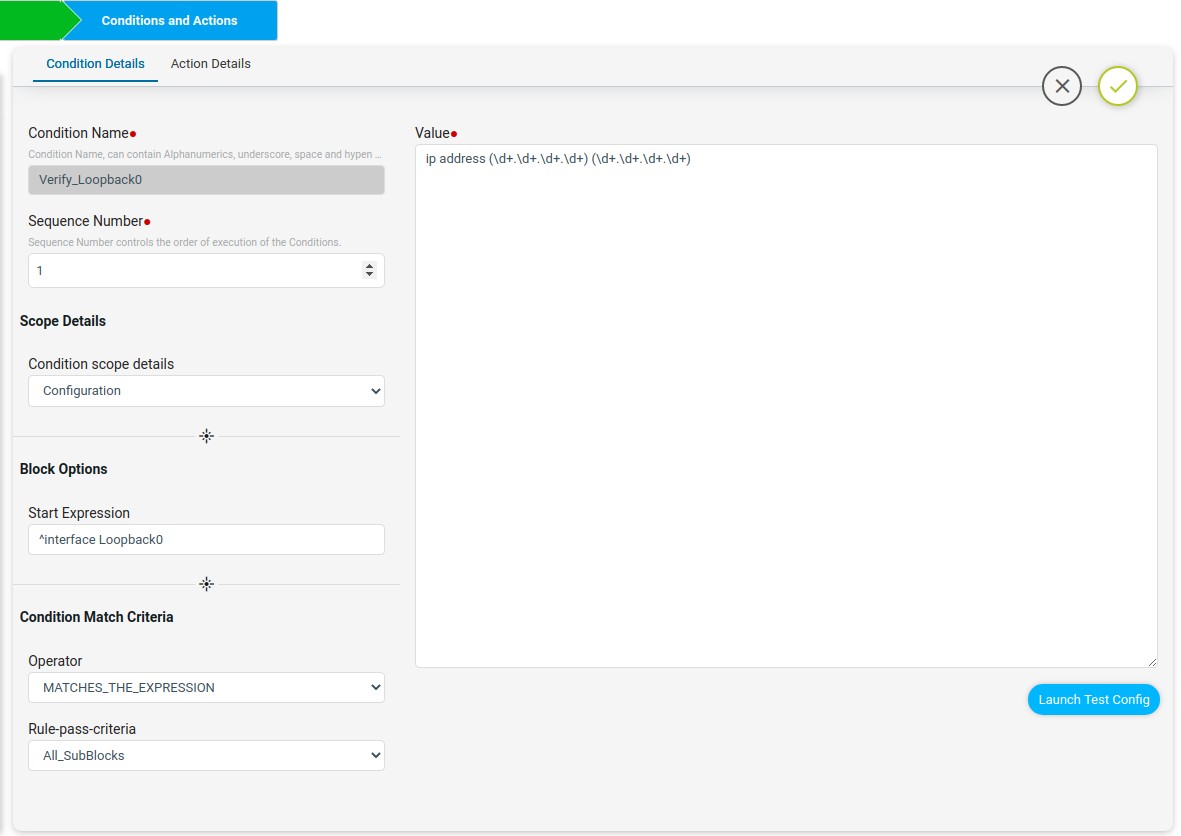 The first line “interface Loopback0” can be written in the start Expression with regex symbol ^ to indicate the block starts with interface Loopback0. The remaining configuration lines can be written in value.
The first line “interface Loopback0” can be written in the start Expression with regex symbol ^ to indicate the block starts with interface Loopback0. The remaining configuration lines can be written in value.
The launch test config will check the condition value with the Test configuration and will give the Test Result. Here the captured loopback0 ip address will be stored in the backend data structure as shown below.
The Test result in maximize view is shown below. This output will be used in condition2.

For Non-Match Action violation is being raised and fix-cli is having no commands as this condition is to capture the loopback0 ip.
Condition2
The Verify_OSPF_Router_Id_as_Loopback condition will check whether the OSPF router id is the same as the first condtion’s captured loopback0 ip address or not. if not matching then in fix-cli it will configure the OSPF router id with loopback0.
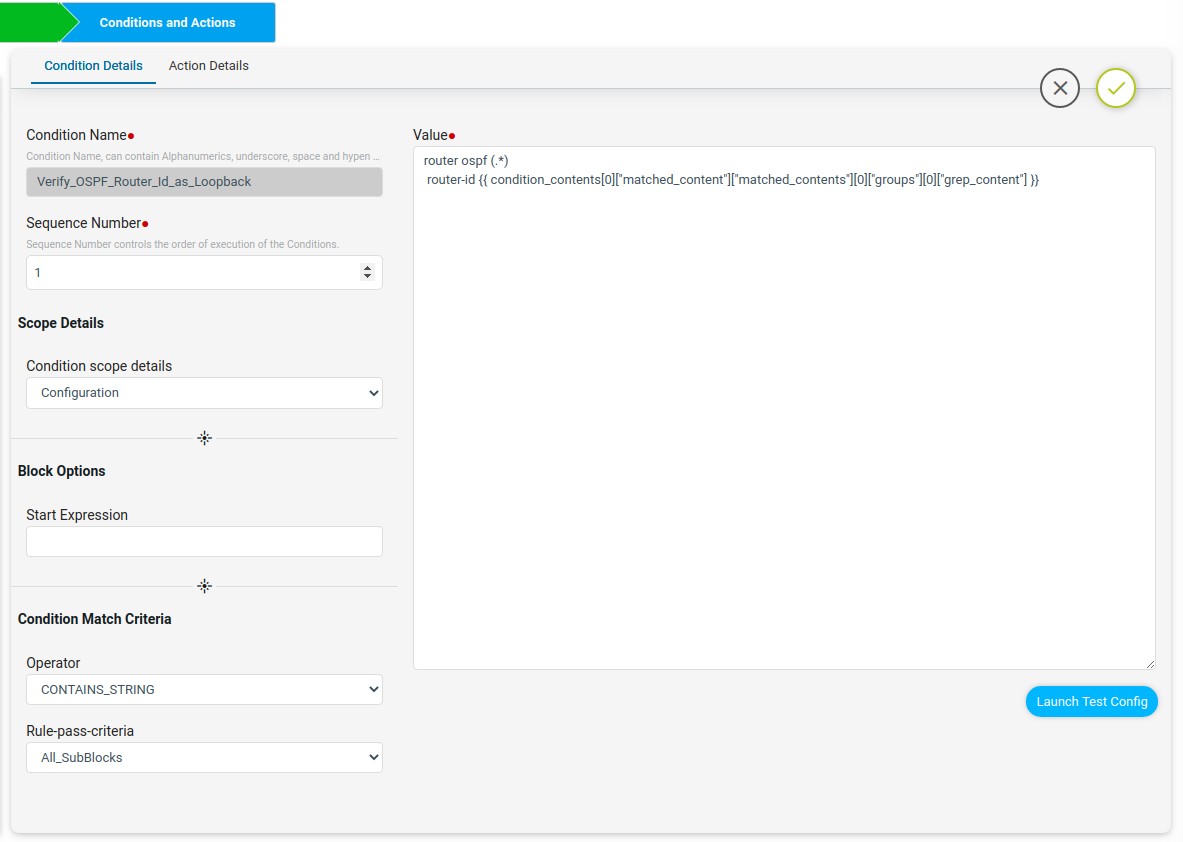
On Match Action it will continue. On Non-Match Action it will use the jinja2 template configuration in fix-cli to configure the OSPF router id with loopback0 ip.
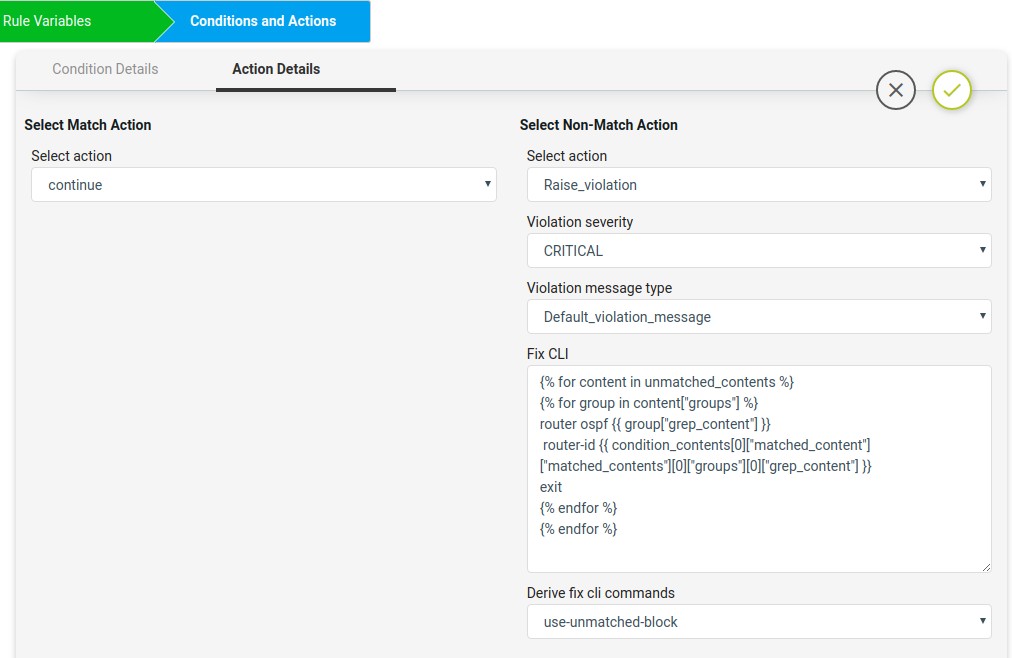
The Non-compliant device fix-cli configurations from the jinja2 template configuration is given below.

Scenario 6: BGP TTL Hop-count
Scenario: All devices in the network should contain the network admin preferred BGP
ttl-security hops. If hops is not configured on the device or mis-match with the network admin preferred ttl-security hops, ATOM CLI compliance can configure the devices with the user preferred hops.
In this example we are considering the ttl-security hops as 5.
Platform:
Cisco IOS-XE
Expected Configuration:
router bgp 65535
bgp log-neighbor-changes neighbor 2.3.2.6 ttl-security hops 5
Fix-CLI Configuration:
router bgp 65535
bgp log-neighbor-changes neighbor 2.3.2.6 ttl-security hops 5
This use case is using the regex and rule variables and contains two conditions.
- First condition is to match the block. It will not have a fix-cli configuration as the intention of the condition is to match the block.
Fix-cli Configuration :
<< no fix cli configuration >>
- Second condition will check whether the BGP ttl-security hops is in the first condition’s matched block or not. if not matching in the block then it will configure the BGP hops. Fix-cli Configuration :
router bgp 65535
neighbor 2.3.2.6 ttl-security hops 5
Steps:
-
- Navigate to Resource Manager > Config Compliance -> Policies
- Click ‘+’ to create new Policy and provide the following information
- Policy Name – BGP_TTL_Hop_Count
- Description
- Select the Policy and Click ‘+’ to create new Rule
- Rule Name – Check_BGP_TTL
- Navigate to Resource Manager > Config Compliance -> Policies -> Rules
- Select a Rule & Provide the following information
- Vendor – Cisco Systems
- OS type – IOSXE
- Device Family – ALL
- Device Type – ALL
- OS Version – ALL
- Now create the Rule variables for this scenario.
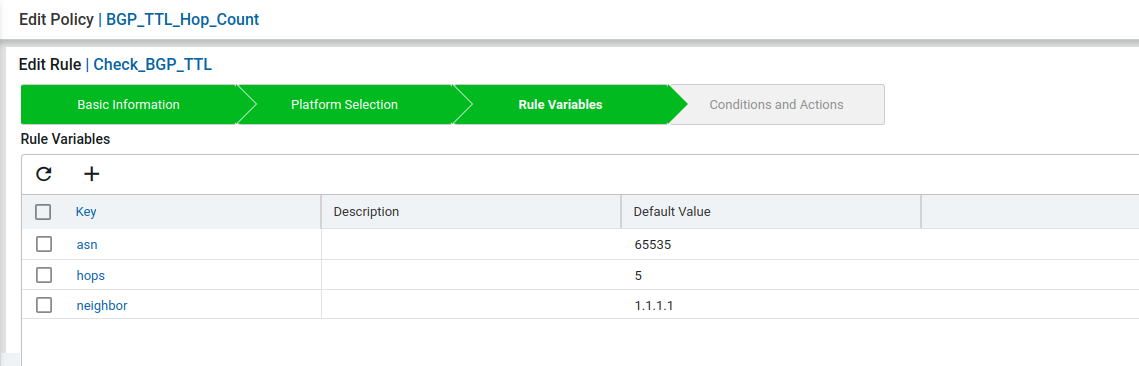
Condition1
The first line “router bgp (.*)” to be written in the start Expression with regex to indicate the block starts with router bgp. The remaining configuration lines can be written in value.
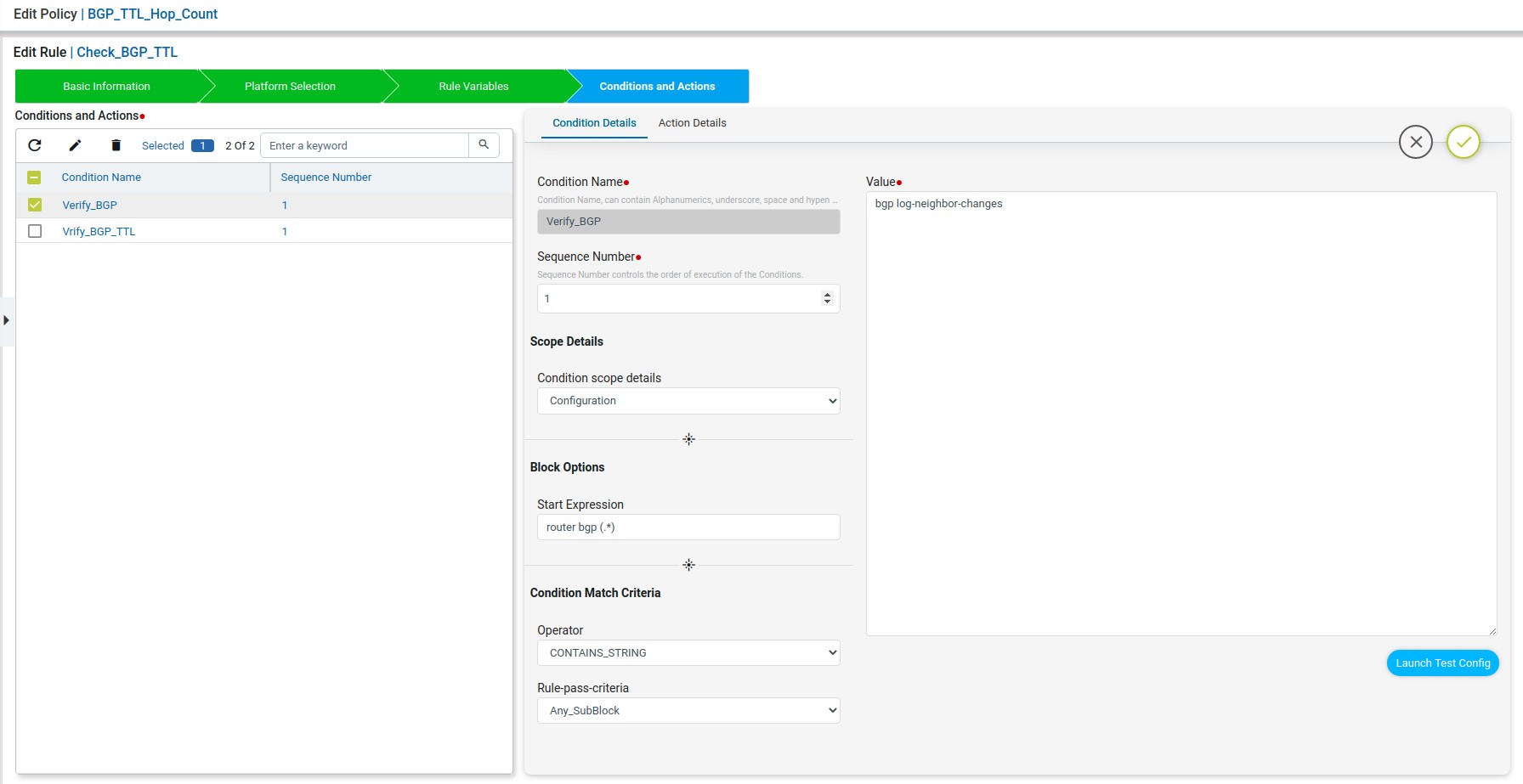
On Match Action execution continues to the next condition. On Non-Match Action it will raise a violation and continue next condition. The “Fix-CLI” for the condition was written based on the test results obtained from “Launch Test Config”.
When the start Expression is used the regex captured data will be stored in “condition_contents” of “aggregated-condition-ouput” in test results.
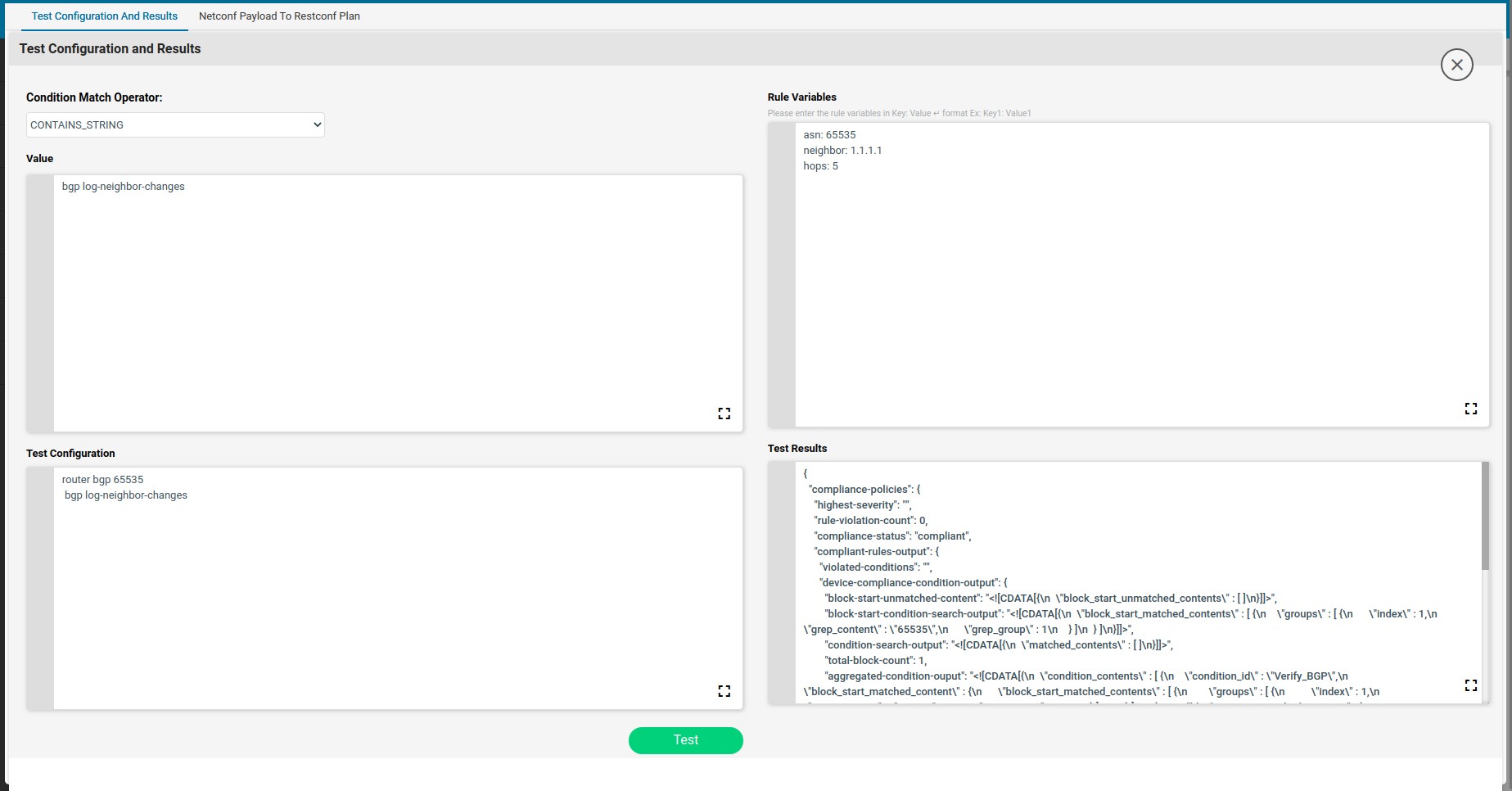

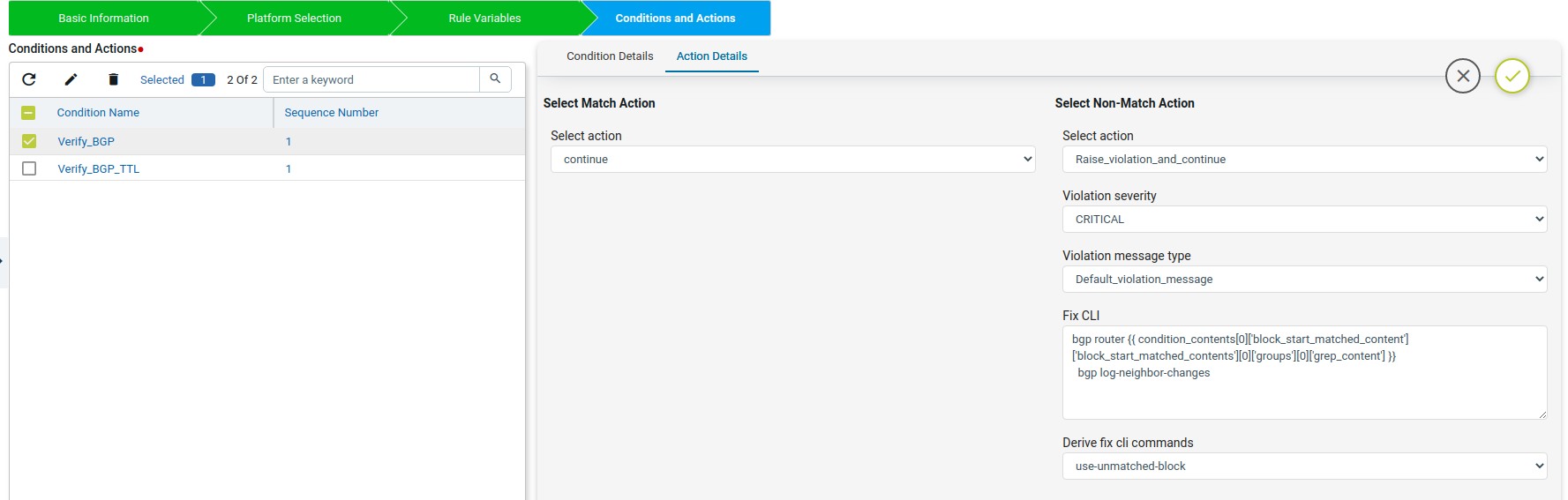
Condition2
The Verify_BGP_TTL condition will check whether the router bgp block config matched in the previous condition has the ttl-security hops or not. if not matching then in fix-cli it will configure the ttl-security hops.
This condition uses the condition scope details as Previously_Matched_Blocks to check on previous condition matched block.
YANG Compliance
Note: In order to use Yang Compliance make sure that the config-snapshot is provided in the Credential profile, which lets ATOM to parse the configuration and store it. For more information on Credential profile please refer to credential profile section in ATOM User guide.
For Yang based Configuration Compliance, make sure to select the option of Inventory_Data for Condition scope during Compliance Policy creation. This gives two ways of defining the Condition Match Criteria
-
- Xpath Expressions
- XML Template Payload
Policy creation with Xpath Expressions
-
- Within Condition Match Criteria select “Matches_the_Xpath_Expression”
/”Doesn’t_Matches_the_Xpath_Expression” option for Inventory Operator field
-
- The Fix Mutation Payload is in Netconf xml RPC format written using the XML template details for the yang parsed entities.
Navigate to Resource Manager > Config Compliance > Policy > + (Add Policies)
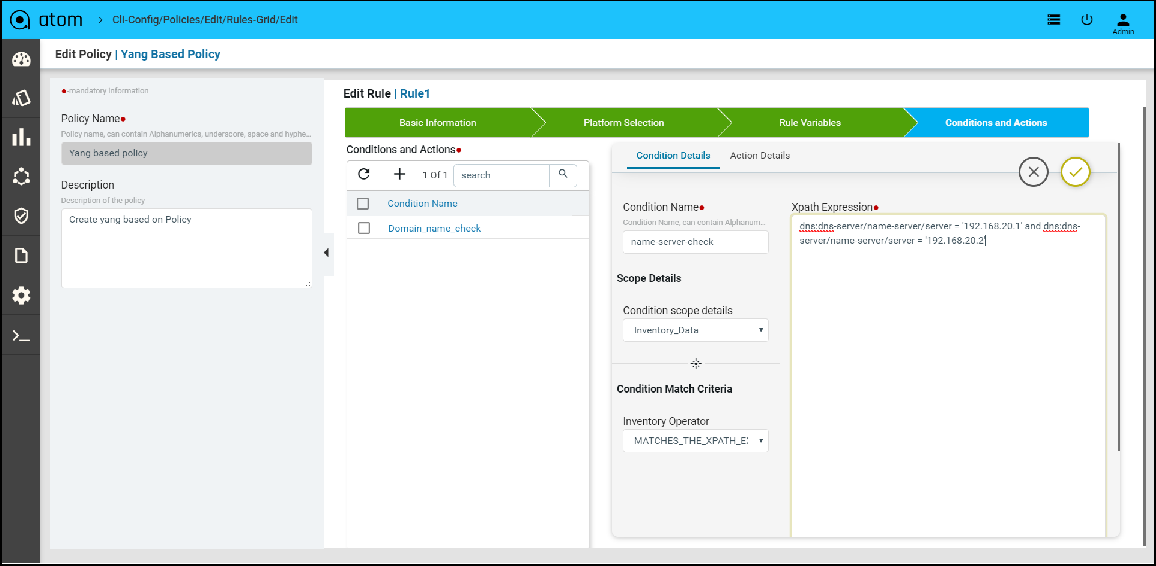
Few examples
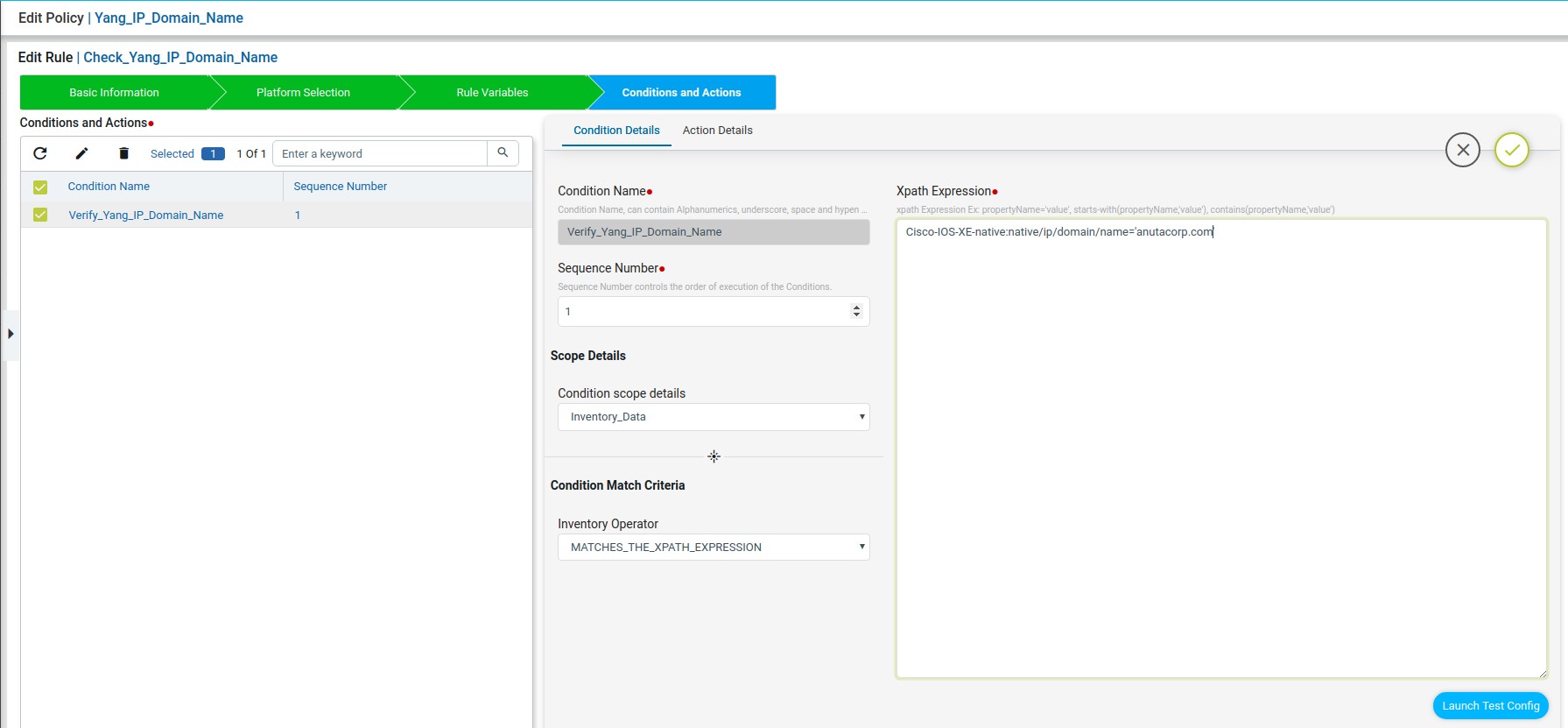
Scenario 7: IP Domain Name
In this example we are looking for the domain name as anutacorp.com across all devices in the lab using X-path expression.
Xpath Expression:
Fix Mutation Payload:
Note: we can use ATOM_DEVICE_ID or inputDeviceId for substituting the deviceId.
Defining Xpath Expression
Defining Fix Payload
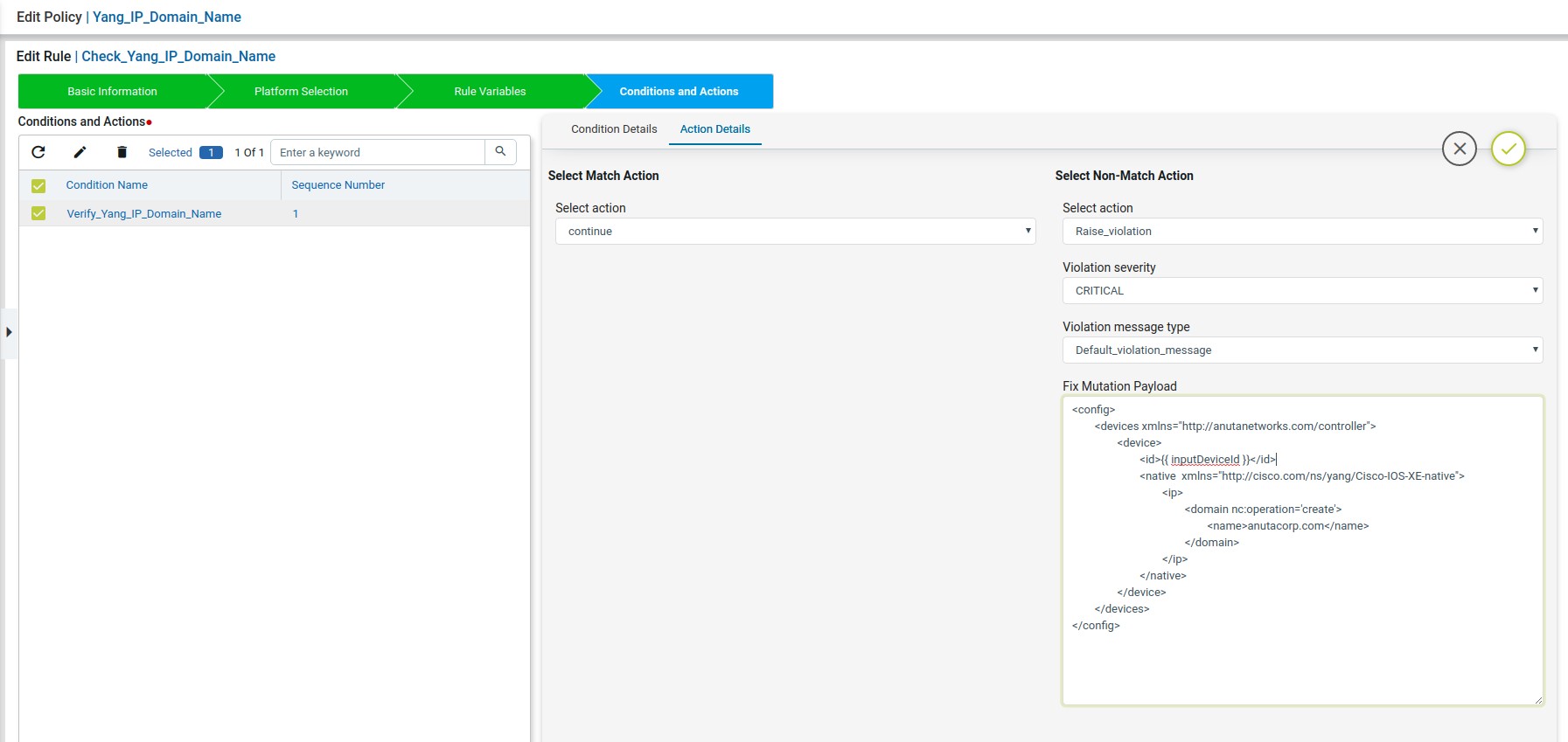
Fix Configuration Display in Remediation
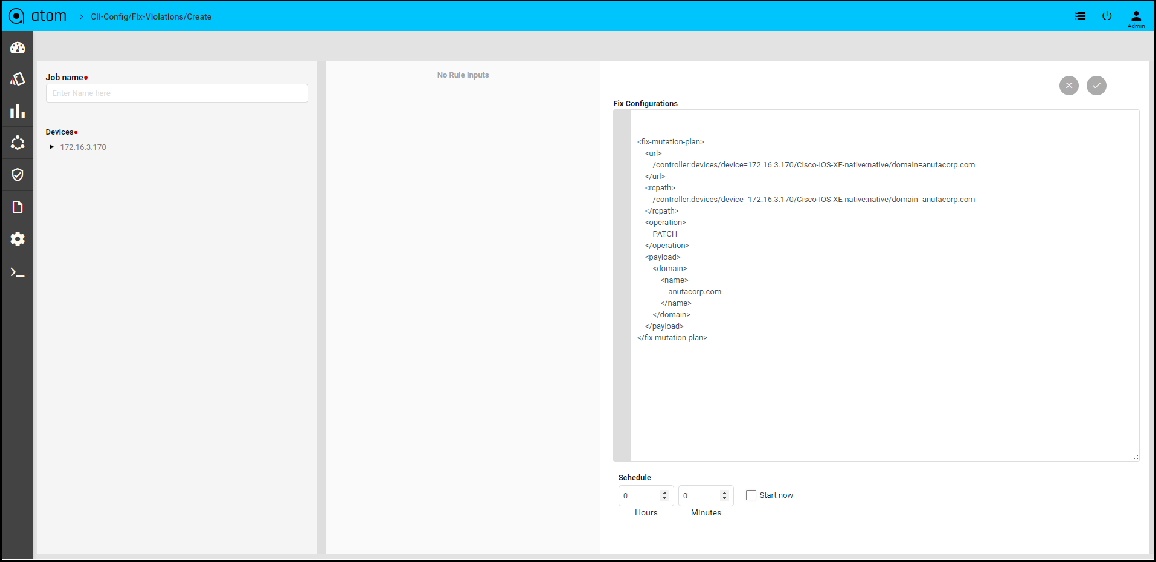
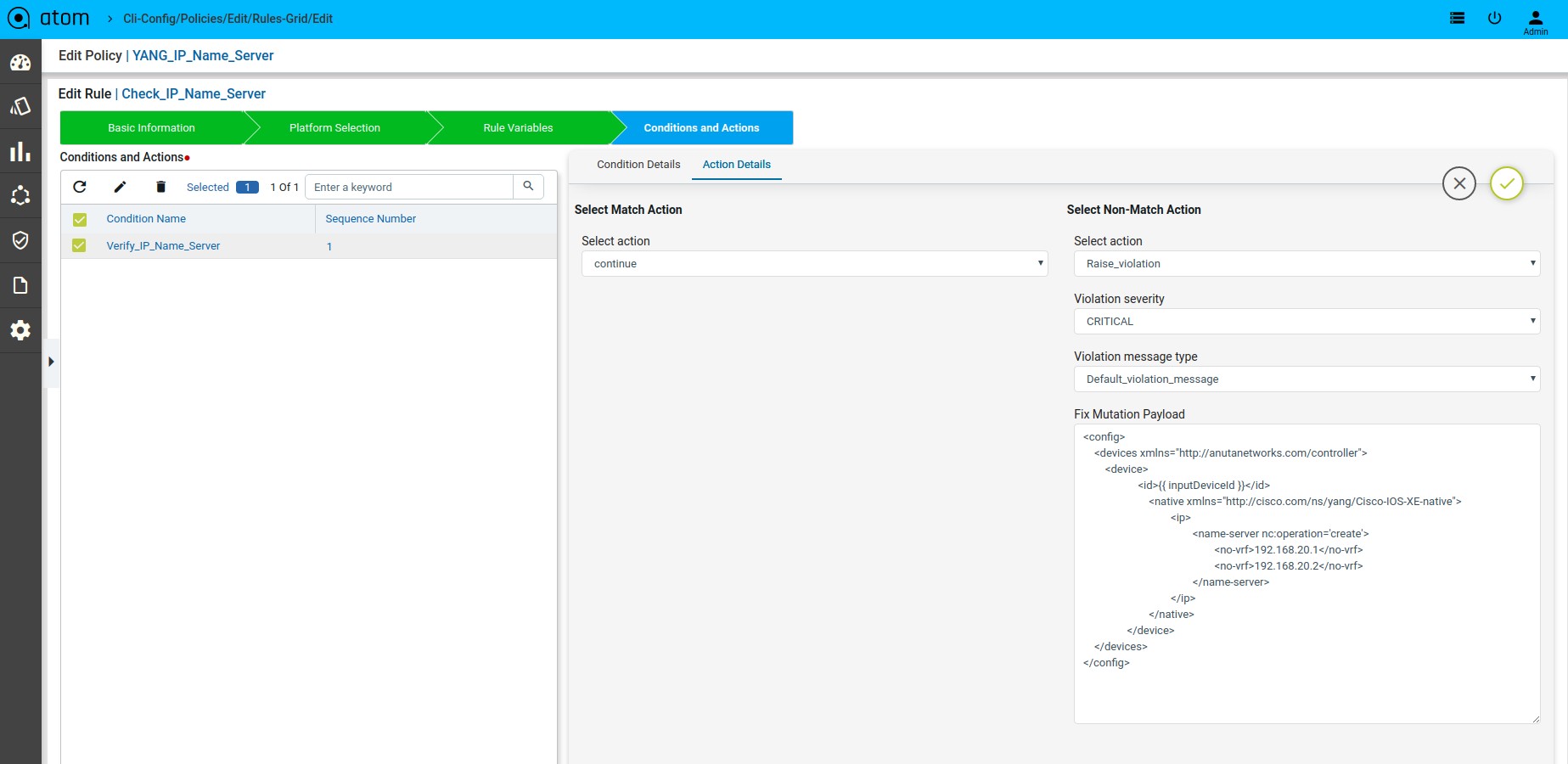
Scenario 8: IP Name-server check
Xpath Expression:
Fix Mutation Payload:
Defining Xpath Expression
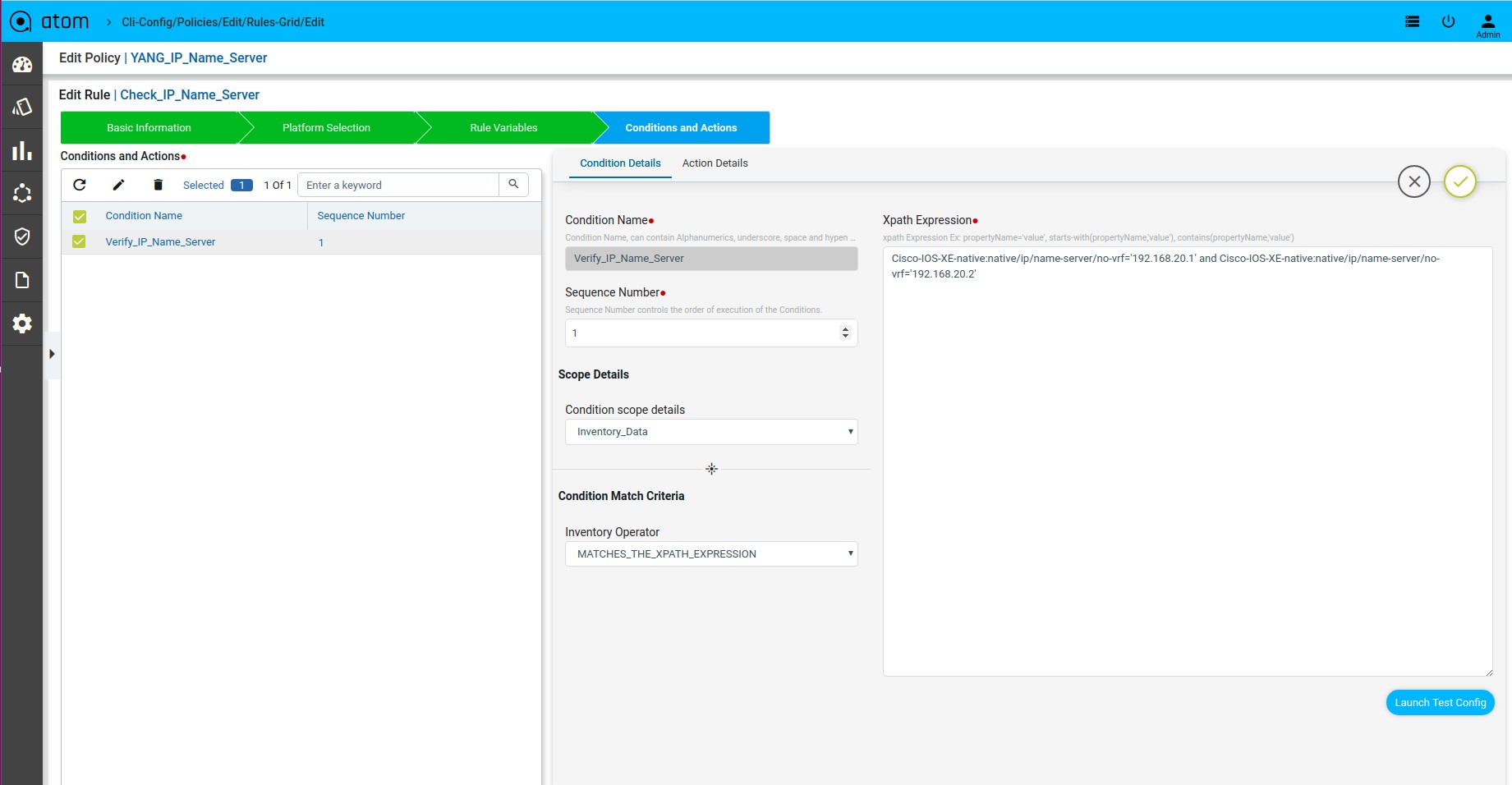
Defining Fix Payload
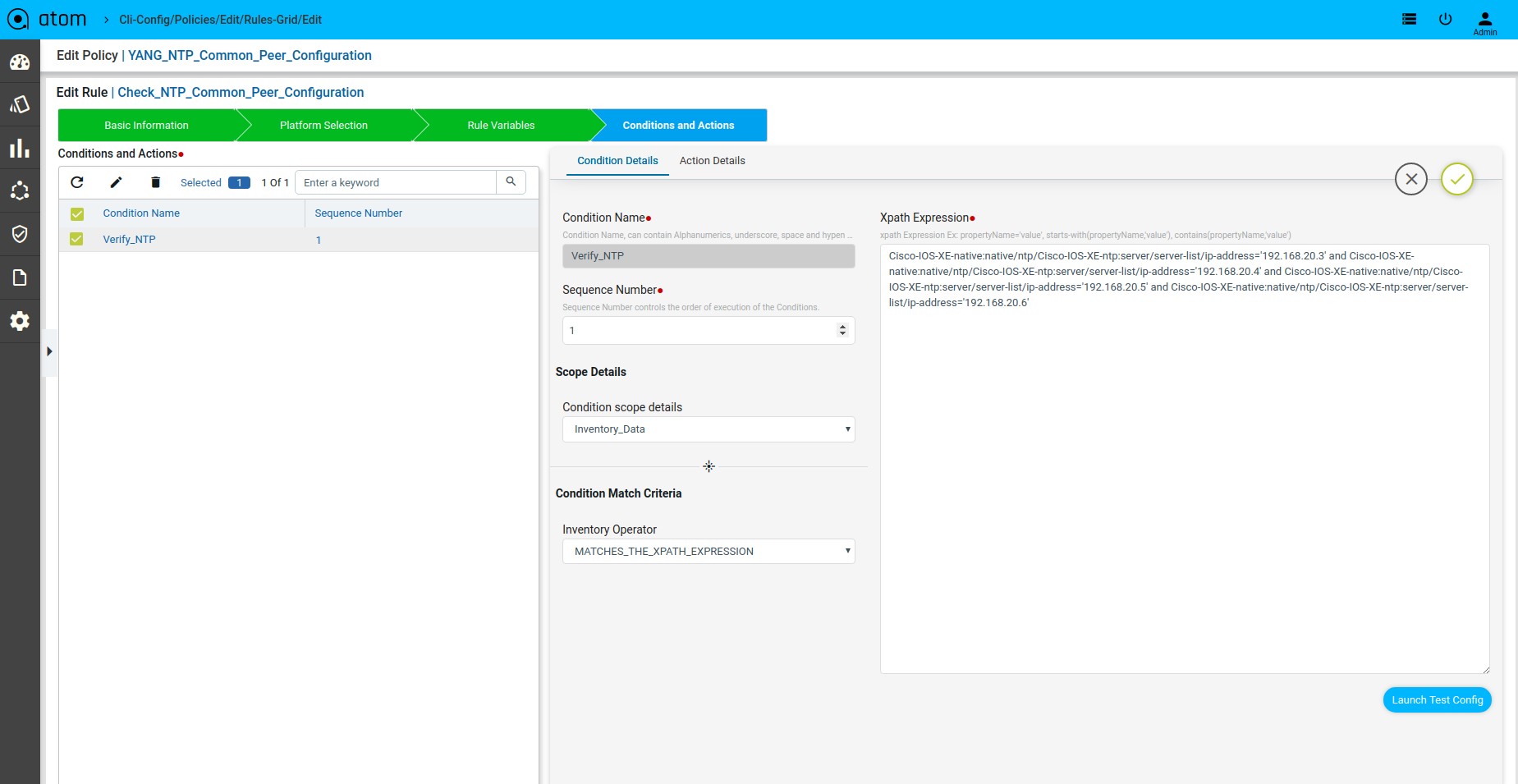
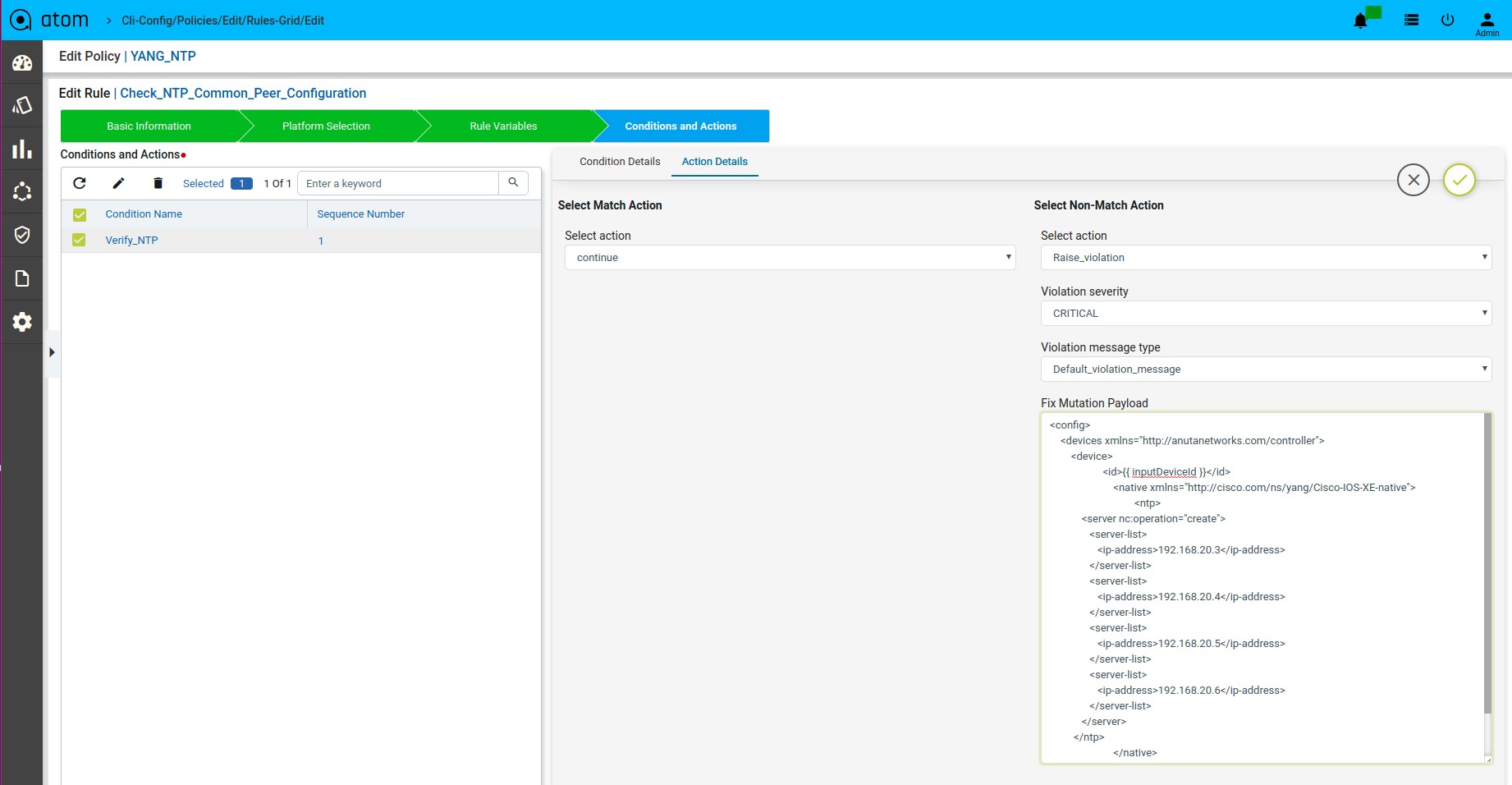
Scenario 9 : NTP server Check
Xpath Expression:
Fix Mutation Payload:
Defining Xpath Expression
Defining Fix Payload
Scenario 10 : Interface Check with rule_variable
Xpath Expression:
Fix Mutation Payload:
Defining Rule Variables
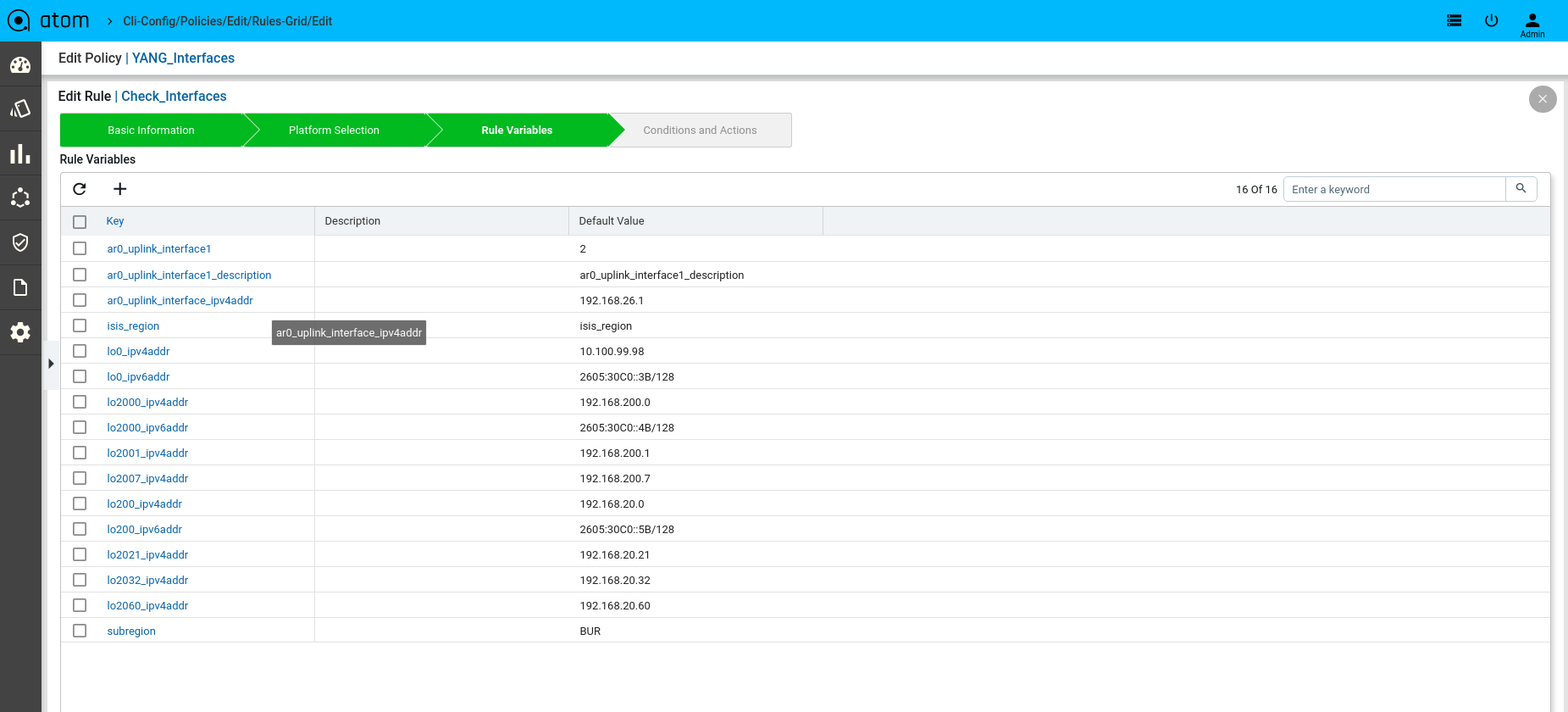
Defining Xpath Expression
Defining Fix Payload
Scenario 11 : VRF Check with rule_variable
Xpath Expression:
Fix Mutation Payload:
Defining Rule Variables
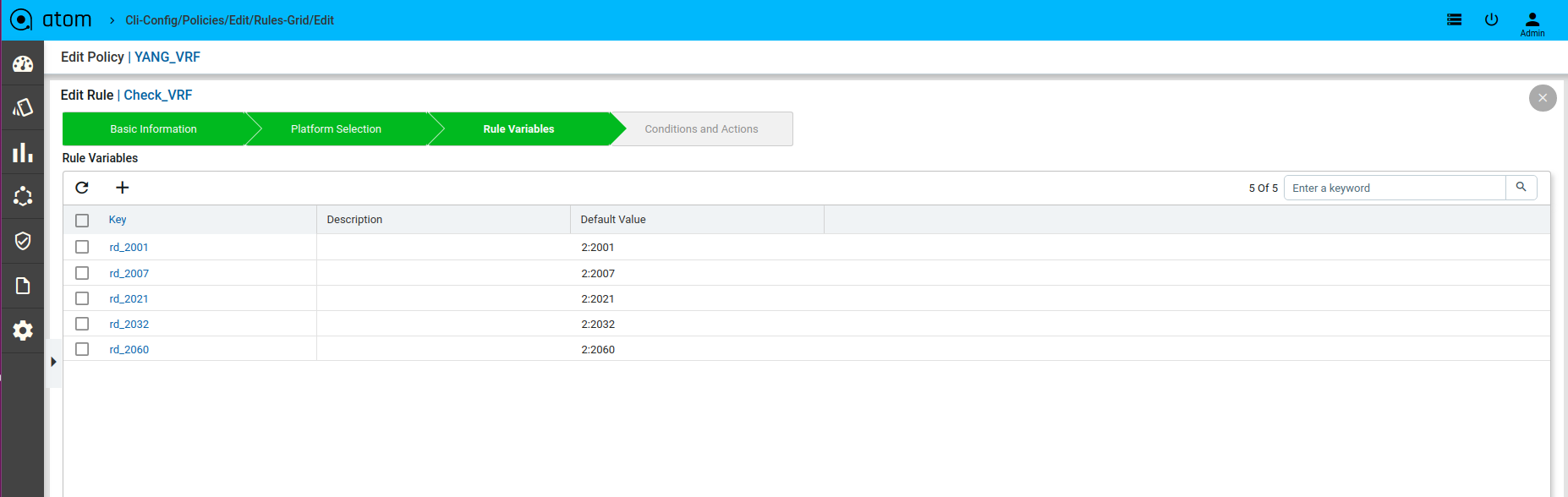
Defining Xpath Expression
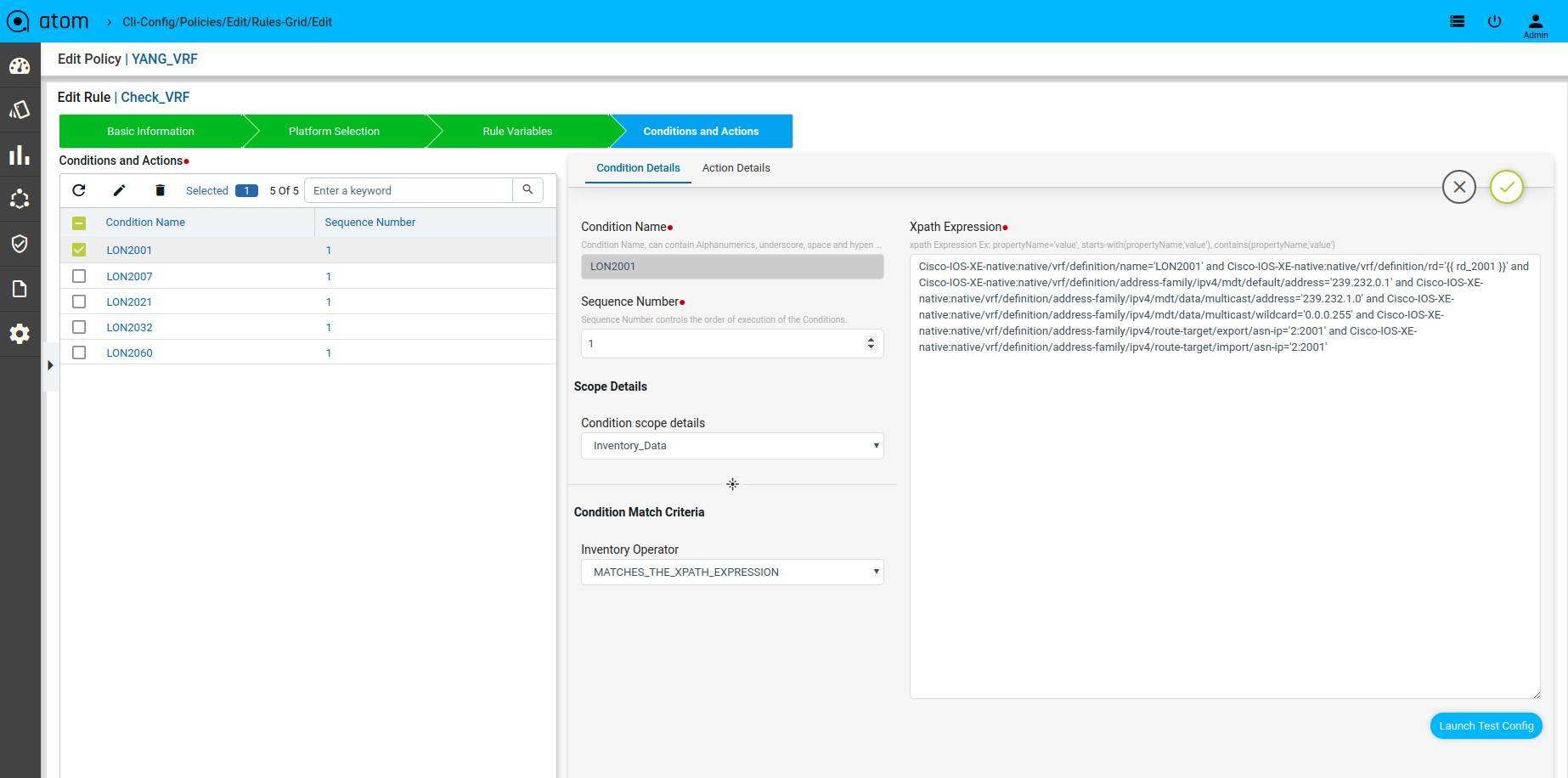
Defining Fix Payload
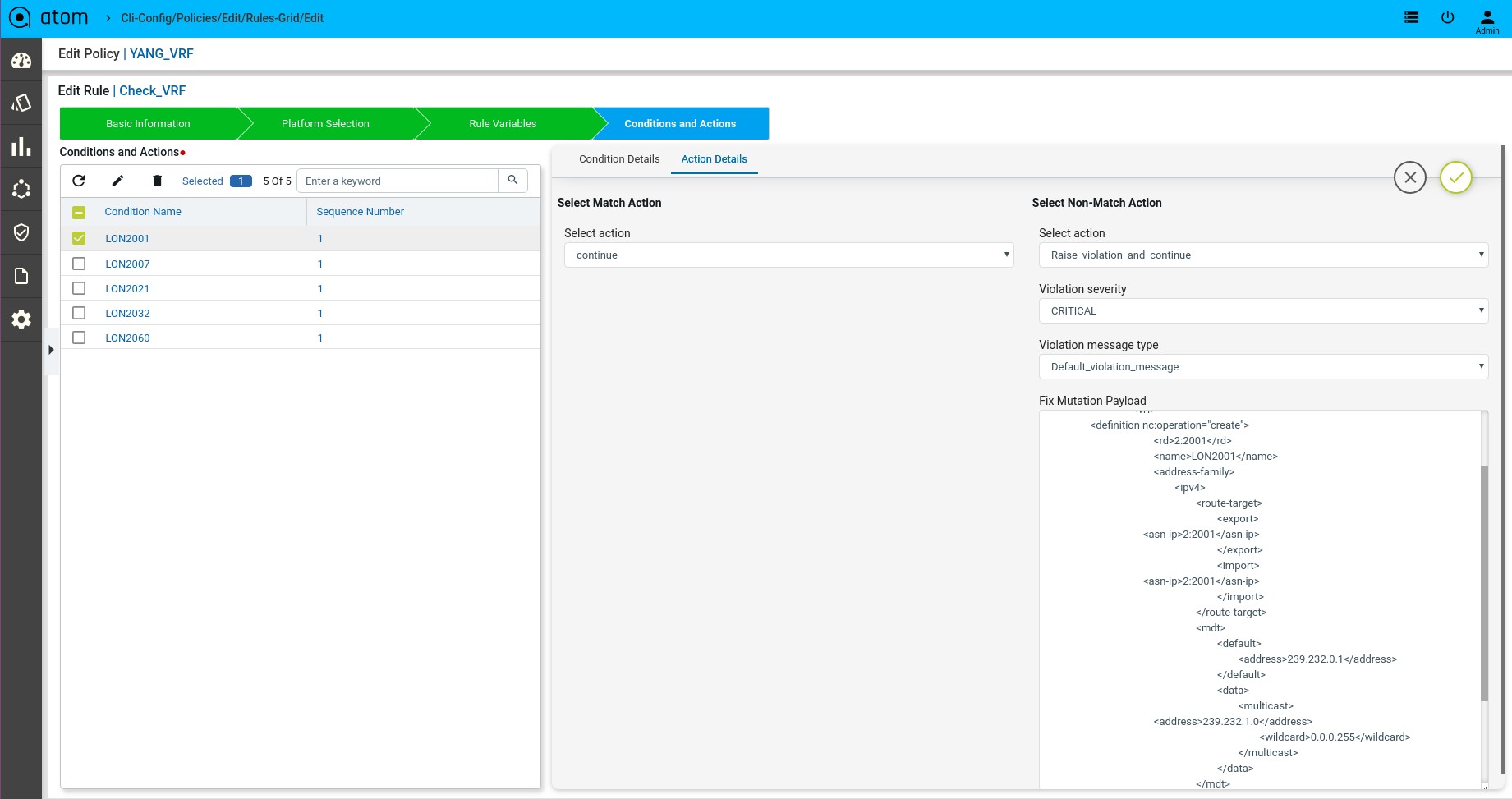
-
- Snmp-string with rule_variable :
basicDeviceConfigs:snmp/snmp-community-list/snmp-string = “{{ community }}”
-
- Logical A|B : starts-with(vendor-string,’Cisco’) or contains(device-family-string,’Cisco 800′)
- Logical A&B : starts-with(vendor-string,’Cisco’) and contains(device-family-string,’Cisco 800′)
- Logical A&(B|C) : contains(vendor-string,’Cisco Systems’) and
(contains(device-family-string,’Cisco 800′) or contains(device-family-string,’Cisco CSR 1000V’))
-
- Logical A&(B|(C&D)) :
contains(interface:interfaces/interface/if-name,’GigabitEthernet1′) and (contains(os-version,’15.6(1)S’) or (contains(vendor-string,’Cisco Systems’) and contains(device-family-string,’Cisco CSR 1000V’)))
-
- Logical not(A&B) :
not(contains(basicDeviceConfigs:local-credentials/local-credential/name , ‘admin’) and contains(basicDeviceConfigs:local-credentials/local-credential/name , ‘cisco’))
How to derive the X-path expressions
There can be two ways by which you can derive the X-path expressions
-
- Navigate to the Device profile page to get the X-path Expression Details for the yang parsed entities
Resource Manager → Devices → Select a Device → Configuration → Config Data →
Entities → Select Entity
For Example: If we want to write xpath expression for VRF name to match as “anuta”, then below is how condition needs to be written
l3features:vrfs/vrf/name = ‘anuta’
l3features:vrfs/vrf : This is x-path derived based on model under device
name : Attribute of vrf name.
-
- Navigate to Schema Browser to see all yang models under path
/controller:devices/device
Policy creation with XML Template Payload
-
- Within Condition Match Criteria select “Matches_the_template_payload”
/”Doesn’t_matches_the_template_payload” option for Inventory Operator field
-
- The Fix Mutation Payload is a Jinja2 template configuration in Netconf xml RPC format written using the unmatched content from the test results tab.
Navigate to Resource Manager > Config Compliance > Policy > + (Add Policies) Few examples
Scenario 12 : IP Domain name check
Template Payload:
Fix Mutation Payload :
Defining Template Payload
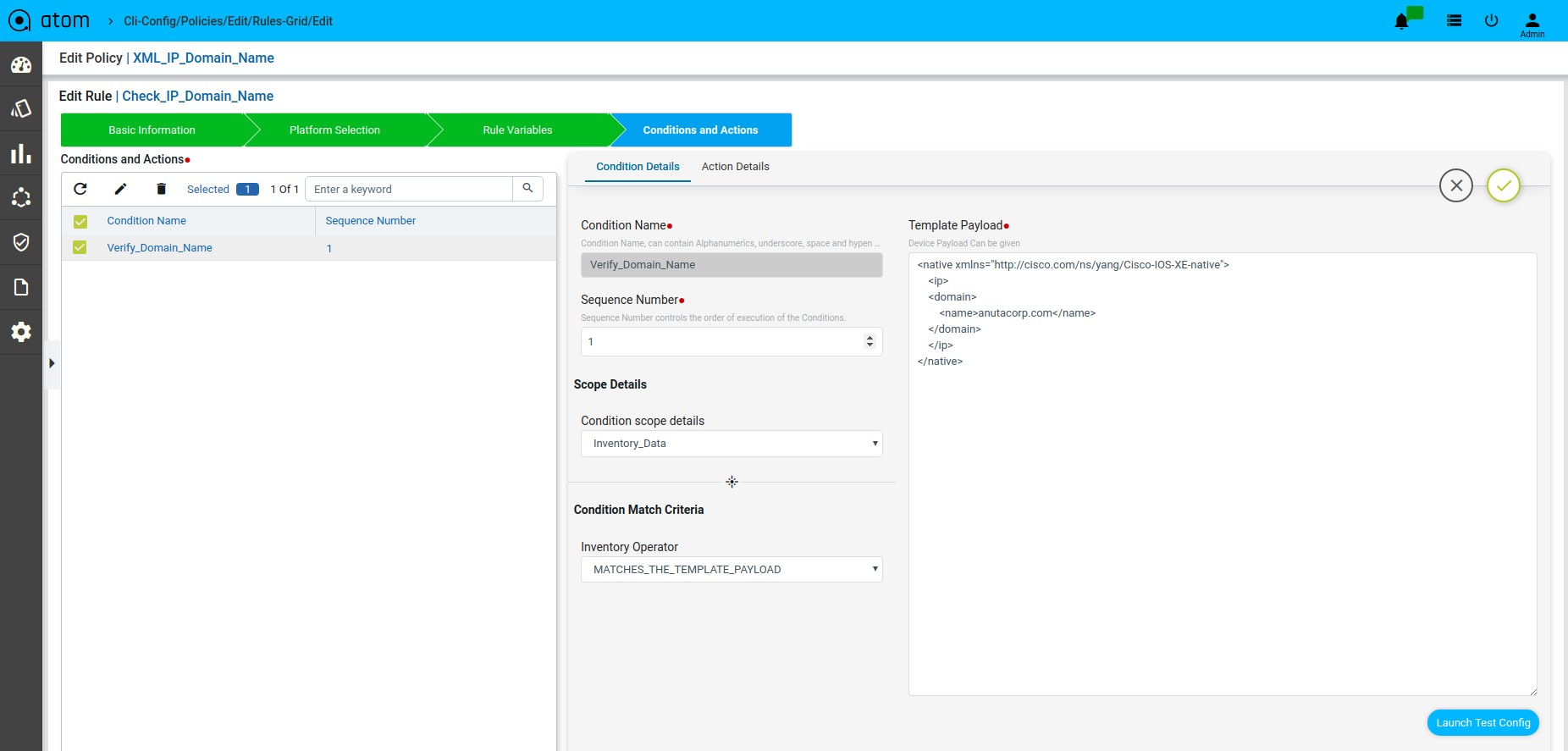
 Here the matched and unmatched data will be stored in the backend data structure which is shown in the Test Results tab. The matched data will be stored in the condition-search-output. The unmatched data will be stored in unmatched-content.
Here the matched and unmatched data will be stored in the backend data structure which is shown in the Test Results tab. The matched data will be stored in the condition-search-output. The unmatched data will be stored in unmatched-content.
The Fix Mutation Payload is a Jinja2 template configuration in Netconf xml RPC format written using the unmatched content from the test results tab.
Defining Fix Payload
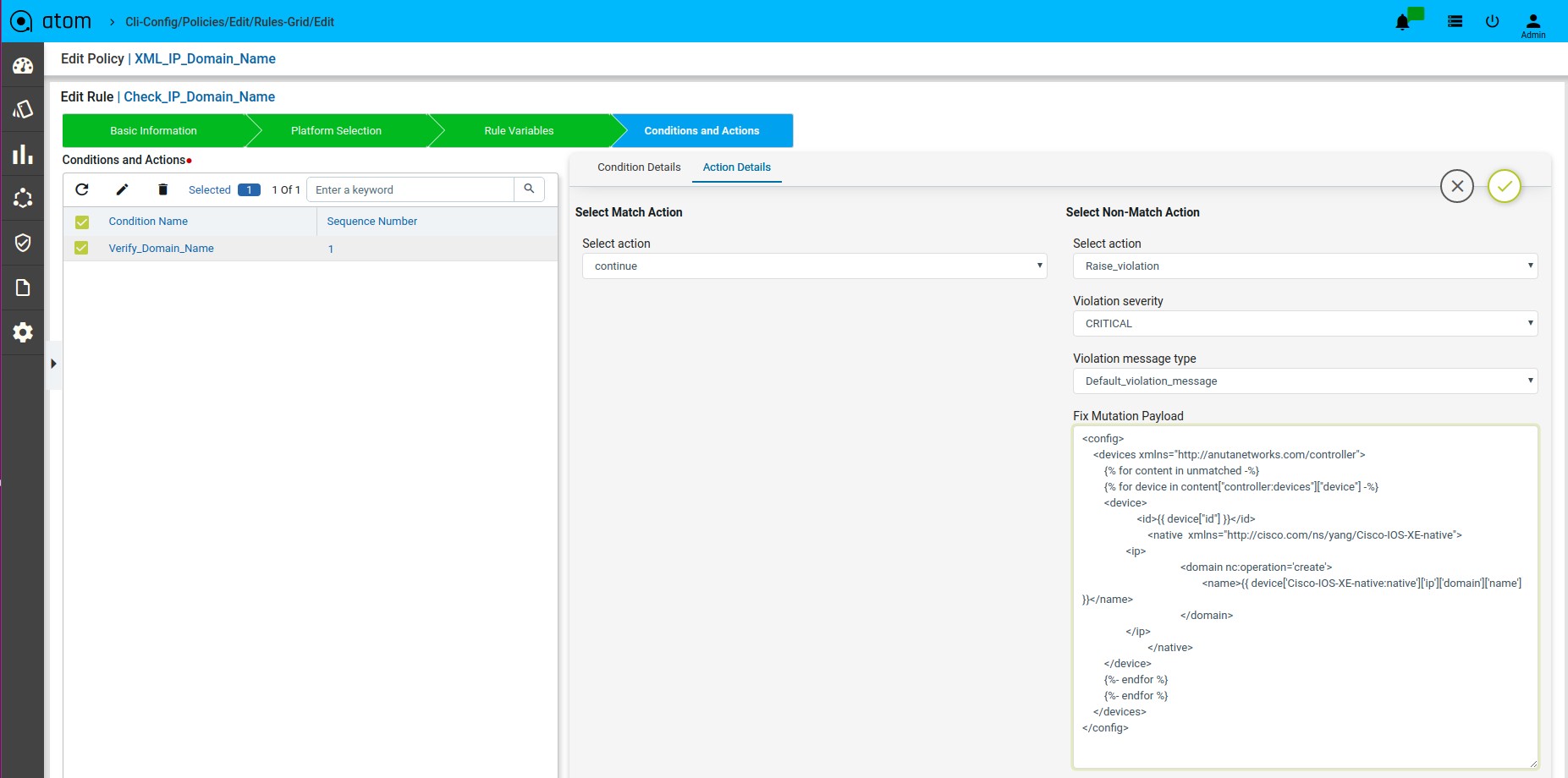
Fix Configuration Display in Remediation
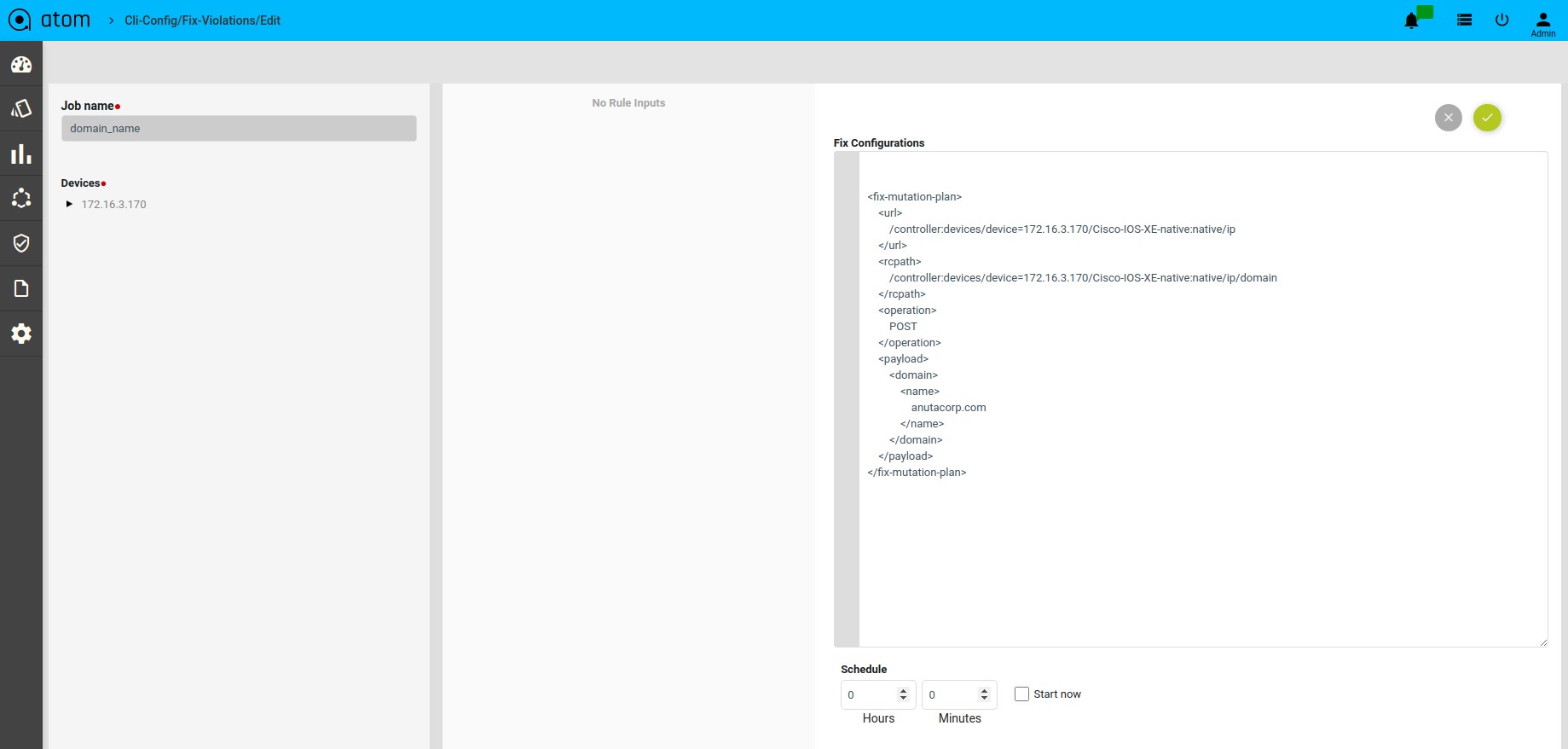
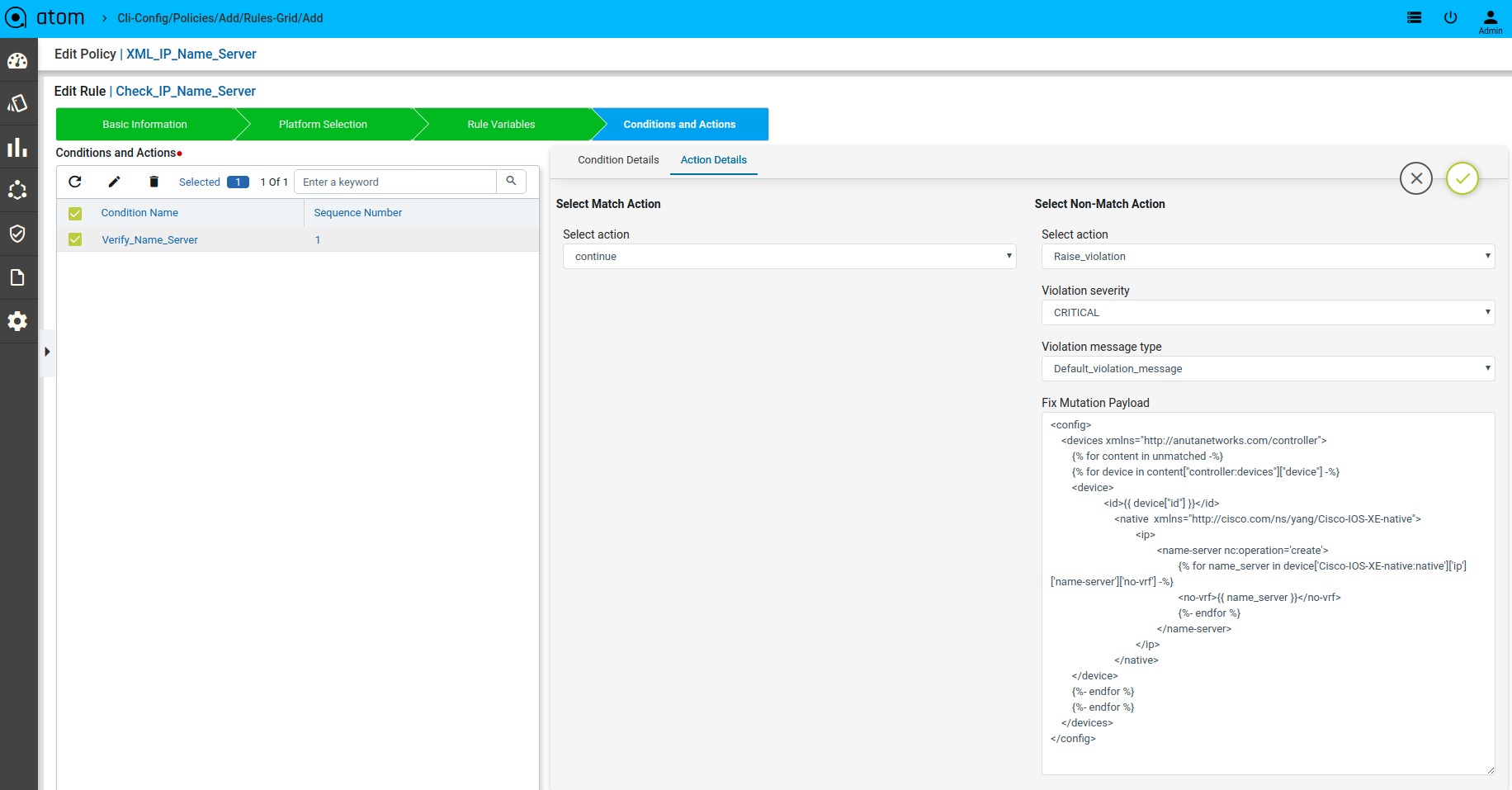
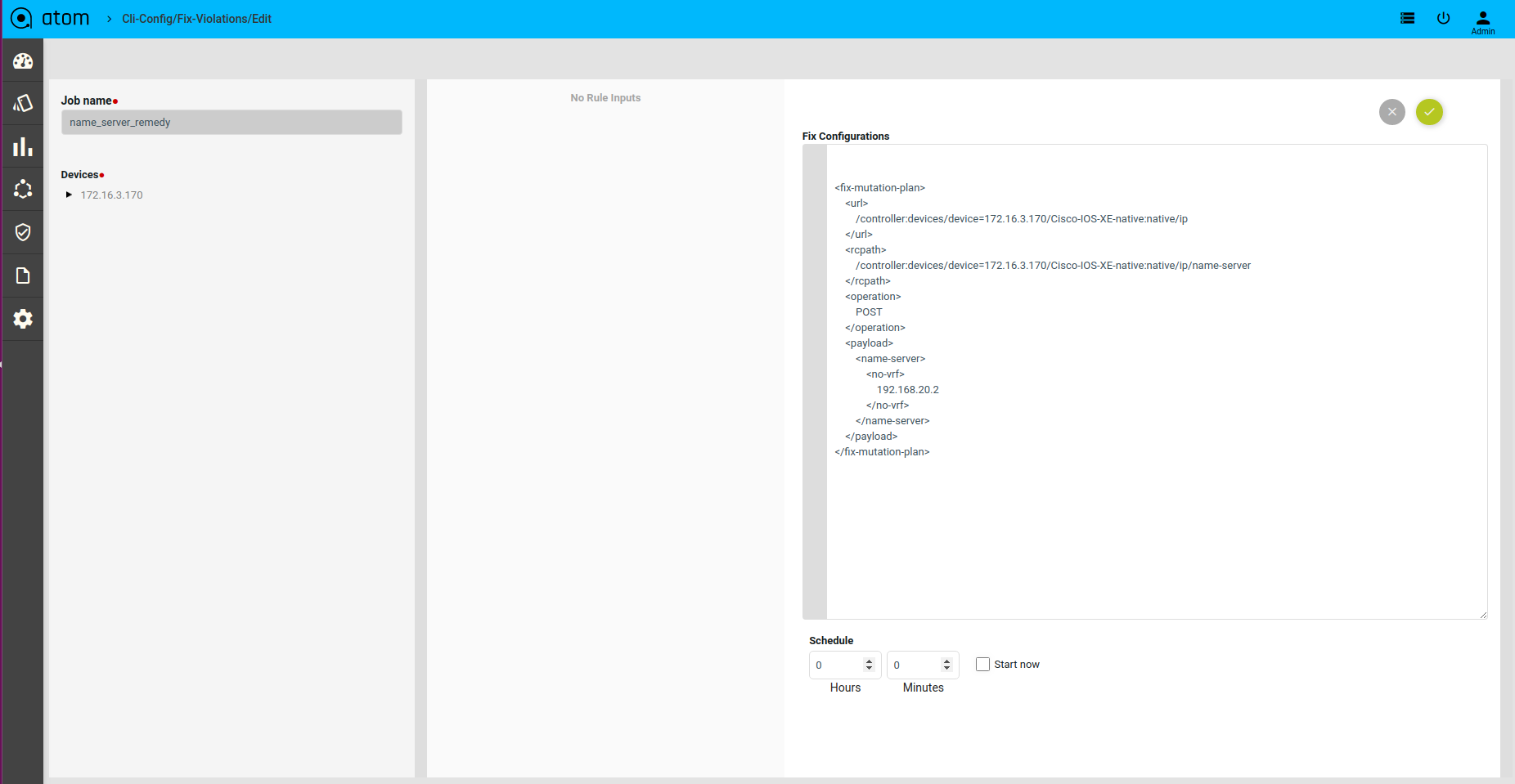
Scenario 13 : IP Name Server check
Template Payload:
Fix Mutation Payload :
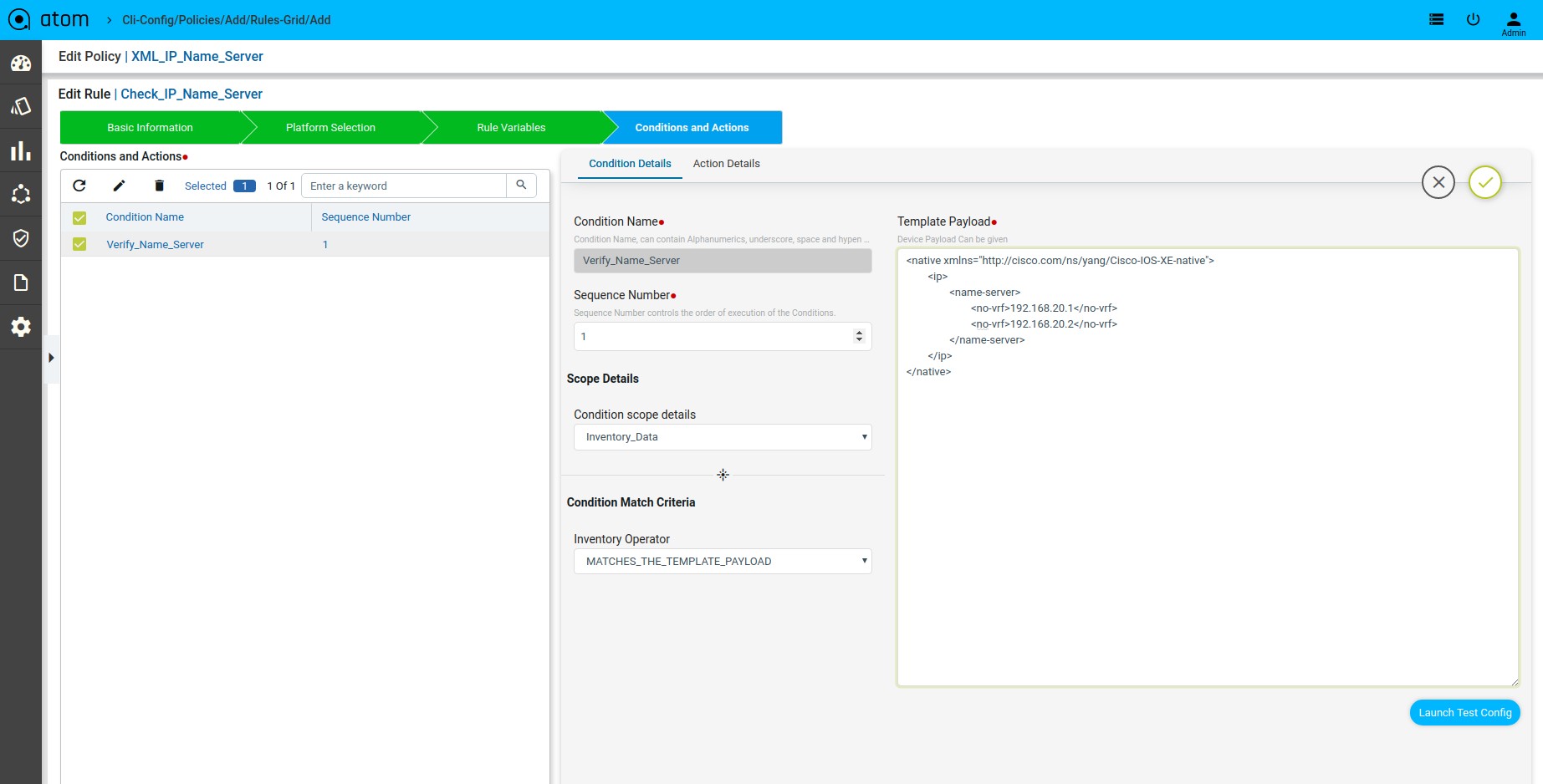
Defining Fix Payload
Fix Configuration Display in Remediation
Scenario 14 : Interface check
Template Payload:
Fix Mutation Payload :
<config>
<devices xmlns=”http://anutanetworks.com/controller”>
{% for content in unmatched –%}
{% for device in content[“controller:devices”][“device”] –%}
<device>
<id>{{ device[“id”] }}</id>
<native xmlns=”http://cisco.com/ns/yang/Cisco-IOS-XE-native”>
<interface>
{% for loopback in
device[‘Cisco-IOS-XE-native:native’][‘interface’][‘Loopback’] –%}
<Loopback nc:operation=”create”>
{% if loopback[‘ip’] –%}
<ip>
<address>
<primary>
<address>{{ loopback[‘ip’][‘address’][‘primary’][‘address’]
}}</address>
<mask>{{ loopback[‘ip’][‘address’][‘primary’][‘mask’] }}</mask>
</primary>
</address>
</ip>
{%- endif %}
{% if loopback[‘ipv6’] –%}
<ipv6>
<address>
<prefix-list>
{% for prefix in loopback[‘ipv6’][‘address’][‘prefix-list’] –%}
<prefix>{{ prefix[‘prefix’] }}</prefix>
{%- endfor %}
</prefix-list>
</address>
</ipv6>
{%- endif %}
<name>{{ loopback[‘name’] }}</name>
</Loopback>
{%- endfor %}
</interface>
</native>
Defining Template Payload
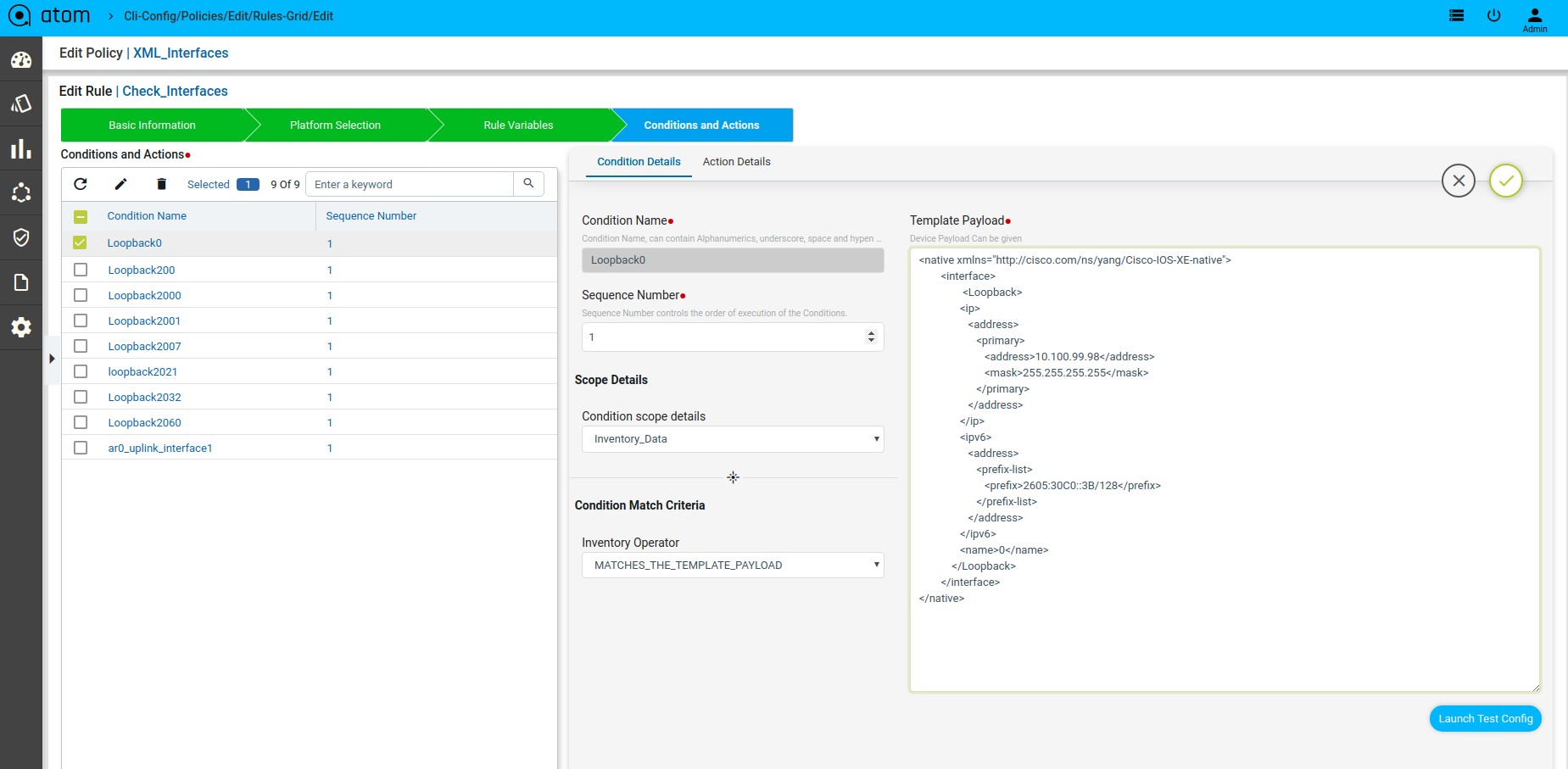
Defining Template Payload
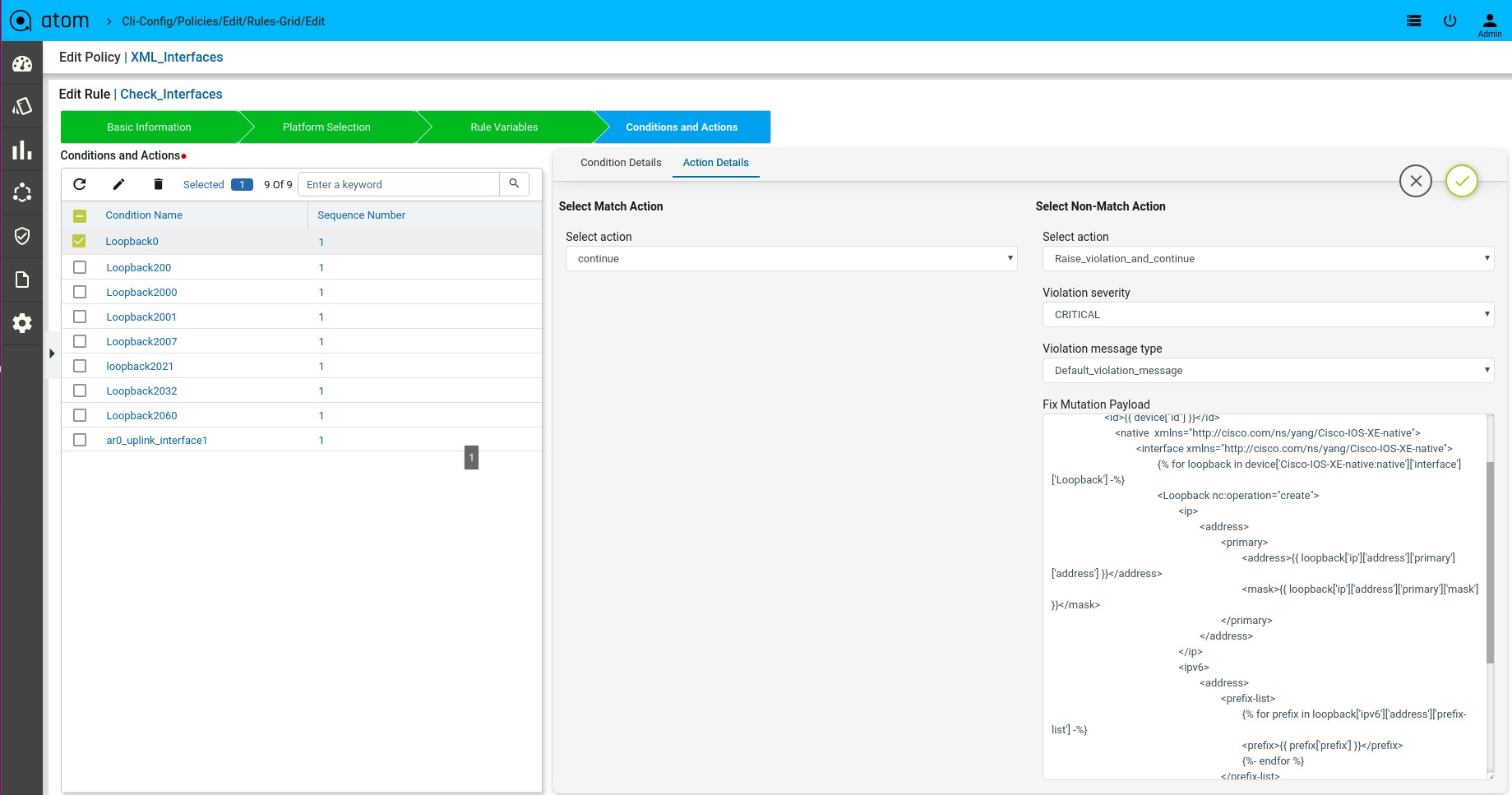
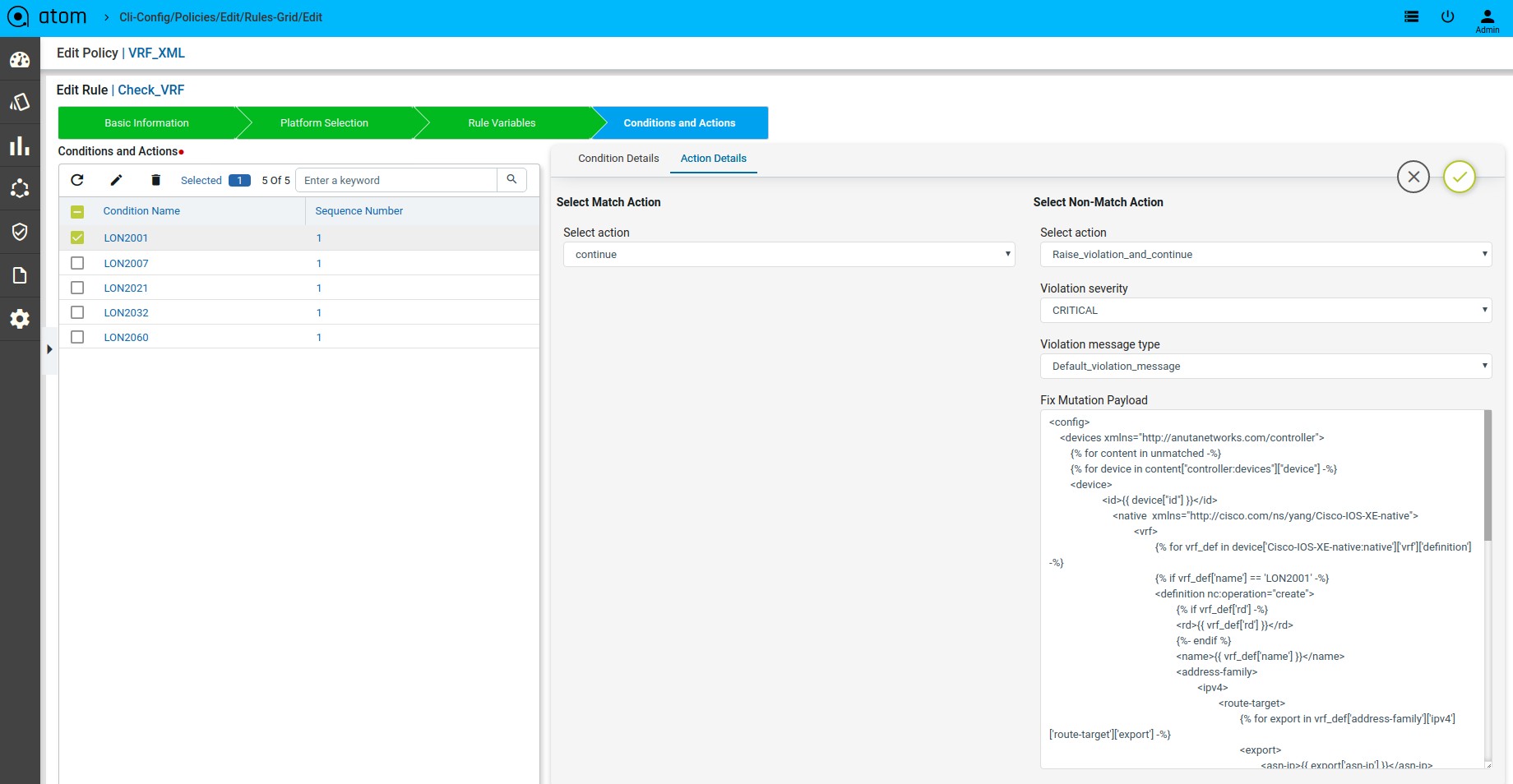
Scenario 15 : VRF check
Template Payload:
Fix Mutation Payload :
–%}
{% for vrf_def in device[‘Cisco-IOS-XE-native:native’][‘vrf’][‘definition’]
{% if vrf_def[‘name’] == ‘LON2001’ –%}
<definition nc:operation=”create”>
{% if vrf_def[‘rd’] –%}
<rd>{{ rd_2001 }}</rd>
{%- endif %}
<name>{{ vrf_def[‘name’] }}</name>
{% if vrf_def[‘address-family’] –%}
<address-family>
<ipv4>
{% if vrf_def[‘address-family’][‘ipv4’][‘route-target’] –%}
<route-target>
{% for export in
vrf_def[‘address-family’][‘ipv4’][‘route-target’][‘export’] –%}
<export>
<asn-ip>{{ export[‘asn-ip’] }}</asn-ip>
</export>
{%- endfor %}
{% for import in vrf_def[‘address-family’][‘ipv4’][‘route-target’][‘import’] -%}
<import>
<asn-ip>{{ import[‘asn-ip’] }}</asn-ip>
</import>
{%- endfor %}
</route-target>
{%- endif %}
{% if vrf_def[‘address-family’][‘ipv4’][‘import’] –%}
<import>
<map>{{ vrf_def[‘address-family’][‘ipv4’][‘import’][‘map’] }}</map>
</import>
{%- endif %}
{% if vrf_def[‘address-family’][‘ipv4’][‘mdt’] –%}
<mdt>
{% if vrf_def[‘address-family’][‘ipv4’][‘mdt’][‘default’] -%}
<default>
<address>{{
vrf_def[‘address-family’][‘ipv4’][‘mdt’][‘default’][‘address’] }}</address>
Defining Template Payload
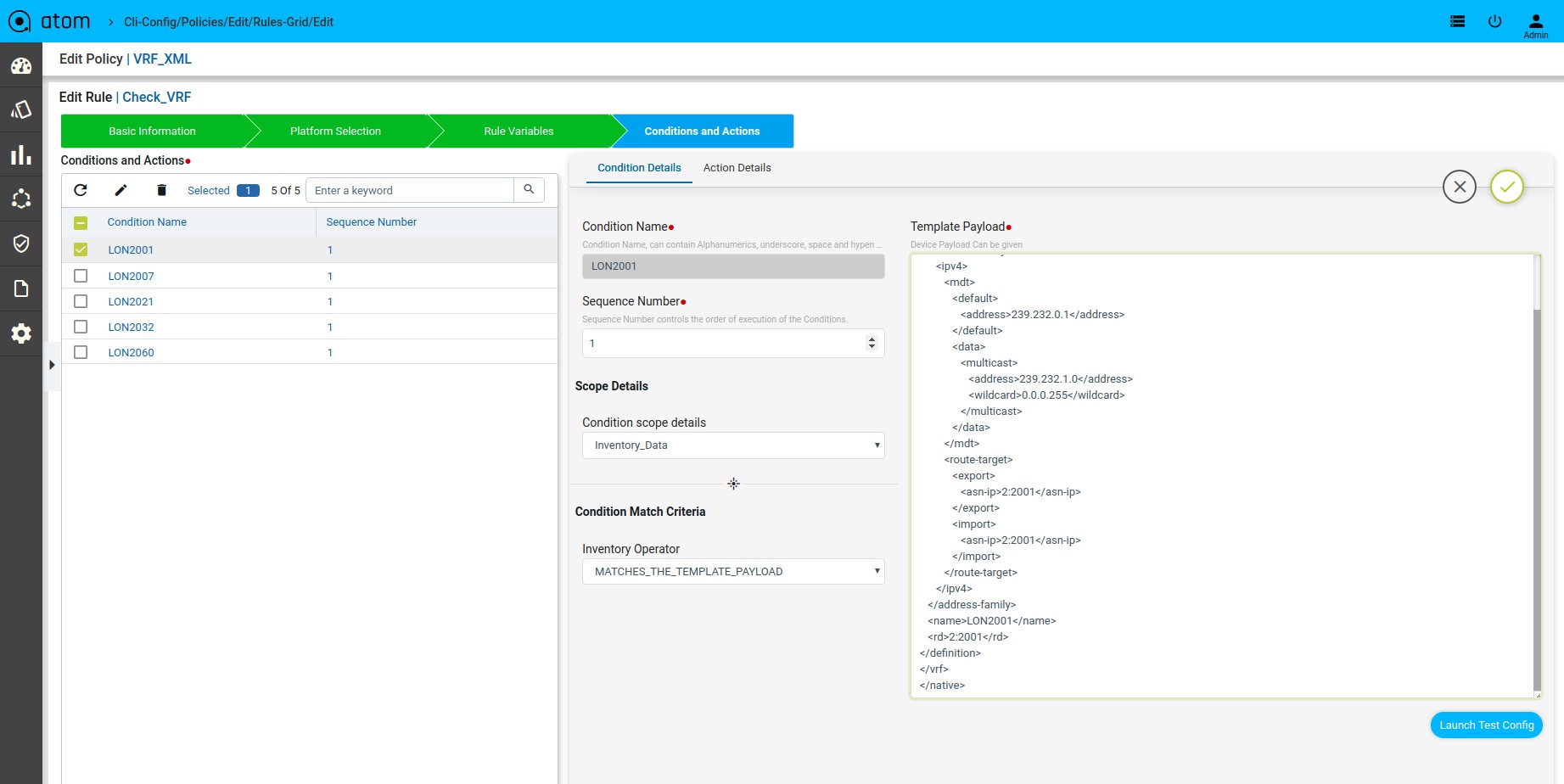
Defining Fix Payload
How to derive the XML Template payload
-
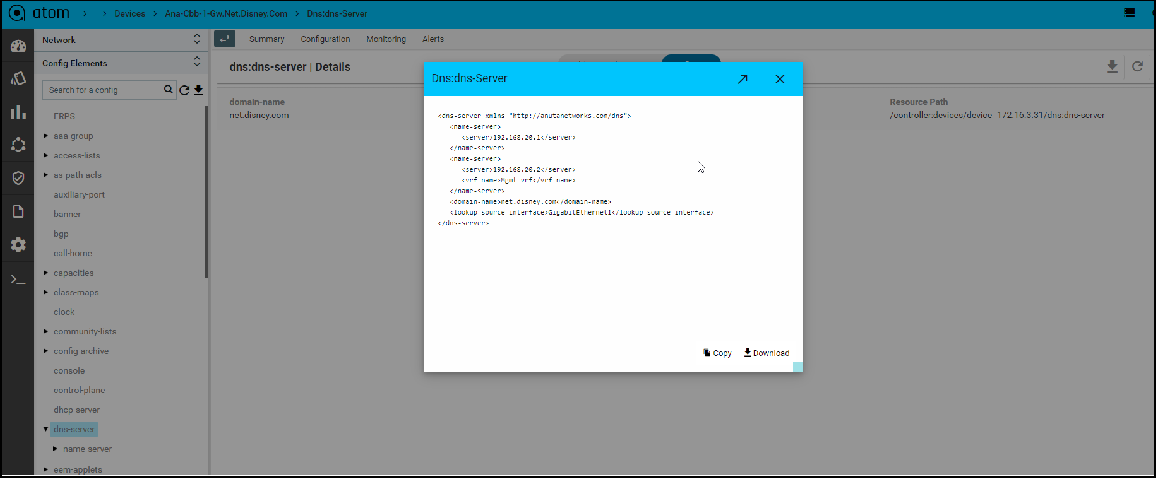
- Navigate to the Device profile page and export the XML template details for the yang parsed entities
Resource Manager → Devices → Select a Device → Configuration →Config Data → Entities → Select Abstract entity → Use Download button to export/copy the XML payload
Example : Let’s derive domain-name XML Template payload
Navigate to Devices → select a device→ configuration -> Config Data → Entities →
dns-server → Export XML payload using download button.
Profiles
A profile allows one or more Policies to be grouped and executed on one or more devices either on-demand or as per Schedule. Profile execution results in a per-device compliance report included in the execution.
Steps:
- Navigate to Resource Manager > Config Compliance -> Profiles
- Select “+” to Create a Profile
- ATOM opens up a new wizard and displays 2 sections.
- Policies – Select one/more policies
- Devices & Schedule – Select one/more devices or Device groups
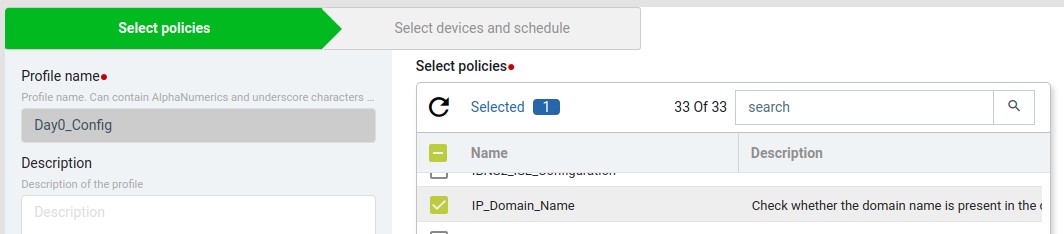 Create profile by providing name, description and select policy which was created previously IP_Domain_Name.
Create profile by providing name, description and select policy which was created previously IP_Domain_Name.
- Navigate to the next tab, Select devices and schedule. We can select either device(s) from
Devices or Device Groups tab
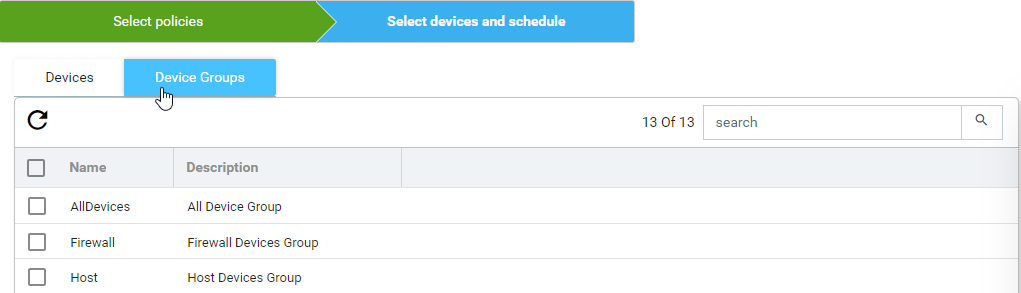

- After device(s) are selected, choose if the compliance checks need to be run against an archived config or current running-configuration of the device. By default Latest From Config Archive is selected.
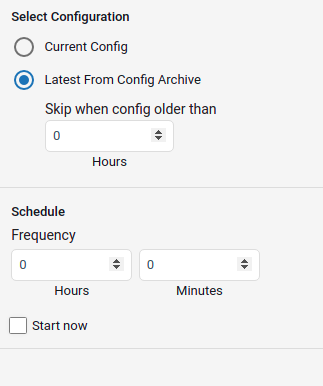
Schedule: The profile job can be scheduled in Hours or Minutes. Alternatively, a job can be started right away by enabling Start now option.
Configuration:
- Current Config: This will pull the current device configuration and evaluate against the polices.
- Latest From Config Archive: This will use the latest configuration that is stored in the ATOM. Optionally you can add a check to skip the compliance check when the configuration is older than n hrs
Or the profile job can triggered at a later point of time using run job icon on the profiles view
Report
Navigate to Resource Manager > Config Compliance -> reports
Compliance report is generated upon completion of Profile run. For each device, the report lists the compliant and non-compliant policies, rules and conditions .
 After profile job is run, audit details can be viewed in Report View
After profile job is run, audit details can be viewed in Report View
Since IP_Domain_Name policy has a condition named Verify_IP_Domain_name, where it didn’t meet the required criteria. The condition is marked as Non_compliant.
Severity: Severity the condition where the condition Match Action or Non Match Action is of type Raise_violation or Raise_violation_and_continue.
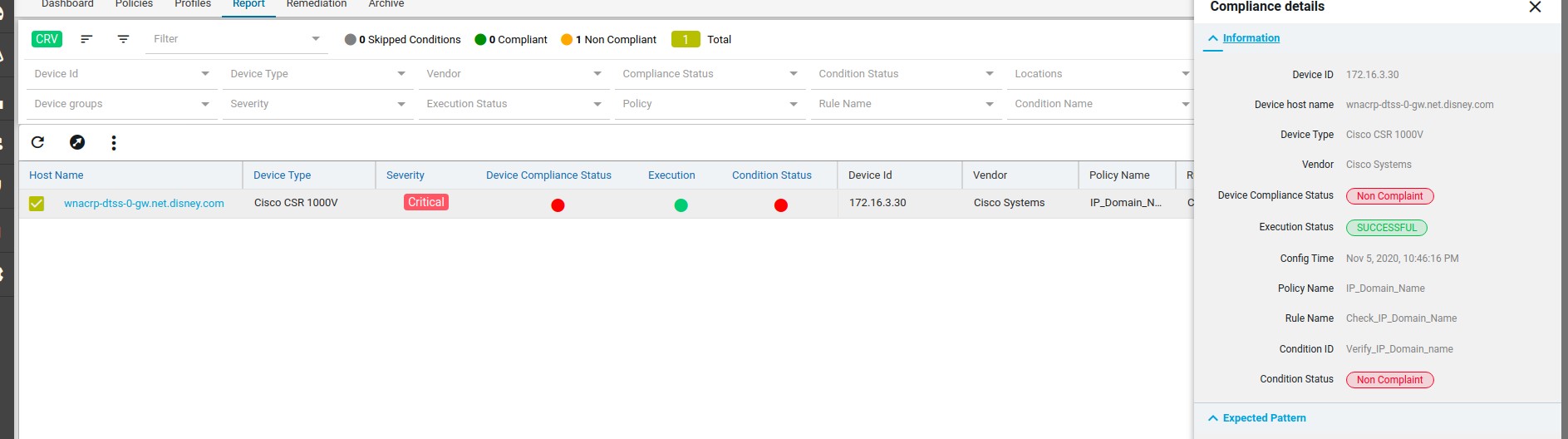 Upon checking the row you can see the expected and the fix commands for that condition along with action-severity, action-type and other metadata related to device & condition.
Upon checking the row you can see the expected and the fix commands for that condition along with action-severity, action-type and other metadata related to device & condition.
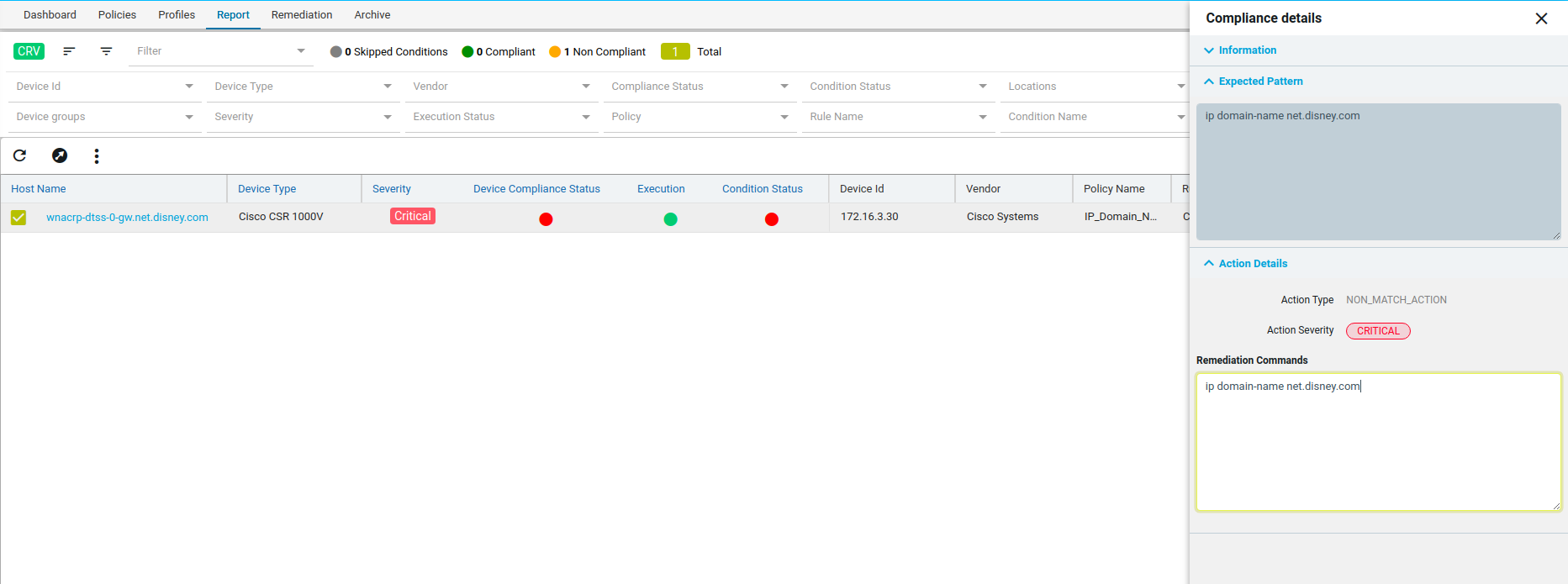
The reports section also facilitates users to filter the results of what user is interested in. The dropdown will display all the possible values for the filters. Users can try out any combination and see the results. By clicking on the apply button.
Inorder to revert the filter that are applied you can click on the clear button.
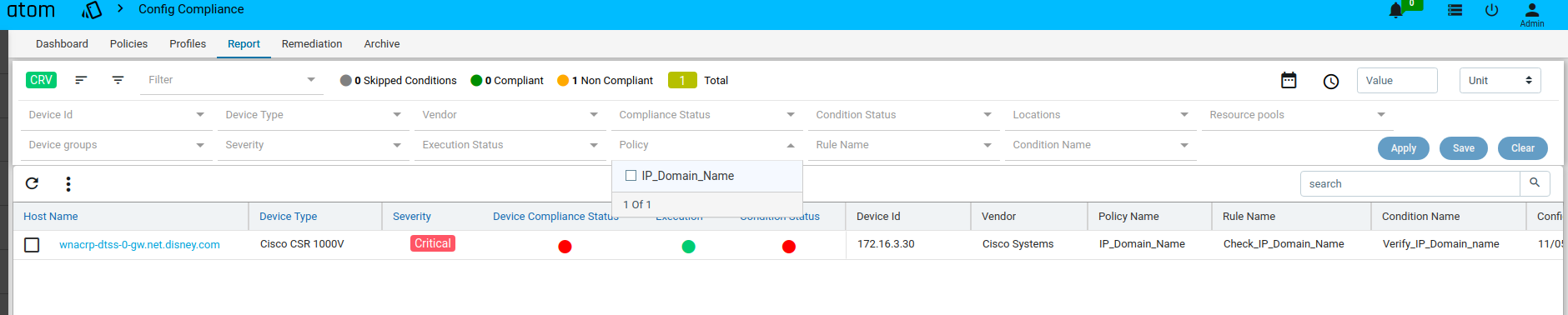
Tired of filtering the results every time for more frequent data. We got you covered ATOM provides an option to save the filter that you applied again with a single click.
- Select filters that you are interested in and click on the save button
- This will show a new pop-up box prompting for the filter name and the dashboard where the user wants to pin it.
- Click on the save and apply button will save this filter and the resulting data will be populated.
We can pin to the dashboard, upon saving the filter using dropdown.we are able to see the filter under the dashboard.
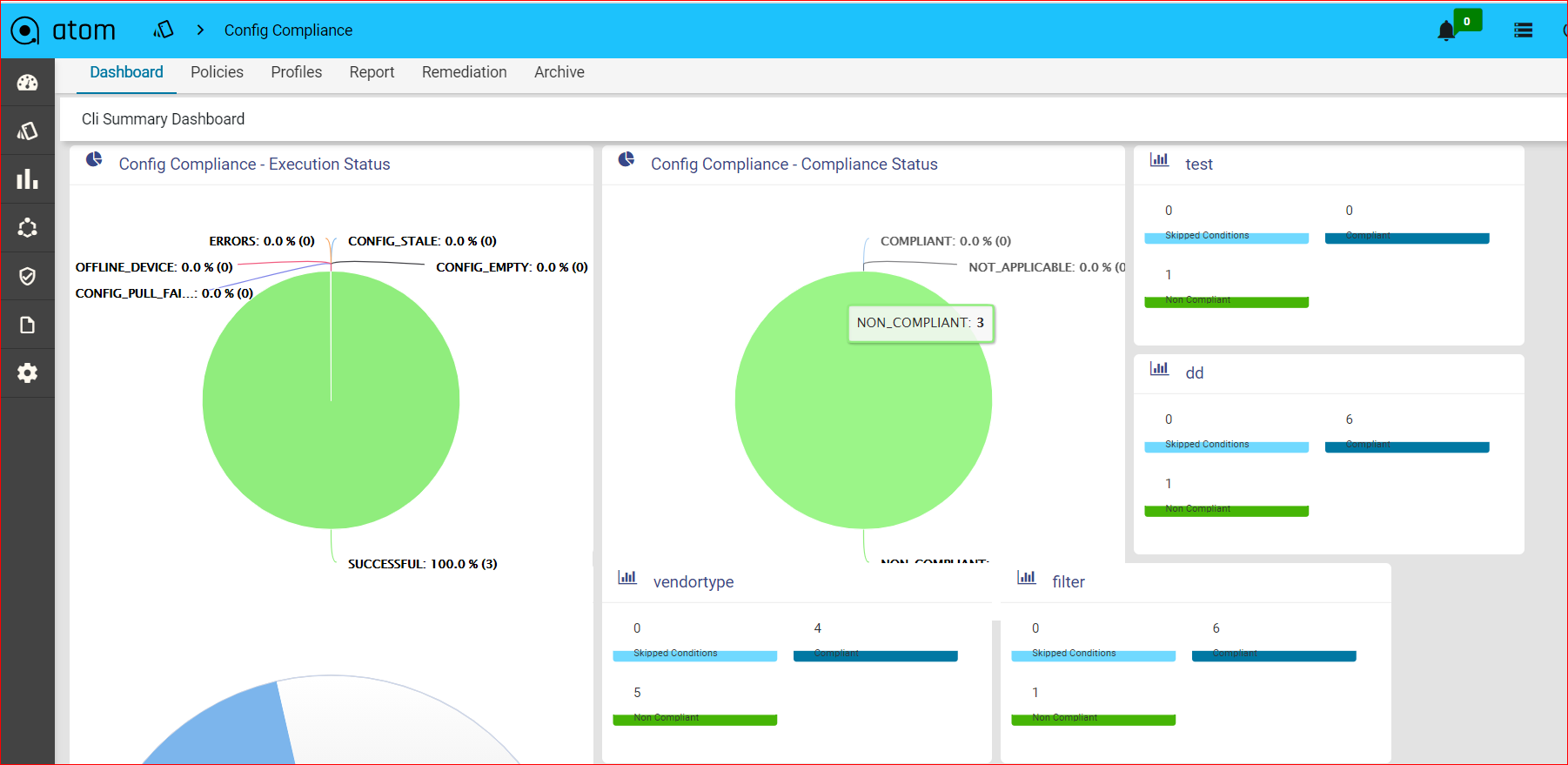
From where I can access these saved filters?
- They are easily accessible. All the filters that are saved are listed under the dropdown on the top.
- Click on the interested filter and you see the data getting filtered.
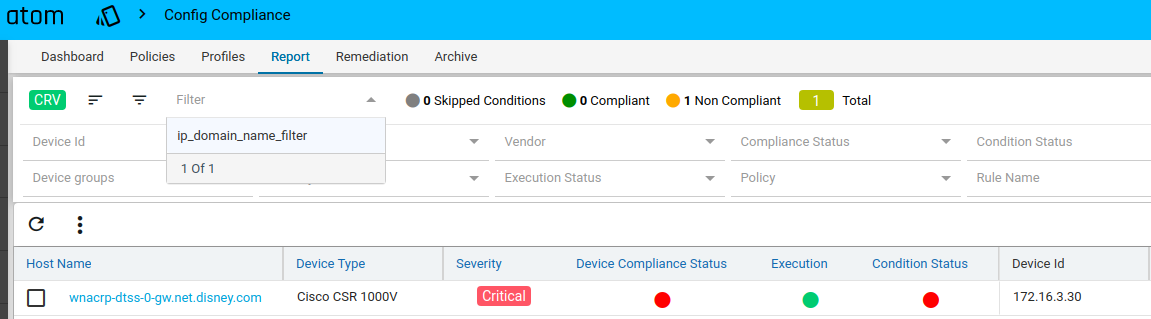
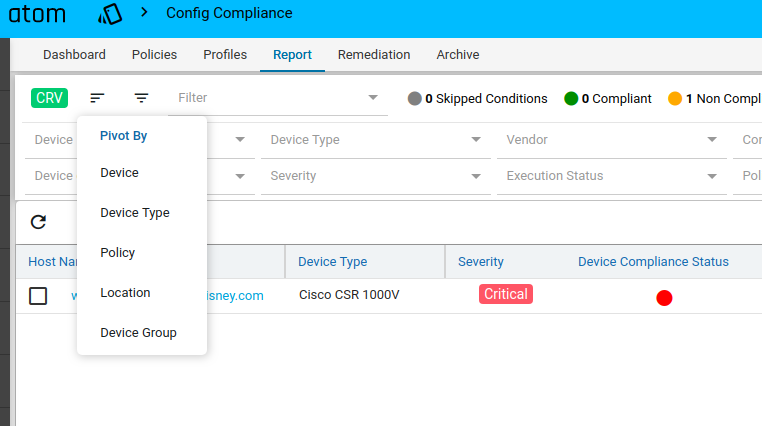 ATOM also provides an option to view the statistics based on Pivot by Device, Device Type, Policy, Location and Device Group.
ATOM also provides an option to view the statistics based on Pivot by Device, Device Type, Policy, Location and Device Group.
Users can opt for any view that they are interested in.
Pivot by device

Severity: The aggregated severity of that particular device.
Compliant Policies: The number of policies that are compliant against the device.
Non-Compliant Policies: The number of policies that are non-compliant against the device.
Compliant Conditions: The number of Conditions that are complaint against the device
Non-Compliant Conditions: The number of Condition that are non-compliant against the device Device ID: Displays all Device Ids for which compliance has run. This is the context column for pivot by device.
Execution status: Based on execution on device it is updated as Successful, errors,stale config, empty config, config pull failed, offline device.
Hostname: Hostname of a device is displayed here.
Device compliance status: Based on compliance run, for a device it is updated as Compliant, non-compliant, Not applicable.
Device Type: The device type of a device is displayed(like cisco csr 1000v , cisco 891).
Vendor: vendors of device are displayed here (like cisco, juniper)
On clicking on the Device ID, Device ID filter gets applied and the user will be navigated to CRV.
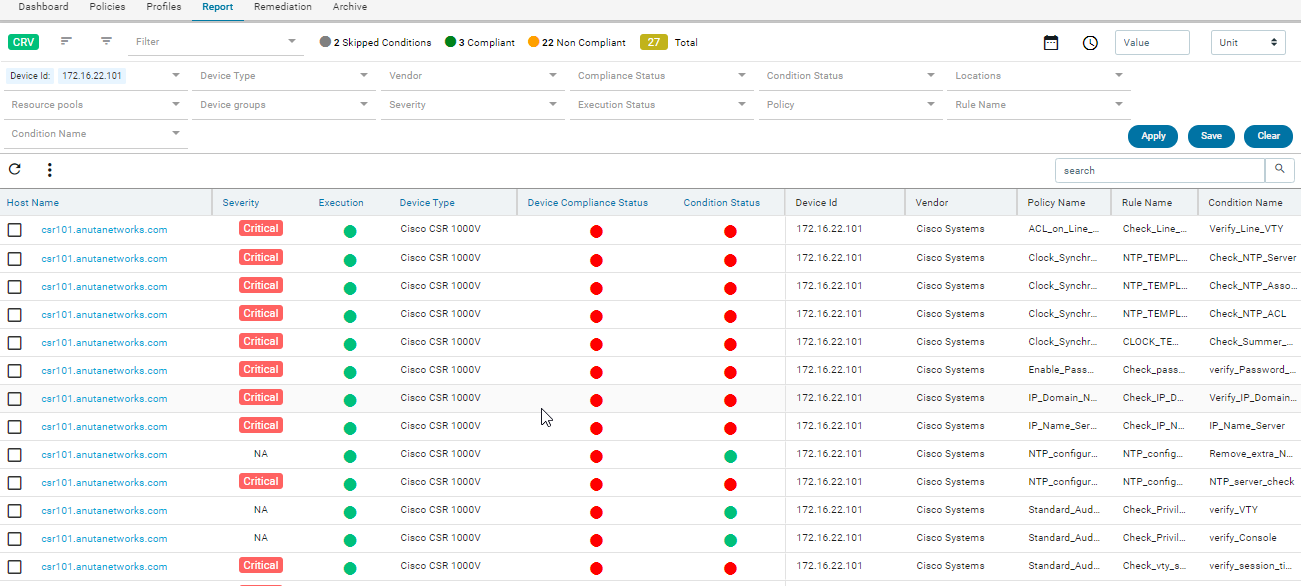
Pivot By Policy
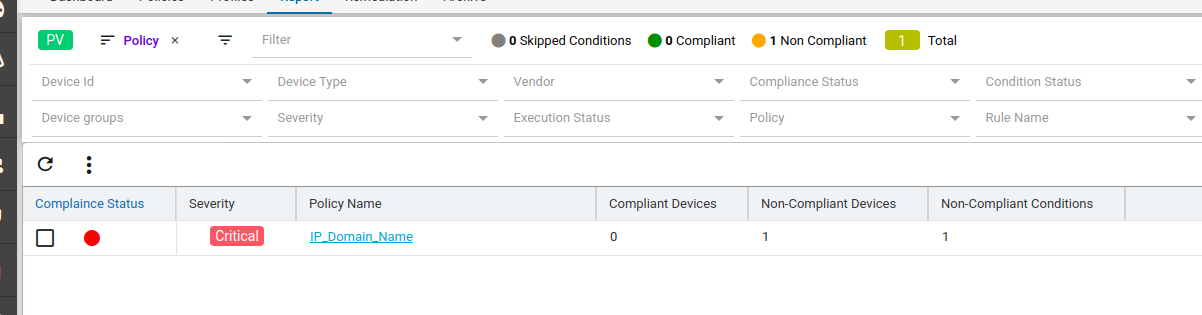
Severity: The aggregated severity of that particular policy.
Compliant Devices: The number of devices that are compliant against the policy.
Non-Compliant Devices: The number of devices that are non-compliant against the policy.
Non-Compliant Conditions: The number of conditions that are non-compliant against the policy.
Policy Name: Displays all policies for which compliance is run. This is the context column for pivot by policy.
Compliance status: Based on policy, it is updated as compliant or non-compliant.
On clicking on the policy, the policy filter gets applied and the user will be navigated to CRV.
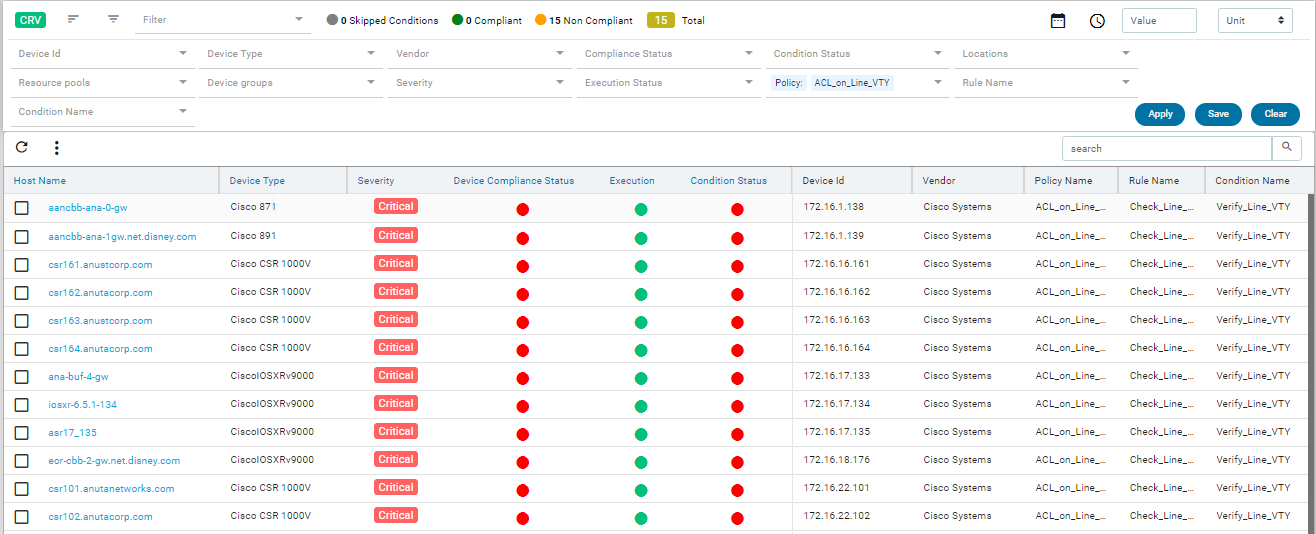
Pivot By Device Type:
Severity:The aggregated severity of that particular device type
Device type: Displays all device types available in compliance. This is the context column for pivot by device type.
Vendor: Displays the vendors available in compliance .
Compliant Device: The number of devices that are compliant against the device type
Non-compliant device:The number of devices that are non-compliant against the device type.
Compliant policies:The number of policies that are compliant against the device type
Non-Compliant policies:The number of policies that are non-compliant against the device type
Compliant Condition:The number of conditions that are compliant against the device type.
Non-compliant Condition:The number of conditions that are non-compliant against the device type.
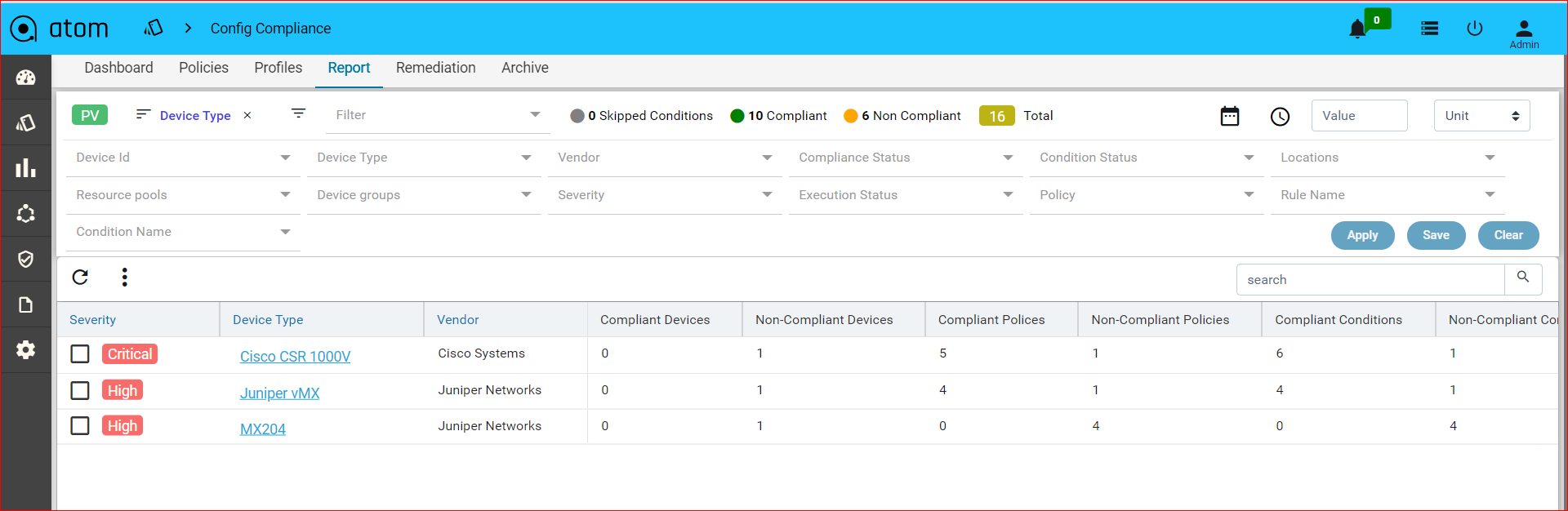
Click on device type> Cisco CSR 1000v here
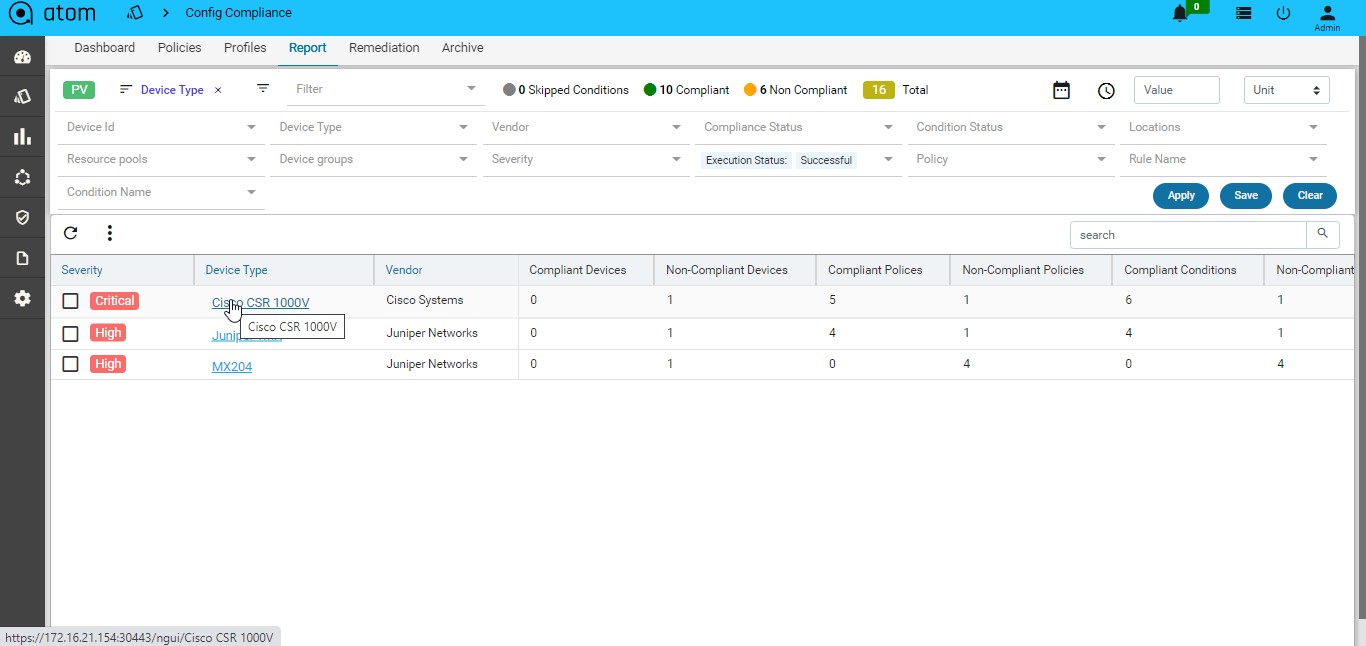
On clicking on the Device Type, Device Type filter gets applied and the user will be navigated to CRV.
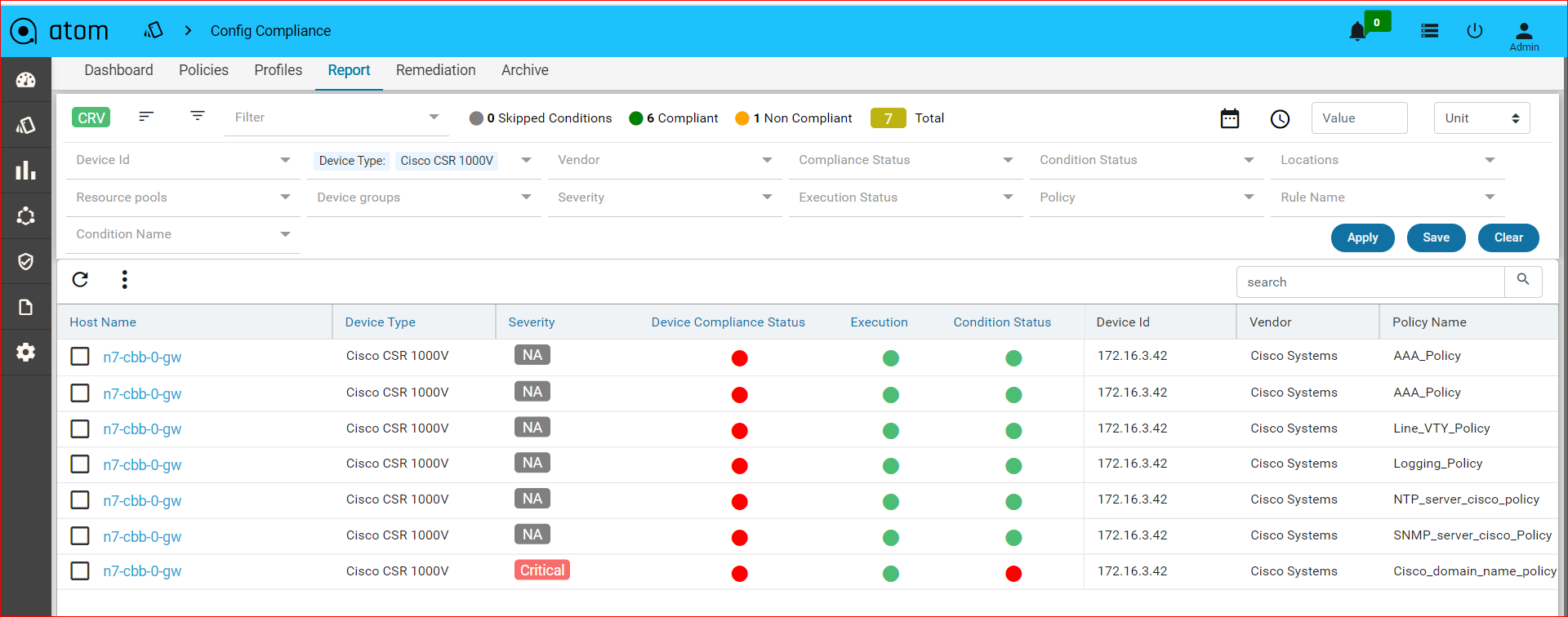
Pivot By Location:
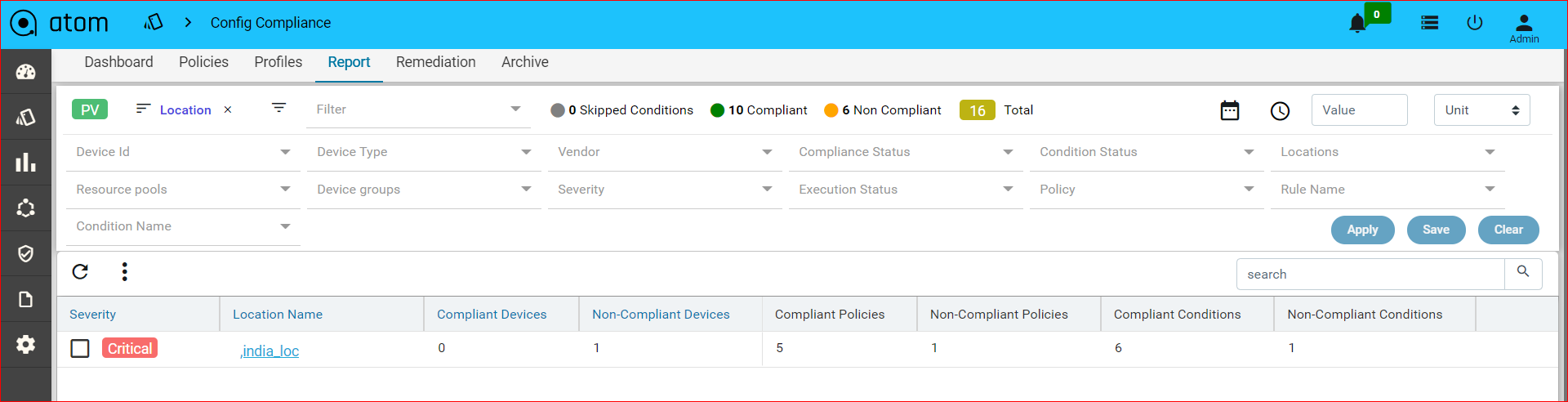
Severity: The aggregated severity of that particular locations
Location Name: Displays all available locations over which compliance is run.This is the context column for pivot by location.
Compliant Devices: The number of devices that are compliant against locations
Non-Compliant Devices: The number of devices that are non-compliant against locations
Compliant Policies: The number of policies that are compliant against locations
Non-compliant Policies: The number of policies that are non-compliant against locations
Compliant Condition: The number of conditions that are compliant against locations
Non-Compliant Condition: The number of conditions that are non- compliant against locations Click on any of location name
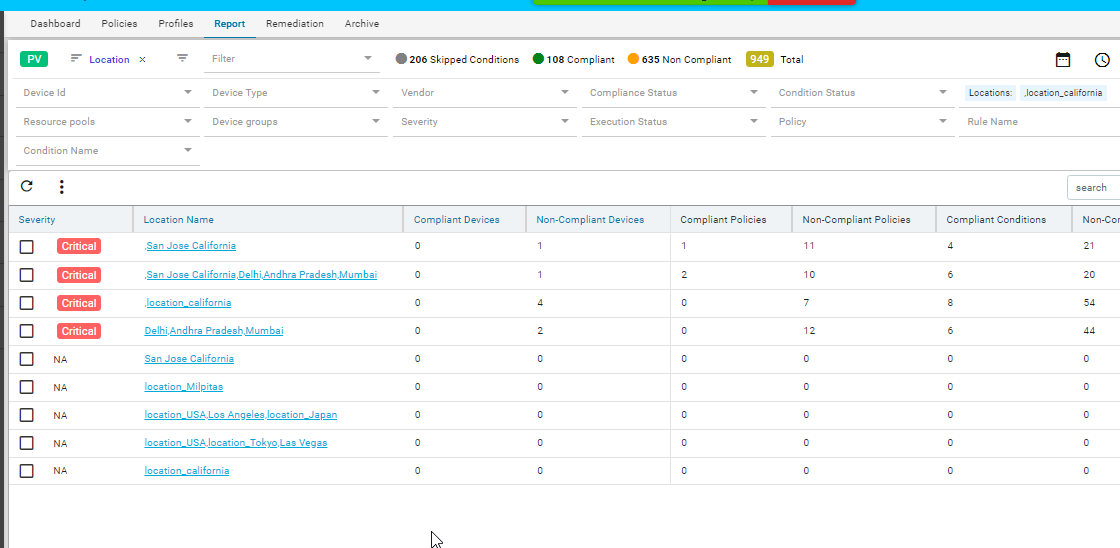
on clicking on the location name, the location filter gets applied and the user will be navigated to CRV.
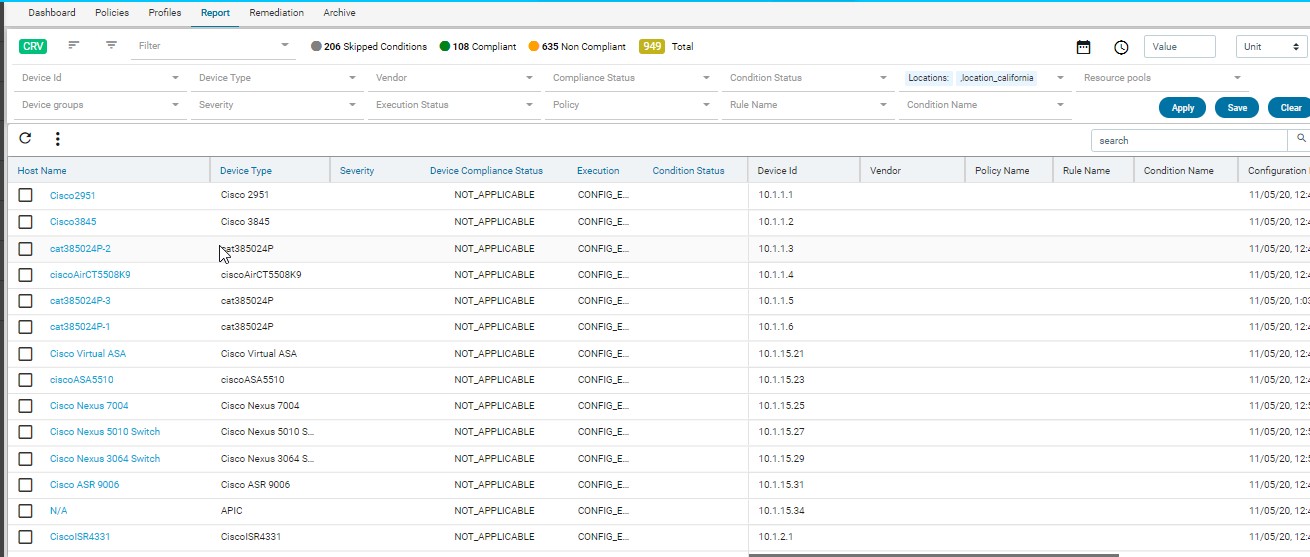
Adding the same device in multiple resource pools and each RP associated with a different location, all locations will be listed in pivot views.
Adding the same device in two resource pools and associate one RP with location and another RP with no location, only location associated with RP will be listed.
Pivot By Device Group:
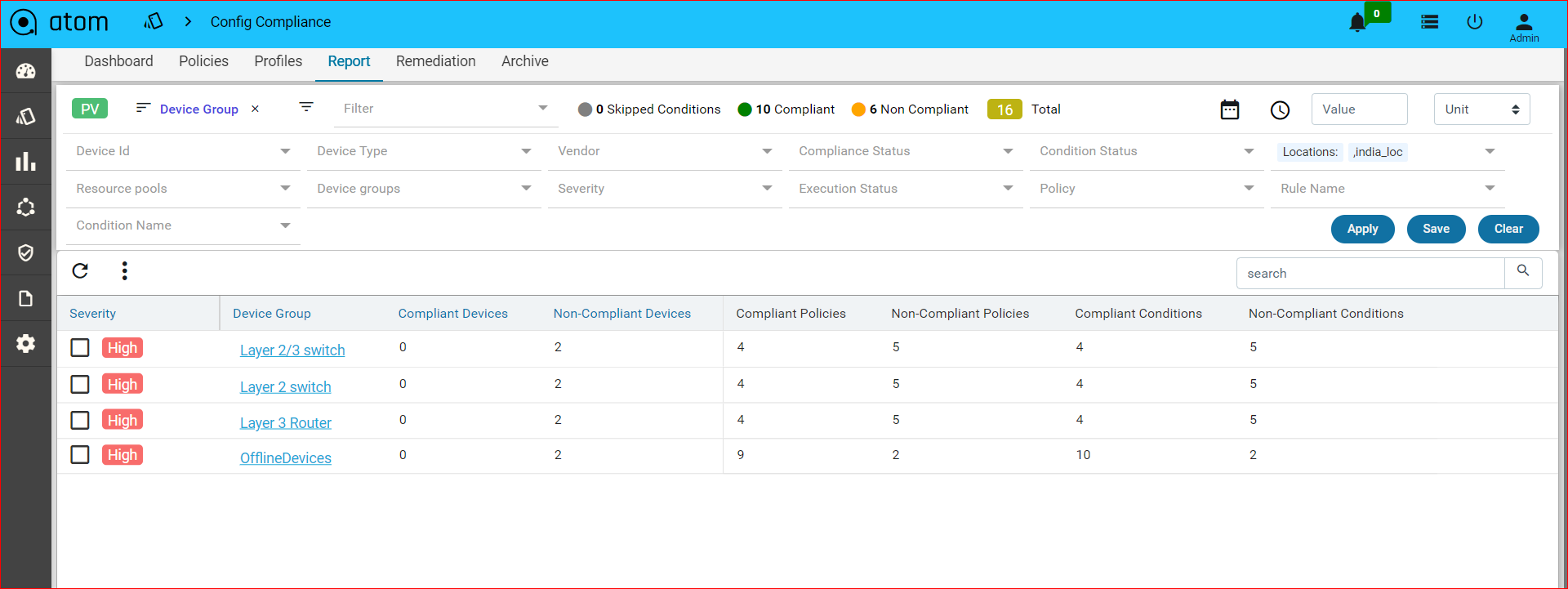
Severity: The aggregated severity of that particular Device group
Device Group: Displays all available device groups over which compliance is run. This is the context column for pivot by device group.
Devices in group: This gives the number of devices in a group
Compliant Devices: The number of devices that are compliant against device groups
Non-Compliant Devices: The number of devices that are non-compliant against device groups
Compliant Policies: The number of policies that are compliant against device groups
Non-compliant Policies: The number of policies that are non-compliant against device groups Compliant Condition: The number of conditions that are compliant against device groups Non-Compliant Condition: The number of conditions that are non- compliant against device groups.
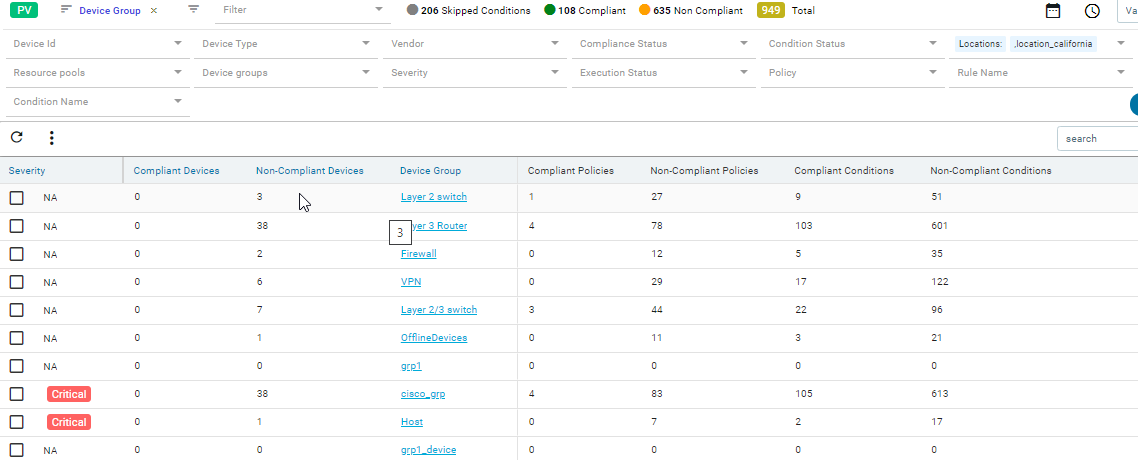 Click on any of device groups
Click on any of device groups
On clicking on the device group, the device group filter gets applied and the user will be navigated to CRV.
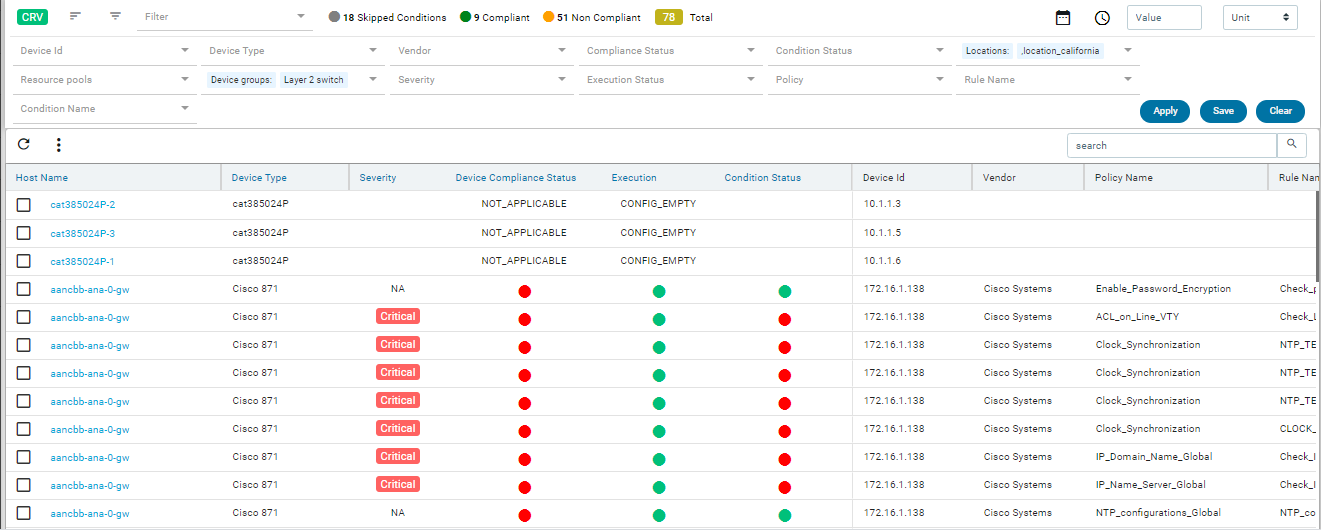
pivot view :
- Single pivot view can be selected.(no multi pivot view selection)
- Upon selecting a pivot view, further filters like device id, device type, vendor, compliance status,condition status,location,resource pool, device groups,severity,execution status,policy, rule name, condition name can be applied.
- Just with the pivot views, a filter can’t be saved, Based on further filters applied, a filter can be saved. The saved filter can be deleted.
- Bulk delete is not supported in pivot views
- Remediation is not supported
- Sorting is not supported on any column in pivot view.
- Searching is not supported in pivot view.
- The counts on top are related to the non- pivot views and labels are from condition status
- Export: based on pivot views, the records can be exported.
CRV(conditional report view) :
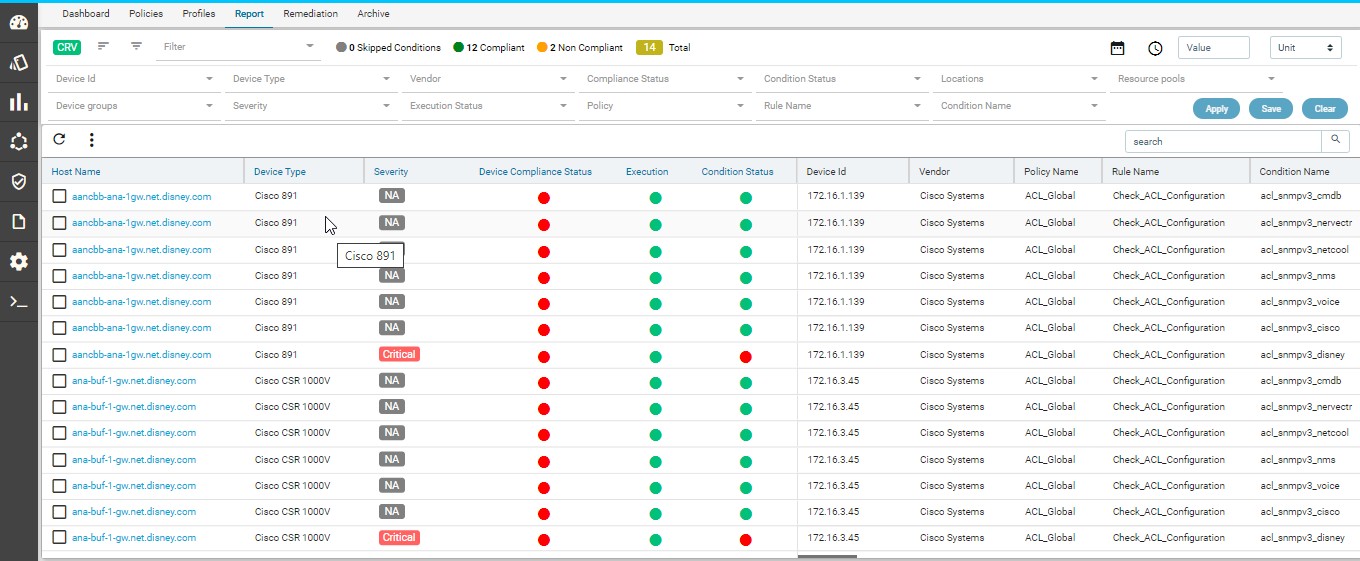
- The available columns are: Hostname, Severity, Execution, Device Type, Device compliance status, condition status, Device id, Vendor, Policy name, Rulename, Condition name, Configuration retrieved at, Expected pattern, Enforcement time.
- The data can be filtered by applying filters on device id, device type, vendor, compliance status,condition-status,location,resourcepool, device groups,severity,execution status,policy, rule name and condition name.
- Time based filtering : For timing based, user can use value and units(Days,weeks,months, hours, minutes) fields.
Date wise filter: User can choose the date from the calendar symbol and click on ‘apply’ in the calendar.
- Count band – Represents counts for skipped, compliant, and non compliant conditions
-
- Skipped conditions – Platform mismatch and Execution Status (Stale Config, Empty Config, Erros, Config Pull Failed, Offline Device) fall into this category.
- Complaint conditions – Based on conditions meeting the criteria
- Non- compliant conditions -Based on conditions meeting the criteria and violations chosen
- Multi-selection on filters is supported – More than one entry for a given filter can be selected.
- Sorting is enabled on all columns.
- Searching is enabled for all columns.
- The record details are listed when the checkbox for a given entry is selected. Device ID, Device host name, Device type, Vendor, Device compliance status, Execution status, Config time, Policy name, Rule name, Condition ID, Condition status, Expected pattern, Action Details, Remediation commands( if it’s non-compliant) are shown as part of details.
Remediation :
Navigate to Resource Manager > Config Compliance -> Remediation
Fix CLI Action will generate the remediation CLI to be applied for each non-compliant device. Users can schedule remediation on one or more devices or execute it right away. For each device selected, ATOM will push remediation CLI to the device.
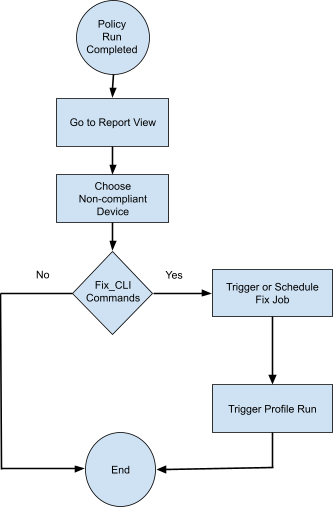
- Select a Report and click on the highlighted arrow for navigating to the Remediation screen.
Only if it is non- compliant, user will be taken to the remediation screen.
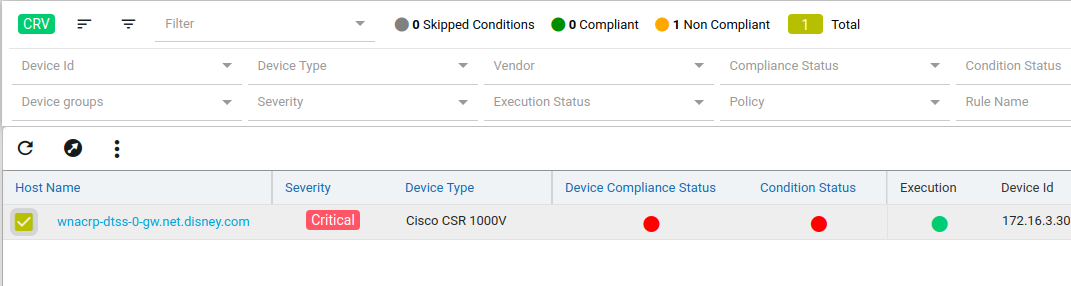
- Fix Violations by providing a Job name and verify rule-input values and fix CLI commands under Fix Configurations. Click on the tick button to complete fix-job.
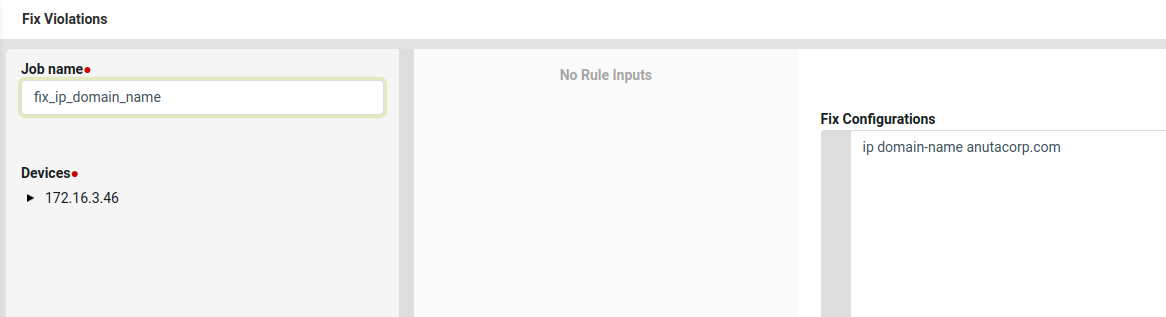
- Fix Job can be scheduled using the Schedule option or can be initiated immediately by enabling Start now. And click on the Tick button to initiate a fix-job.
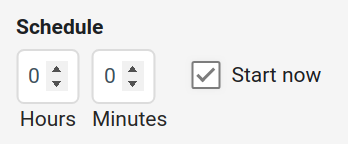
-
- Fix job can be initiated from the Remediation tab as well at a later point of time.
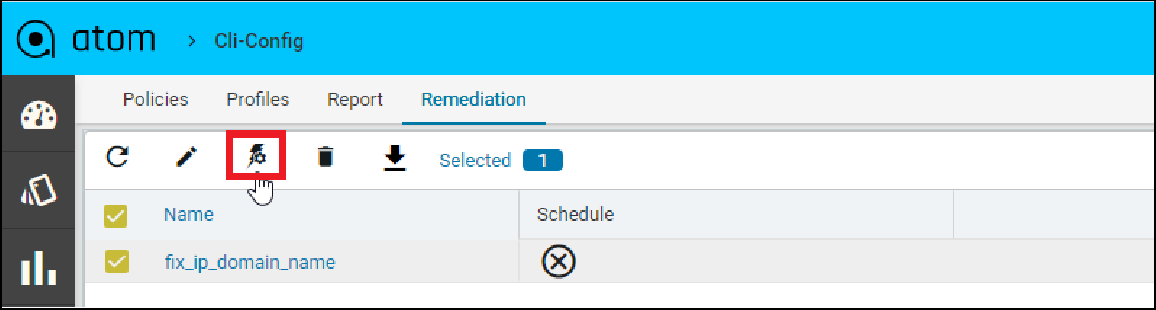
- After remediation, trigger profile job and validate the report to see if the device came back as a complaint.
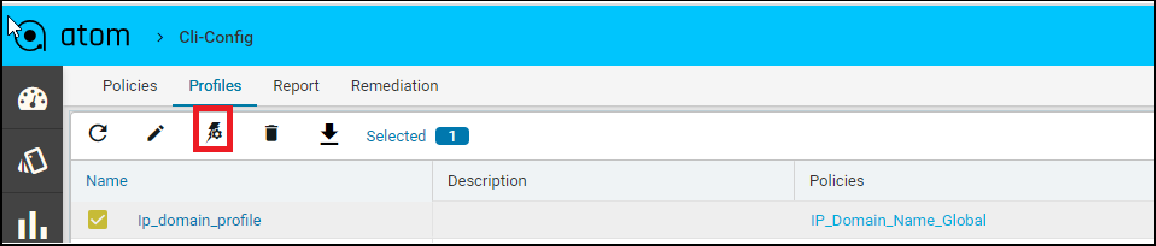
- Below we can see the device is now back to complaint after fixing violations.
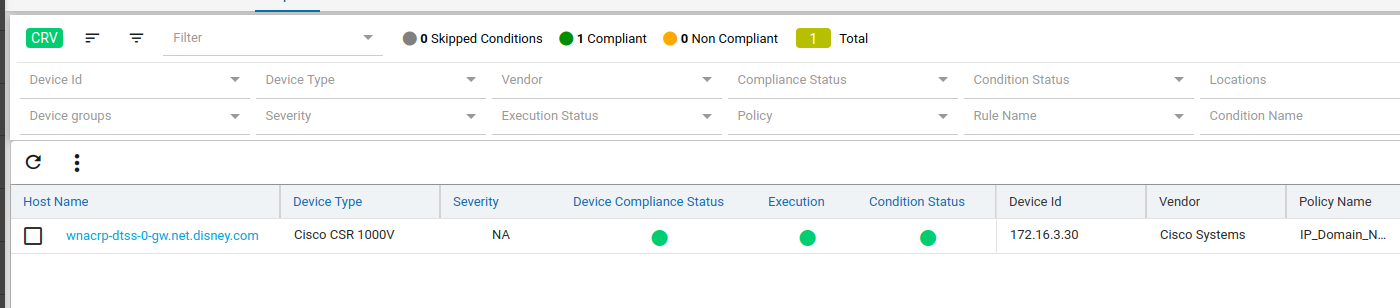
Remediation is not supported when the user is in pivot view.
Bulk delete:
Navigate to Resource Manager > Config Compliance -> reports(CRV)
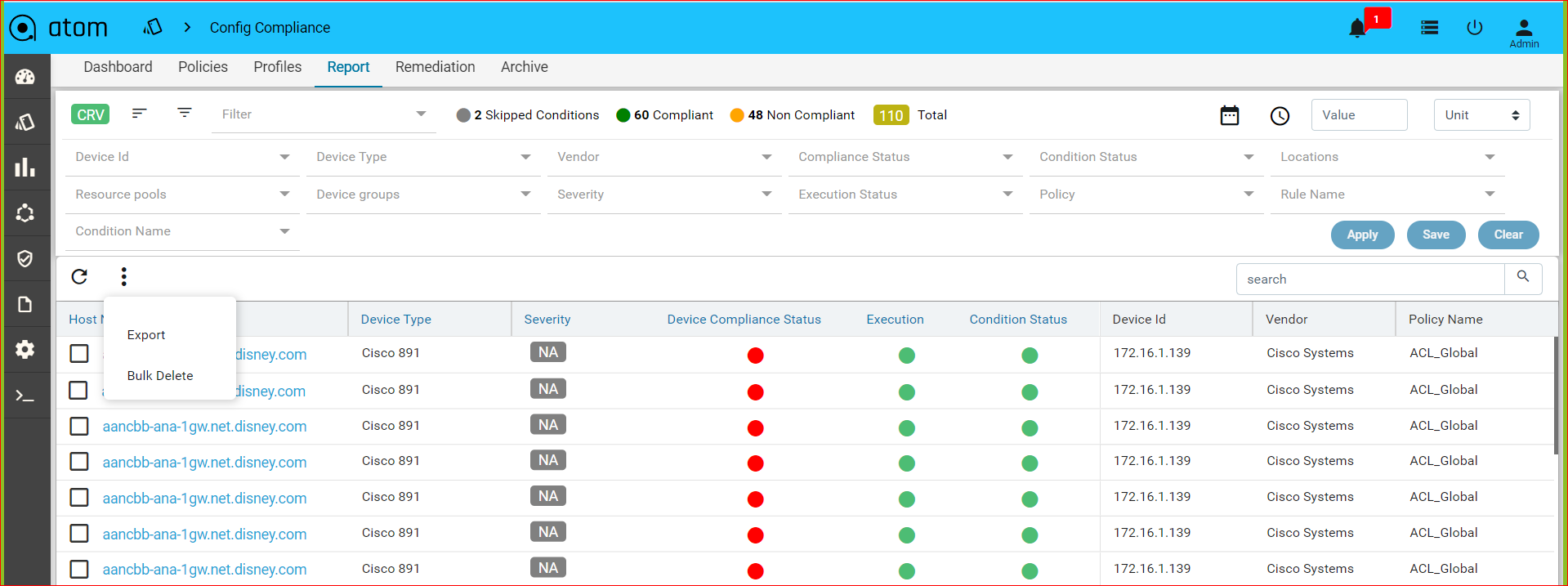
In order to delete the records at shot bulk delete is used. Based on filters applied, records can be deleted
- If the filter is on Device(device id/ device group/ device Type) And invoke Bulk delete, all the records related to devices are deleted.
- If the filter is on Policy and Bulk delete is invoked,all the records Related to policies across all devices are deleted.(columns like Policy, rule, condition, expected pattern, enforcement time- empty)
- If the filter is on device + policy and bulk delete is invoked, all the records related to policies across all devices are deleted but Device is not deleted.(columns like Policy, rule, condition, expected pattern, enforcement time- empty)
- If the filter is policy+rule+condition, where there are many rules or many conditions, records are deleted at policy level only.(records having the selected policies are deleted irrespective of rule or condition)
Purge compliance history:
In order to delete history details, we can use purge compliance history under Monitoring–> jobs→ Maintenance→ purge compliance history..
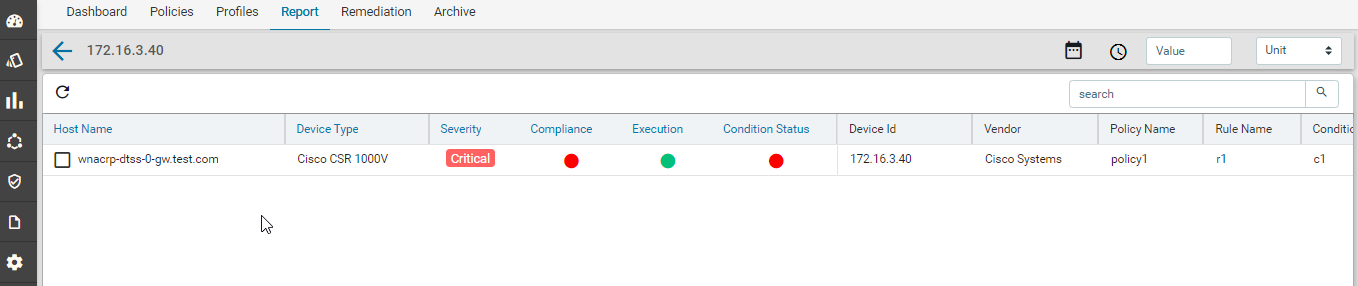
Say, the threshold is 60 and it is set for days. When this job is run, it deletes all the record history details that are older than 60 days.
It can be set in hours too.
Export:
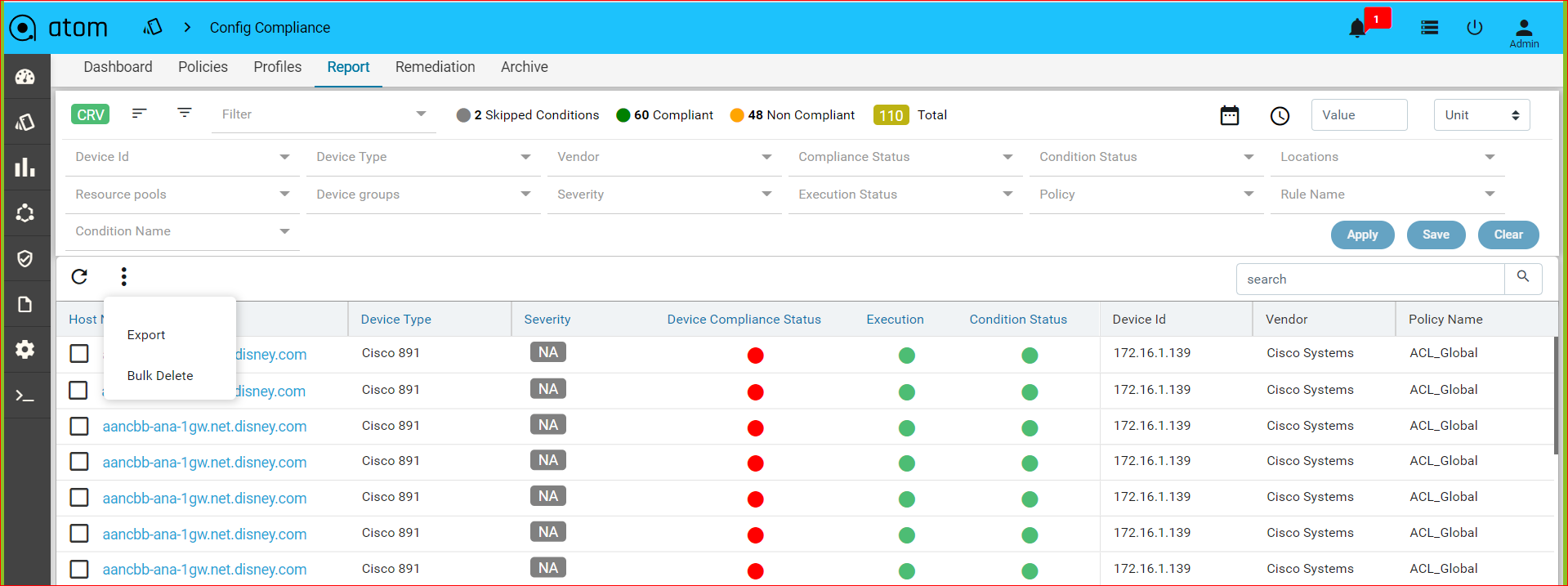 Navigate to Resource Manager > Config Compliance -> reports(CRV/Pivot) Using export will get report for all the records at one shot
Navigate to Resource Manager > Config Compliance -> reports(CRV/Pivot) Using export will get report for all the records at one shot
Upon applying filters and the user does export, then the user can get only those records. Without applying filters, if the user does export, all records are exported.
Provide a name to export file to be saved
Export file will be saved in the archive tab.
Archive:
Navigate to Resource Manager > Config Compliance -> Archive
From here we can download the report and delete as well. File download format is CSV. The headers of the downloaded csv report are according to the filter applied.
If pivot views are applied, the headers are according to it.
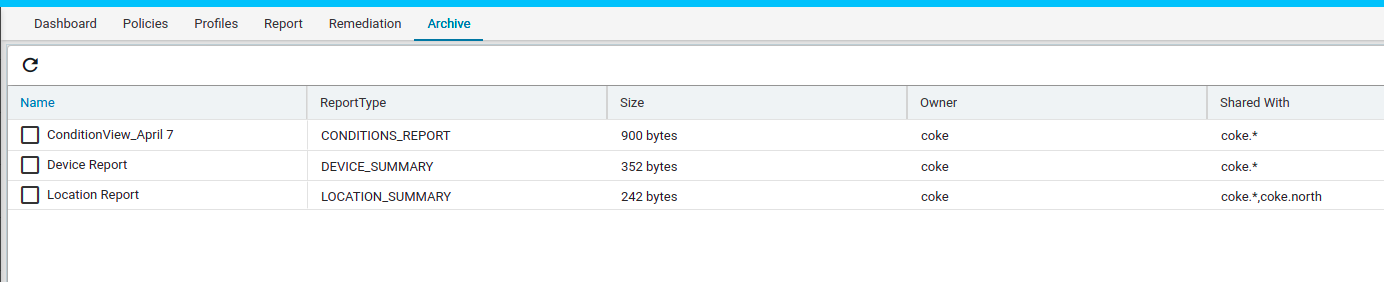

Dashboard
There are 5 Dashboards which gives a quick information about compliance status
-
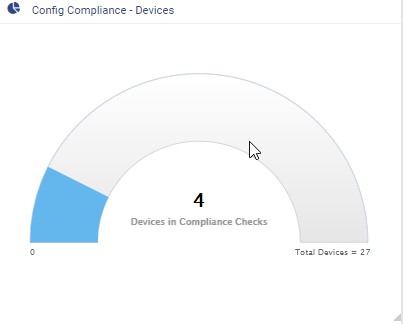 Config compliance -devices: Representing the number of devices participated in compliance v/s all the available devices in ATOM.
Config compliance -devices: Representing the number of devices participated in compliance v/s all the available devices in ATOM.- Config compliance- execution status: A pie chart representing the percentage of execution status in terms of successful, config_empty, config_stale, errors, config_pull_failed, offline_device.
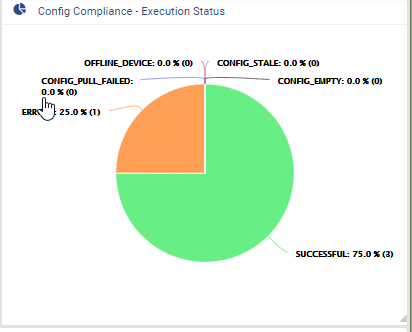
-
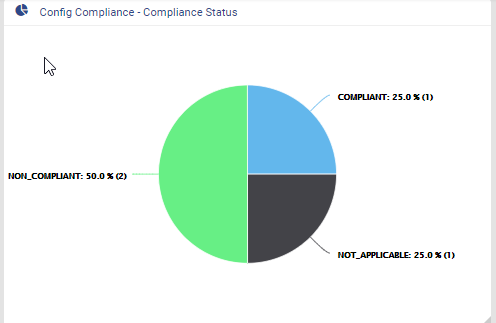 Config compliance- compliance status: A pie chart representing the percentage of compliance in terms of Complaint, Non- compliant, Not_applicable.
Config compliance- compliance status: A pie chart representing the percentage of compliance in terms of Complaint, Non- compliant, Not_applicable.- Compliance status by group: A bar graph representing compliance status such as complaint, non-compliant, not_applicable for each and every device group on which compliance profile jobs are run.
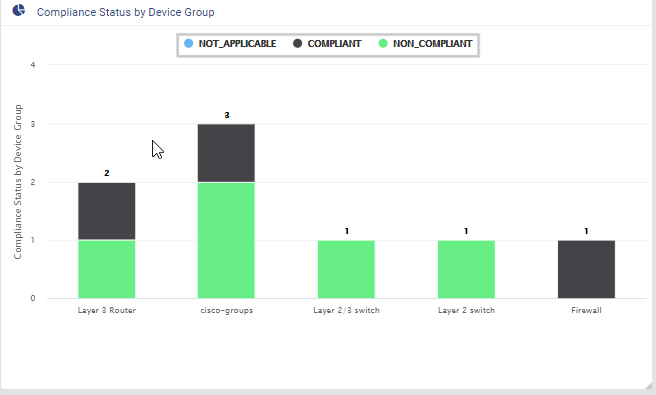
-
- Execution status by device group: A bar graph representing execution status such as config pull failed, not applicable, config_stale, errors, offline device, successful, config_empty for each and every device group on which compliance profile jobs are run.
Upon clicking on any of the dashboards, the user is navigated to CRV.
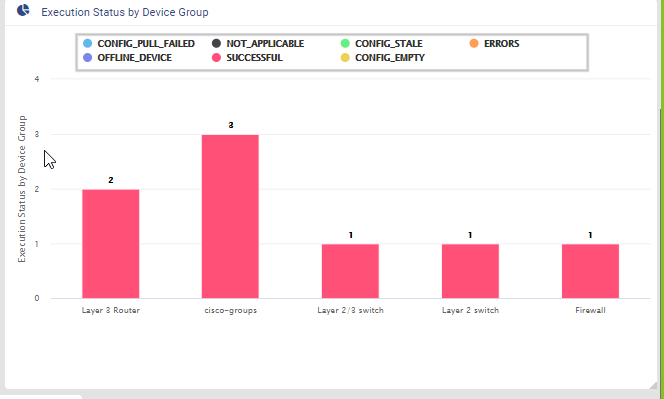
Upon clicking on any of the dashboards, the user is navigated to CRV.
FAQ’s
- We have a multi-vendor network, can ATOM help ensure compliance in my environment?
ATOM supports compliance management for Cisco, Juniper and Fortigate at this point in time.
- We want to standardize the network configs even before introducing automation, can ATOM help?
The standard configurations can be defined explicitly in ATOM’s compliance framework. ATOM will perform compliance checks against the network and perform remediation in case of non-compliance to standardize the network configurations.
- We already have a platform which checks for compliance, but the remediation is manual, can ATOM help ?
Yes, ATOM is capable of performing remediation on non-compliant devices. The Fix-CLI or derived CLIs can be scheduled or executed immediately to fix all non-compliance issues in the network.
- Can we schedule compliance checks periodically using ATOM ?
Yes, the profiling section in ATOM’s compliance framework supports scheduling of compliance checks against a device or a group of devices
- Can ATOM’s compliance help in achieving regulatory compliance ?
Yes, based on the policies that regulatory authorities specify, ATOM’s compliance management framework can be configured to meet these requirements.
- We have multiple checks that need to be run on the network, can ATOM help handle this scenario ?
ATOM’s profiling section supports grouping of multiple policies
Appendix
- Writing Jinja template configurations based on Test Result output
Below is a sample output from the test result obtained in Launching Test Config. This helps writing jinja2 templates as required in use case requirements.
{
“compliance-policies”: { “highest-severity”: “”, “rule-violation-count”: 0,
“compliance-status”: “compliant”, “compliant-rules-output”: { “violated-conditions”: “”,
“device-compliance-condition-output”: {
“block-start-unmatched-content”: “<![CDATA[]]>”, “block-start-condition-search-output”: “<![CDATA[{ “block_start_matched_contents” : []
}]]>”,
“condition-search-output”: “<![CDATA[{ “matched_contents” : [ {
“groups” : [ {
“index” : 1,
“grep_content” : “1.1.1.1”,
“grep_group” : 1
} ]
}, {
} ]
}]]>”,
“groups” : [ {
“index” : 1,
“grep_content” : “2.2.2.2”,
“grep_group” : 1
} ]
“total-block-count”: 2,
“aggregated-condition-ouput”: “<![CDATA[{ “condition_contents” : [ {
} ]
}]]>”,
“condition_id” : null, “block_start_matched_content” : null, “block_start_unmatched_content” : null, “unmatched_content” : null, “matched_content” : null
“template-substituted-content”: “<![CDATA[ntp server (?!10.0.0.1)(d+.d+.d+.d+)]]>”, “block-unmatch-count”: 0,
“cli-match-output”: “<![CDATA[ntp server 1.1.1.1 ntp server 2.2.2.2
]]>”,
“condition-status”: true,
“unmatched-content”: “<![CDATA[]]>”, “id”: “Remove_NTP_Extra_Config”, “block-match-count”: 2,
“cli-unmatch-output”: “<![CDATA[]]>”
},
“name”: “test-condition”, “failed-conditions”: “”
}
}
}
| Keys | Condition value | Jinja2 template |
| matched_contents –when matched with | ntp server (?!10.0.0.1)(d+.d+.d+.d+) | {% for content in matched_contents -%}
{% for group in content[“groups”] –%} no ntp server {{ group[“grep_content”] }} {%- endfor %} {% endfor %} |
| regex in the condition | ||
| value with the test | ||
| configuration. | ||
| unmatched_contents -when matches with the regex and does not match with the block config in the condition value with the test configuration. | line vty (.*) session-timeout {{ session_timeout }}
exec-timeout {{ exec_timeout }} 0 |
{% for content in unmatched_contents %}
{% for group in content[“groups”] %} line vty {{ group[“grep_content”] }} session-timeout {{ session_timeout }} exec-timeout {{ exec_timeout }} 0 |
| exit
{% endfor %} {% endfor %} |
||
| condition_contents -condition1 captured data will be accessible to condition2 using condition_contents. | condition1: interface Loopback0 ip address (d+.d+.d+.d+) (d+.d+.d+.d+)
condition2: router ospf (.*) router-id {{ condition_contents[0][“ma tched_content”][“matched _contents”][0][“groups”][0 ][“grep_content”] }} |
{% for content in unmatched_contents %}
{% for group in content[“groups”] %} router ospf {{ group[“grep_content”] }} router-id {{ condition_contents[0][“matched_c ontent”][“matched_contents”][0][“ groups”][0][“grep_content”] }} exit {% endfor %} {% endfor %} |
Collections in ATOM
ATOM collects network operational & performance data from multiple data sources such as SNMP, Streaming Telemetry, SNMP Traps and Syslog.
Appropriate data source and data stream can be chosen based on device capabilities, and throughput and latency requirements. Model-Driven Telemetry uses a push model and provides near real-time access to operational & performance statistics.
The collected Operational and Performance data can be visualized using Grafana (available as part of ATOM package) or in ATOM UI (by using various built-in reports available in Report section or under the device view). Users can build additional dashboards customized to their interests. (See ATOM Platform Guide to know more on how to create custom dashboards).
Jobs
A Job is the configurable task on a device that can be managed by ATOM. A job thus created can be a piece of work that can be created, executed and tracked in ATOM. Depending on the need, the administrator can schedule and manually run various Jobs to collect data about the device state.
Jobs are classified into the following types:
- Collection Job
- Configuration Job
- Diagnostics Job
- Discovery Job
- Inventory Job
- Maintenance Job
- Batch-reports Job
- SNMP-collections Job
- Syslog-collection Job
- Telemetry-Collections Job
- Telemetry-measurement Job
Collection Job
ATOM collects or retrieves the status of the device (OFFLINE or ONLINE) . By default, this job is scheduled to run every 6 hours. Starting with 6.0 release, you can model the collection job to collect information about the device using the SNMP OIDs. For more information, refer section, “Modelling of Collection Job” in the “ATOM Platform Guide.”
Configuration Job
Configuration job retrieves the running configurations from the device, or is triggered in the event of configuration discrepancies (either at the device or the service level) between the device and ATOM.
Creating a Configuration Job
-
- Navigate to Monitoring > Jobs > Configuration
- Select the Configuration folder > Add Configuration
- In the Create configuration screen, enter the values in the following fields:
- Name: Enter the name of the Job
- Description: Enter an appropriate description for the Job
- Configuration Type: Select the type of Configuration Job from the menu:
- CONFIG_RETRIEVAL – Retrieves the basic device configuration. This option is the default value.
- DEVICE_COMPLIANCE – The device compliance job is triggered when there is a violation of policy configured on the device or a set of devices. For information about the Device Compliance Policies, refer “Creating Compliance Templates”
- SERVICE_COMPLIANCE – The service compliance job is triggered when there is a discrepancy in the service configurations available on ATOM and the device.
By default, ‘ServiceInventory’ Job of type Service Compliance is triggered every 5 minutes.
- Resource Type: Select one of the following resource entities where the job should be triggered:
- DEVICE: If the selected resource type is a Device, click Add to enter the IP address of the device for ATOM to communicate with it.
- DEVICE GROUP: If the selected resource type is Device Group, click Add to enter the device group for which the configuration jobs should be triggered.
- RESOURCE POOL: Click Add to select from the available resource pools where the job should be run.
- Config Pull type: If the selected configuration type is Config Retrieval, you can opt for one of the following methods to be used while retrieving the configurations from the device:
- TFTP_EXPORT – Select this option when ATOM should retrieve configs from the TFTP server
- SHOW_COMMAND – Select this option if ATOM should retrieve configs from the running configuration of the device. This will be useful when in some customer environments where the TFTP port is disabled.
- Parse Config: Select this option if the parsing of the configurations should be enabled on the device/devices after the successful run of the config retrieval job.
- Schedule: Select the checkbox and schedule the job to be run at intervals
- Interval: Enter the time period for which the job should be scheduled
- Interval Type: Select the units of time when the job should be scheduled (HOUR or MINUTE)
Click the Task viewer to check for the status of the executed job.
Option 1: A successful run of the Config Retrieval job, where ‘TFTP Export’ enabled, fetches the following details from the device:
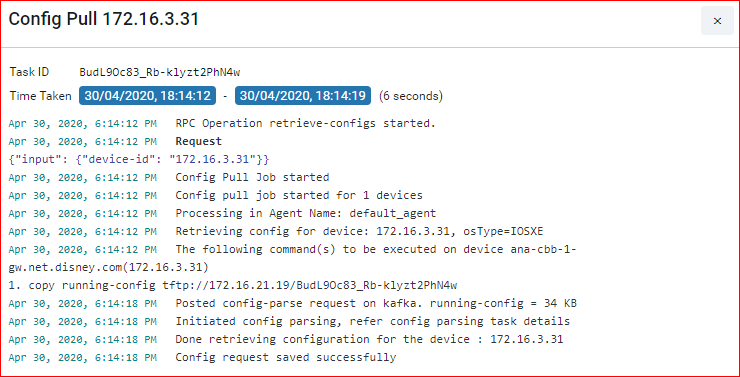
Case 2: A successful run of the Config Retrieval Job, with ‘show run config’, is shown as below:
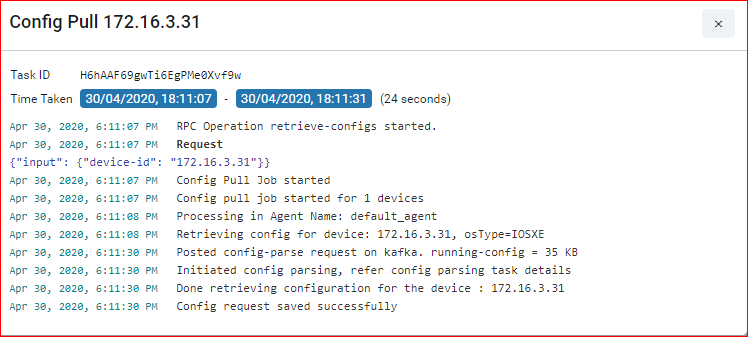
Diagnostics Job
Diagnostics job collects various CPU, memory utilization and interface performance data that is used to provision the service. By creating a Diagnostics Job, you can run the basic device Telnet or SNMP connections to the device and also perform module- level diagnostics.
Creating a Diagnostics Job
- Navigate to Monitoring > Jobs > Diagnostic
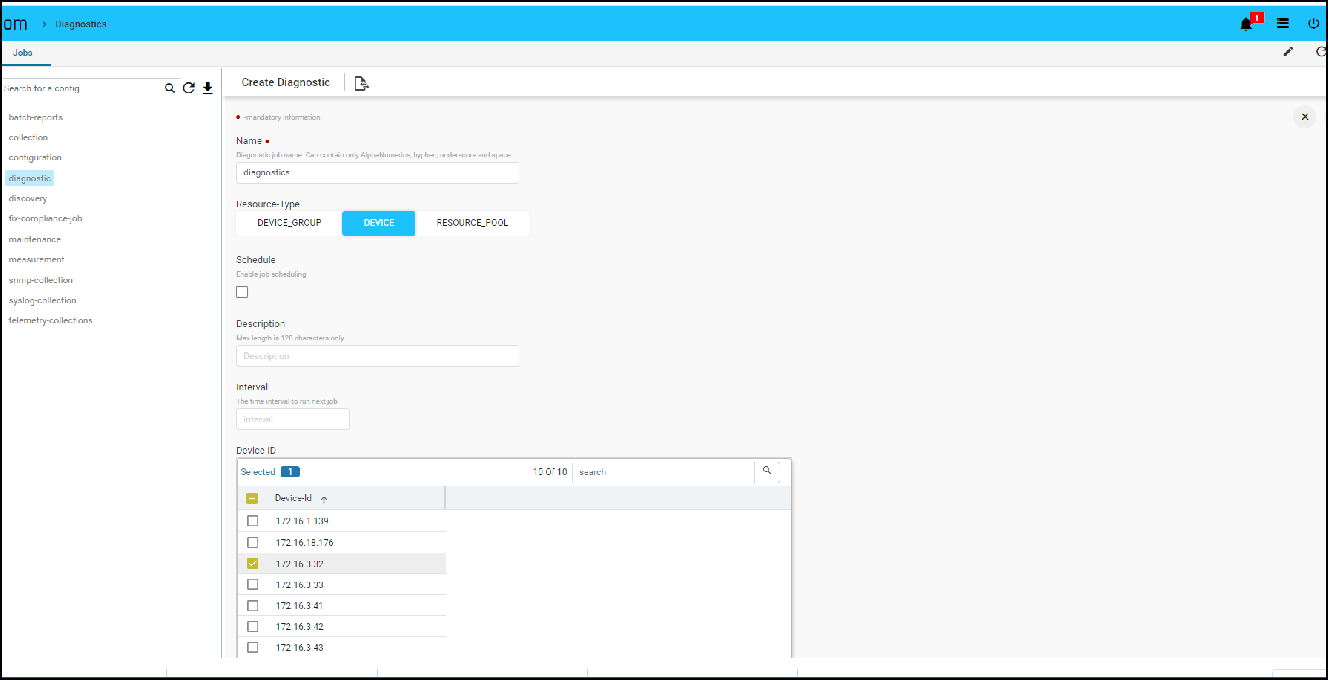
- Select Diagnostic and click Actions > Add Job
- In the Add Diagnostic screen, enter values in the following fields:
- Name: Enter a name not exceeding 64 characters
- Description: Type an appropriate description for the job.
- Resource Type: Select one of the entities where the job should be run
- Device: Enter the IP address of the device
- Device Group: Select a device group from the drop-down list.
- Resource Pool: Select the resource pool from the available resource pools in ATOM.
- Schedule: Select this option to run the job in specific intervals of time
- Interval: Enter a number representing a span of time.
- Interval Type: Select the units of time (minute or hour)
Click the Task Viewer pane and search for the Diagnostics job. A successful run of the Diagnostic Job displays the following information in the task details:
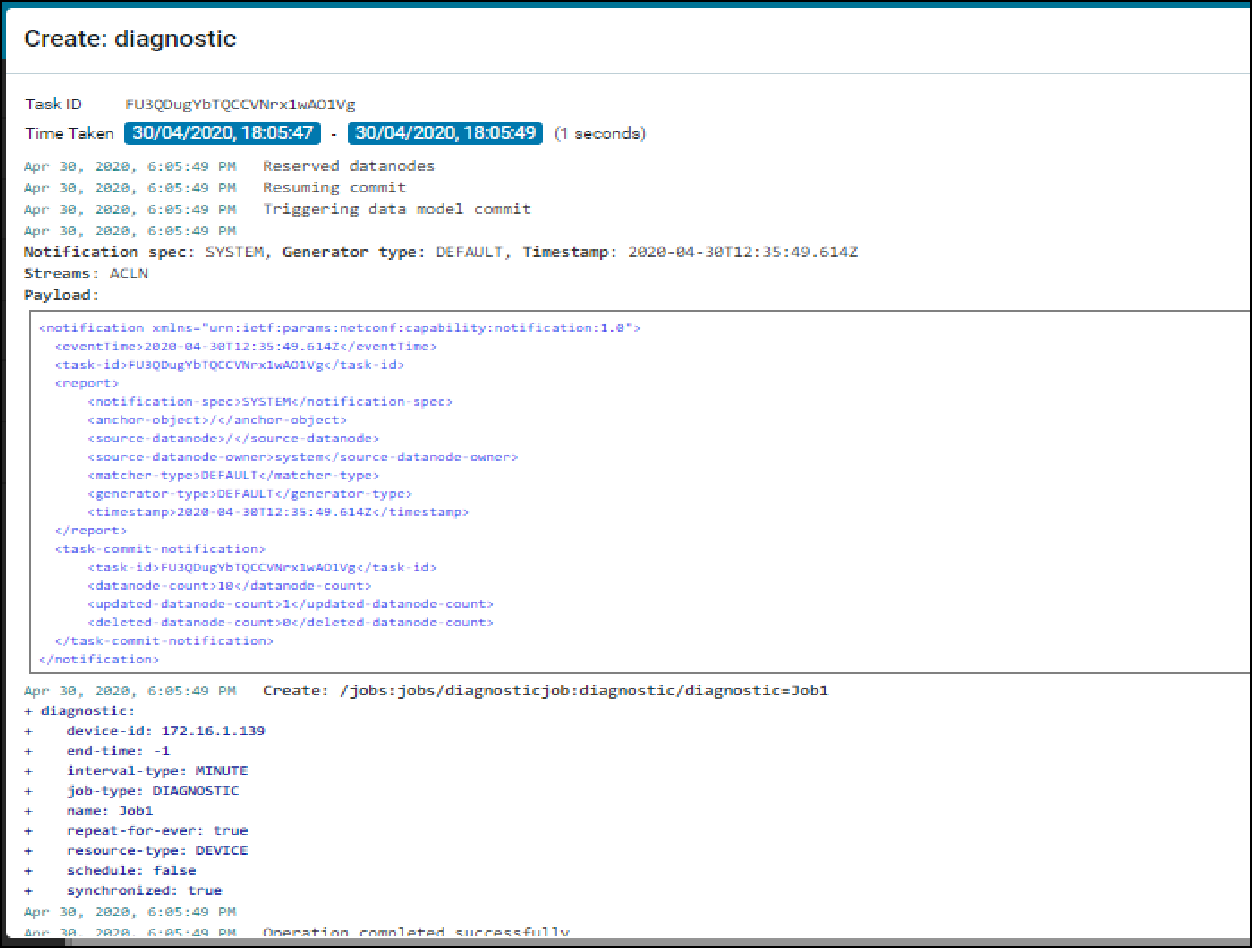
Discovery Job
Discovery job is used in discovery of the devices falling within a range of IP addresses.
The first step in provisioning a network is discovering the devices in the network. ATOM discovers the devices in the pod using either CDP or LLDP. Based on this discovery, ATOM automatically draws a network topology diagram.
If only SNMP is enabled, the topology diagram cannot be drawn as SNMP does just the sweep, which is not a methodical way of discovering device hierarchy. Therefore, it should be ensured that either CDP or LLDP is enabled on all the devices managed by ATOM.
A SEED device is the starting point from which ATOM discovers the network and its peers or neighbor devices. SEED discovery type should be selected when devices in a smaller range are required in the topology. This method of discovery is quicker, but fewer number of devices are discovered.
If the selected discovery type is SWEEP, the devices within a range of IP addresses are discovered.
Creating a Discovery Job
- Navigate to Monitoring > Jobs > Discovery > Add Discovery
- In the Create Discovery screen, enter values for the mandatory fields:
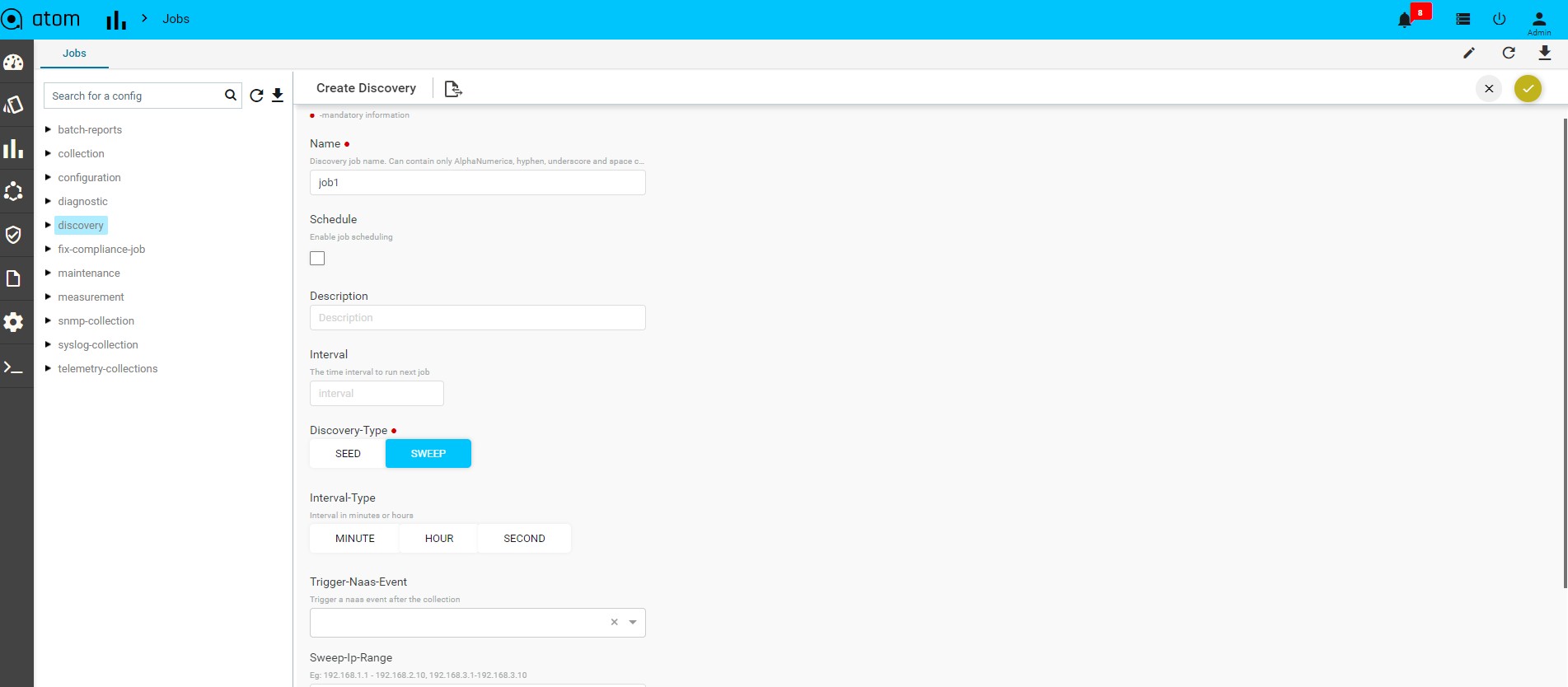
-
- Name: Enter an alphanumeric string to identify the created discovery job
- Description: Enter some text that describes the Job
- Discovery Type: Select one of the discovery protocols that used for discovering devices:
- SEED – By default, the discovery type is SEED.
- SWEEP – Change the value to SWEEP, if you want more devices to be discovered.
- Seed Type: Select the type of the seed protocol, either CDP or LLDP. In case the Discovery type is selected as SWEEP, enter the SWEEP IP range in the field.
-
- Hop Count: Enter the number of hops (devices)that ATOM should discover from the seed device while using CDP.
- Seed IP Address: Enter the IP Address of the seed device from which the discovery of the neighbouring devices should be initiated.
- Auto manage: Select this option to add the discovered devices to ATOM automatically.
If this option is selected, a Managed Task is generated after the successful run of the discovery job.
-
- Schedule: Select this option if this job should be scheduled at prescribed time intervals.
- Interval: Enter the period of time within which the job should be scheduled
- Interval Type: Enter the units of time (HOUR or MINUTE)
- Schedule: Select this option if this job should be scheduled at prescribed time intervals.
A successful run of the Discovery Job with the SWEEP protocol is as shown as below:
Details of the Executed Job along with the devices that are discovered by ATOM in this job are displayed as follows:
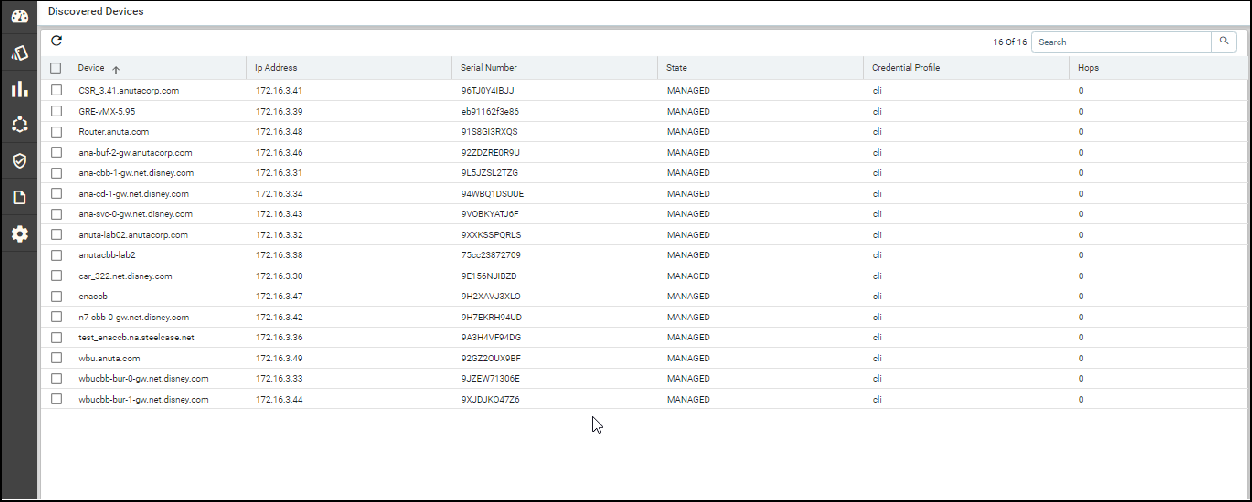
Managed Task
This task will be triggered in ATOM after the successful run of the discovery job. All the discovered devices are added to the device table maintained in the ATOM inventory are marked as “Managed” devices
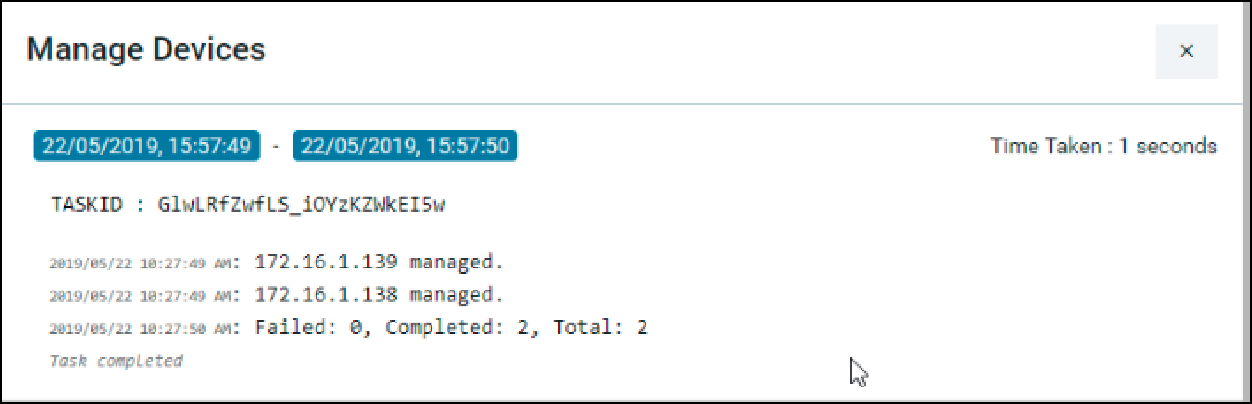
Inventory Job
Inventory job is used for detecting and adding device Interfaces, interface capabilities, and interface addresses.
Extended Inventory: Retrieves the lost network connections, establishes the new network connections between the devices, retrieves the configurations from the device, By default, this job is scheduled to run every 12 hours.
Maintenance Job
You can configure the maintenance jobs to remove unwanted records of the tasks or the alarms in ATOM. The maintenance jobs can be scheduled on a one-time basis or run periodically.
Purge Older Alarm Records (You can remove unwanted, older records of the Alarms generated in ATOM.)
Creating a Purge Older Alarm Records Job
- Navigate to Resource Manager > Jobs
- In the left pane, navigate to the MAINTENANCE folder
- Click the MAINTENANCE folder > Actions > Add Job
- In the Create MAINTENANCE screen, enter the values for each field described below:
- Maintenance Job Name: Enter a name for the maintenance job to be created.
- Description: Enter a suitable description for the job
- Maintenance Type: Select the type as “ PURGE_OLDER_ALARM_RECORDS“ to create a job to clean all the old Alarms from ATOM
- Threshold (in days): Enter a number of days, of which the records for which history should be maintained. All the records before the prescribed days will be deleted.
-
- Schedule: In order to schedule the job to run periodically at specified intervals of time, select the Schedule option.
- Interval: Enter the number for the interval
- Interval Type: Select either Hour or Minute as units of time. Example:
If 30, 24, and HOUR are entered as values in the fields – Threshold, Interval, and Interval Type respectively, a maintenance job is executed every 24 hours that will remove all the Alarm records older than 30 days. That is, all the records of the previous month before the 30th day will be deleted..
Purge Older Task Details Records
You can schedule a maintenance job that can be run to remove all the details of the tasks run before a specified period in time.
Creating a Purge Older Task Details Records
- Navigate to Monitoring> Jobs
- In the left pane, navigate to the maintenance folder
- Click the maintenance folder > Actions > Add Job
- In the Create maintenance screen, enter the values for each field described below:
- Maintenance Job Name: Enter a name for the maintenance job to be created.
- Description: Enter a suitable description for the job
- Maintenance Type: Select the type as “ PURGE_OLDER_TASK_RECORDS“ to create a job to clean all the details of the tasks
- Threshold (in days): Enter a number of days, of which the records for which history should be maintained. All the records before the prescribed days will be deleted.
- Schedule: In order to schedule the job to run periodically at specified intervals of time, select the Schedule option.
- Interval: Enter the number for the interval
- Interval Type: Select either Hour or Minute as units of time. Example
If 30, 24, and HOUR are entered as values in the fields – Threshold, Interval, and Interval Type respectively, a maintenance job is executed every 24 hours that will remove all the details of the tasks older than 30 days. That is, all those task details of the previous month before the 30th day will be deleted.
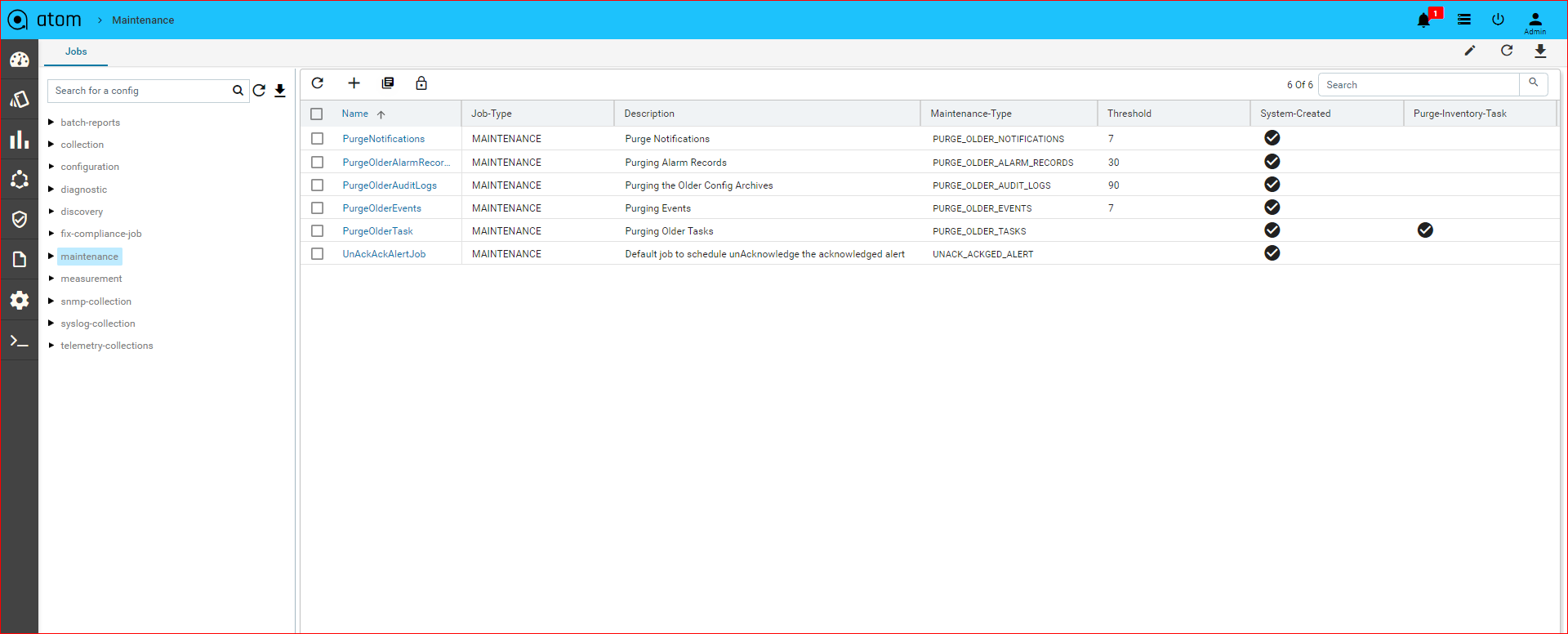
Device Inventory (SNMP)
All Device inventory collected through SNMP Collection jobs is shown in the Entities view. Following provides guidance on
- To view Device Configuration – Navigate to Devices > select a device
- Click on the “Monitoring” Tab
- Collected data will be shown under MIB-name
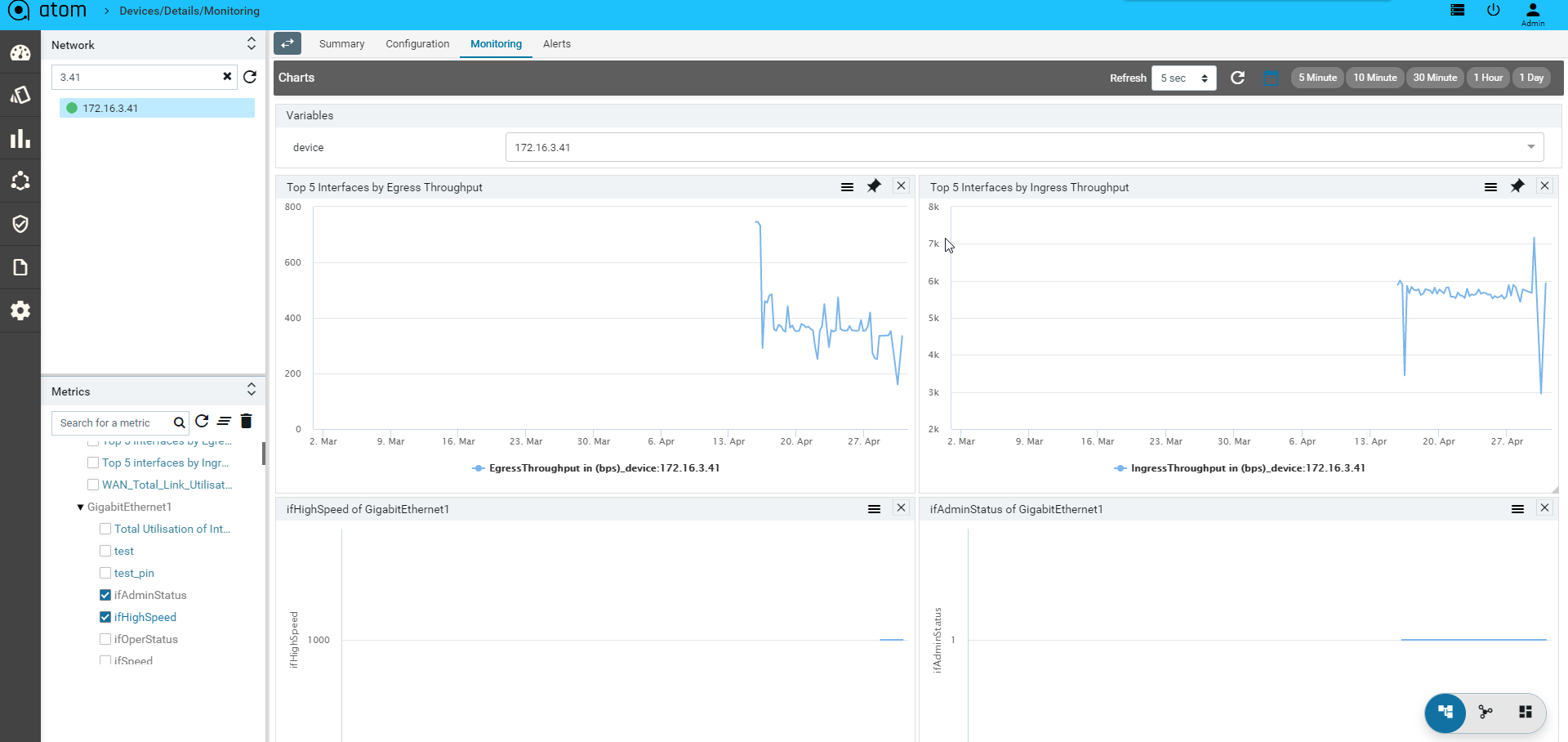
Monitoring
[[[ ATOM enables you to create Assurance profiles to facilitate 24×7 uptime of your network. Closed loop automation (CLA) framework allows you to define policies and remediation actions in violation of those policies.ATOM collects operational & performance metrics from multiple data sources such as SNMP, SNMP traps, Syslog and Streaming Telemetry and stores them in a time-series database.
Following are the different activities on the metrics:
- Visualize Data Using Charts & Reports
- Alerts against thresholds defined on the Metrics
- Alert Dashboards – Collection of Predefined & User Defined Dashlets
- Alert Routing to Email, Slack etc.,
- Actions on Alerts
- Closed Loop Automation Actions on the Alerts
Please refer to “ATOM User Guide – Performance Management & Alerting” for further details.]]] ATOM enables you to create Assurance profiles to facilitate 24×7 uptime of your network.
Closed loop automation (CLA) framework allows you to define policies and remediation actions in violation of those policies.
ATOM collects operational & performance metrics from multiple data sources such as SNMP, SNMP traps, Syslog and Streaming Telemetry and stores them in a time-series database.
Following are the different activities on the metrics:
- Visualize Data Using Charts & Reports
- Alerts against thresholds defined on the Metrics
- Alert Dashboards – Collection of Predefined & User Defined Dashlets
- Alert Routing to Email, Slack etc.,
- Actions on Alerts
- Closed Loop Automation Actions on the Alerts
Import SNMP MIBs
ATOM allows users to import any SNMP MIBs. To use the Object identifiers (OID’s) which are part of the uploaded MIB need to be compiled by activating them.
During activation, it compiles all the dependent MIBs automatically if they are already available on the system. Otherwise, the user has to upload the dependent MIBs to compile properly.
Navigate to Administration -> Plugins and Extensions -> SNMP -> SNMP MIBs and upload a mib file
Below snapshot shows IFMIB along with its dependencies after uploading. All of them are still inactive. To activate a MIB, select a MIB entry and click on the activate button.
Once the MIB is activated, automatically its dependencies get activated as shown in the snapshot below.
After compilation (activation), it will extract all the OIDs from each MIB and can be seen on Administration -> Plugins and Extensions -> SNMP -> SNMP OID Map.
For each OID, it will extract the following properties:
- Fetch Type: Identifies the snmp fetch type such as GET or WALK
- Is Accessible : Is it actual OID or the tabular header
- Key OID’s : Lists out the all key oids for each oid
By Default, ATOM uses the MIB name as the default in device monitoring trees. To provide an alias, specify the entity name.
Note:: Navigate->Administration->Plugin & Extension->Packages:: We have other option to upload the mib packages are IF-MIB, Host -resource-mib,Cisco Process-Mib, bgp4 mib are etc.
To activate a MIB, select a MIB entry and click on the activate button.
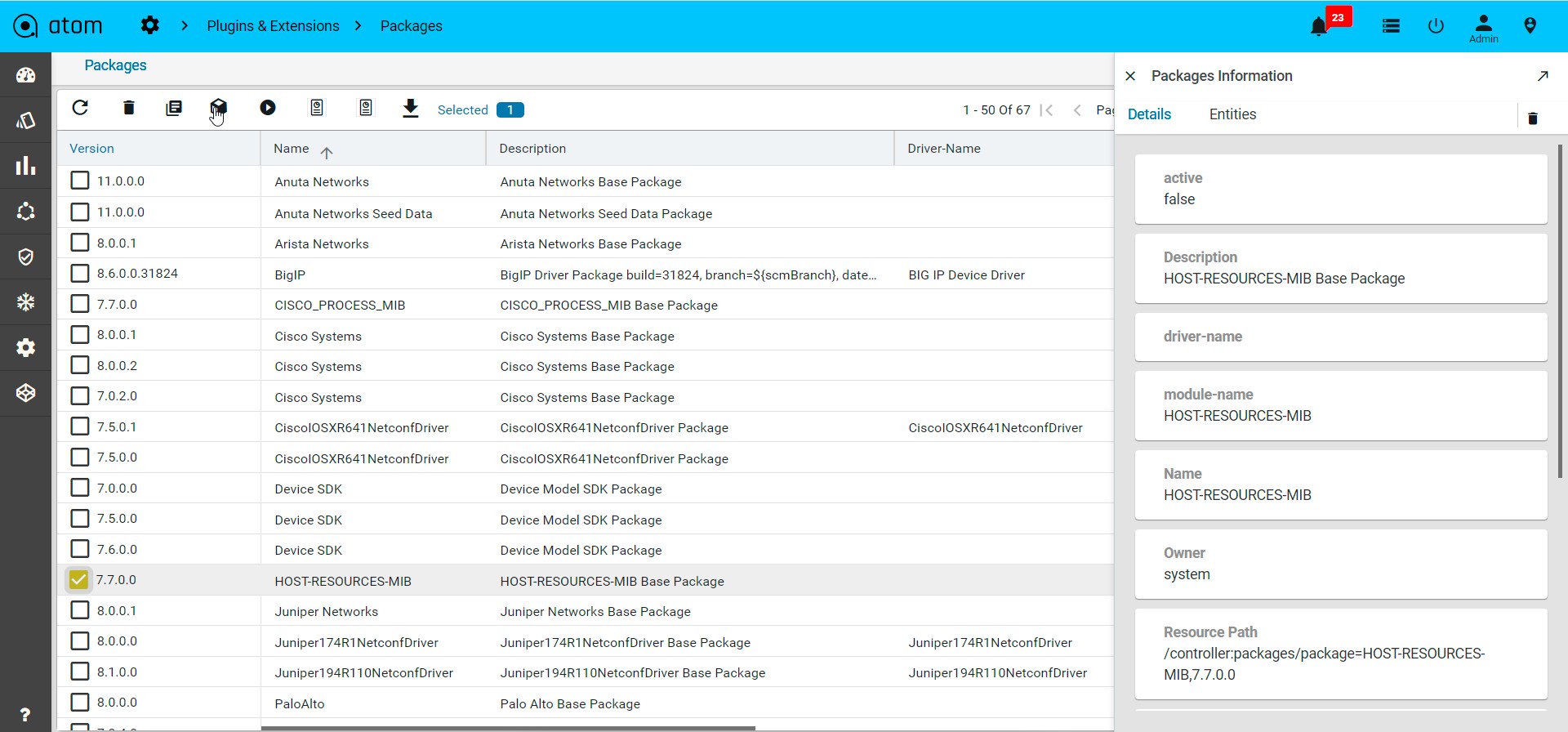
SNMP
SNMP Collections can be created for collecting Inventory information from the devices, checking the health of the devices, to measure performance of Network Objects and discovering the neighbours of the device.
- From the left pane, navigate to Monitoring > SNMP
- Click Add (+) to create a new SNMP collection profile
- In the New Inventory Collection screen, enter the following details in the Collection package tab
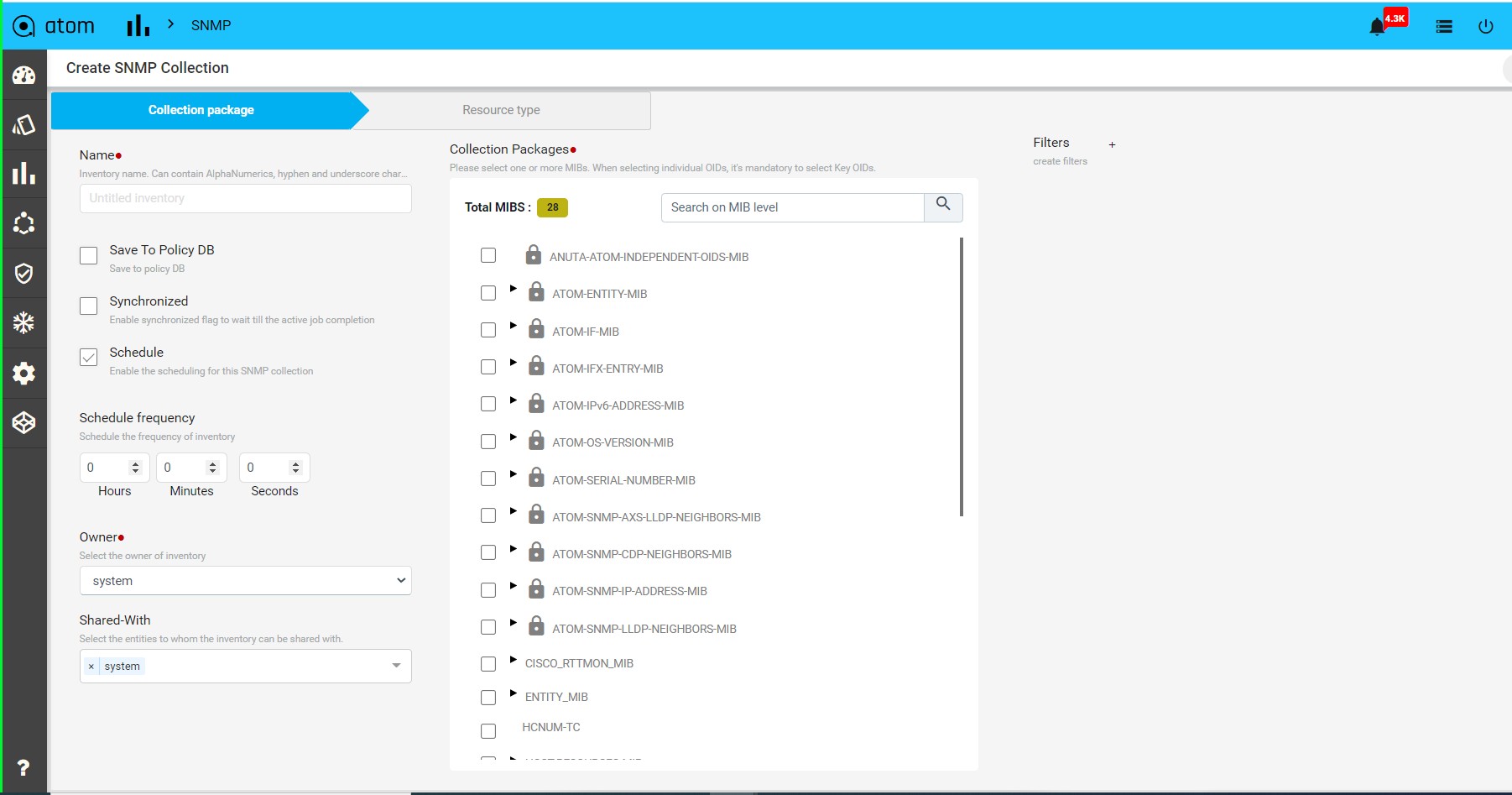
-
- Name: Enter the appropriate name for the collection.
- Synchronized: It makes scheduled collection at regular tight intervals when it is set to true.
eg: if we are polling the device every 1min to collect Interface counters but the device hasn’t responded for previous requests as it has too many objects to gather. So, when we set the synchronized flag to true, it waits until the previous request is completed by the device. Otherwise, it makes continuous requests at regular intervals irrespective of the time spent on the device.
-
- Save to Policy DB: By default, all the metrics data will be stored in a time series database. To store anything as inventory with overridden policy, this has to be enabled. It stores the data on the ATOM policy database and it requires the YANG mappings to OID’s which can be defined as part of the device package. Refer to the ATOM SDK to generate the YANG mappings for MIB.
- Collection Packages: Choose one or more Object identifiers which can be spread across the MIBs. ATOM will automatically let the users know about mandatory key OIDs for selected Objects. For example, if a user wants to collect InterfaceInErrors then they must require the interface names to map the values correctly.
- Schedule frequency: Choose the SNMP polling frequency
- In the Resources type tab, choose the devices, device groups or resource pools to which the profile has to be applied
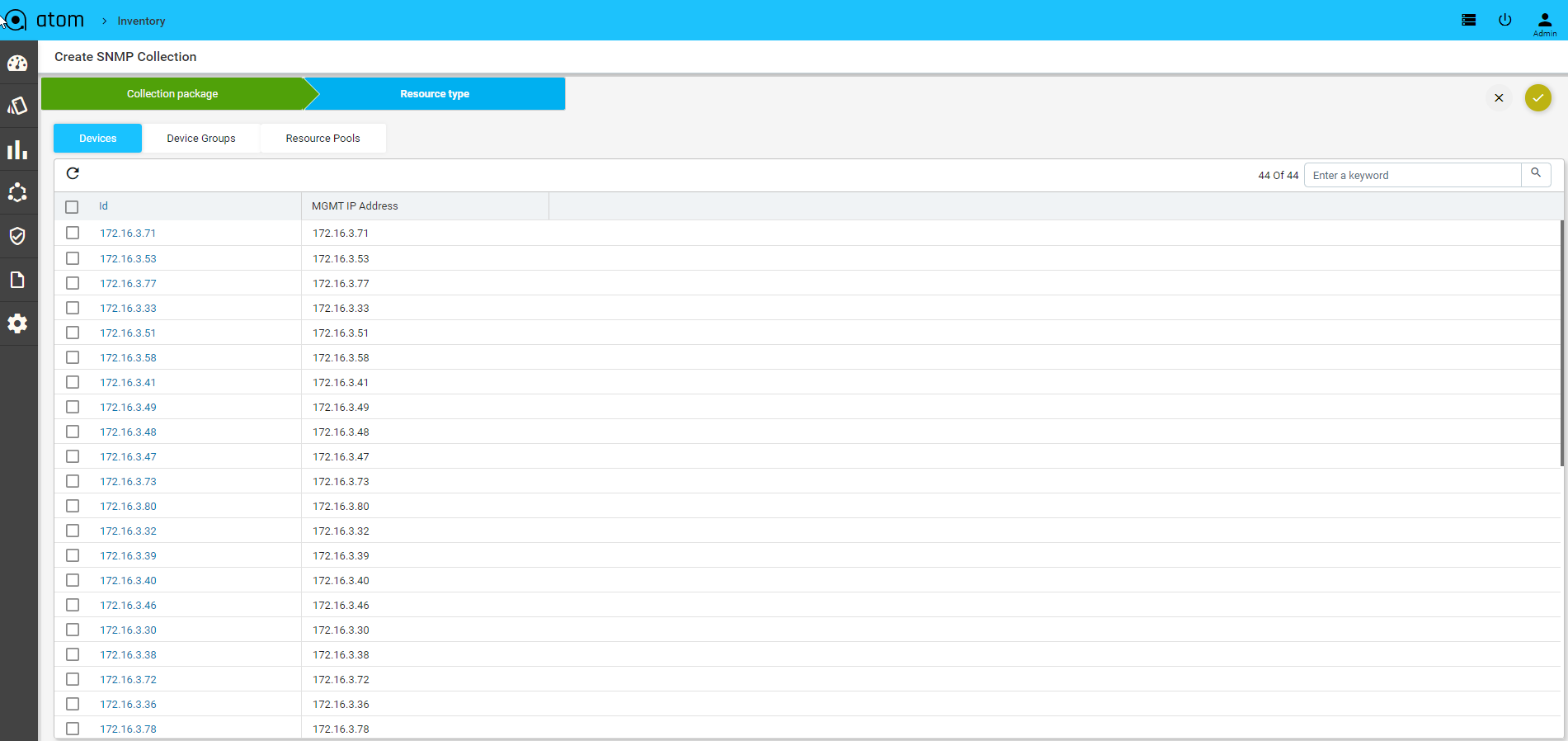
- Click ✓ to save the collection profile
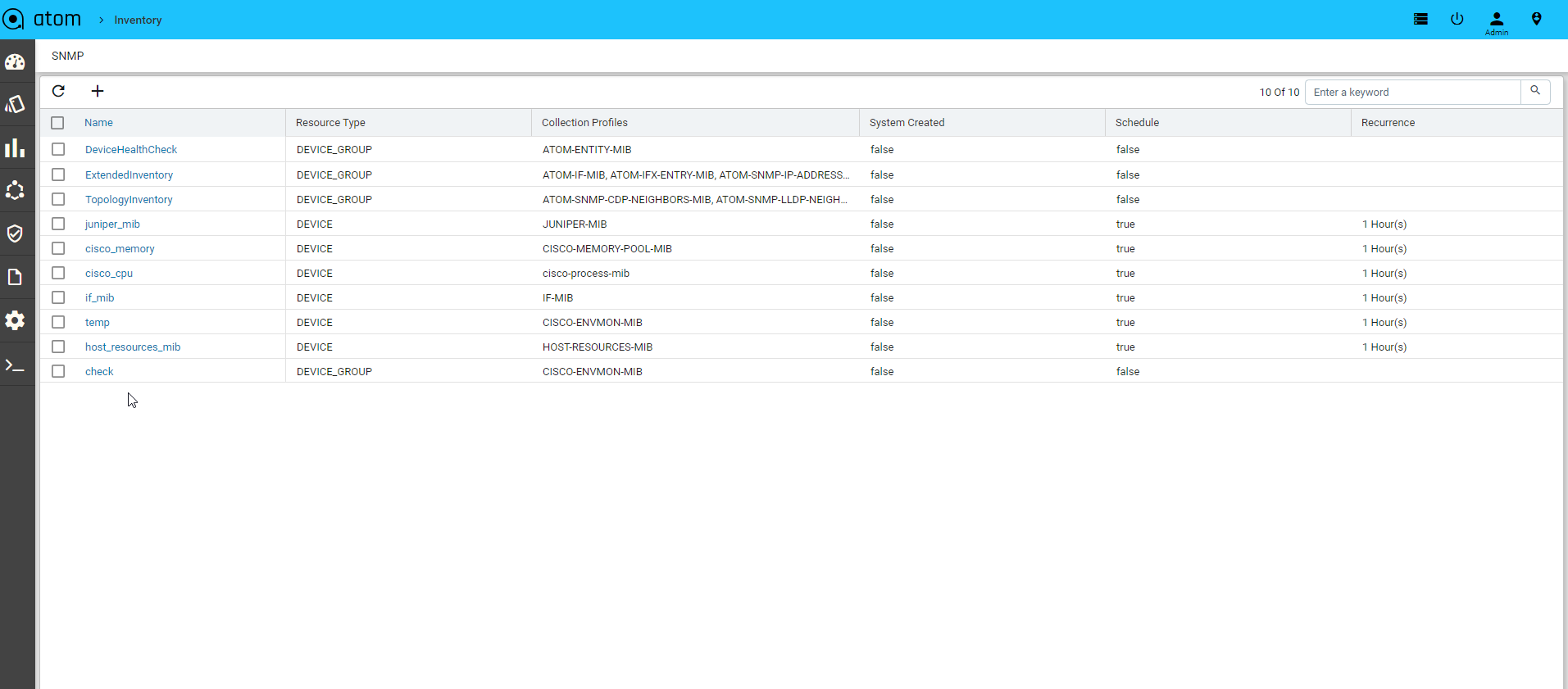
- Navigate to Monitoring > SNMP to view/modify the collection profile.
For each new collection, ATOM creates the metric schema for each MIB on every Device to showcase the metrics in logical hierarchy in device-explorer. Refer to the Metric schema customisation.
Telemetry
ATOM can act as a Telemetry receiver. ATOM Supports Model driven Telemetry, various Transport options, encoding and frequency of collection.
- Telemetry configuration in ATOM is optional if Telemetry is enabled manually on the devices
- ATOM can enable Telemetry subscription on the device. The section below discusses the steps to be followed.
Configure Telemetry Collection
- Ensure that the dry run option is unchecked in Administration > General Settings tab.
- For configuring the sensors on the device, navigate to Monitoring > Telemetry.
- Click Add (+) to create a new streaming telemetry collection profile
- In the Create Telemetry Collection > Platform tab, enter the following information
- Name: Enter a name for the collection profile
- Platform: Select the device platform that supports Telemetry
- Transport type: Select the mode of transmission of telemetry data between the sender (device) and the receiver (ATOM’s Agent), depending on your requirement
- gRPC
- TCP
-
- Dial Mode: Select Dial Out if the session establishment between the destination and the device should be initiated by the device itself.
-
-
- Packet Encoding: Select the encoding format for the streamed data between the sender (device) and the receiver (ATOM’s Agent)
-
- Compact gpb
- Self-describing gpb
-
-
- Owner: Select the owner/tenant who owns the telemetry data
- Shared-With: Add the tenant names to share the data or alternatively leave it as “all” to make it globally available
-
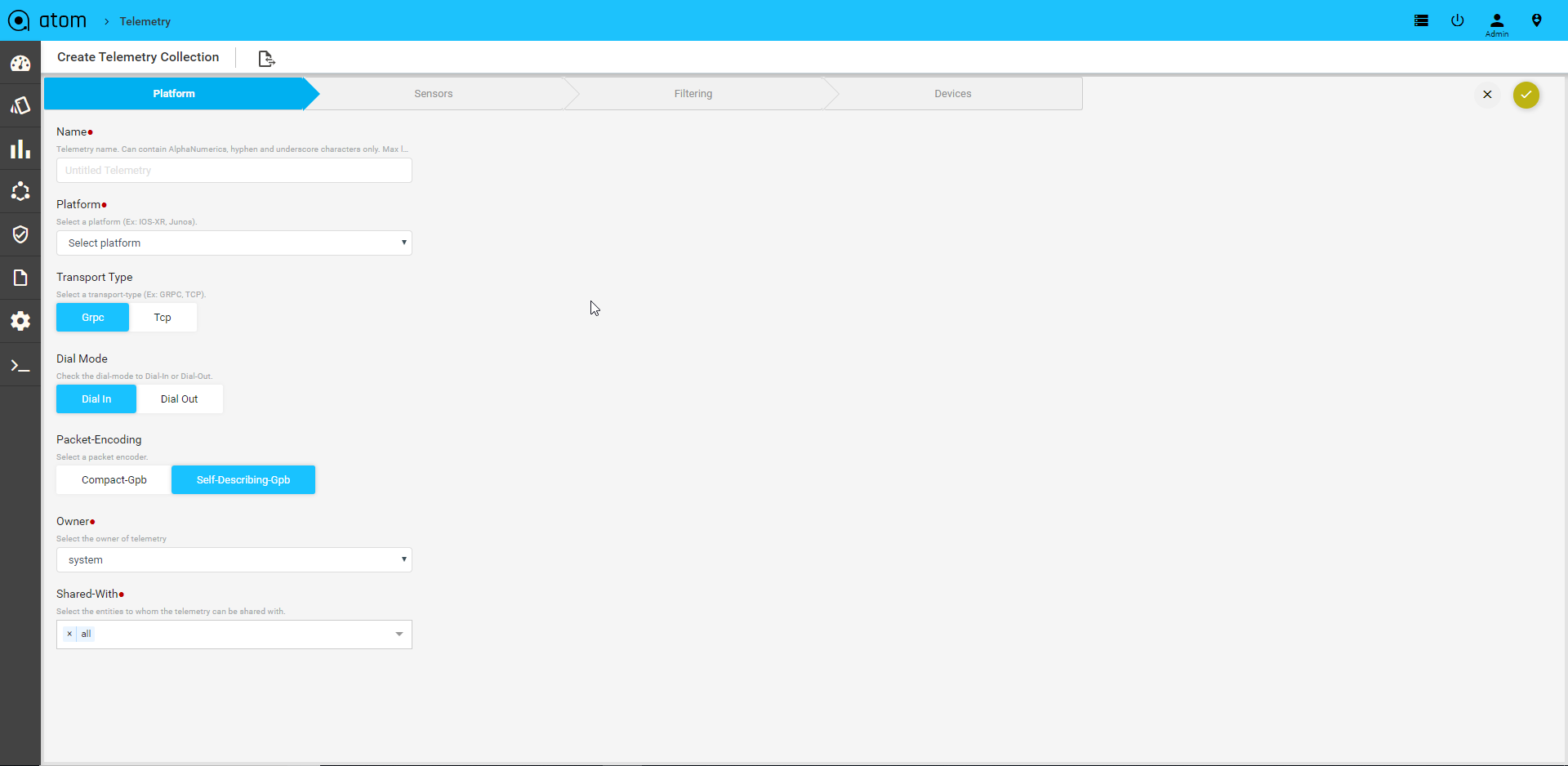
- In the Create Telemetry Collection > Sensors tab, enter the following information
-
- Sensors: Select the sensor paths for the device platform selected
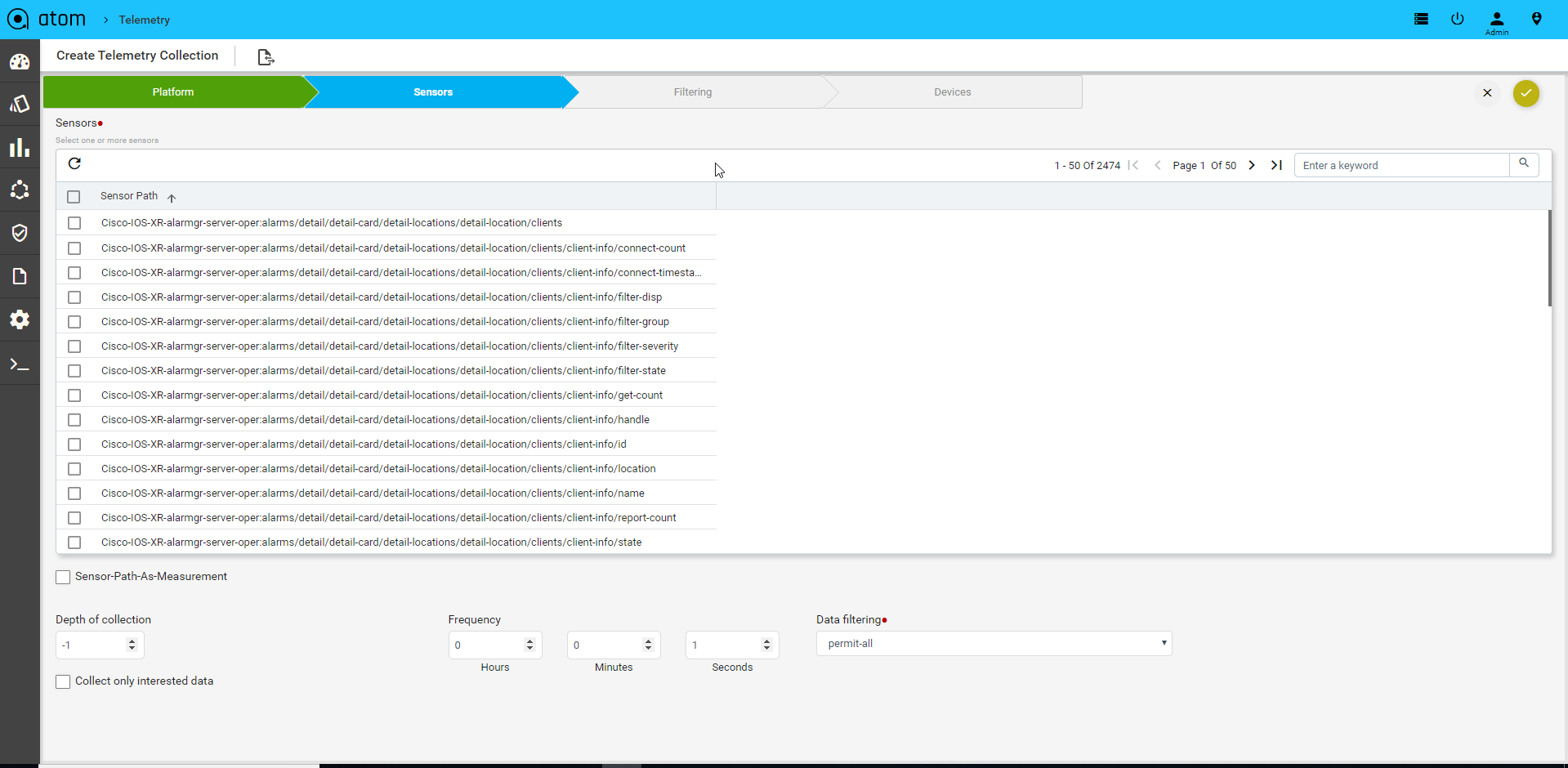
-
- Depth of collection: In the selected sensor paths, enter the level in the container hierarchy at which the data should be streamed from the device.
For example, a depth of collection of 0 returns only the leaf entities in the specified container and a depth of 1 returns the data from depth 0 and depth 1 levels the data from the container specified in the sensor path.
Example:
-
- Collect only interested data: Check this box to collect the data selectively only for the required sensors.
- Data filtering: In the global filtering policy, permit or deny the collected data from the device to the Time-series database.
- Frequency: Enter the rate at which sensor data needs to be collected from the device to be saved into a Time-series database.
- In the Create Telemetry Collection > Filtering tab, enter the following information
- Click Add (+) to create Telemetry collection data filtering
- In the Xpath field, choose the sensor path to be filtered from the drop-down list
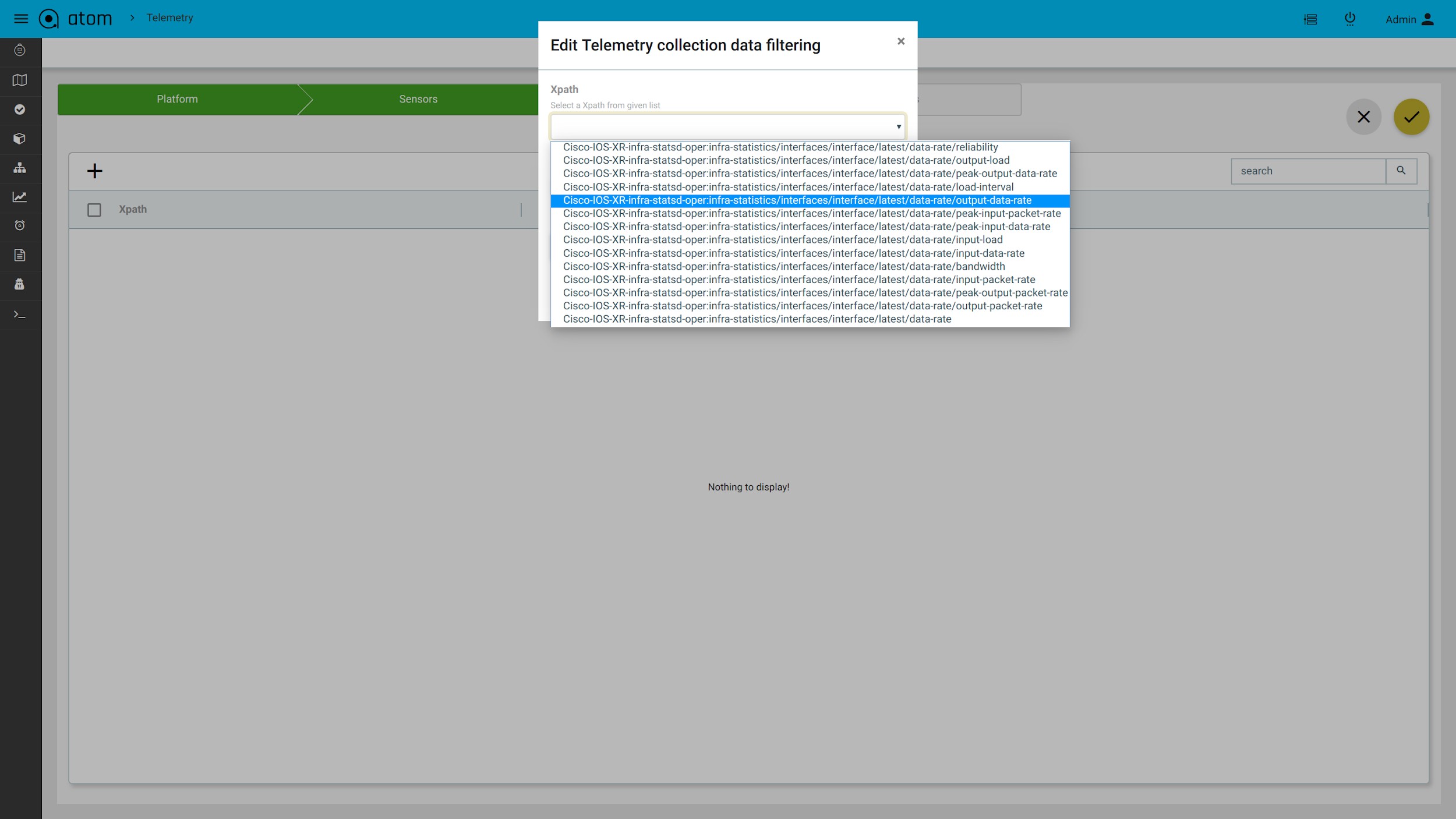
-
- In the Subtree field, check or uncheck the value of subtree
- In the Filter type, select Permit or Deny
- In the Create Telemetry Collection > Devices tab, select the Device (multiple devices can be selected), where the subscription services are running and the data should be pushed to the device.
- Click ✓ to save the streaming telemetry collection profile.
- After successful creation of collection, provision collection and deploy if it is dial in mode. If it is dial out mode then provision the collection only.
- After successful deployment of the collection make sure that the status of the collection will be shown as DEPLOYED in the UI.
- Navigate to Monitoring > Telemetry to view/modify the collection profile
SNMP Traps
Navigate->Administration->Plugins & Extension->Packages::
Upload the mib dependencies package & load it. Navigate->Monitoring->SNMP::
Add snmp collection with if-mib & csr devices and schedule it every two minutes & ran job it Check snmp collection data is shown in the monitoring tab.
SNMP traps generated by the device can be collected and visualized in ATOM
- Navigate to Monitoring > SNMP trap on the main menu
- Click Add (+) to create a new SNMP trap collection profile
- In the Platform and devices tab, enter the following information
- Name: Enter a name for the SNMP trap profile
- Platform: Select the device platform from the drop-down list
- Devices: Select one or more devices from which SNMP traps need to be collected
Click on create alert immediately & enter link is up and down in mib oids
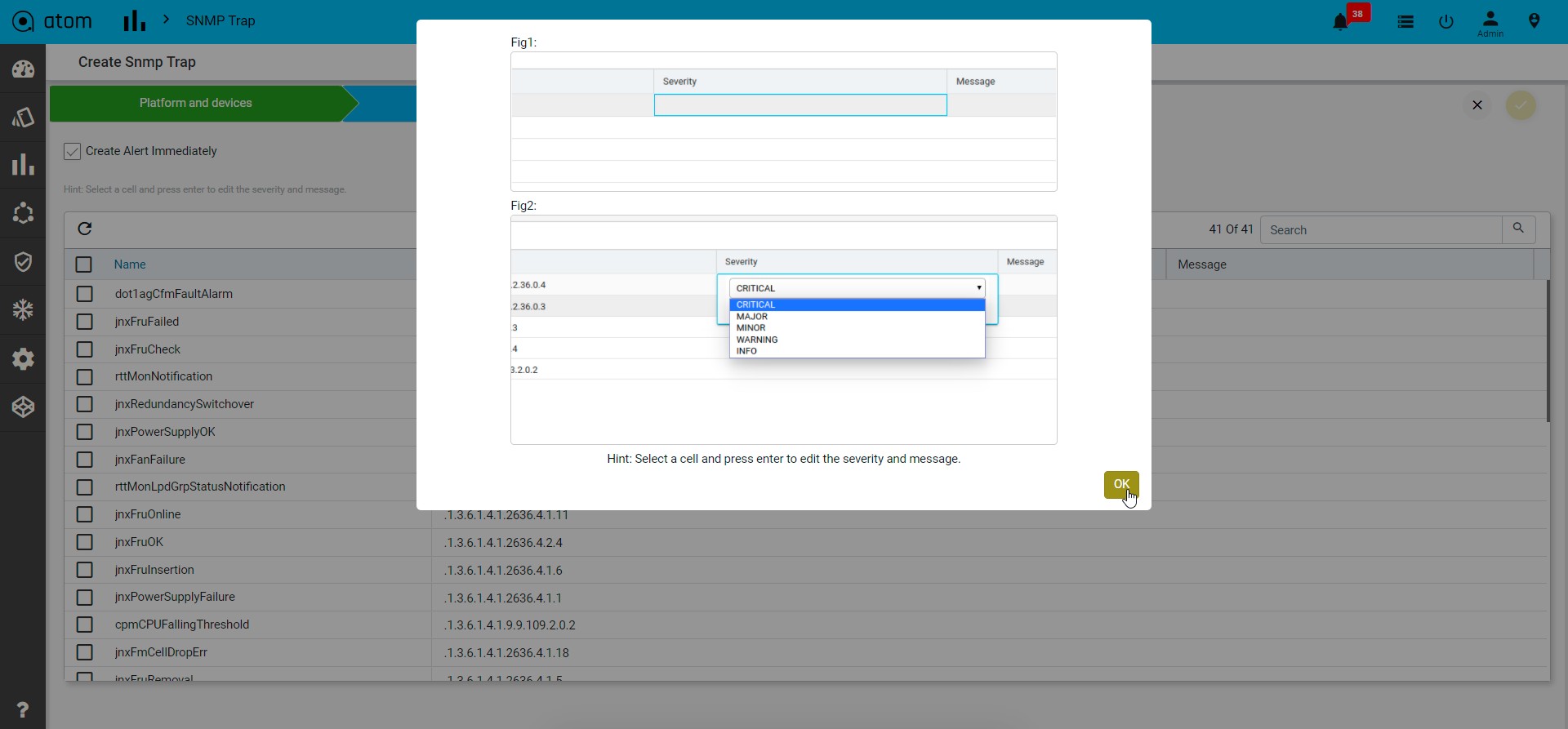
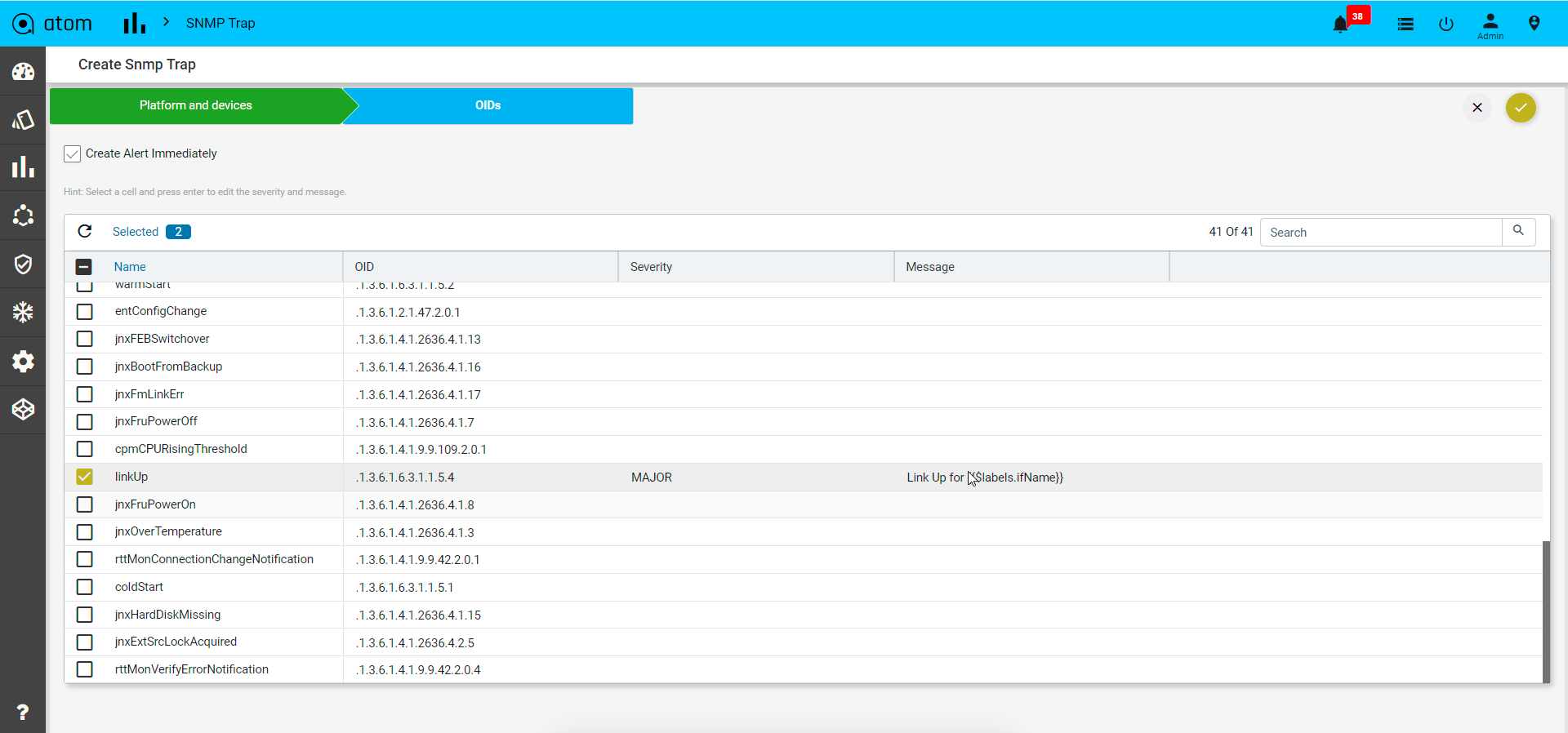
- In the OIDs tab, enter the following information
- In the list provided, select the OIDs to be enabled for SNMP trap collection to enter link is up & link is down as above screen shot.
- Owner: Choose the owner/tenant who owns the SNMP trap data
- Shared-With: Add the tenant names to share the data or alternatively leave it as “all” to make it globally available
- Click ✓ to save the collection profile
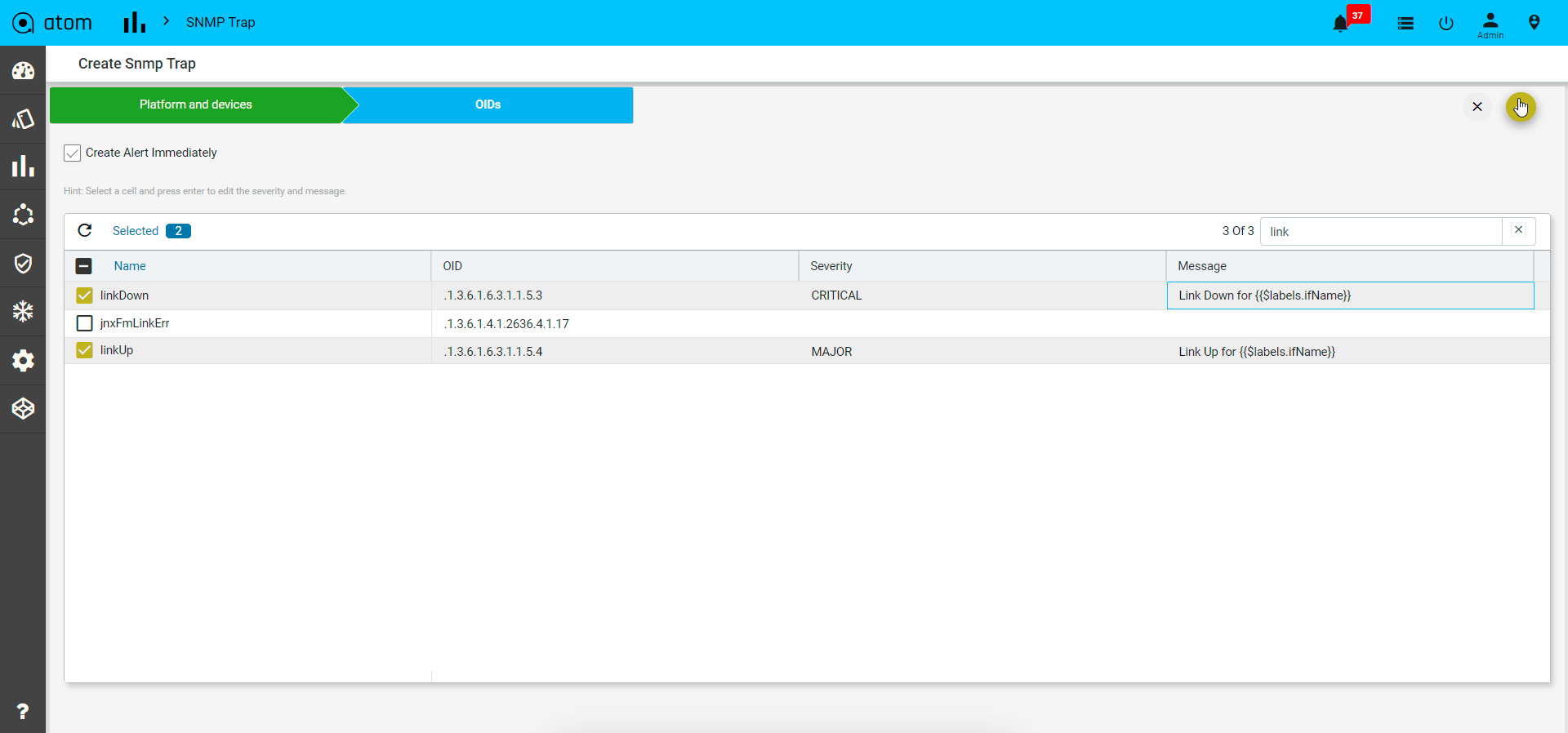
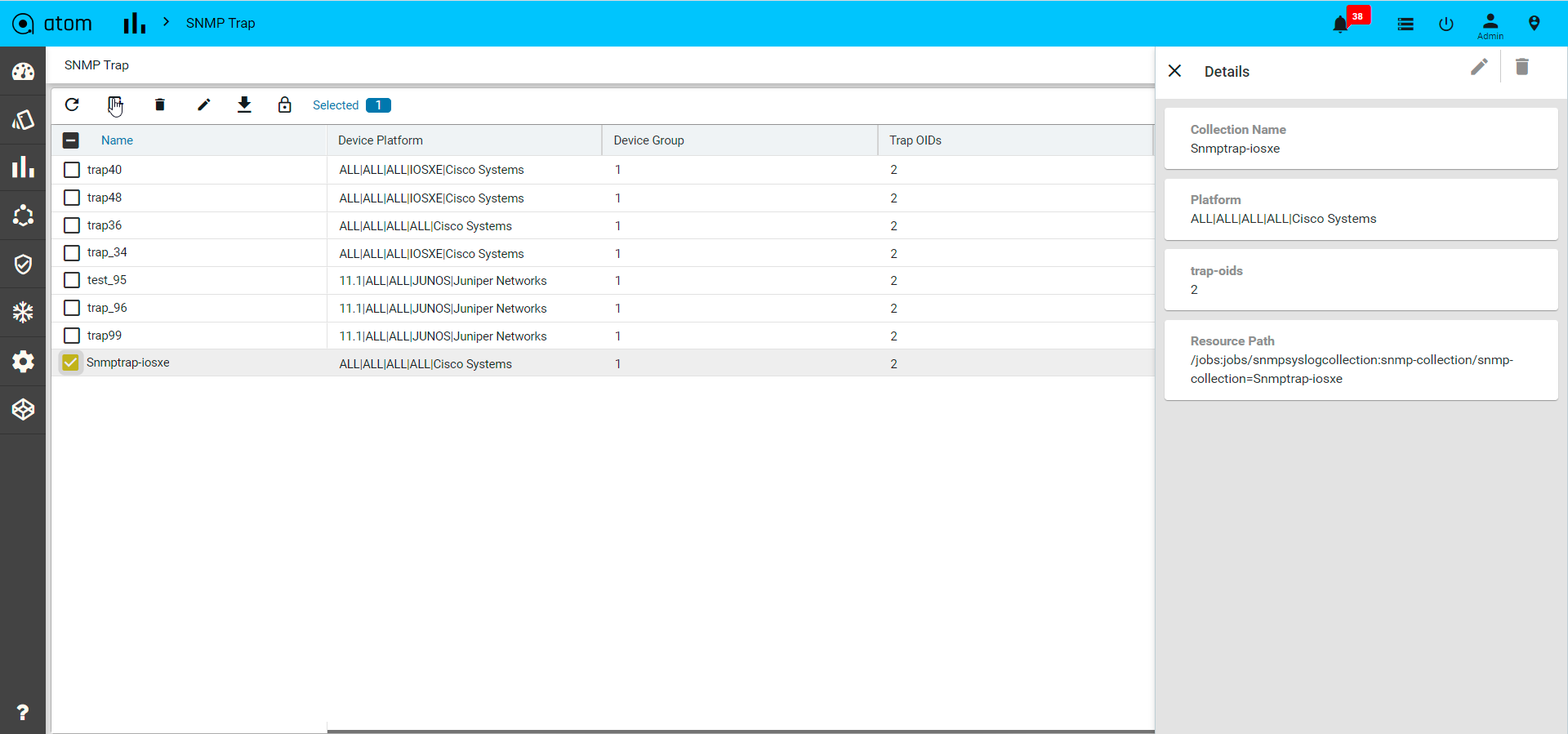
- Navigate to Monitoring > SNMP Trap to view/modify the collection profile
- Click the Subscribe button to provision the SNMP traps configured on the devices
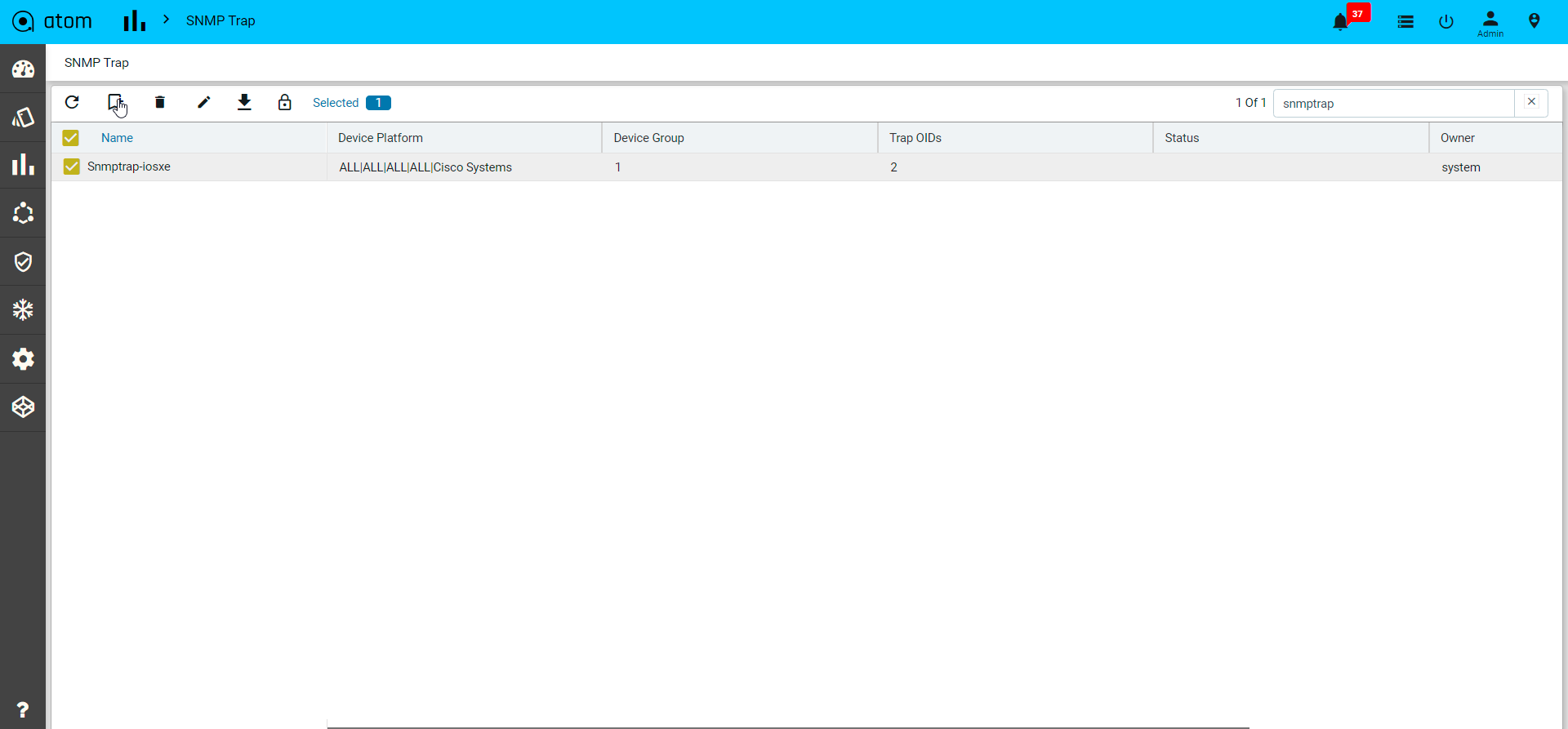
- The subscription of snmp trap can be seen as shown as below commands
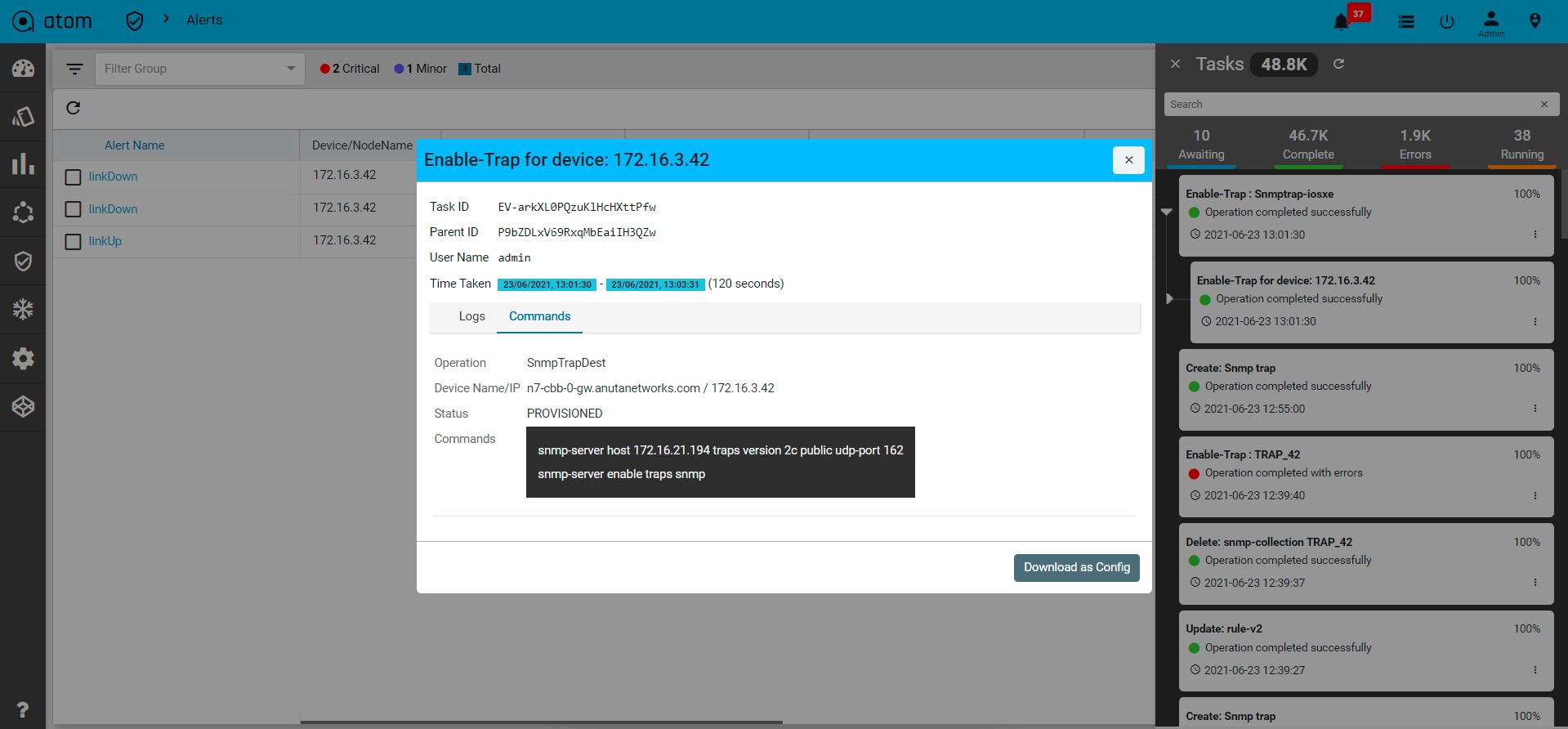
- Check login device to shutdown the interface & check the alerts can be generated for snmp trap
Syslogs
Syslogs generated by the device can be collected and visualized in ATOM
- Navigate to Monitoring> Syslog on the main menu
- Click Add (+) to create a new Syslog collection profile
- In the Platform and devices tab, enter the following information
- Name: Enter a name for the syslog collection profile
-
- Platform: From the drop-down list, select the device platform from which Syslog messages need to be collected
- Devices: select one or more devices from which Syslog need to be collected
- In the Event specs tab, enter the following information
- In the list provided, select the Event specs to be enabled for Syslog collection
- Owner: Choose the owner/tenant who owns the Syslog data
- Shared-With: Add the tenant names to share the data or alternatively leave it as “all” to make it globally available
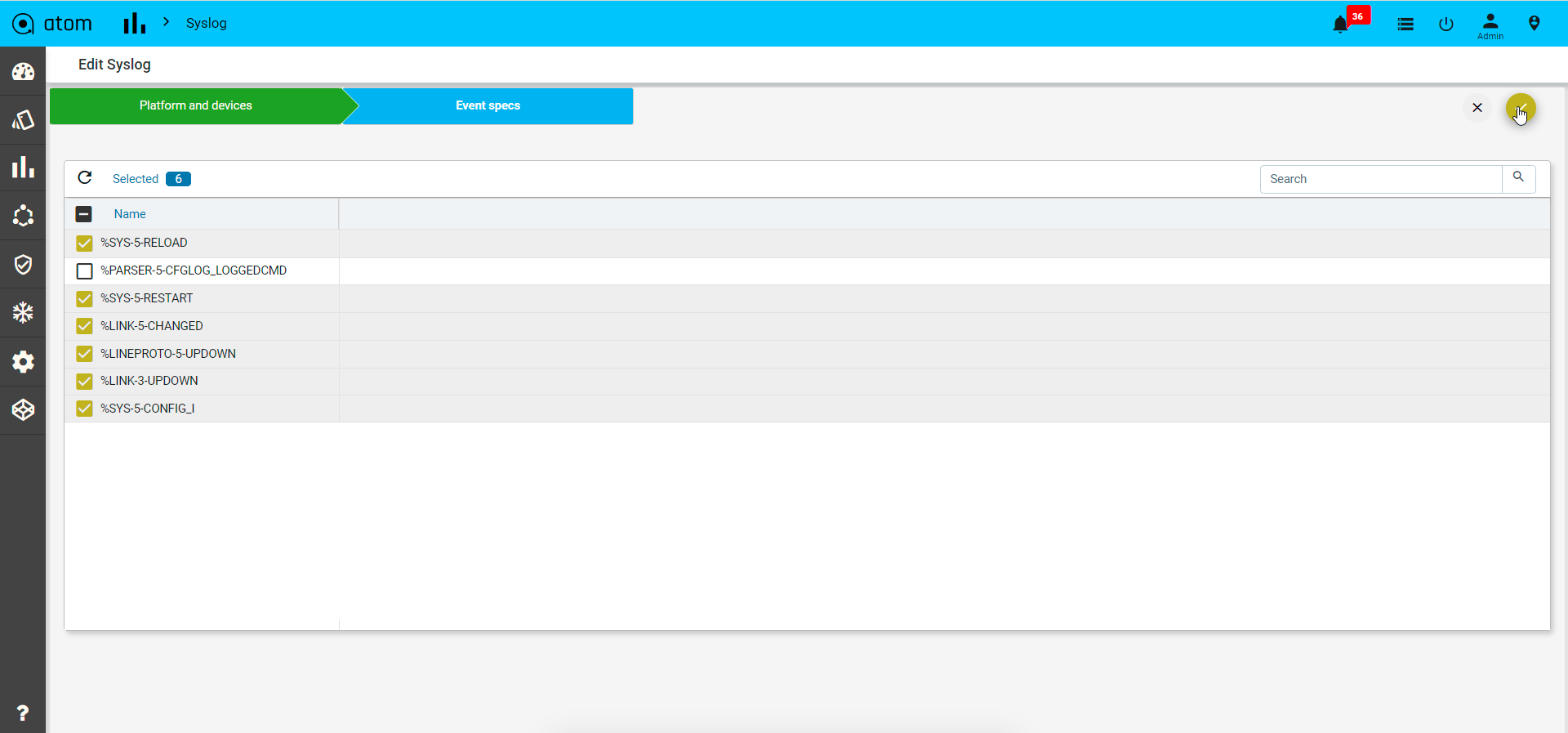
- Click ✓ to save the collection profile
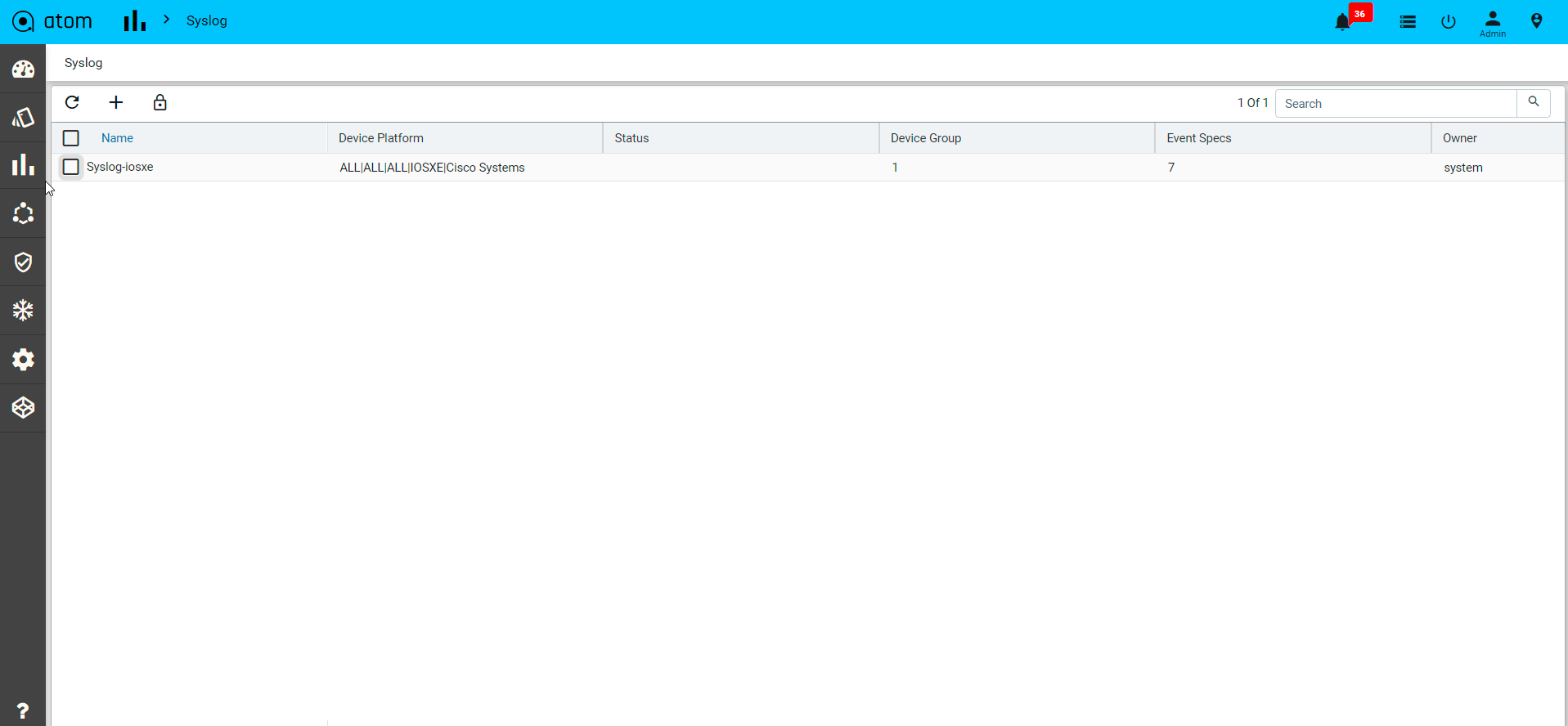
- Navigate to Monitoring > Syslog to view/modify the collection profile
- Click the Subscribe button to provision the Syslog collection on the devices Navigate->Assurance->Closed loop automation:
Create alert definition for syslog is link is up and down & activa it.
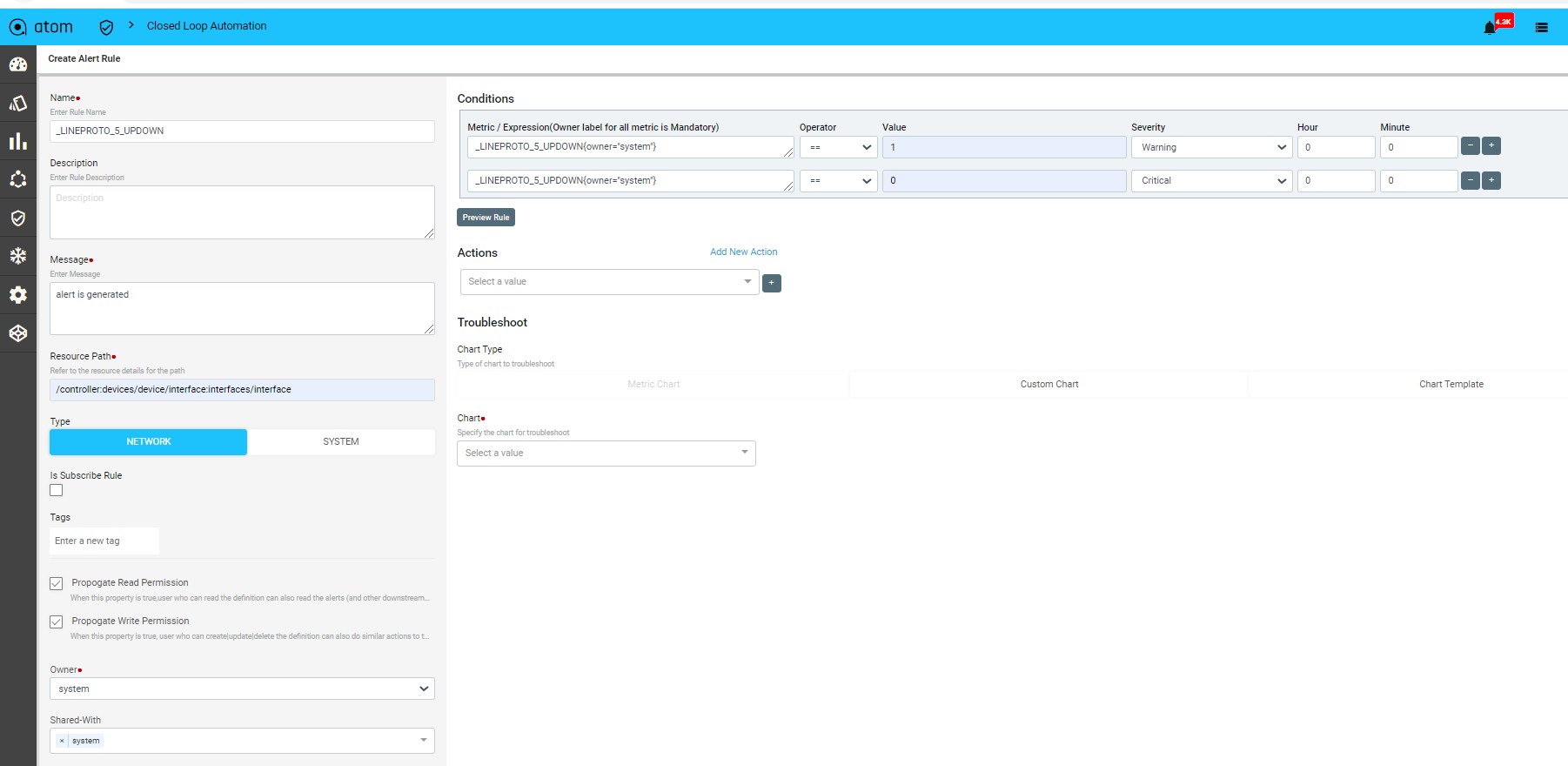
- Check login device to make the interface is up/down
- Syslog alerts can be generated after the interface is up/down.
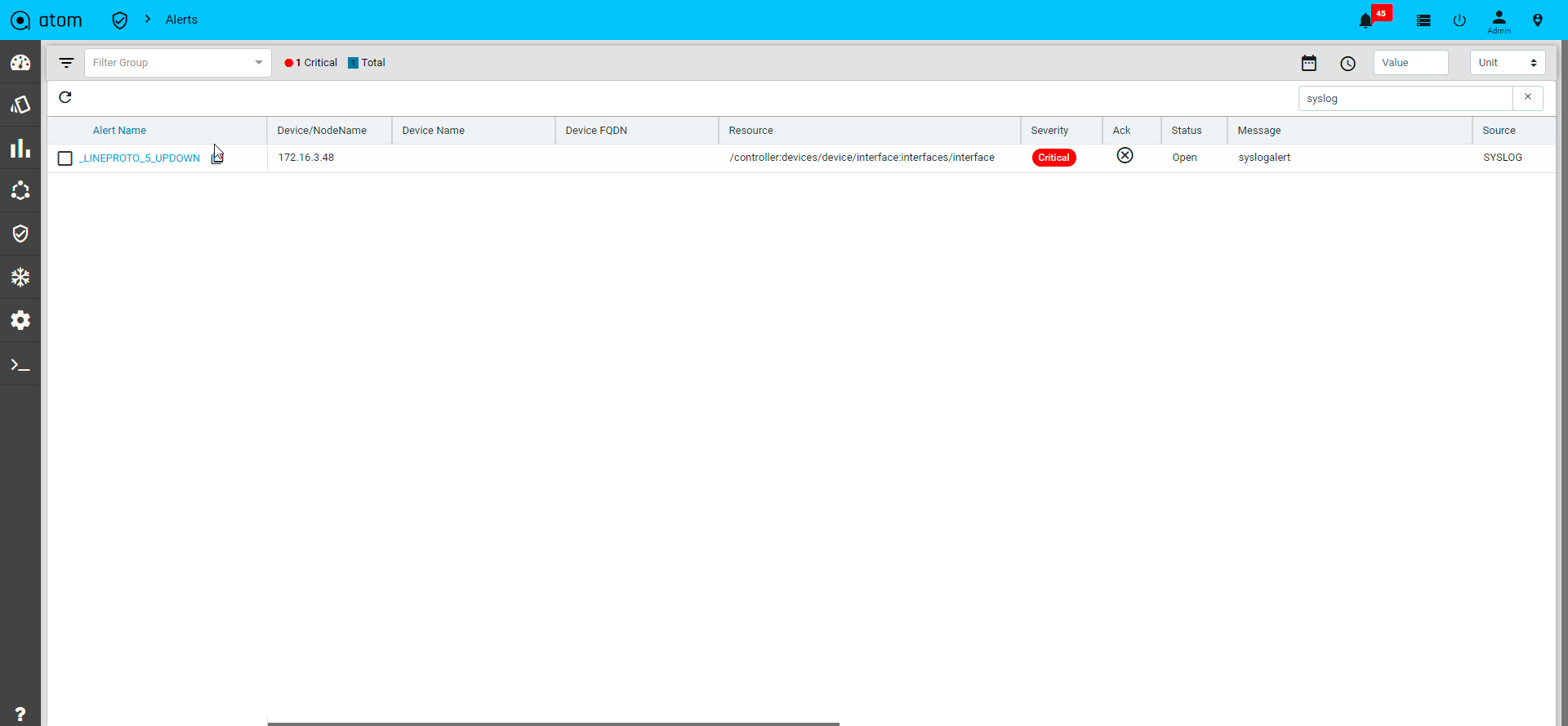
Charts & Templates
ATOM provides various customisations to visualise the collected metrics efficiently. Users can customise the mib names, metric names, logical grouping with human understandable keys, unified view of metric in single chart, context selection, multiple views through templates and also via dashboards.
Key Customization for each metric :
To change the keys in the device monitoring tree. By default key-oids will be shown as parents in a logical hierarchy. Most of the MIB’s have Index numbers as the keys, so we can’t keep track of them while looking at each metric. It is always required to keep well known objects to map the rest of the metrics.
eg: Interface Counters collected through the IFMIB will result below the tree by default. Here, it will have ifindex as the key by default which sits on top in the hierarchy.
Below is the snapshot without any customisations which has default key-oids at higher level in the tree. Here, Ifindex is the default key for IFMIB entries.
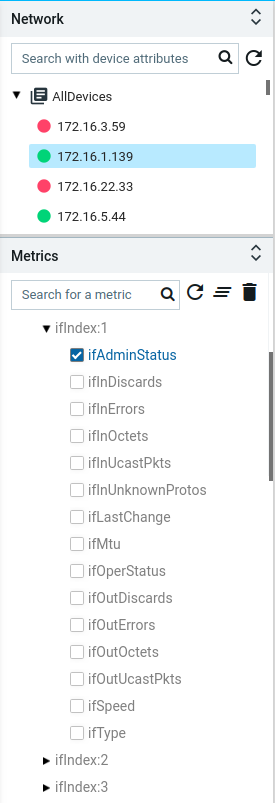
To change the keys to represent this data more human understandable, navigate to the
Administration -> Plugins & Extensions -> SNMP -> SNMP OID Map
Here, choose each metric and add/modify the metric-tag-oids to reflect them in the tree.
We can add multiple metric tag OID’s, after each entry press ENTER to add another. To choose which property has to be primary for tree representation among multiple metric-tag-oids, we have to change the field settings. To change this, select the oid entry as shown in snapshots and select the entities -> fields on the right hand side.

Here, add the fields by providing the oid name and select the label-field checkbox to true to make this as primary.
If we add multiple fields, only one of the fields will become the primary.

All the remaining fields will be shown on mouse over of the key on the device monitoring tree.
Metric Visualization on Device Explorer:
Navigate to Resource Manager -> Devices -> select the device -> Monitoring tab on the right hand side.
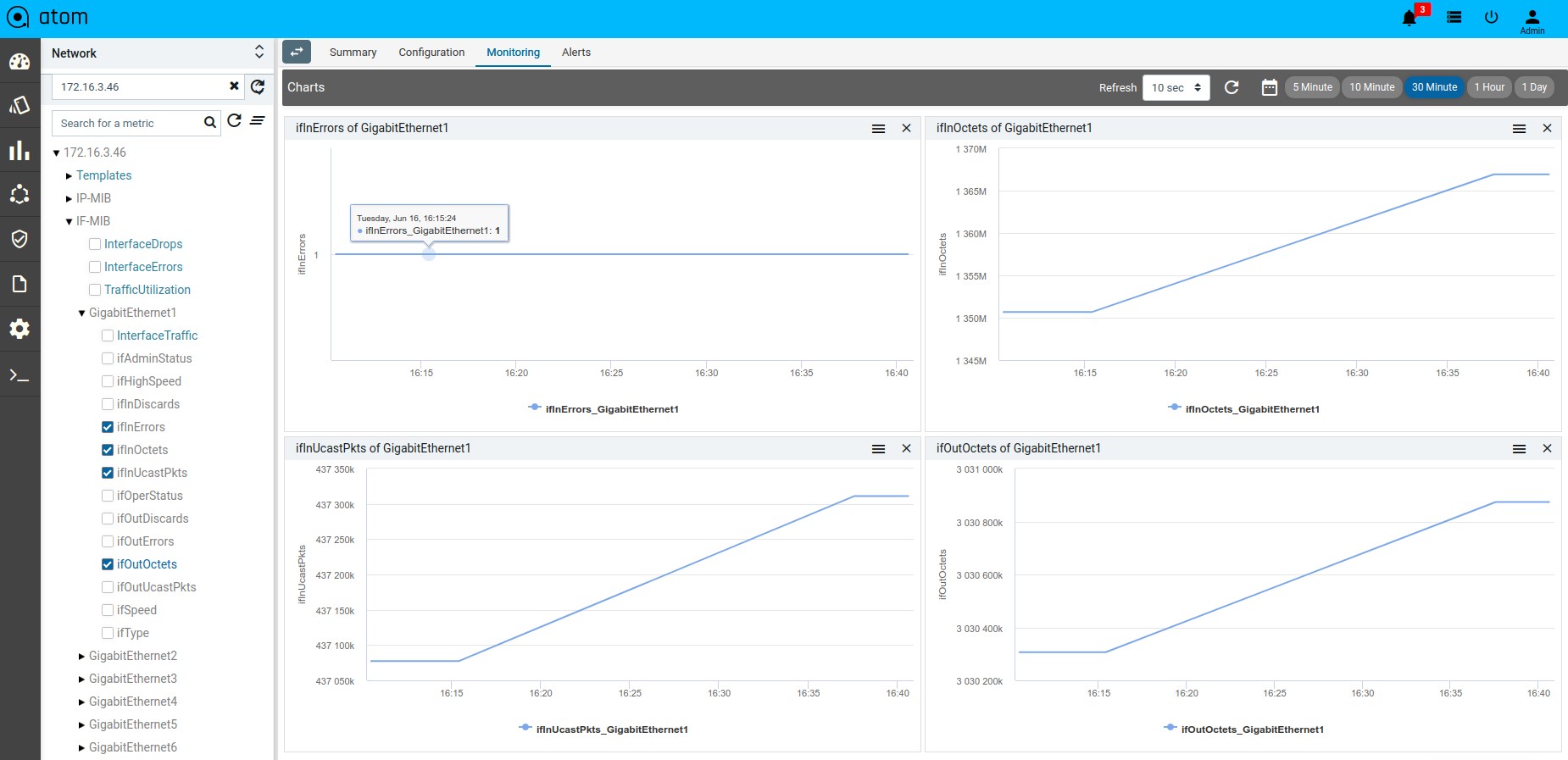
Refer Chart Actions section for various interactions.
Chart Creation
Create Simple Custom Chart:
Simple custom chart is to show multiple metrics in a single chart without further filtering. It will create a corresponding PromQL and retrieve the data.
eg: create a chart to show interface traffic which includes interface in & out packet counters, use preview option to see the data before saving.
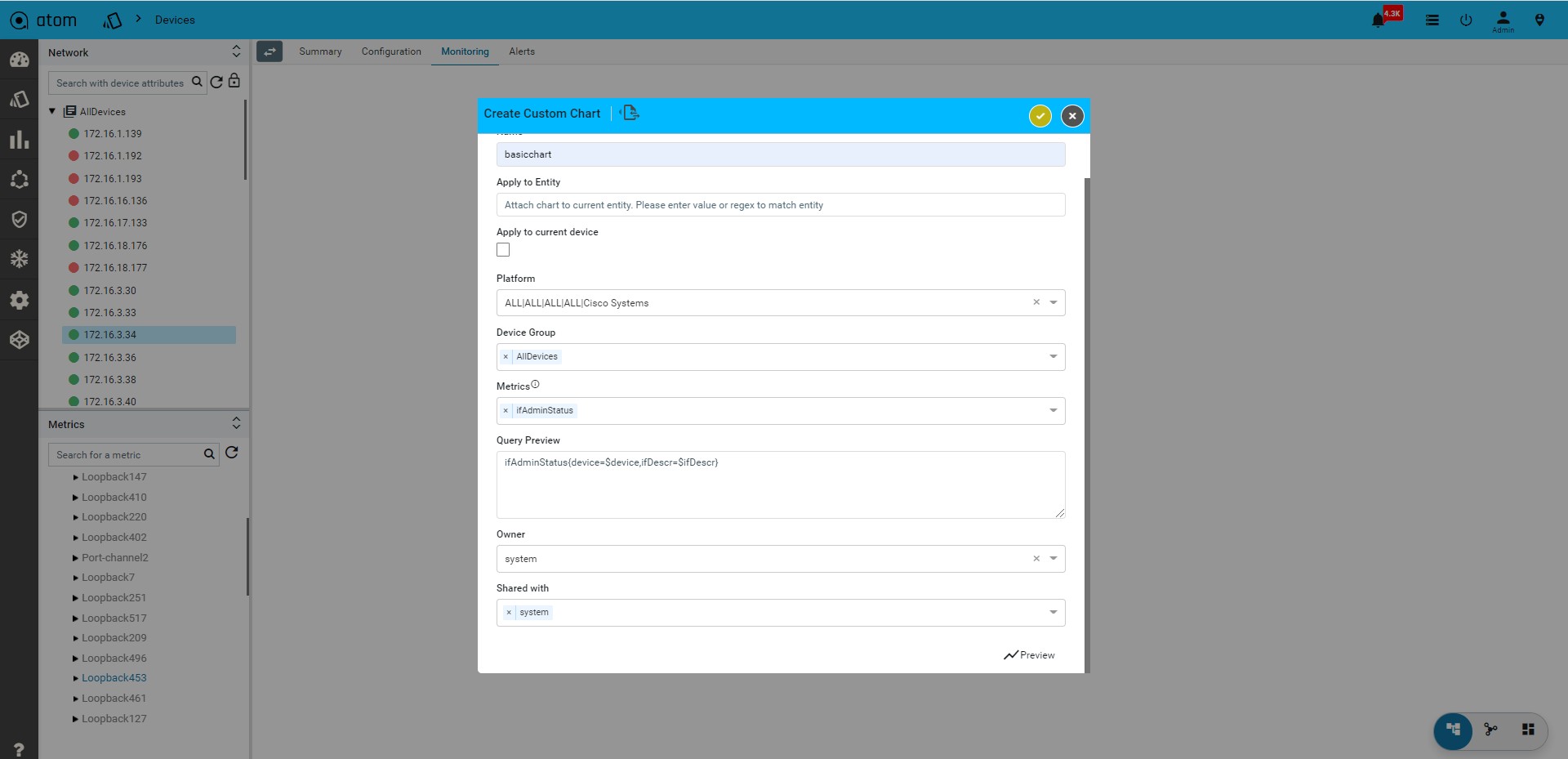
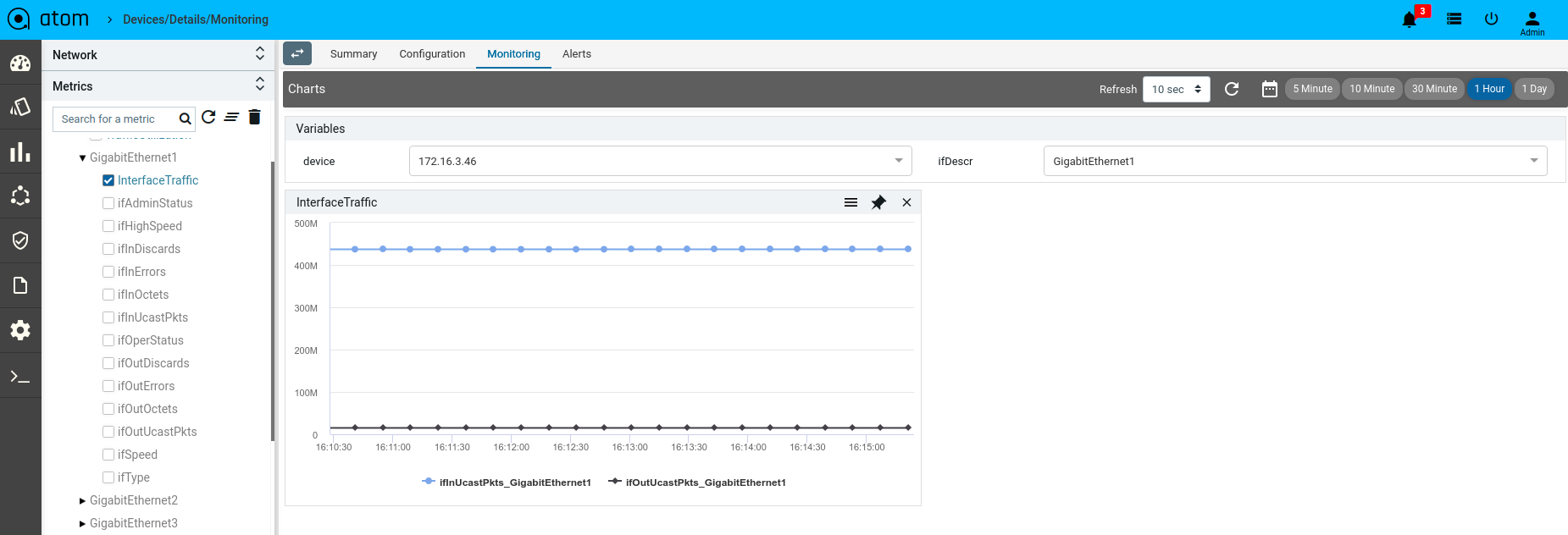
Once the chart is created at any node level and it will be applicable to all other siblings automatically. In the above snapshot, we have created Interface Traffic chart at Gi1 Interface and it will be shown under all other interfaces automatically with the right context selected.
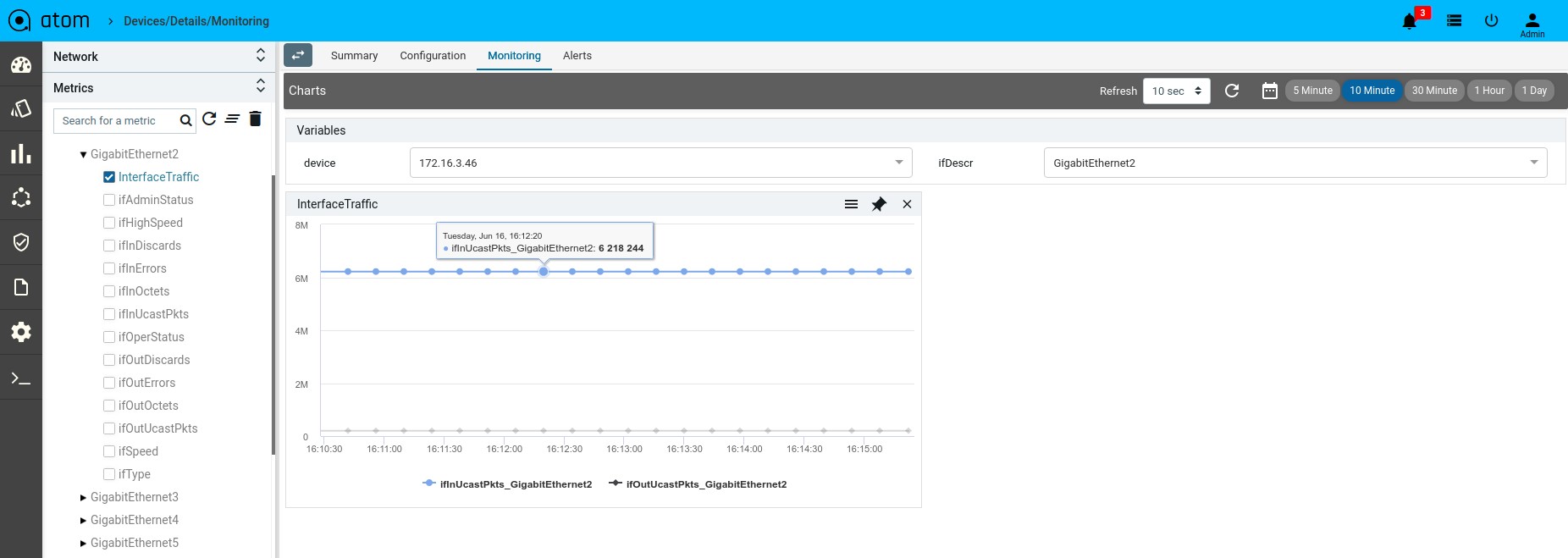
Create an Advanced Custom Chart
Advanced custom charts can have any valid promQL expression with/without variables. To use any variables, we need to define them beforehand.
Create the Variables for Charts
Variables are useful to move across instances or context easily with the dropdown selection. Variables can be used across the charts or templates.
To check the predefined variables or to create new global variable navigate to the
Administration -> UI Customizations -> Chart Variables
Below are system defined variables.

Provide below fields to create a variable.
- Name: Provide the name of variable
- Description: Specify the description for the variable
- Default-value: provide the default value for the variable. It is used when the given expression or query doesn’t result in any value.
- Variable Type: Variable value can be derived using following ways:
- data-type : It can be selected when the variable is known
- query: it is used to fetch the variable value by executing the query on a metric instance database.
- top-n: it is to get the current top n result and use those labels to plot a graph through selections.
- Metric: to specify the key/column which is of interest to store in a variable.
- Filter: It is equivalent to the where condition while fetching the metric value
- Tsdb-query: To execute the top N query on tsdb and use the top n keys in the graph to render for any metric.
eg: To get the Top N Interface utilisation, we need to get the interface names which are utilizing high bandwidth in specified time periods.
Variable creation example:
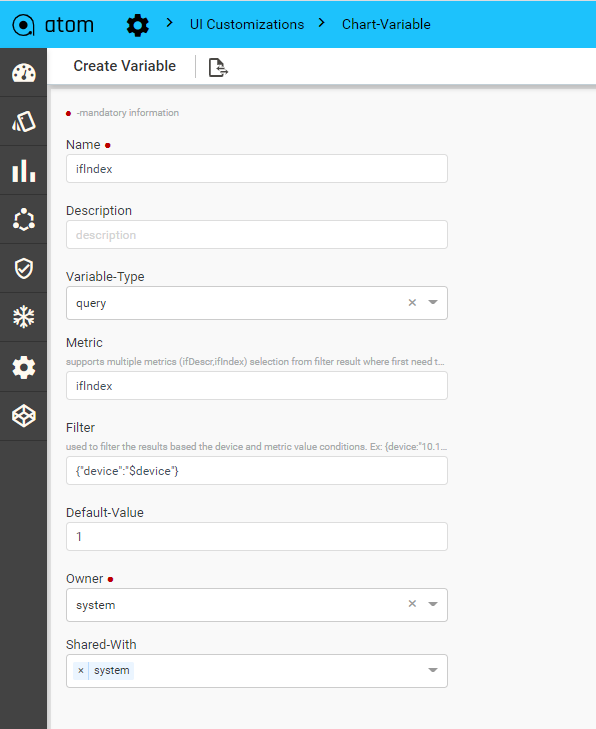
Create Chart Templates:
Chart templates are used to combine one or more charts with/without variables and save it as a view. Templates can be restricted to specific platforms or Groups. Any one of the templates can be set as default, to render automatically when we move to a particular logical level. Applies-to function determine where the template has to show in the device monitoring tree.
Templates can be created from the Admin screen or from device explorer view.
To create a template from device explorer, select one more chart and click on create template bottom left side. User has to provide the name for each template and optionally we can restrict the scope of template to platform or device group.
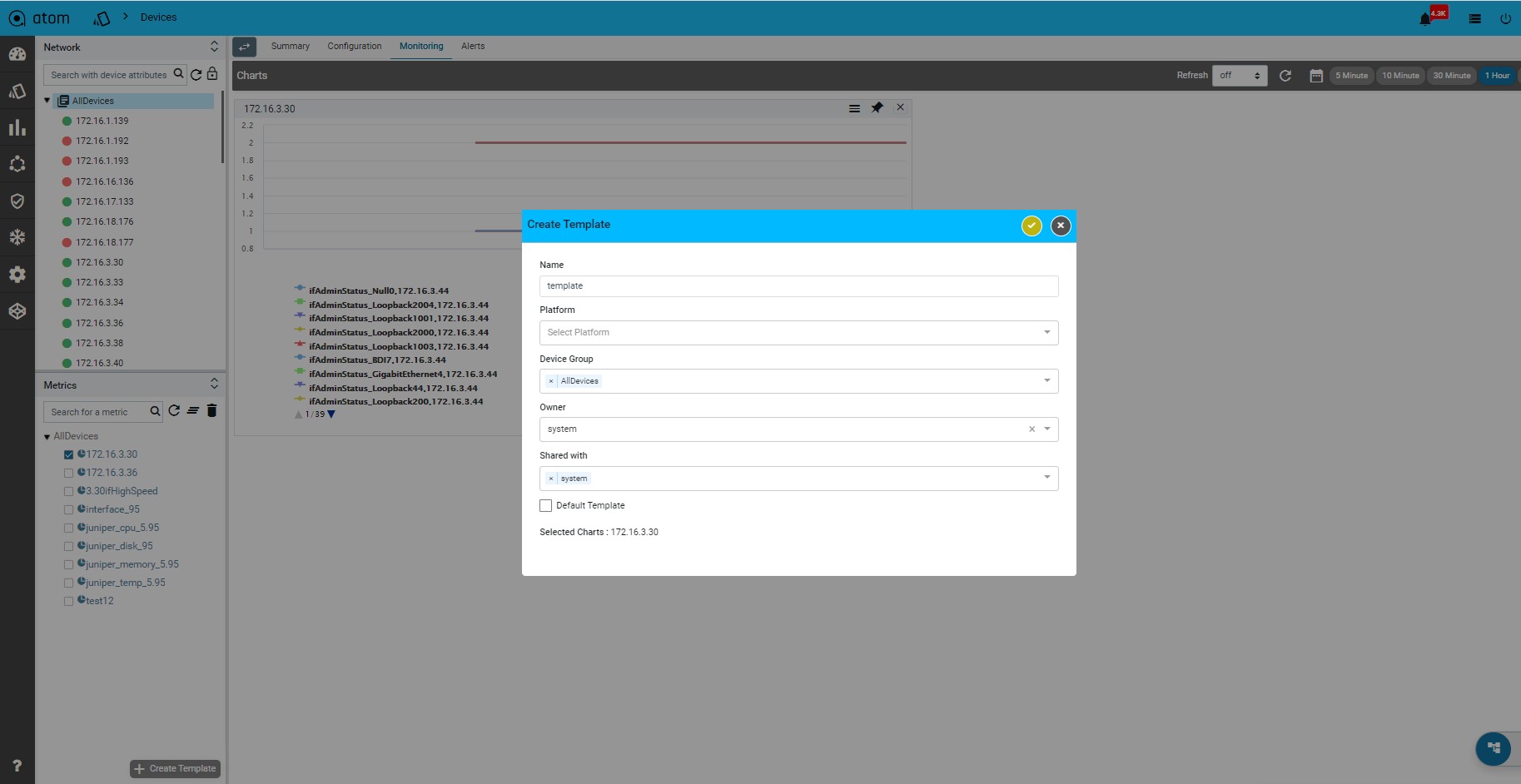
Select any template as default template which will be shown at each device or group level without any further selection.
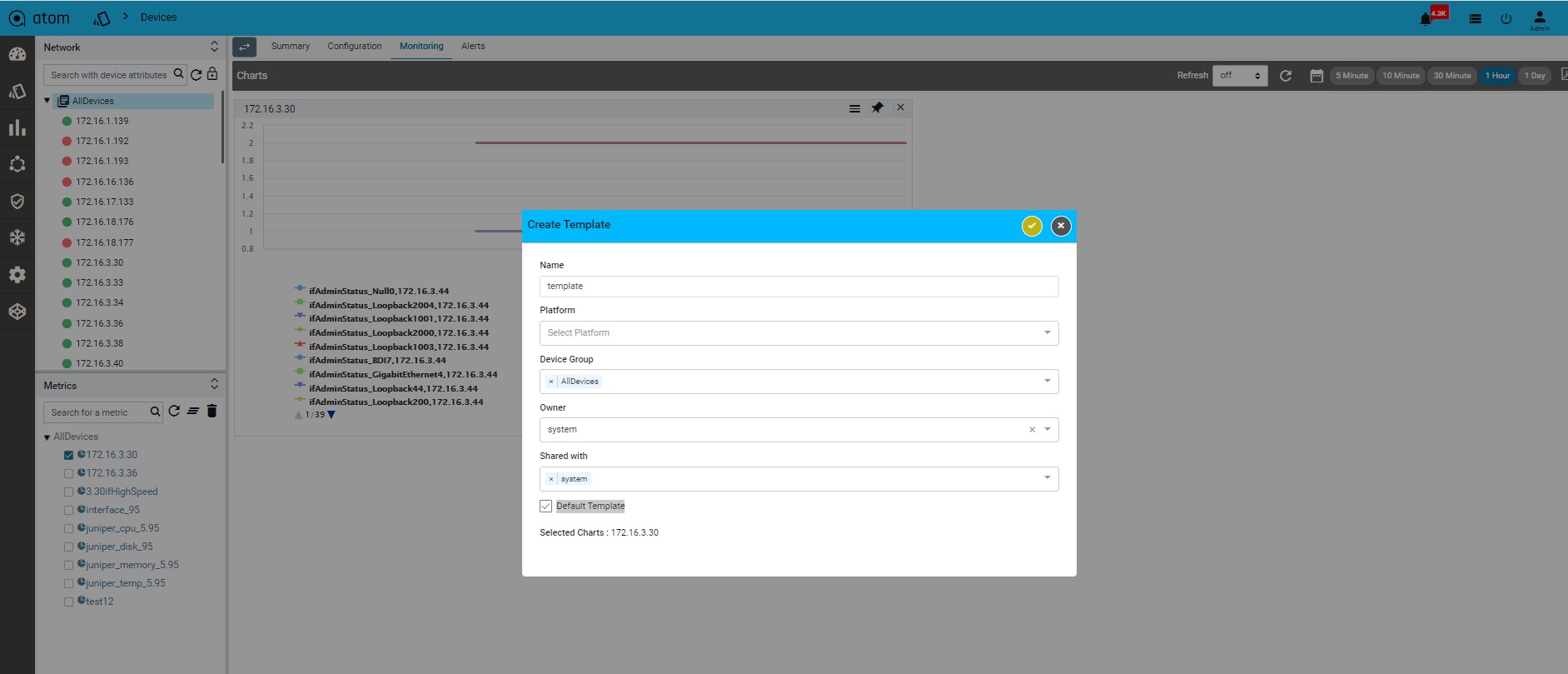
To create template from Admin Screen, Navigate to the Administration -> UI Customizations -> Chart Templates
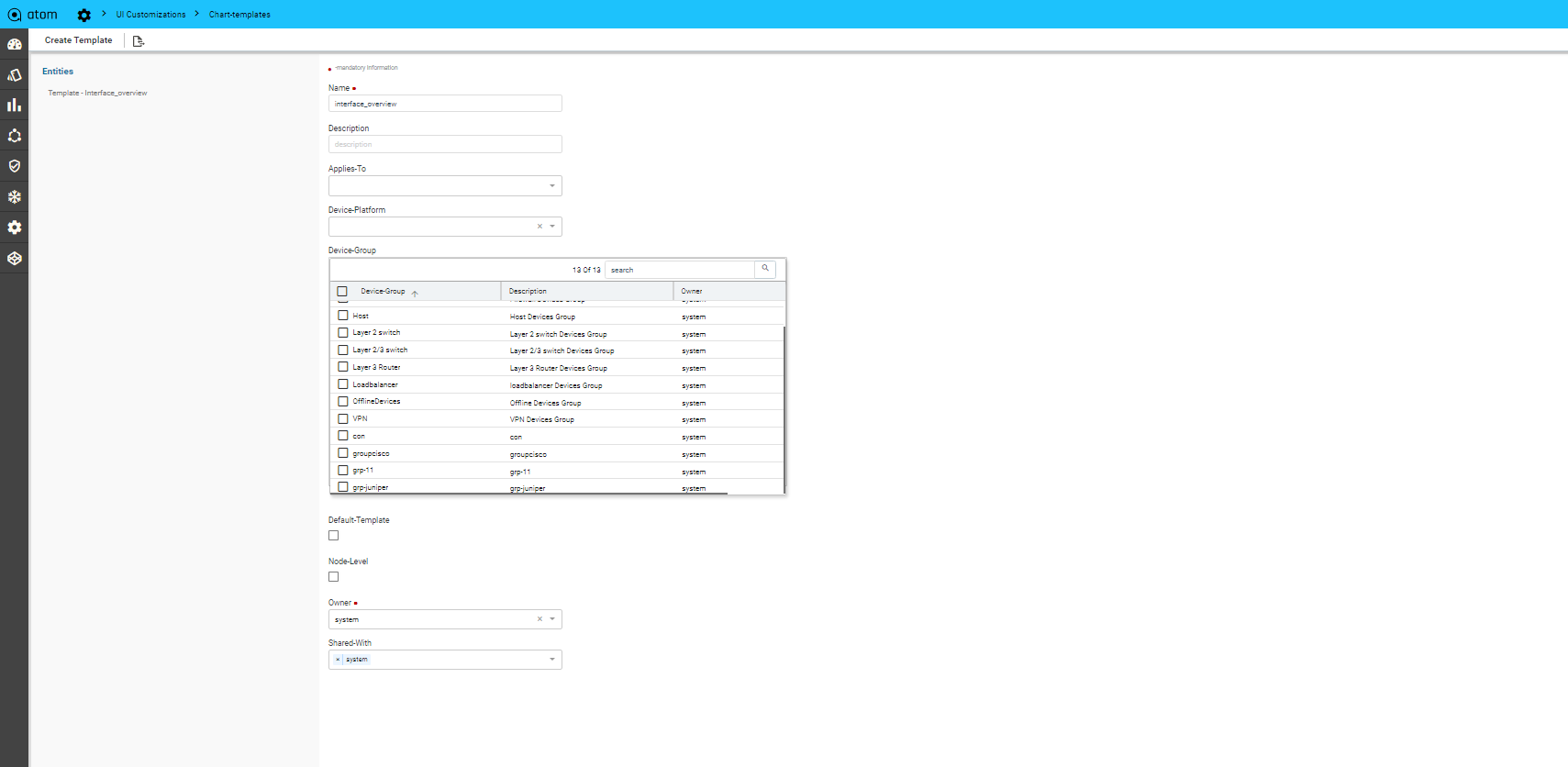
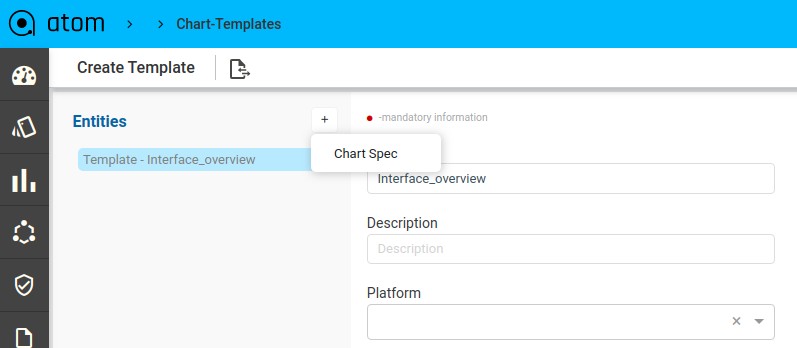
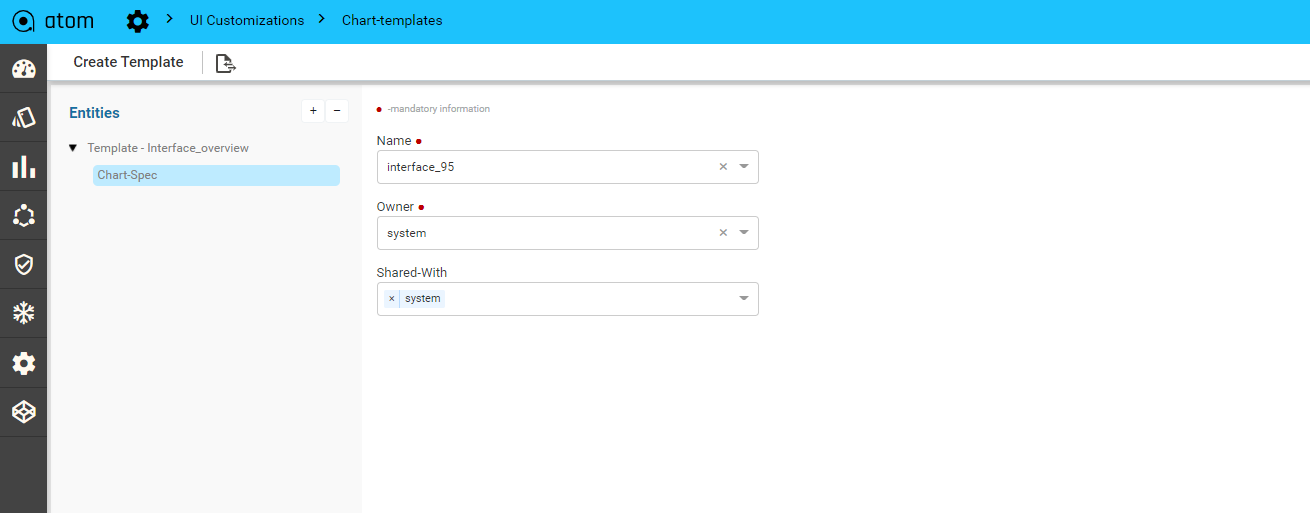
Chart Actions:
Each chart can be seen in full screen, downloaded in PNG, JPEG, SVG formats, export Time series data in csv or xls format, min/max/avg can be seen for each time series and also latest snapshot of time series data can been in a table below the graph. Currently, time selection is global which is applicable to all the charts or templates which are selected.
To see available actions for each chart.. Click on three vertical lines as shown below.
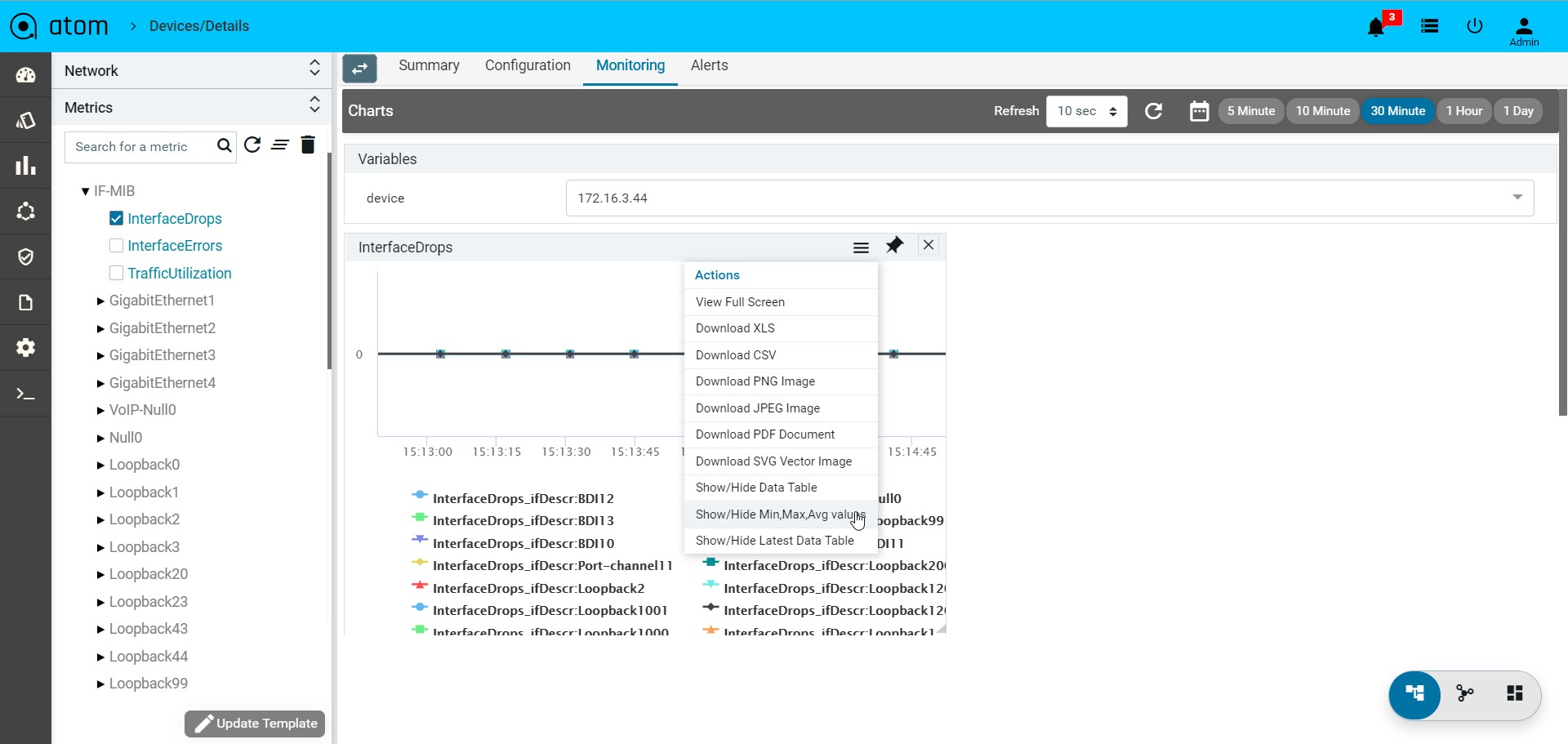
min/max/avg:
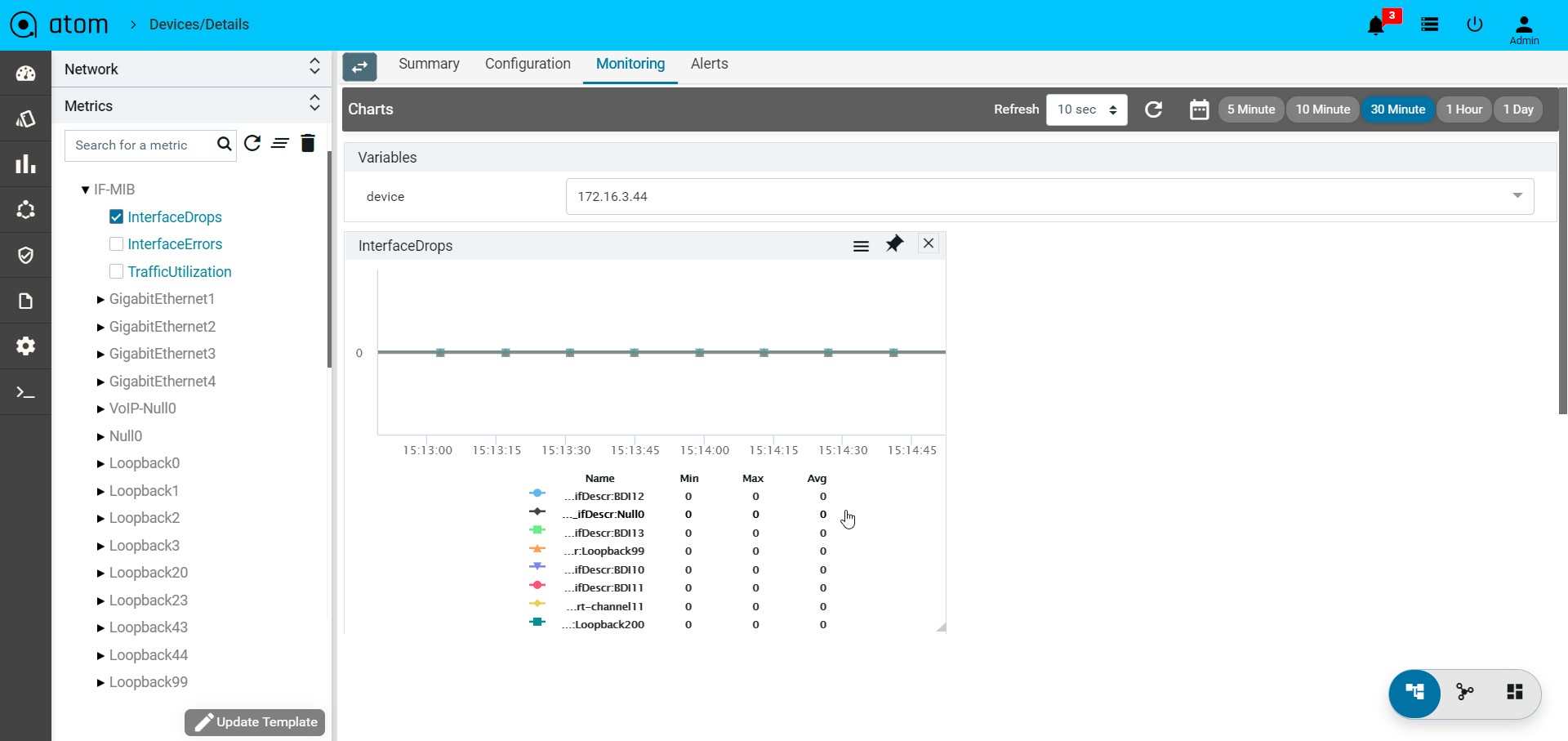
Latest data in table format:
Chart pinning to a dashboard
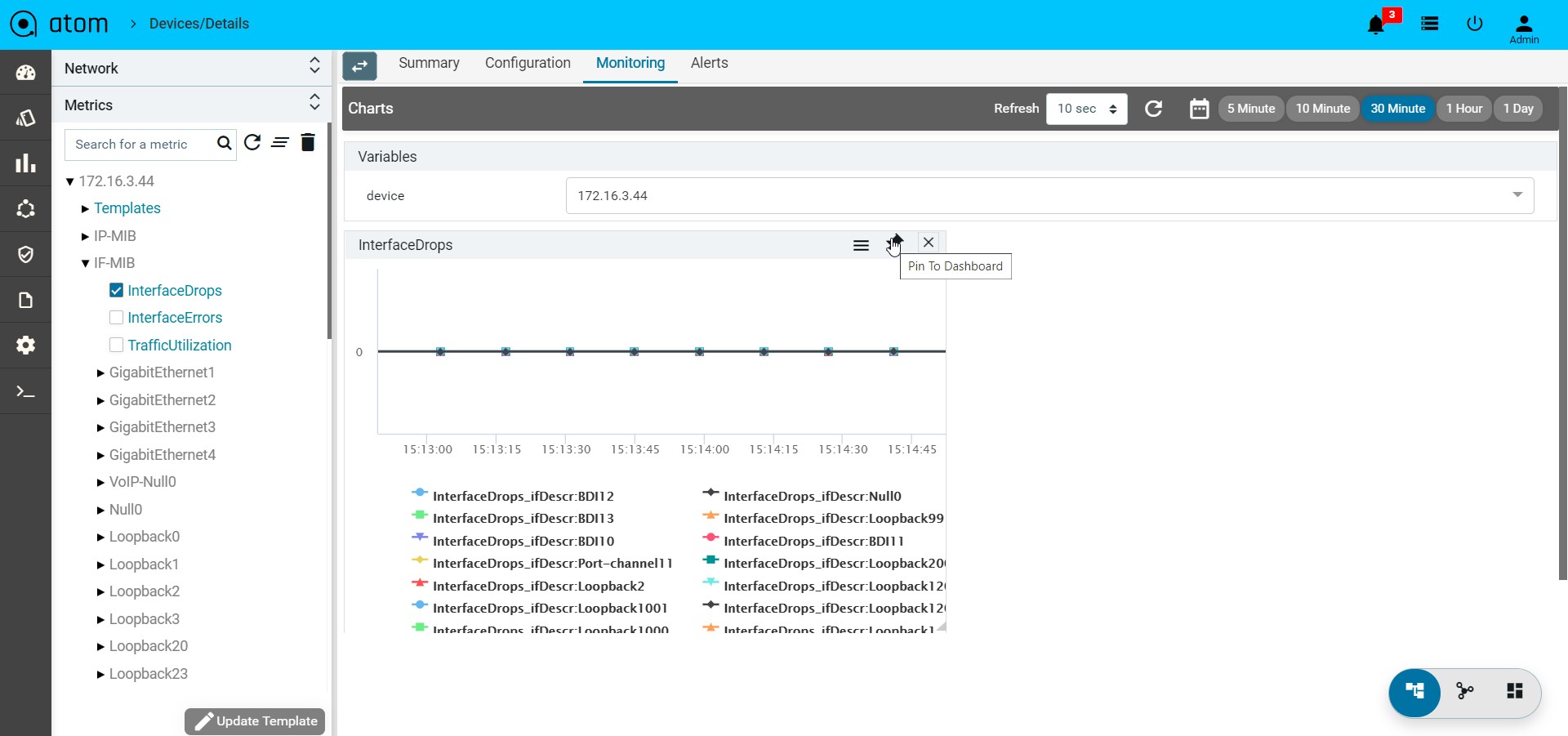
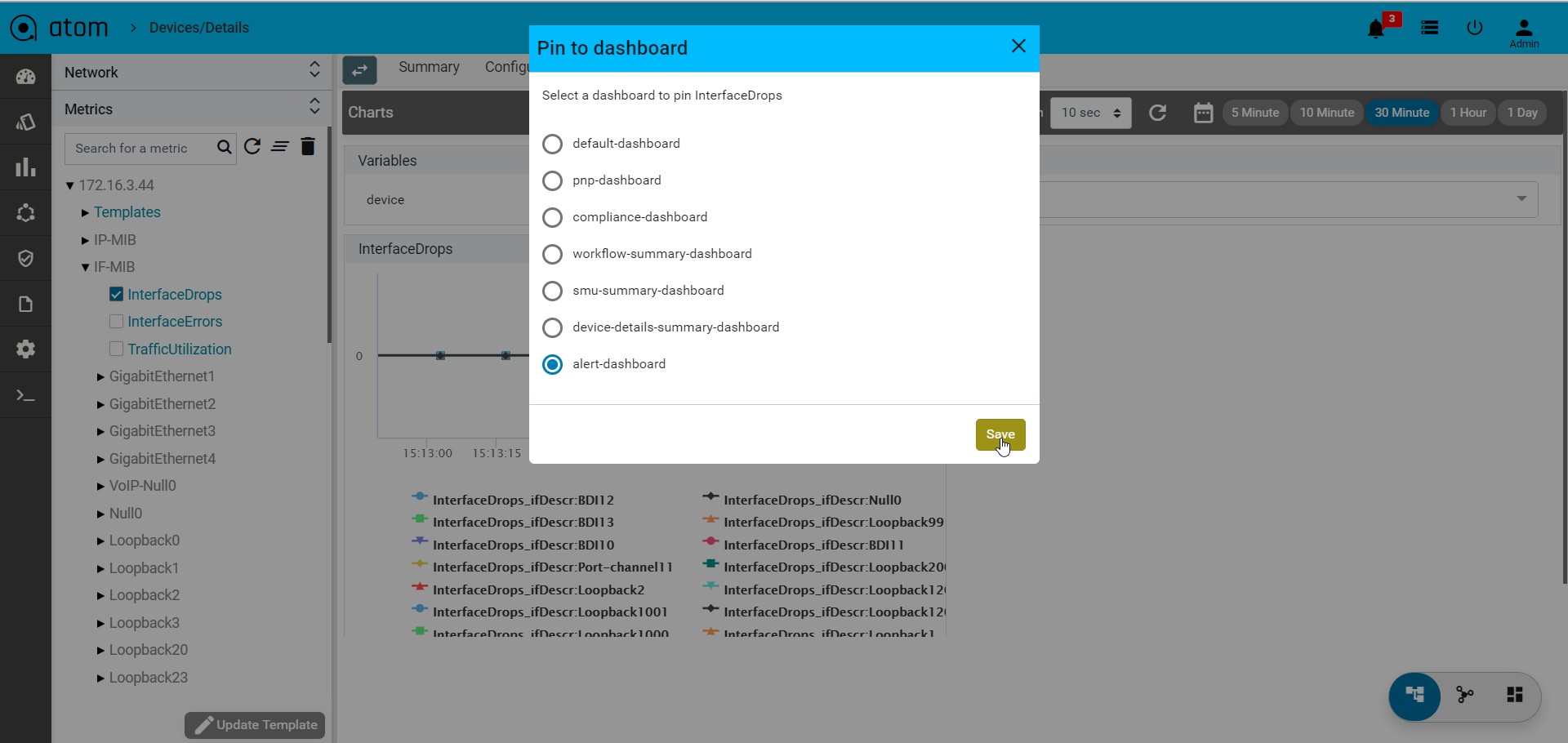
Note: To have the static values for the variables in monitoring charts, create the Advanced charts by following the below steps.
- Create Advanced chart
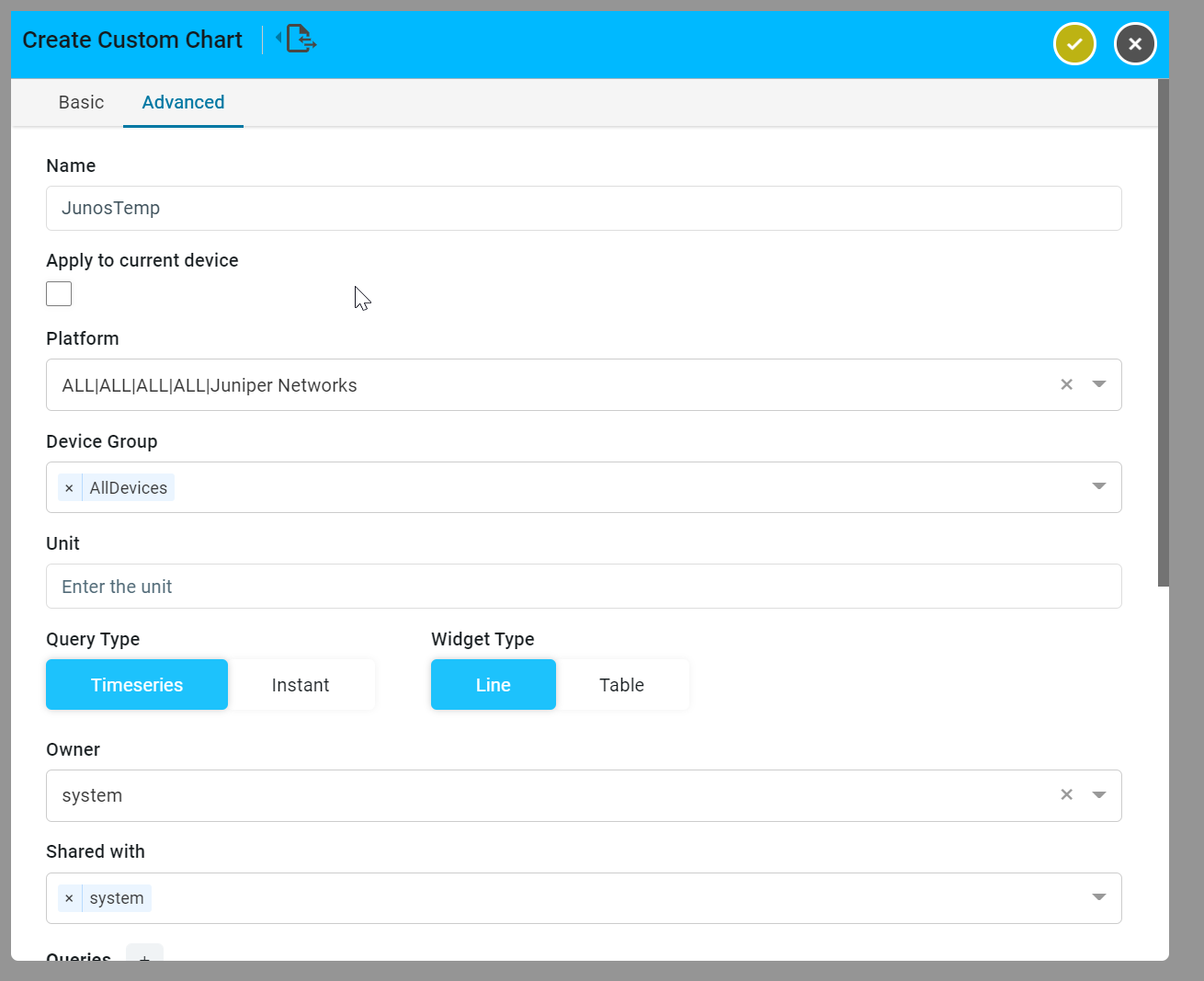
- Provide the variables as follows in the queries.
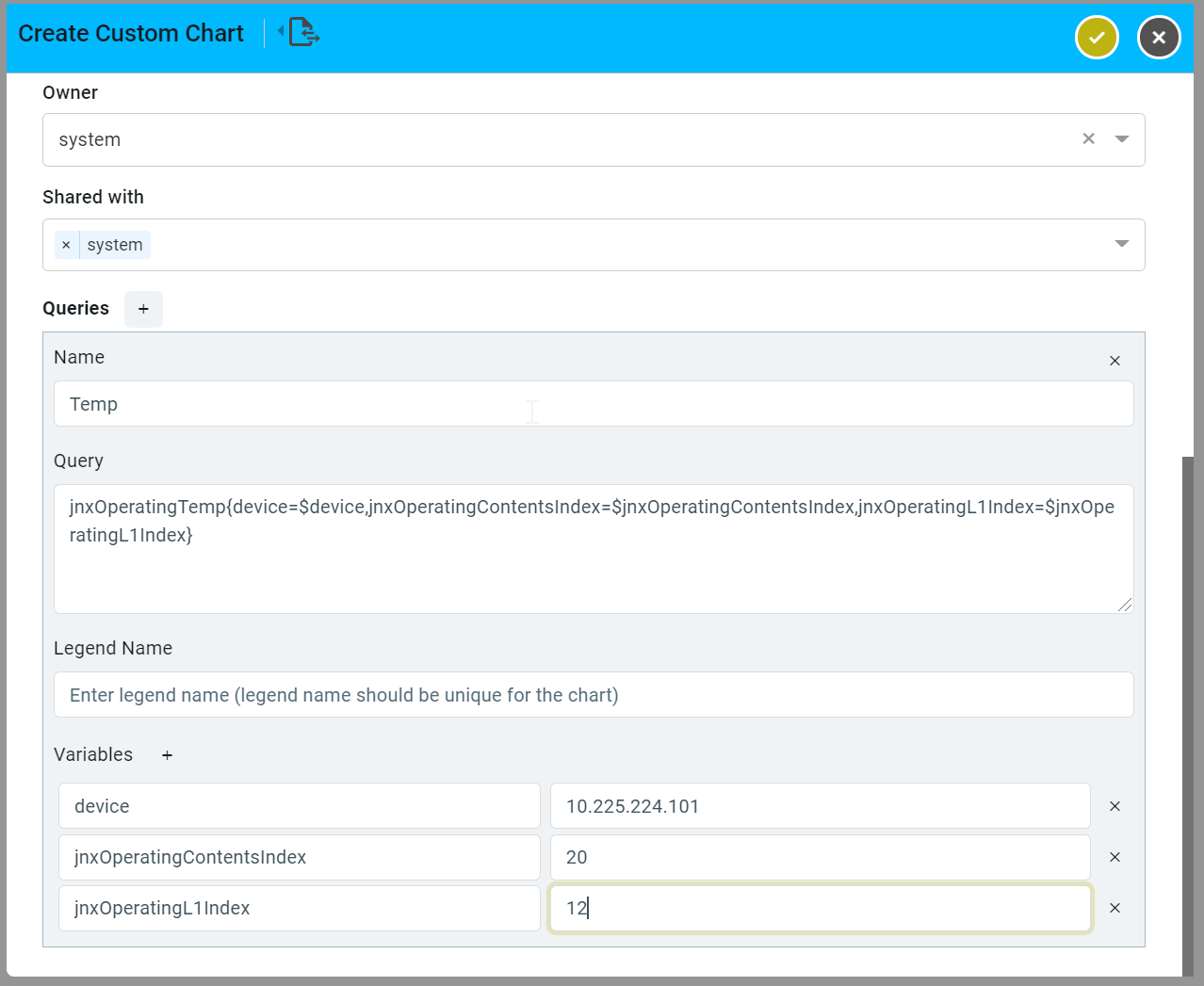
- Charts can be viewed with static values as below.
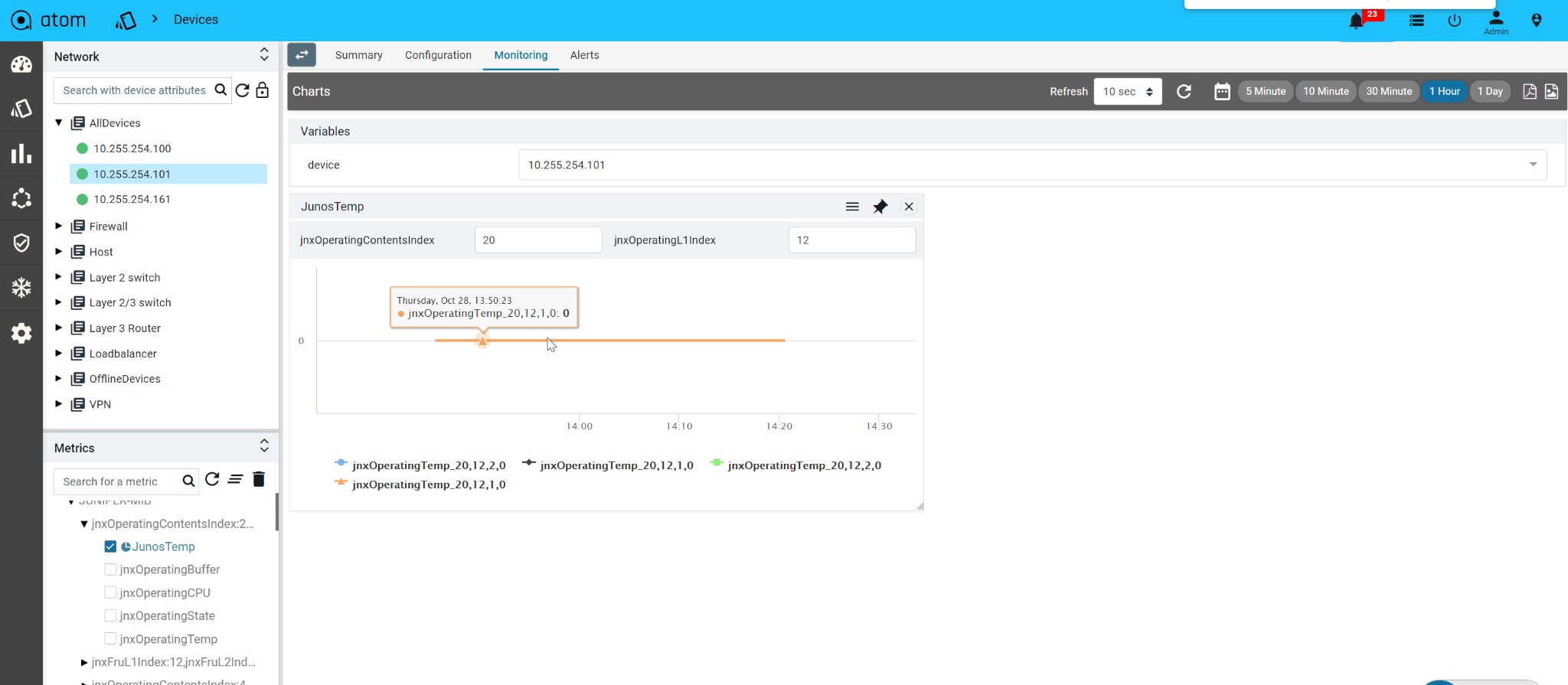
Alert, Actions & Closed Loop Automation
ATOM enables you to create Assurance profiles to facilitate 24×7 uptime of your network. Closed loop automation (CLA) framework allows you to define policies and remediation actions in violation of those policies.
ATOM collects operational & performance metrics from multiple data sources such as SNMP, SNMP traps, Syslog and Streaming Telemetry and stores them in a time-series database.
Following are the different activities on the metrics:
- Visualize Data Using Charts & Reports – To be covered in Monitoring
- Alerts against thresholds defined on the Metrics
- Alert Dashboards – Collection of Predefined & User Defined Dashlets
- Alert Routing to Email, Slack etc.,
- Actions on Alerts
- Closed Loop Automation Actions on the Alerts – Alerts can be routed to ATOM CLA framework where further correlation can be done against the defined behavior and remediation steps to resolve issues in the network. The actions to be taken for any breach in threshold values range from sending an email alert, a slack notification or
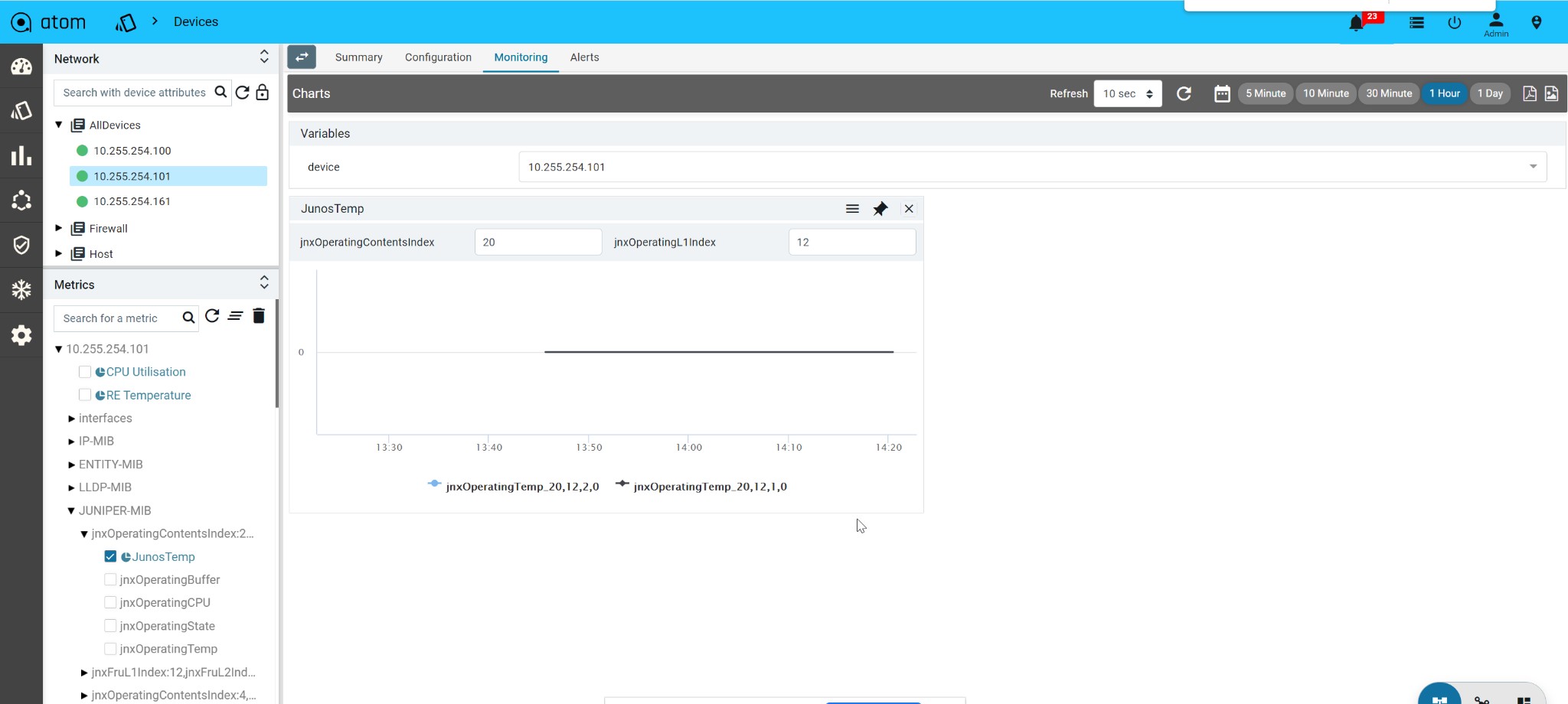
raising the alarm in the system. For more advanced use cases, you can define
auto-remediation actions such as executing a workflow to shut down an interface due to excessive BGP neighbor flaps or seek approvals by sending requests to ITSM tools such as Service Now. Each action can be triggered automatically or on demand by the user after analysing the event. Actions can be attached as generic (all events) or restricted scope by using alert filters.
Follow the below steps to get the event driven closed loop automation works.
-
- Define the Alert Rule – When to trigger an alert
- Each alert rule consists of set of conditions, severity, duration to raise or clear an alert
- Create the Alert Filter to Alert definition – Who gets affected
- It defines the scope for actions such as node level, severity based, location or hybrid etc. These are reusable entities.
- Attach the action with suitable filter and type – What needs to be done after the event
- Attach the actions such as email, remediation, RCA/Diagnostics on set of alerts Below are some of the use cases:
- Define the Alert Rule – When to trigger an alert
- Generate an alert for the interface packet drop events & diagnose the issue (by performing a set of operational checks on the device through workflow) and perform the right action such as upgrading the link or changing the QoS policy etc..
- Notify the management team on all critical events which needs immediate attention.
- Send location specific alerts to corresponding slack channels and email groups.
- Raise a servicenow incident for the hardware issues
- Alert BGP adjacency state stuck issues and diagnose & perform the available actions (check & change BGP port issues and AS Numbers, Peer IP, update source etc..) on demand with manual triggers.
- Create a dashboard with long standing issues on specific resource pools which are triggered from cisco IOS XR streaming telemetry sources.
Define Alert Rules
- Navigate to Assurance > Closed Loop Automation to define the alert rules
- Click Add and provide values for Name, Description, Message, Resource Path
- Name : Name of the alert definition which will contain the set of rules and associated actions
- Description : Provide the description about the what the rule is about
- Message: Define the message template which you would want to see as part of notification with variables replaced with corresponding values. It is based on Prometheus Go Templating. https://prometheus.io/docs/prometheus/latest/configuration/template_exampl es/
- Resource Path: Provide the unique XPATH using alert resulted variables. Resource Path and Name are the composite key to define the alert ingestion, maintain the history and resolve events appropriately. To use variables in the resource path, keep key names inside curly braces.check the following example:
Device={device}/Interface_name={ifDescr}. Here, device and ifDescr are the variables
Eg: Notifying each Interface Flap
-
-
- Name : InterfaceDown and Resource Path : /device/interfacename ,
- all the interface alerts will be treated as similar. If Gi1 Interface goes down on 10.0.0.1 and Gi2 comes to operationally UP on
- Name : InterfaceDown and Resource Path : /device/interfacename ,
-
10.0.0.2 then it will clear the Gi1 Active alert on other devices.
-
-
- Name : InterfaceDown and Resource Path : /device={device} then all the interface alerts will be aggregated by device
- Every InterfaceDown alert of the same device will become the history of other alerts and clear the events raised by other interfaces on that device.
- Name : InterfaceDown and Resource Path : /device={device} then all the interface alerts will be aggregated by device
-
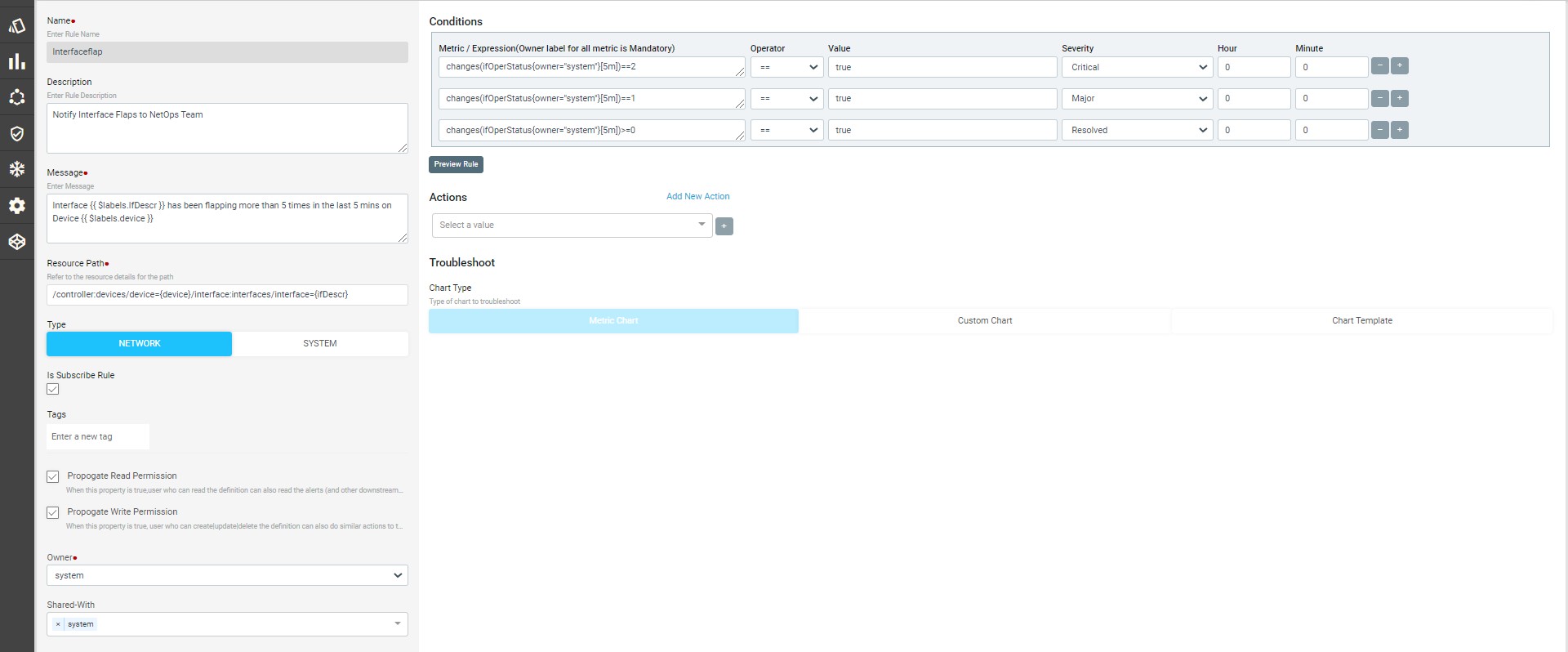
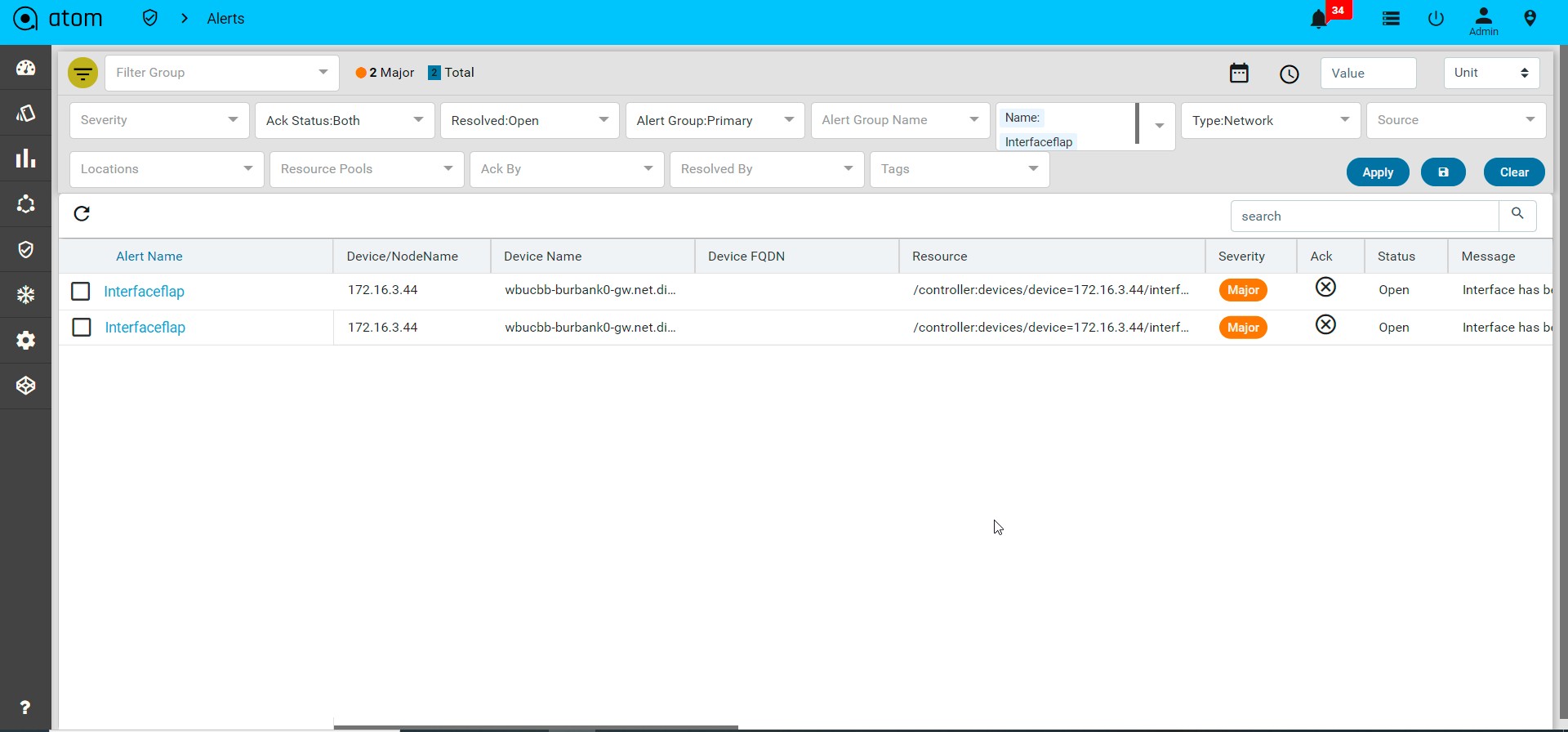
In both (i) & (ii) cases, manual action can be performed only on the latest instance of that since they are grouped by upper level or ad hoc entities.
-
-
- Name : InterfaceDown and Resource Path :
-
/device={device}/Interface_name={ifDescr} then all the interface alerts will be aggregated by device & Interface
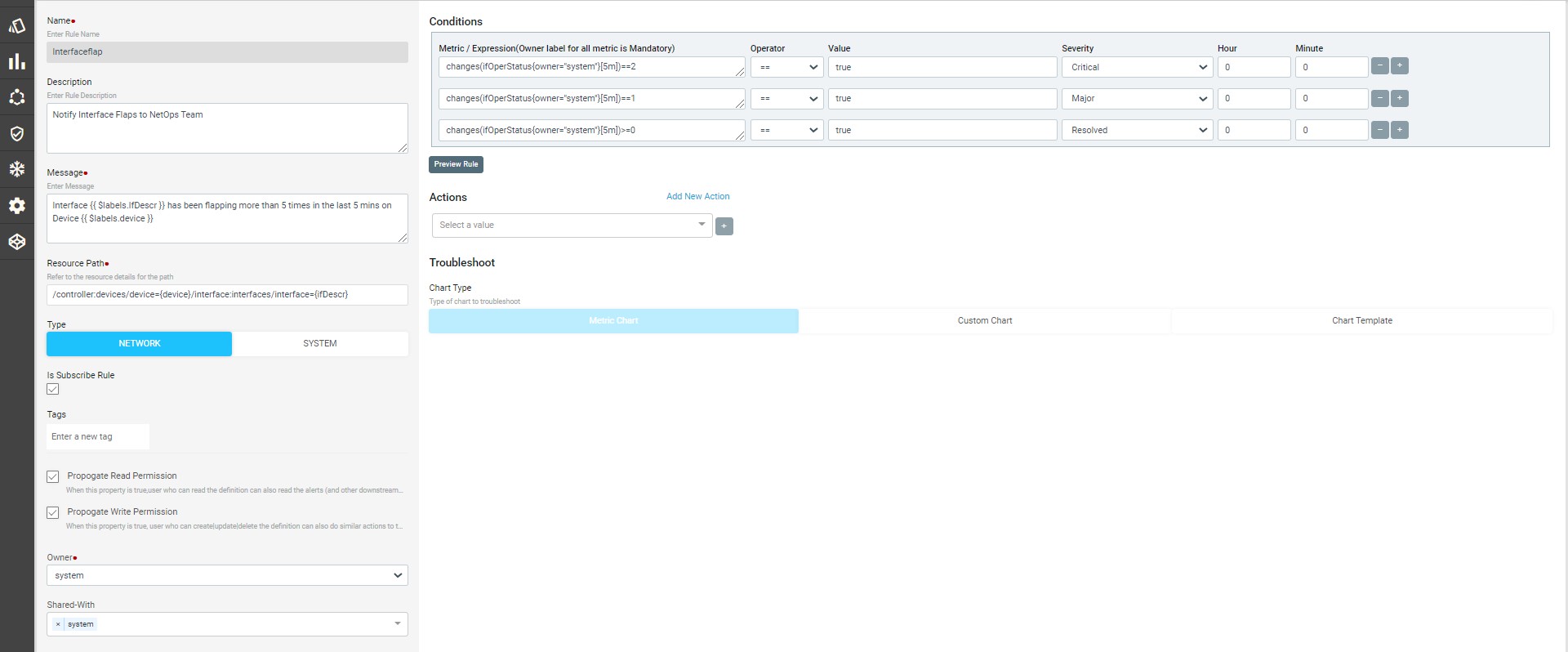
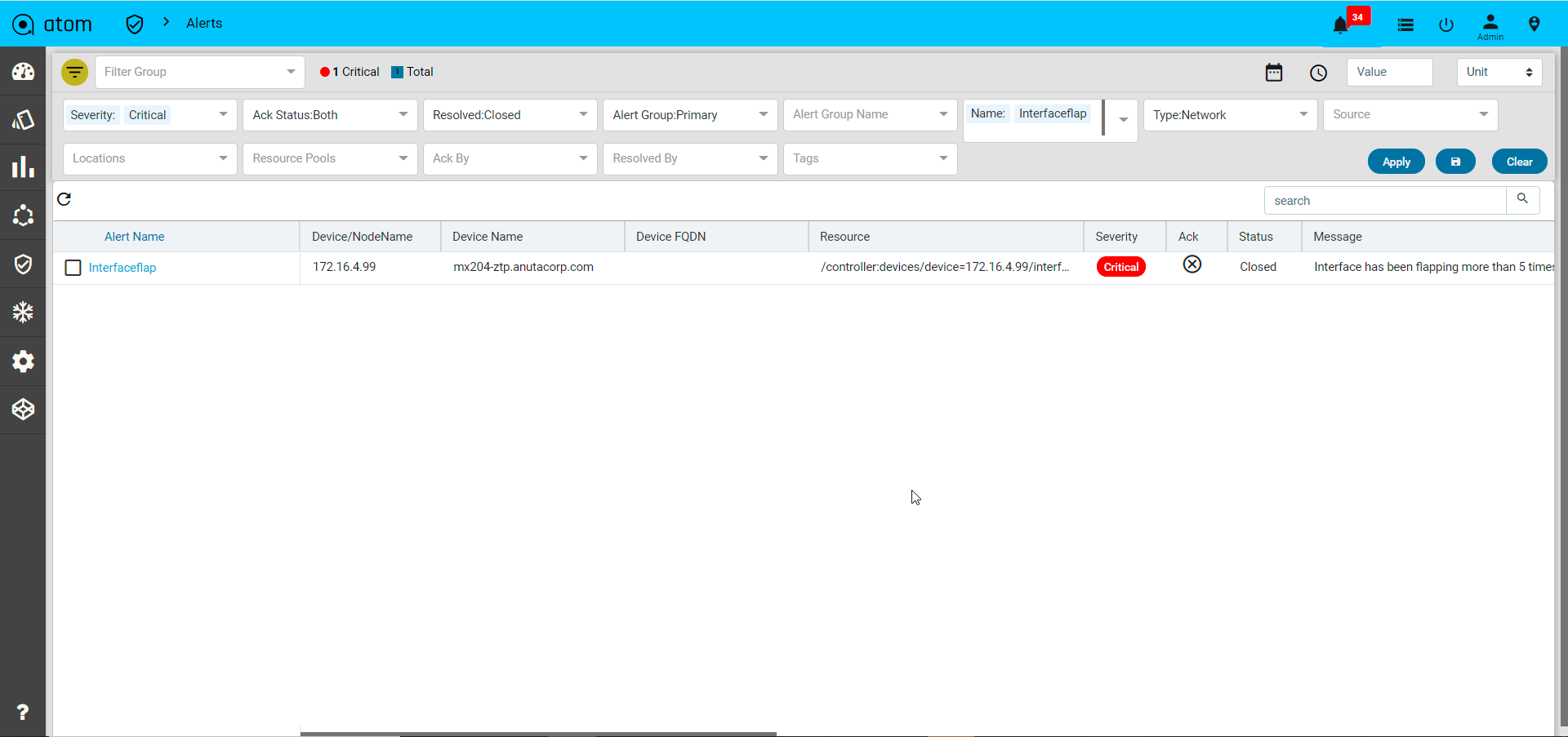
-
-
-
- It makes every event independent and manual actions can be performed at any time since we have the right set of affected object information available instead of just the latest event from that group.
- Auto clearing of events will happen properly. If Gi1 goes down on device 10.0.0.1 will raise an alert and it gets cleared only when it comes operationally on the same Interface on the correct device.
-
- Type: By Default, it is of type NETWORK. Please, don’t switch this flag for device related alert rules as it defines which database query for metrics and alerts.
- Tags: Provide a new tag name or choose the existing ones. it will be useful to create or apply the filter efficiently in an aggregated way.
-
- Configure the condition for each rule with the required thresholds.
- Metric/Expression: Provide the metric or expression in the condition
- Configure the condition for each rule with the required thresholds.
-
-
-
-
-
-
-
- If the condition has the expression with boundaries then no need to change the operator and value. It should be == true in that case.
- If the condition has only the metric or expression which doesn’t have any logical boundaries then operator and value will be useful. Refer below snapshot for more details.
- Severity: A severity level can be attached to the alerts if the sensors being monitored breach the threshold values.
- Duration: Alerts will be fired once they have been returned for this long
-
-
-
-
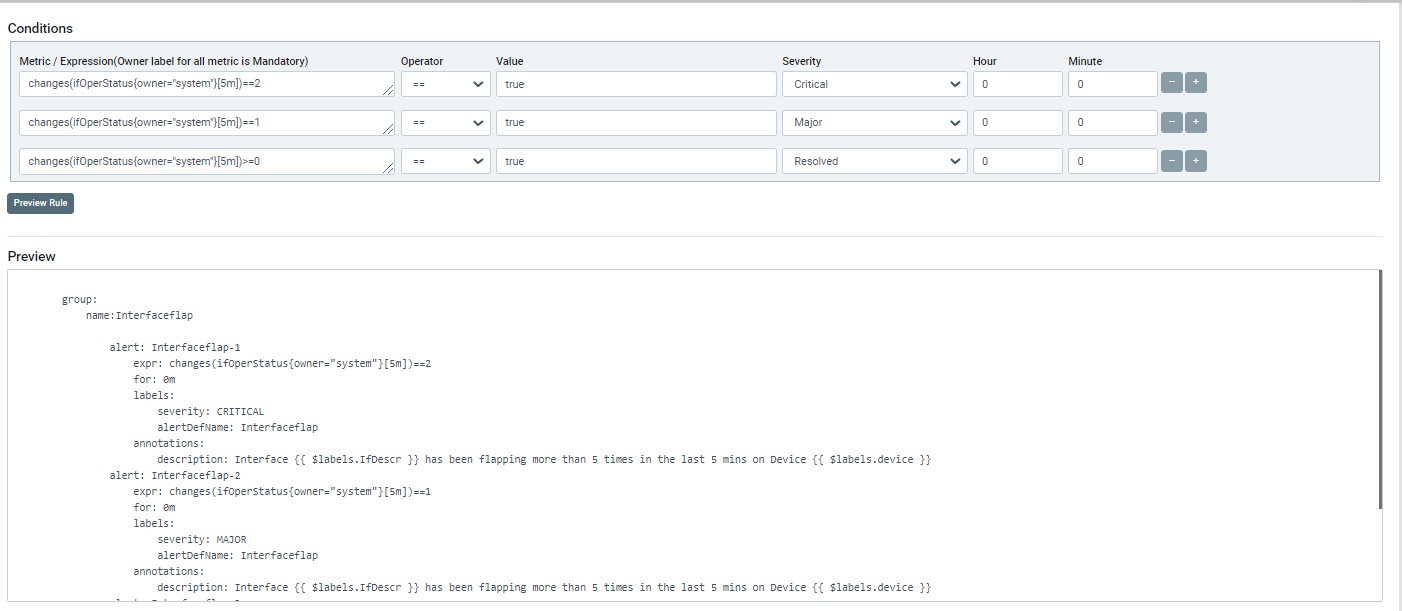
-
-
-
- ‘Live Preview’ shows the generated prometheus rule with the defined thresholds and its metadata.
-
-
Define Alert Filter
Alert filters are to define the scope for any action to be performed or group them together based on certain criteria. We have the following attributes to create the filters : Name, Acknowledge State, Resolved State, Alert Name, Severity, Device-Groups, Resource Pools, Locations, Tags and Relative or Absolute times.
Follow below steps to create and view and filters:
- Navigate to Assurance -> Alerts
- Click on top left corner icon to see the available attributes to define the alert filter
- Choose the values from the dropdowns and apply the filter to see existing alerts.
- If step #3 provides the desired filtered result then go ahead and save the filter by providing the name and optionally save as a dashlet in the dashboard. Refer to the Dashboards section for more details.
Navigate to the top left corner and click on the filter icon to see possible filter attributes.
Choose the filter attributes and click on the Save button to ‘Save Filter’.
Save filter will provide an option to provide a name and to attach to the dashboard.
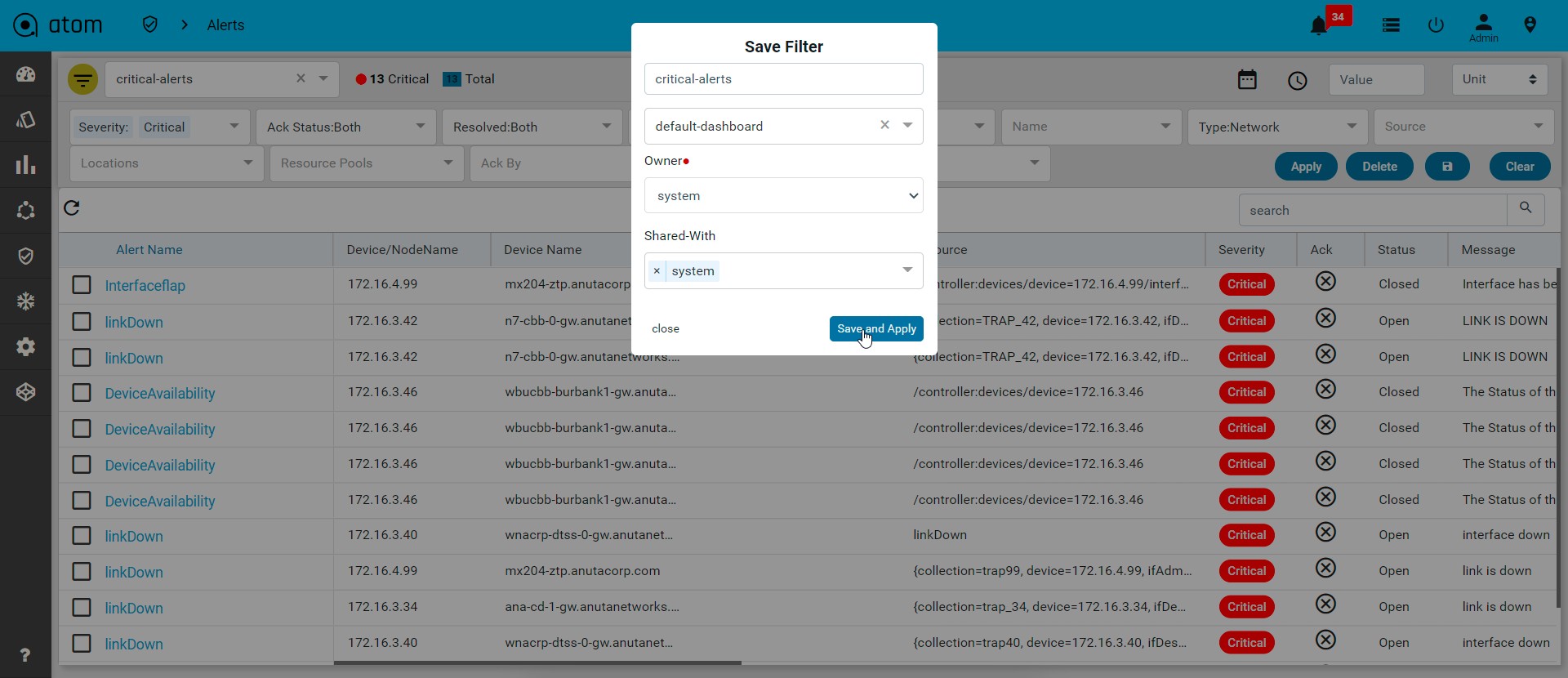
To clear selected filter attributes, click on the Clear button in left down corner
Navigate Dashboard> select alert-Dashboard in right corner and click on it to view the saved filter dashboard
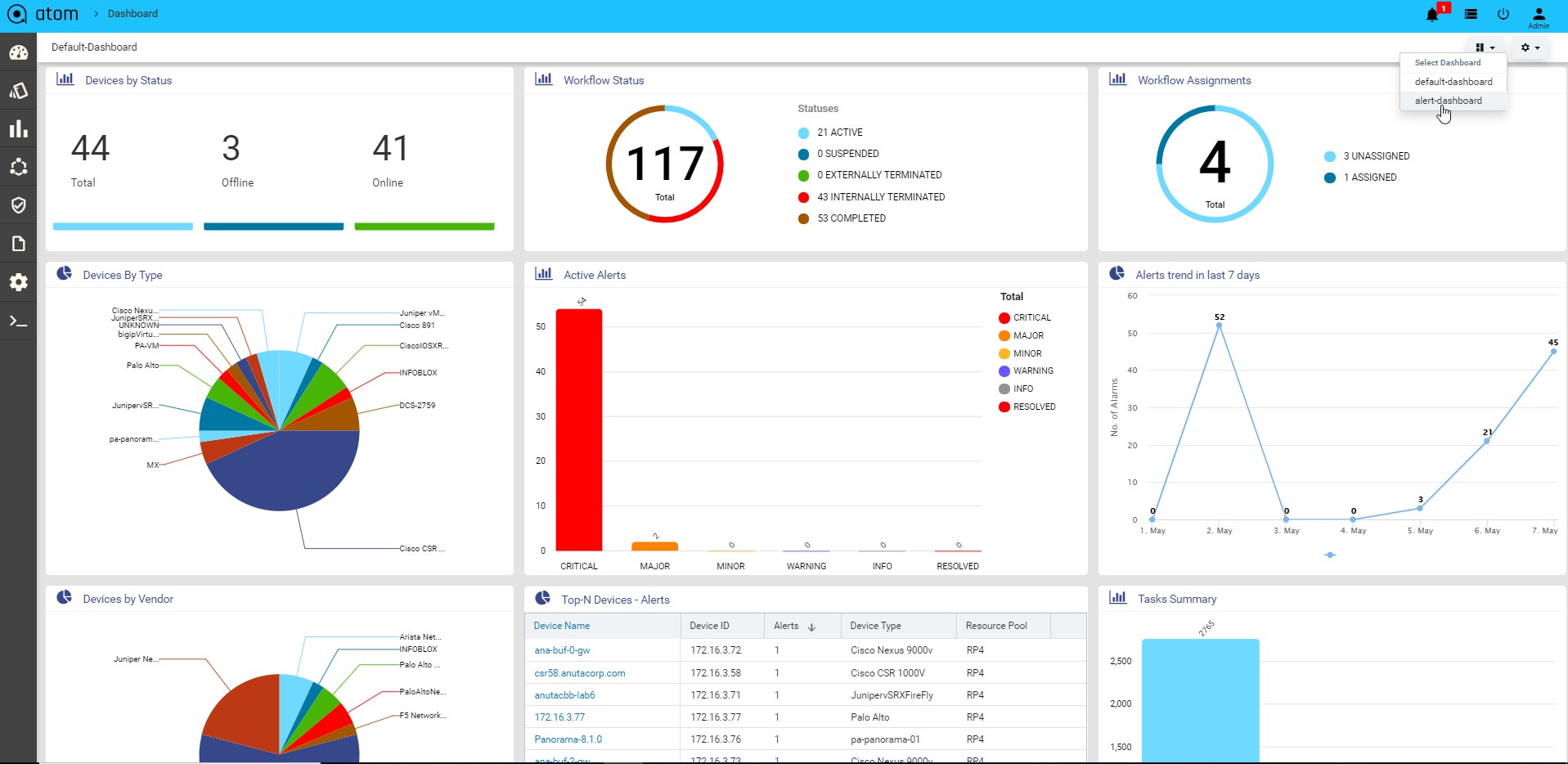
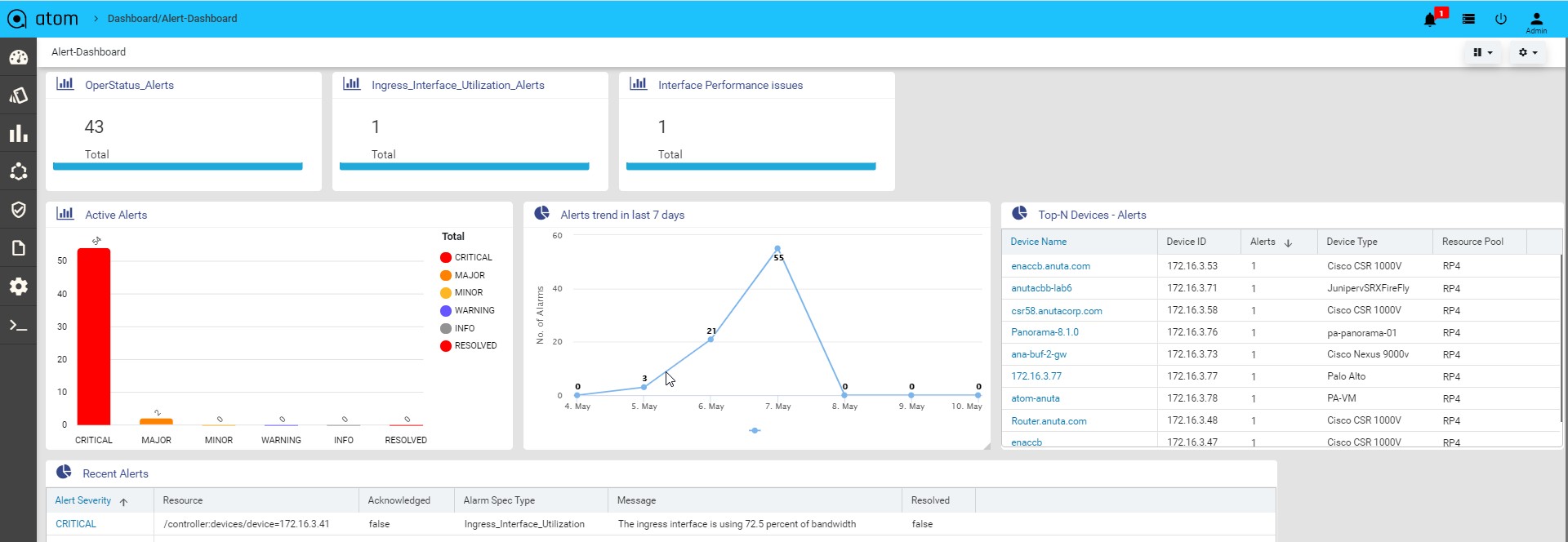
Attach Remediation Actions
Once you define the baseline behavior by specifying the sensors to be monitored, the next step is to define the actions to be automated. The actions range from simple notifications to complex remediation actions. Here, we will bridge the alert to action behavior by using alert filters.
The steps below will help you define the necessary actions for the rules defined
- Navigate to the Assurance -> Closed Loop Automation
- Click on the Alert Actions tab
- Click the Add (+) button to create the action template and provide the Name, Description.
- Name : provide unique name to for action template
- Description : provide the description of action and what is does
-
- Trigger For : It is used to define scope of action. All Filters will enable this action for all the alerts and Alert filters will restrict scope to defined criteria as per selected named filters.
- Alert Filters: Select the name of the alert filter to attach an action
- Type: choose the type of action such as slack, email and workflow or rpc
- Trigger: Auto Trigger is used to perform closed loop automation use cases and Manual trigger is used to perform on demand diagnostics and notifications. However, any type of trigger can be used based on the use case and criticality of the affect.
- Is Action Enabled: It is to make sure the defined Action template is ready to attach for an alert or not. If we disable this, this particular action template won’t be shown or get triggered when the event happens.
Below is the snapshot to send an email notification for every alert
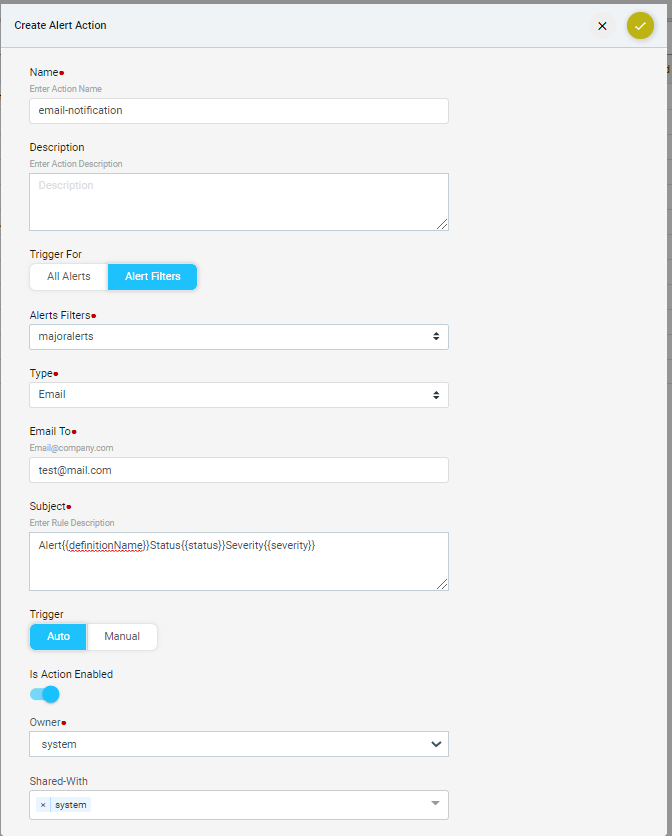
If Action is enabled then those all enabled actions will show in Alerts action window as shown below
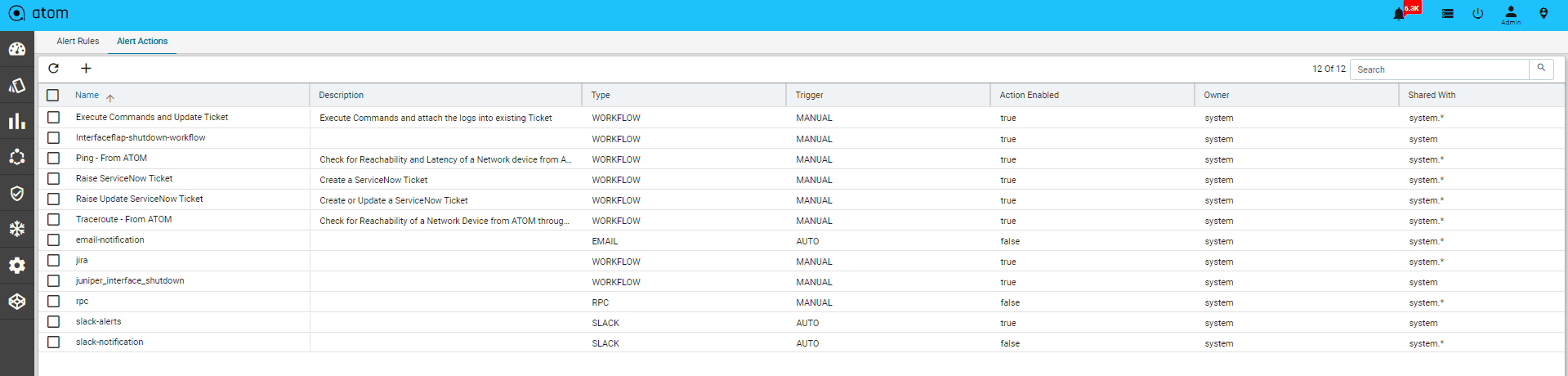
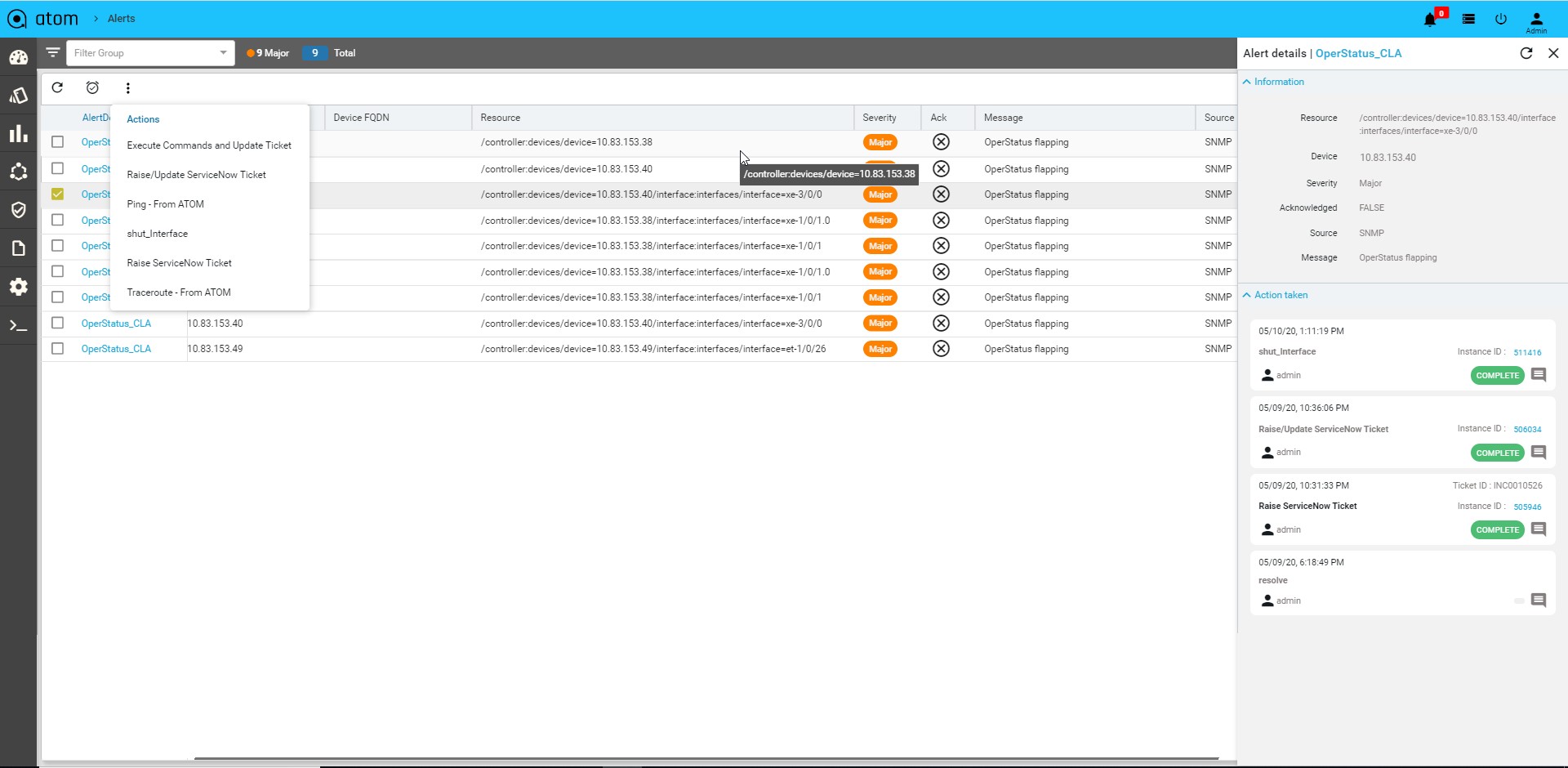
Actions
Slack
- Slack Channel: Provide the channel name
- Webhook: Provide the slack channel webhook, Refer below link to create incoming webhook in slack https://api.slack.com/messaging/webhooks#posting_with_webhooks
- Body: Provide the template to format the message while notifying via slack, here you can use the keys from alert
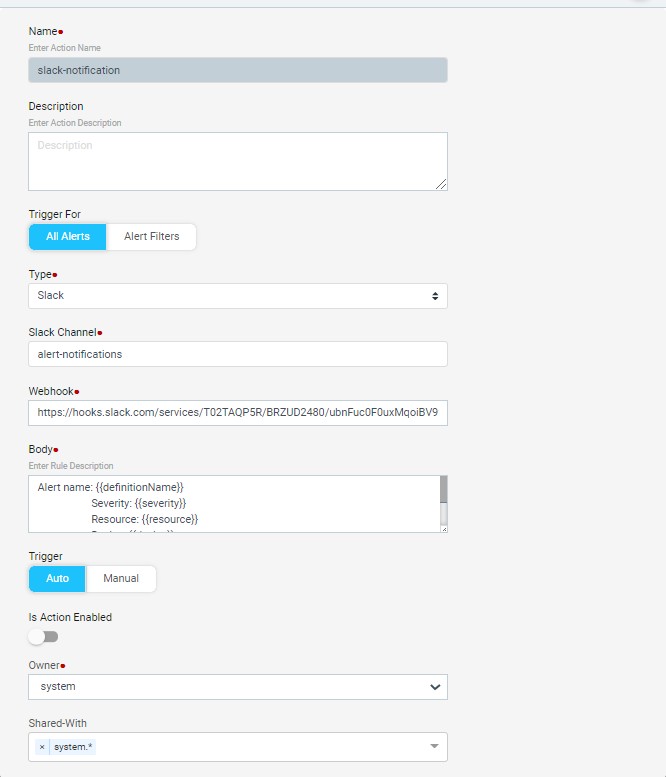
Below the slack notification
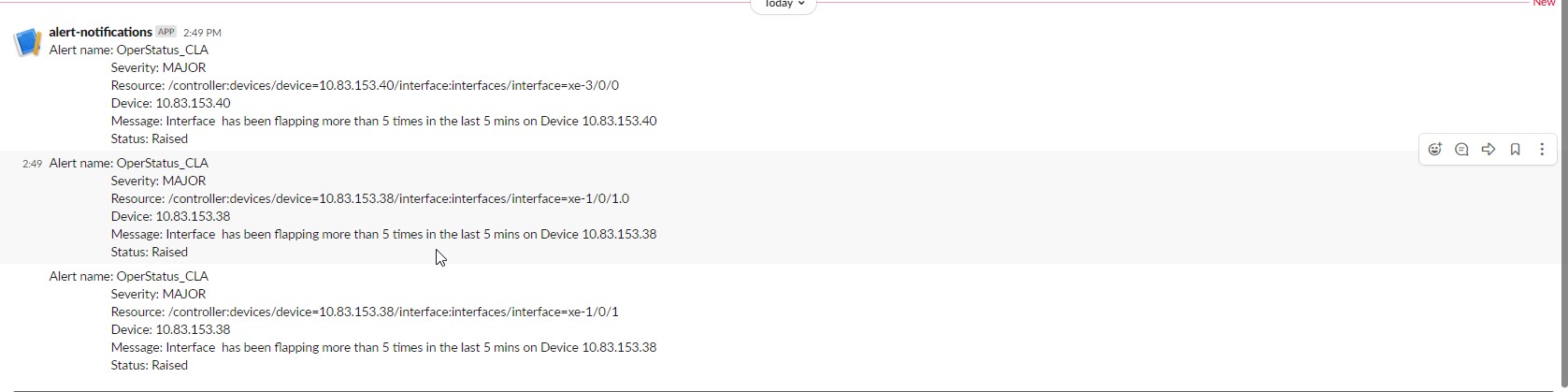
- Email to: Provide the email address
- Subject: Provide the subject for an email
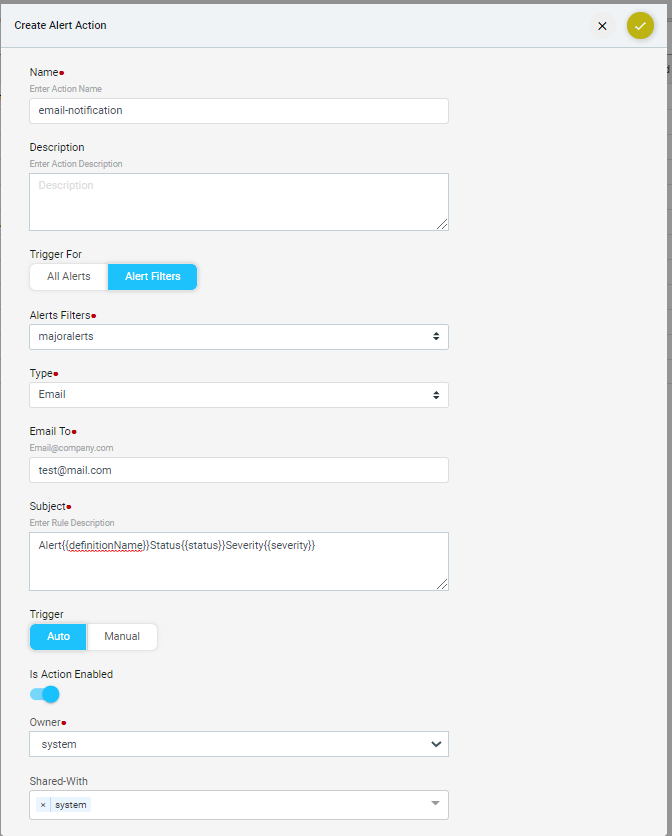
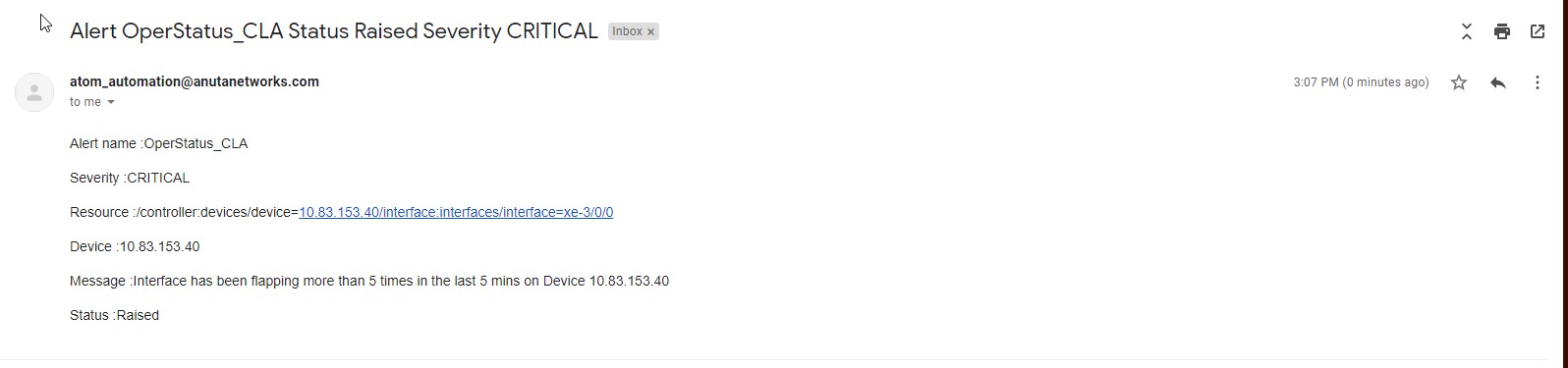
Currently, templatization for email body is not supported in ATOM.
Workflow
Workflow: Choose the available workflow by its name to diagnose or remediate the issue or refer the workflow section to create new workflow and packaging
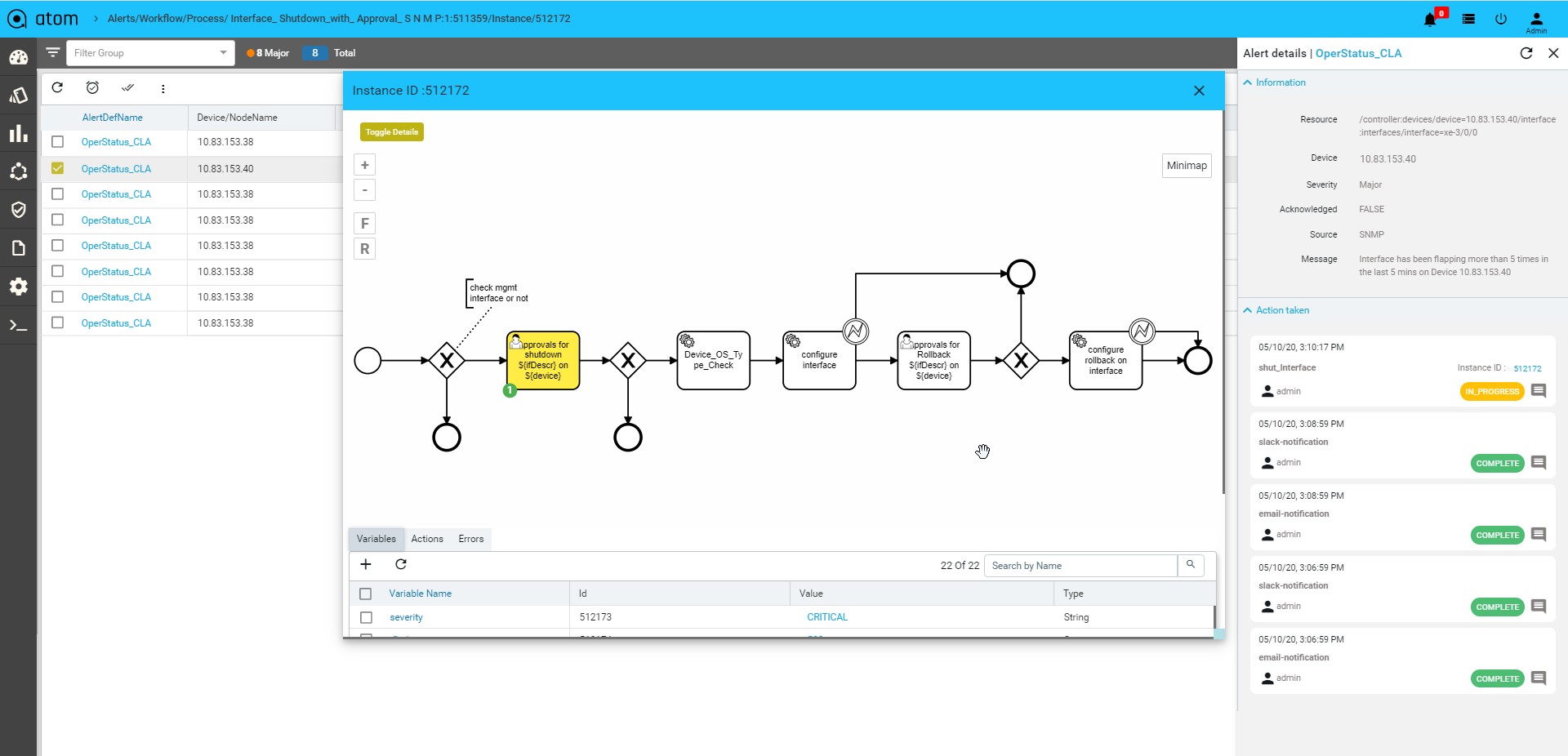
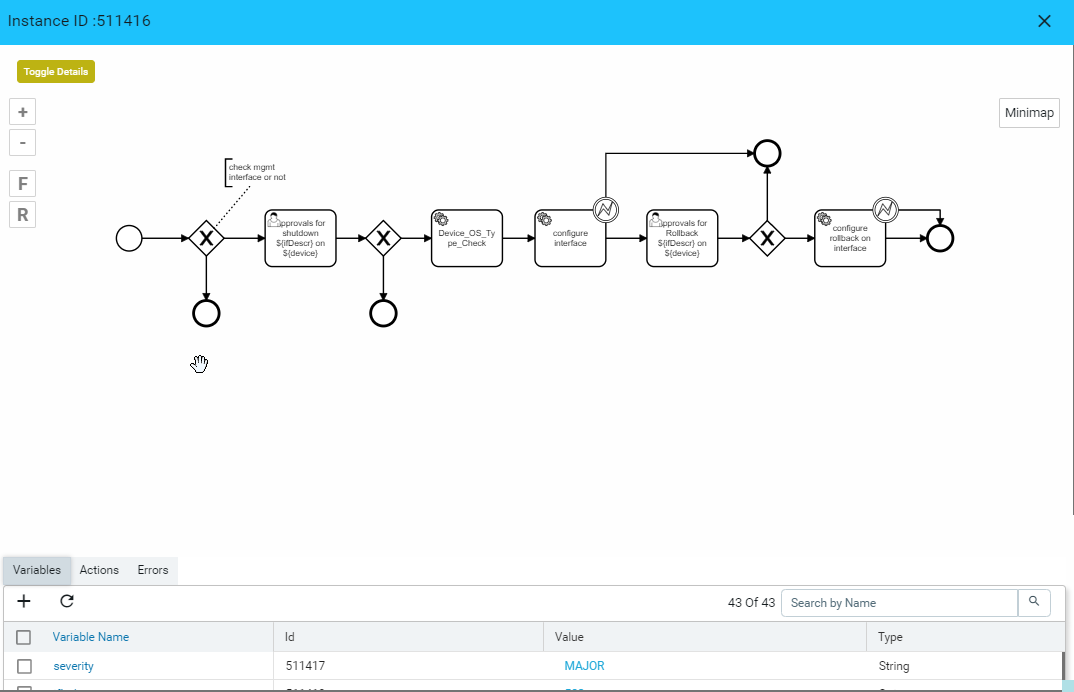
RPC
- RPC: choose the available RPC’s or refer the developer guide to create new rpc’s
- Inputs: Choose input method key-value or json, xml to provide the payload
Alerts Summary
Below is the snapshot for alert summary
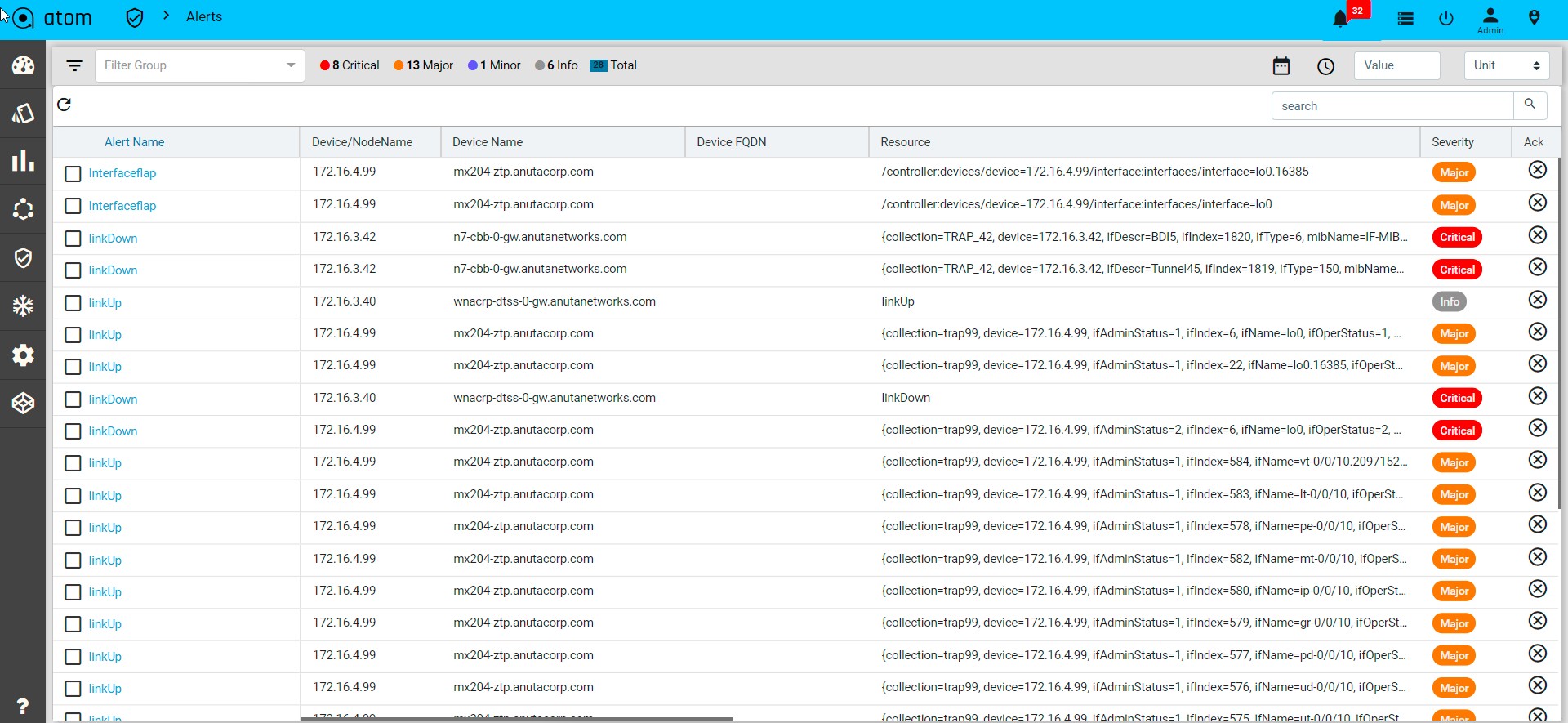
To see the alert history, click on the entry.
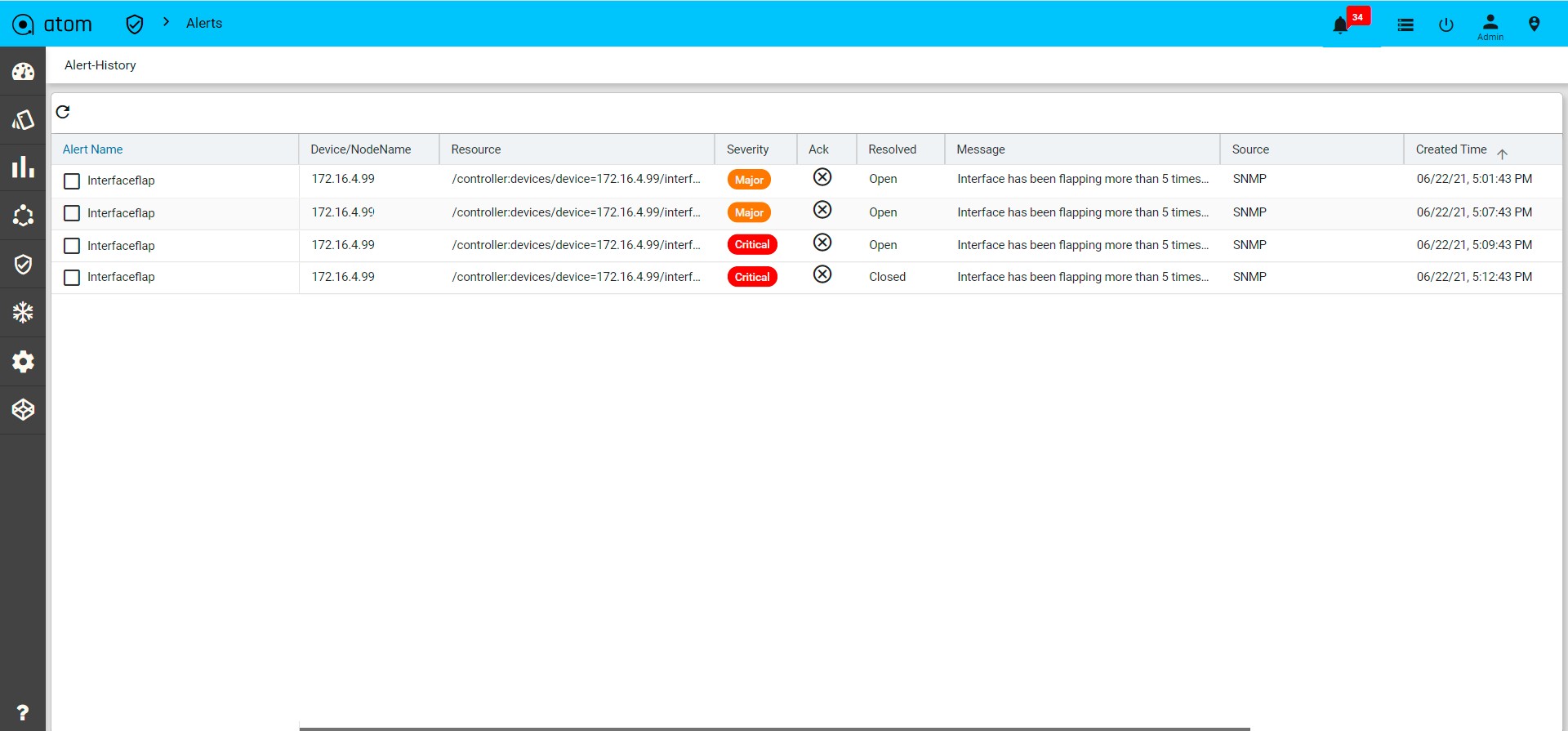
Manual actions will be shown on click of alert record with vertical ellipsis on top
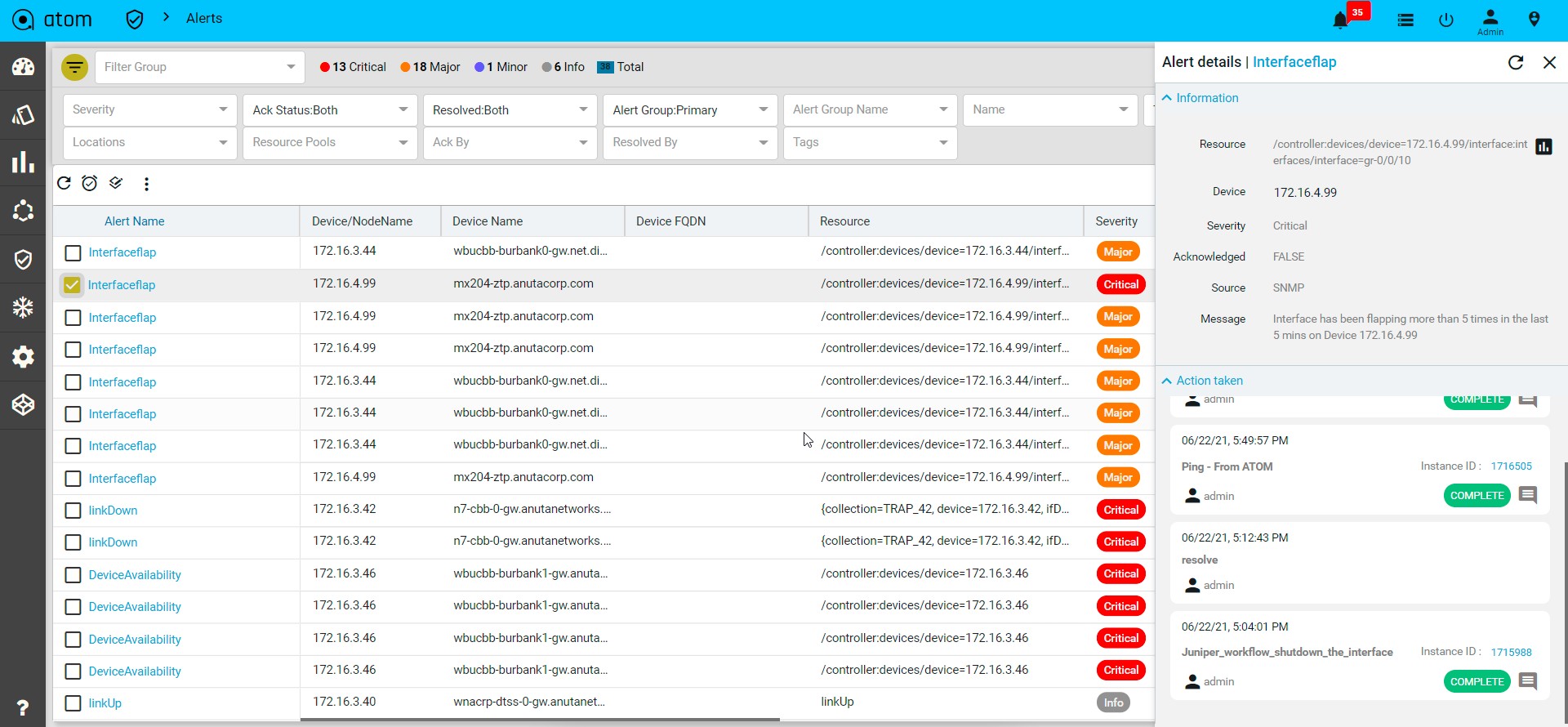
Filter objects can be seen on click on the action in top left
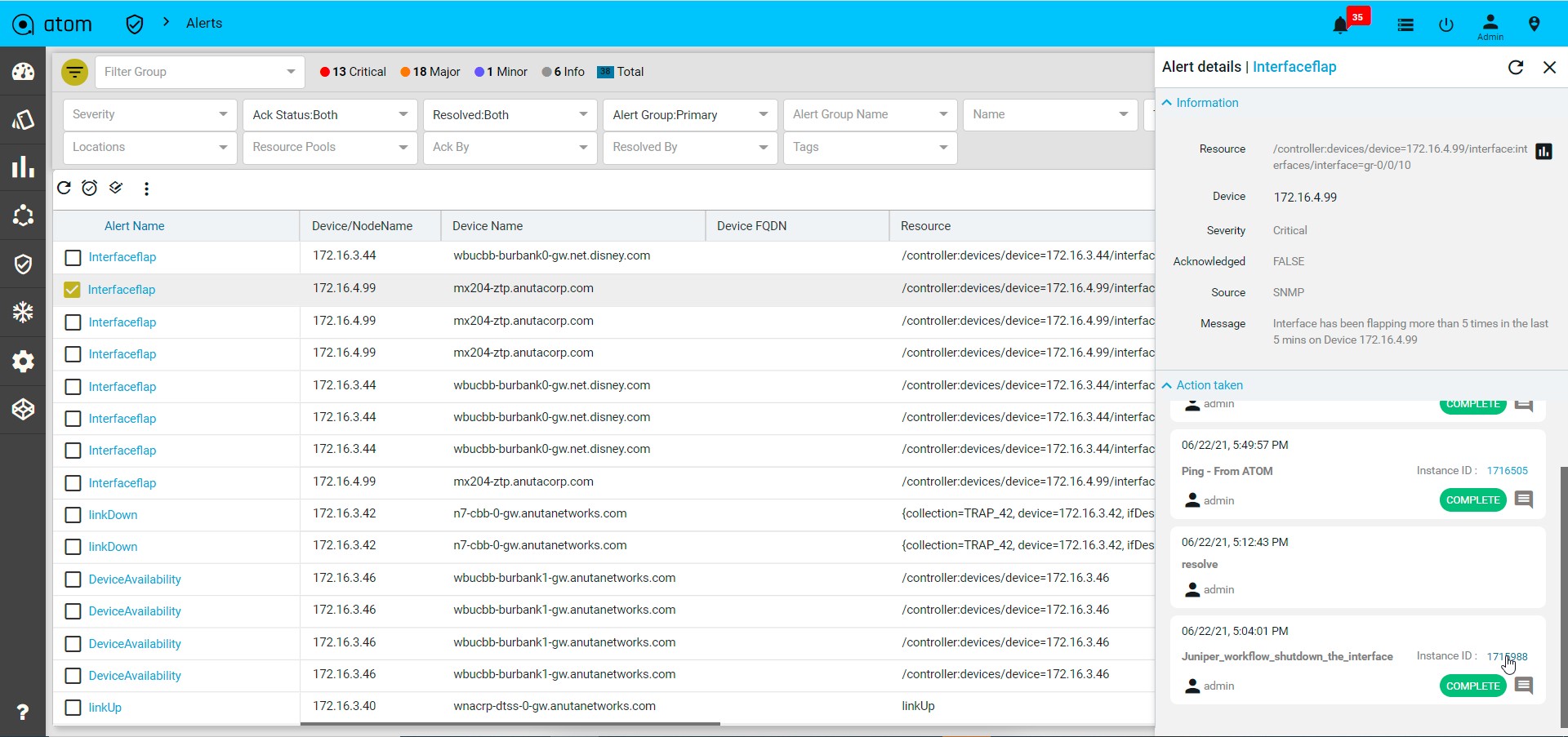
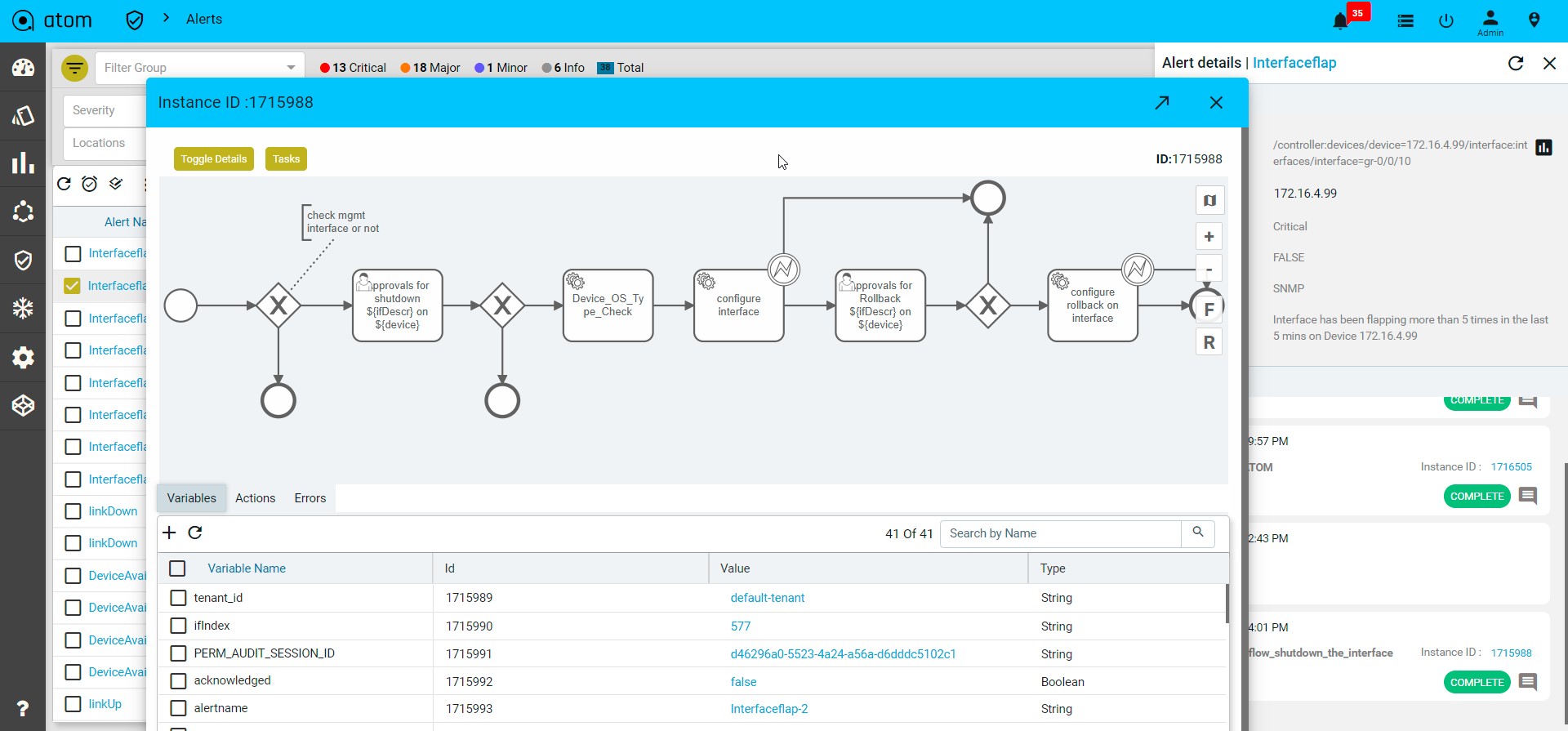
Alert Dashboard
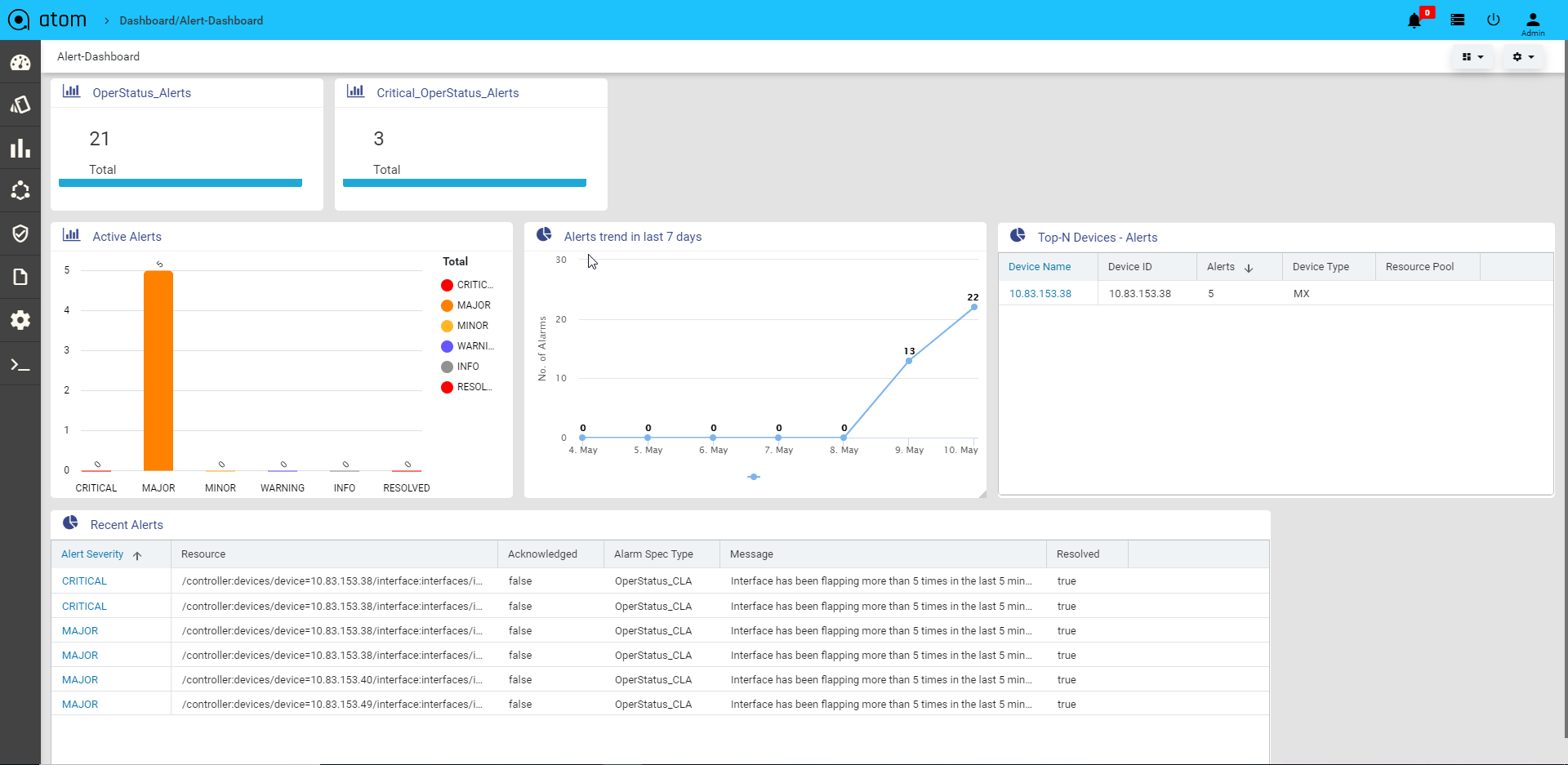
Inventory
[[ Introduction – Chassis, Interface, Software]]iSoftware Image Management
Image Upgrade Workflow
pre-checks and Post-checks to ensure the device is working as expected after the upgrade.
Image Repository
ATOM acts as a Network Element Image Repository (Image Server) as well as Config Repository. Devices can boot an Image from ATOM Image Server manually or through ATOM Network Element Software Image Upgrade Workflow. Image Manager is a replica of the Minio repository. All the images are saved to a minio bucket named ‘atom.device.images’ and all the configs are saved to ‘atom.device.configs’. The supported protocols are Http, anonymous ftp, tftp.
.
Following steps on ATOM & Upload Images:
- To upload a file to the Image Manager navigate to Resource Manager > Image Manager
- To upload image file, click on the upload option after selecting ‘atom.device.images’ option
- To upload config file, click on the upload file option after selecting ‘atom.device.configs’ option
Once files are uploaded to the image-manager then login to the client device, then transfer the files to a particular location on the device by using scp protocol..
Syntax : file copy
scp://{user-name}@{agent-node-ip}/{path}/{file-name} {Destination path}/{file-name} Example :
scp://admin@10.113.10.44/pub/images/junos-vmhost-install-mx-x86-64-18.3R1.9.tgz re0:/var/tmp/junos-vmhost-install-mx-x86-64-18.3R1.9.tgz

Software Version Compliance
Software Version Compliance feature enables defining policies and enforcing software currency checks for network devices. The policies support defining N-1 (previous), N (current), N+1 (next) compliant versions for vendor and device models. Reports are generated for the software version checks. Summary reports by device model and vendor are available. The out of compliance devices can then be upgraded using Software Upgrade workflows available in ATOM.
Network Automation
ATOM provides stateful or Service and stateless (MOP) automation framework.
Stateless Low Code or MOP automation – Low Code Workflow automation enables network administrators to perform method-of-procedures involving different actions configuration, operations including show & exec commands on the device. Multiple actions can be stitched together to form a flow. Such flow is executed on one more device with appropriate user inputs.
Example:
- Device Software Image Upgrade
- Protocol Migration [IPV4 TO V6, OSPF to ISIS]
- Hardware RMA/ Refresh [Moving from one vendor to another]
MOP Automation can be a combination of Stateless Action and Staful actions as well. In such scenarios MOP will contain stateless actions like pre-checks while performing API invocations against Device or Service Models to perform stateful transactional action.
Such tasks have no requirement for statefulness and can be best developed using Workflow Automation.
Example:
- Application Deployment in Data Center with Pre-checks and Post-Checks
- Branch Config Deployment with Pre-Checks & Post-Checks
Stateful Service Automation – ATOM Service automation helps administrators develop stateful and atomic transactions. Admins can create service models that enable Create, Update and Delete operations (CRUD). Such operations can be carried out throughout the life of the service. Brownfield service discovery is also supported.
Example:
- Application Deployment in Data Center
- Layer-3 VPN
- Layer-2 VPN
- Private Cloud to Public Cloud Interconnect
Network Workflow & Low Code Automation
Workflow breaks down an activity into subtasks and ties them together with network events, provisioning actions, show-commands, pre-checks, post-checks, user forms and approvals, timed background tasks, inventory checks etc.
Workflow Automation offers an intuitive graphical designer to automate network provisioning and maintenance activities.
Administrators can create simple or complex flows using ATOM Workflow’s drag and drop interface. ATOM Workflow has prebuilt adaptors to enable integration with ticketing, billing, OSS, BSS and many other network elements. Workflow can also automate multi-level approval sequences. Use workflows for a one time project or for repetitive tasks. Workflow development is covered in “Workflow Modelling” section in the ATOM Platform Guide guide. For automation of tasks that require stateful and atomic transactions it is advised to use ATOM Service Models discussed in ATOM Platform Guide.
Uploading Workflow Package
Navigate to Administration > Plugins & Extensions > Packages
- Click on Add at the top bar to upload the packages.
- Upload workflow package and click on the tick mark
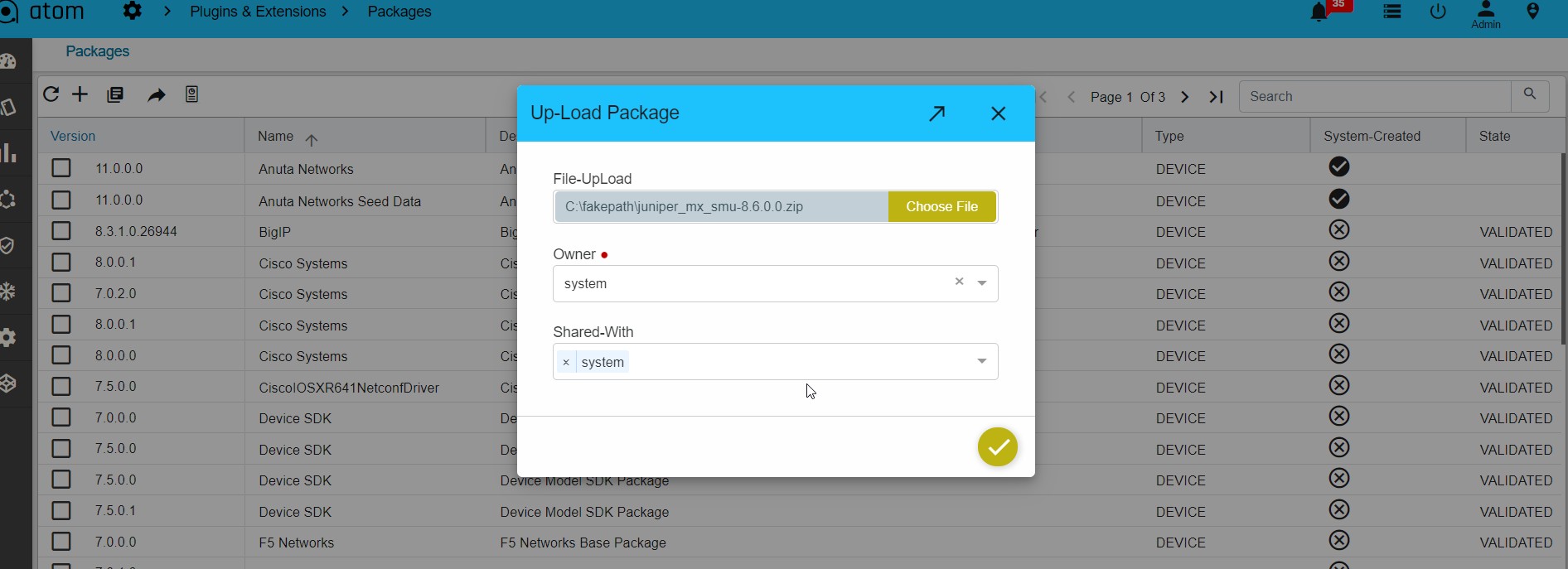
- Select the package and click on Activate
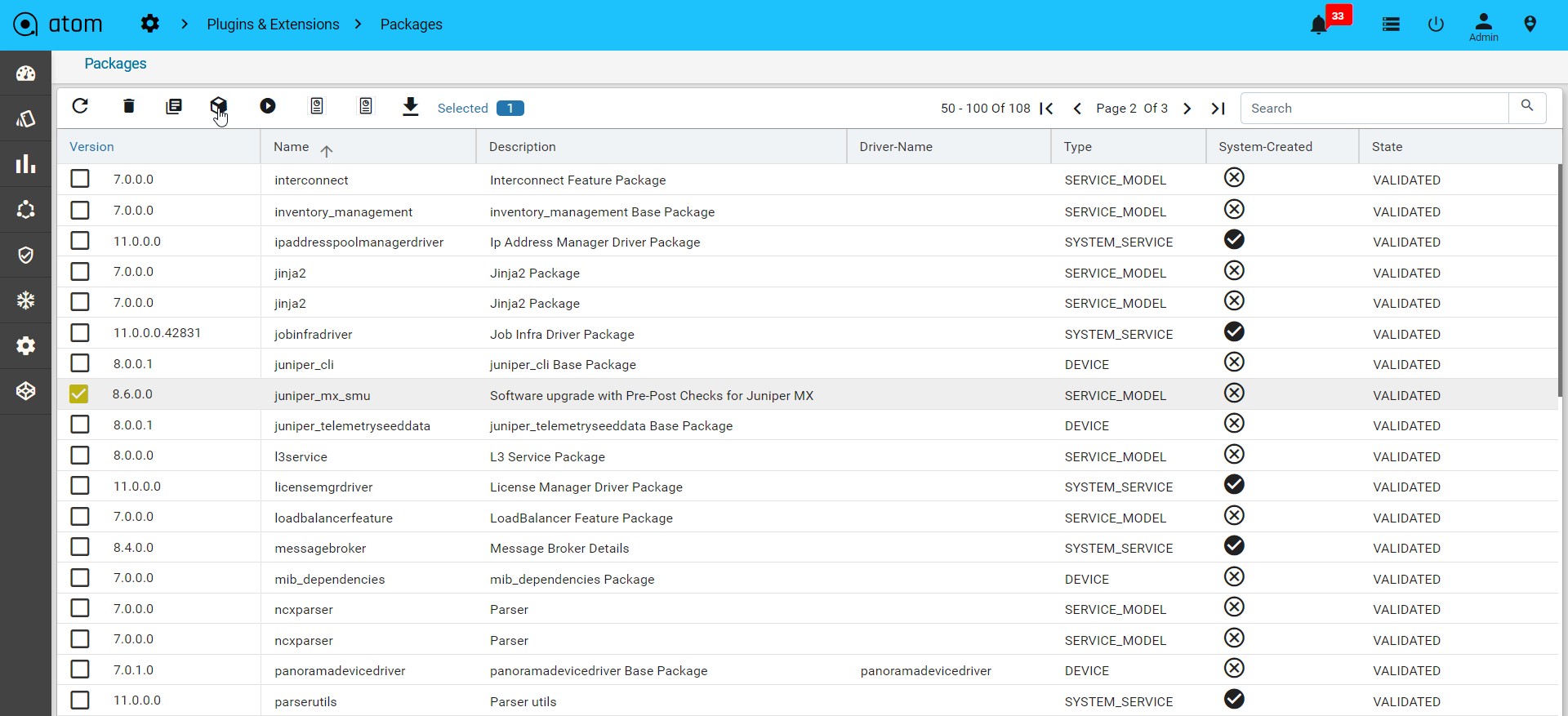
Workflow Lifecycle Management
A workflow definition defines the structure of a workflow. A workflow instance is an individual execution of a workflow definition.The relation of the workflow instance to the workflow definition is the same as the relation between Object and Class in Object Oriented Programming.The workflow engine is responsible for creating workflow instances and managing their state.
Workflow Instances traverse different states as they progress from the start to end.The various states are as listed below:
- Active : Once the workflow is started it gets into an active state. Through-out the different tasks , workflow continues to be in an active state and indicates an error free execution.
- Error State : If there are unhandled exceptions in the scripts and programmatic/syntactic errors in inline scripts the workflow execution goes to an error state.
- Internally Terminated : If there are any errors in communication with the device or any custom RPCs throw exceptions which don’t have explicit error handling defined in the workflow they are internally terminated by ATOM and state is updated accordingly.
- Externally Terminated: If the Network Administrator finds any unexpected behavior during any point in the workflow execution he has an option of manually terminating the workflow instance. This is the only state which the end user can manually state to terminate the flow.
- Completed:Once the workflow is terminated and has reached the stop event, the workflow goes to a completed stage and indicates a successful positive flow execution.
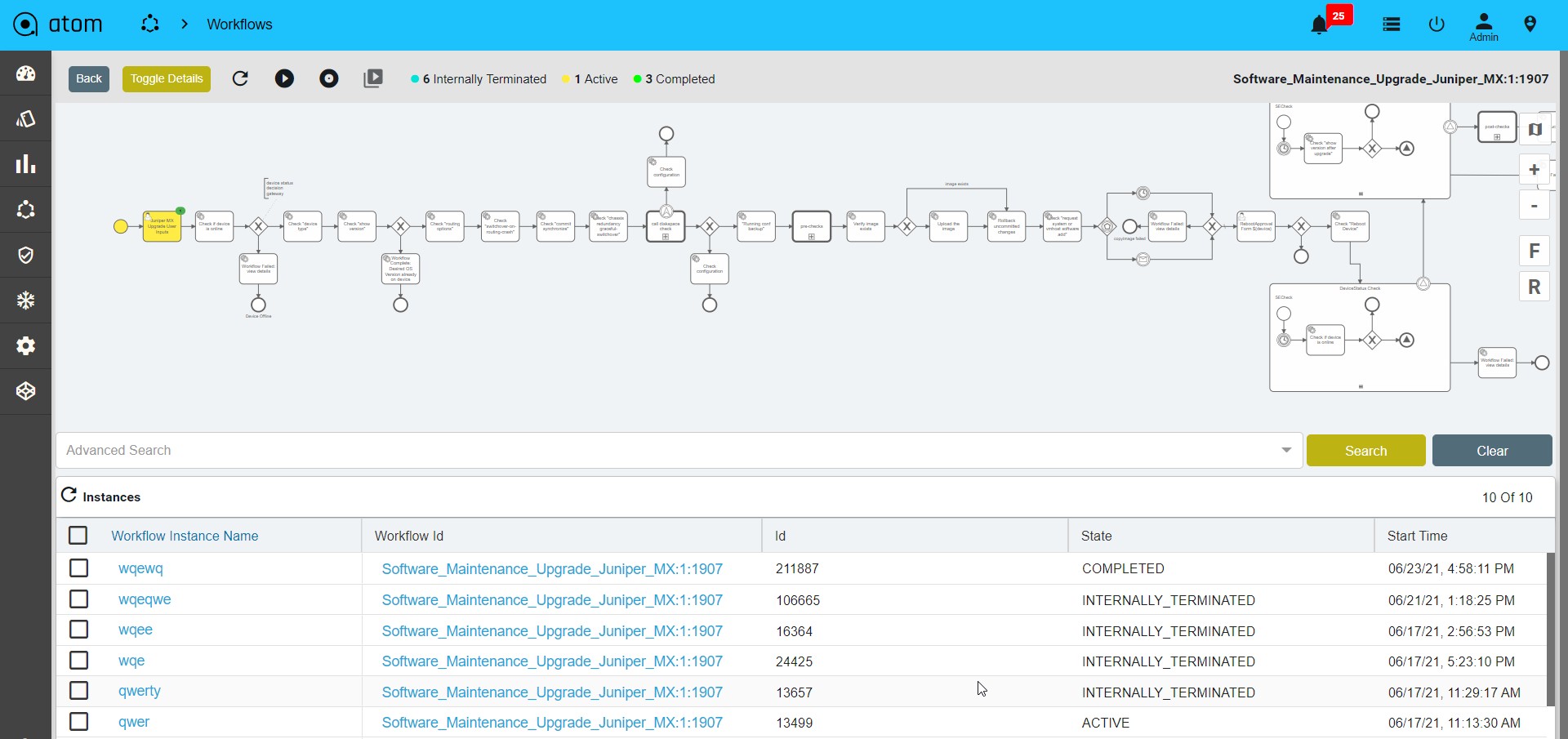
Start Workflows :
To start a workflow instance follow the steps below.
- Navigate to Automation > Workflows > Workflows
- Select the workflow package from the list
- Click on Start to start an instance of the workflow and provide valid Instance Name
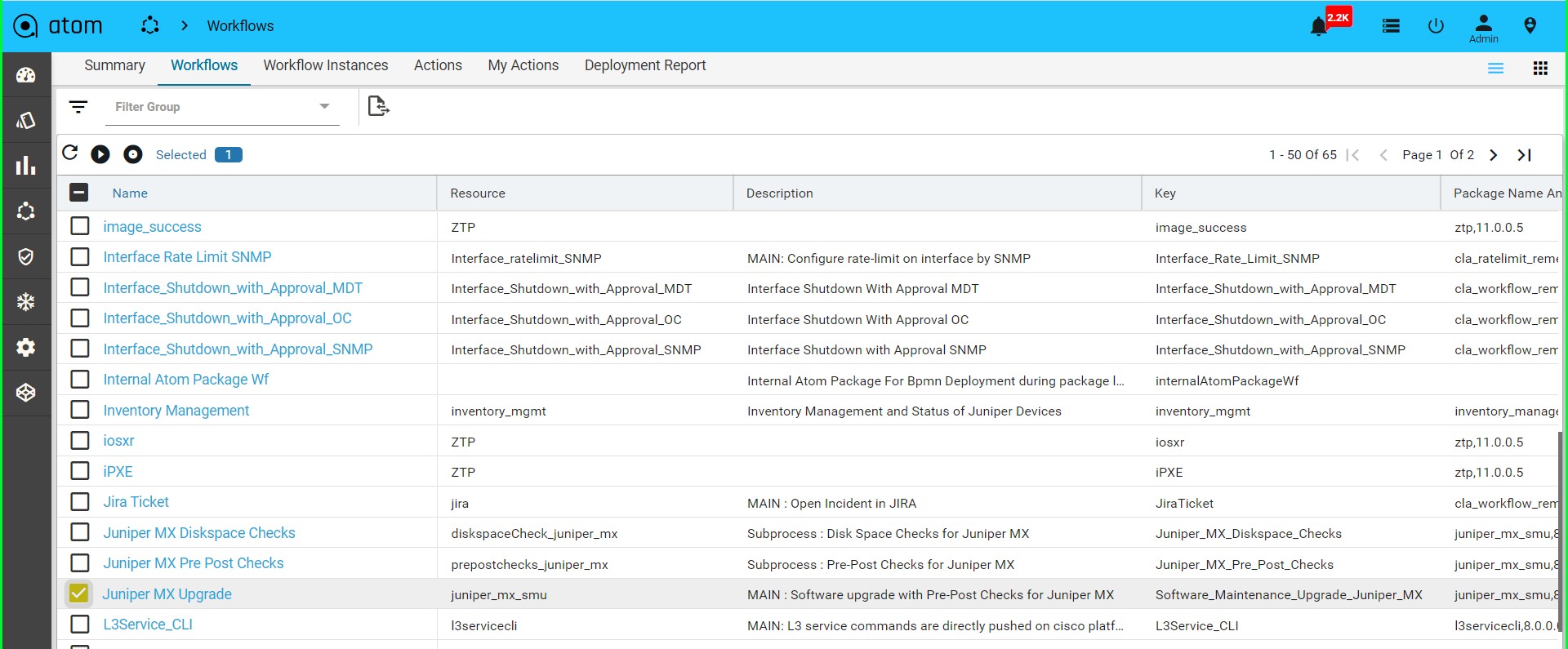
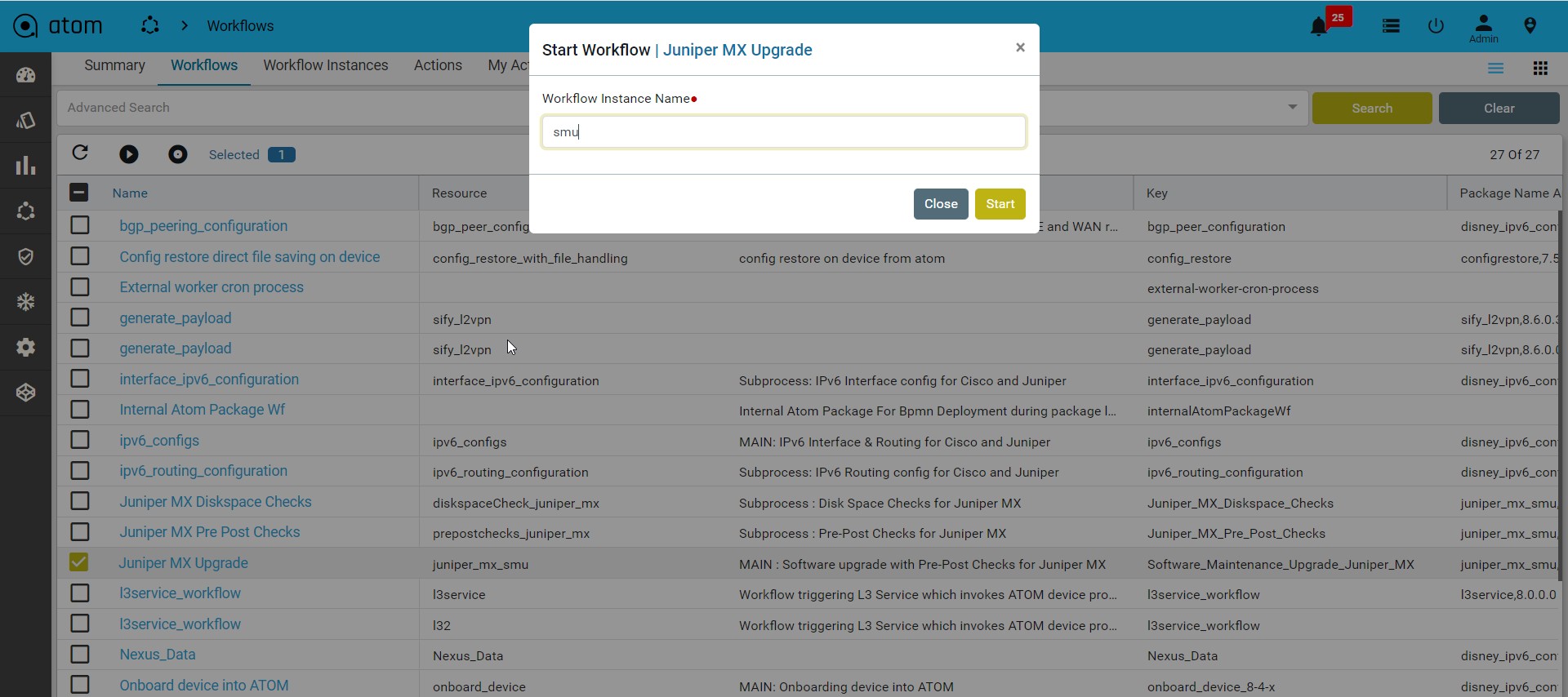
Inspecting Workflows:
To view the current running stage of the workflow
- Navigate to Workflows > Instances
- Click on Inspect
This opens a window with the workflow elements. Green indicates successfully completed tasks. Yellow indicates the current task being executed
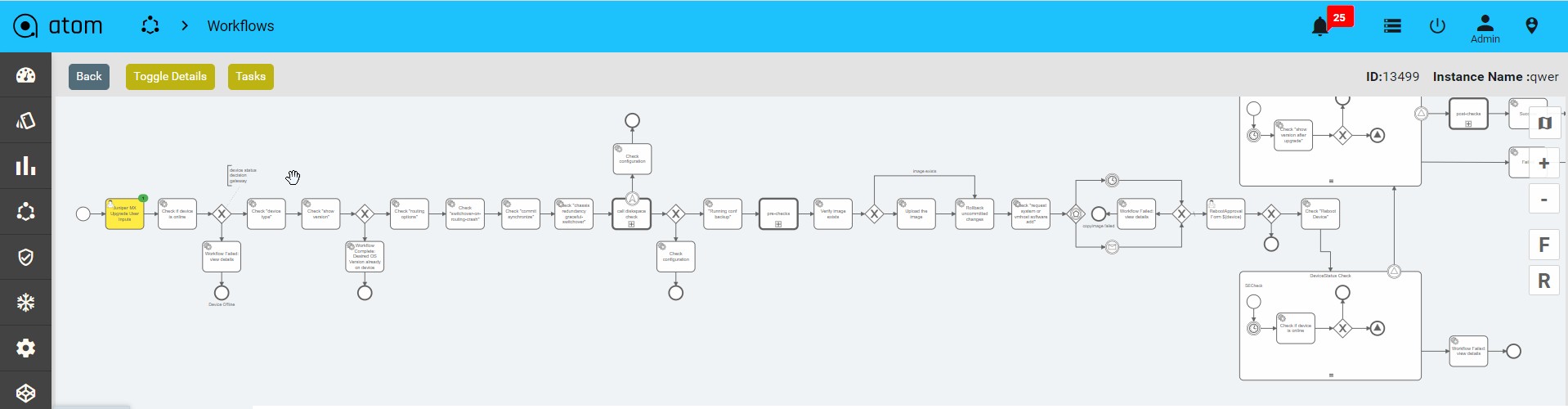
Suspend/Pause Workflows:
In the workflow definition view and in the workflow instance view, can suspend the selected workflow definition or workflow instance by using the suspend button on the panel.
Workflow Definition Suspension
If you suspend the workflow definition, you prevent the workflow definition from being instantiated. No further operations can be done while the workflow definition is in the suspended state. You can simply re-activate the workflow definition .
Workflow Instance Suspension:
If you suspend the workflow instance, you can prevent the workflow instance from being executed any further. This includes suspending all tasks included in the process instance. You can re-activate the process instance at any later point of time.
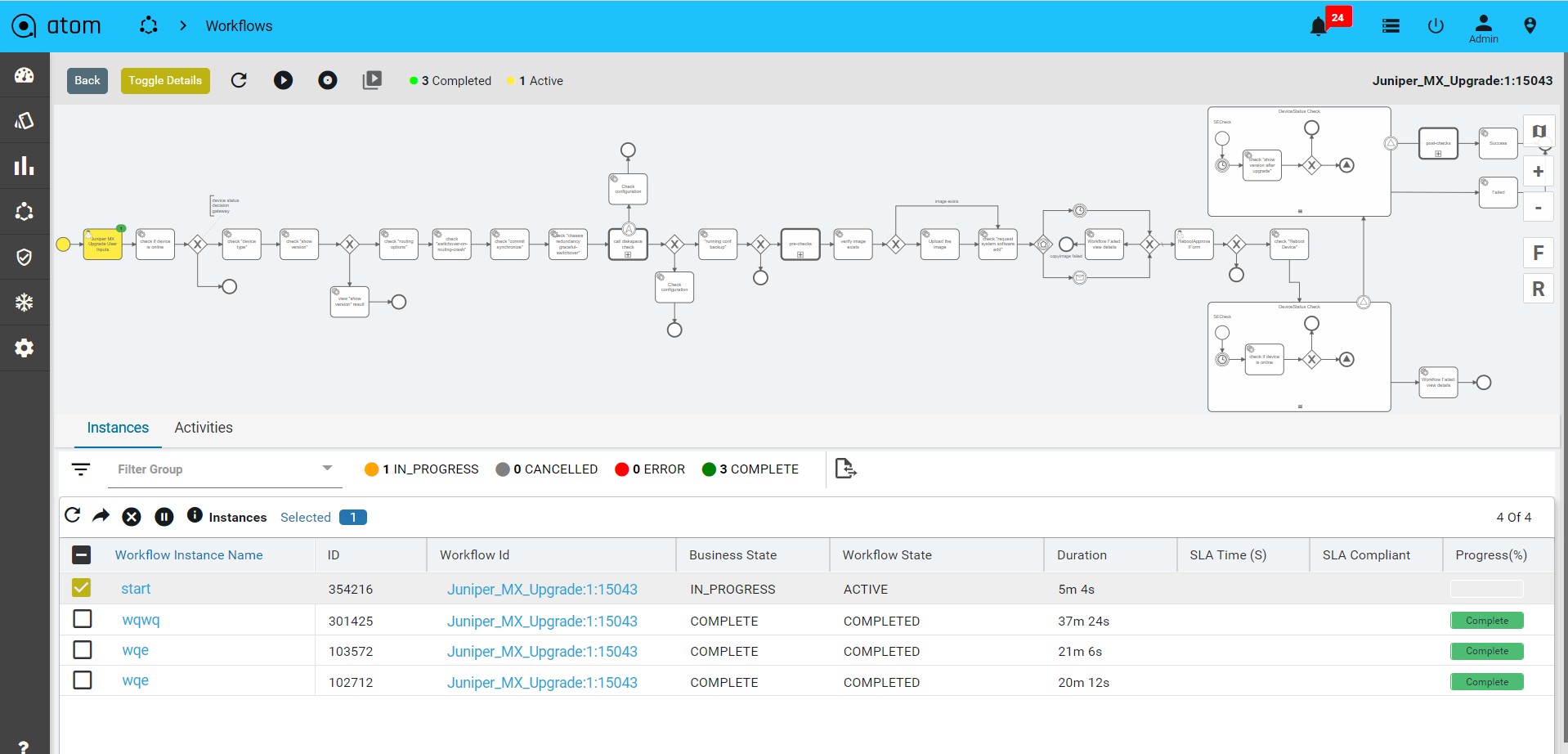
Workflow Instance Error:
Unresolved programmatic/syntactic errors of a process instance or a sub process instance are indicated by Atom workflow engine as errors. The Errors tab in the workflow instance view lists the failed activities with additional information.
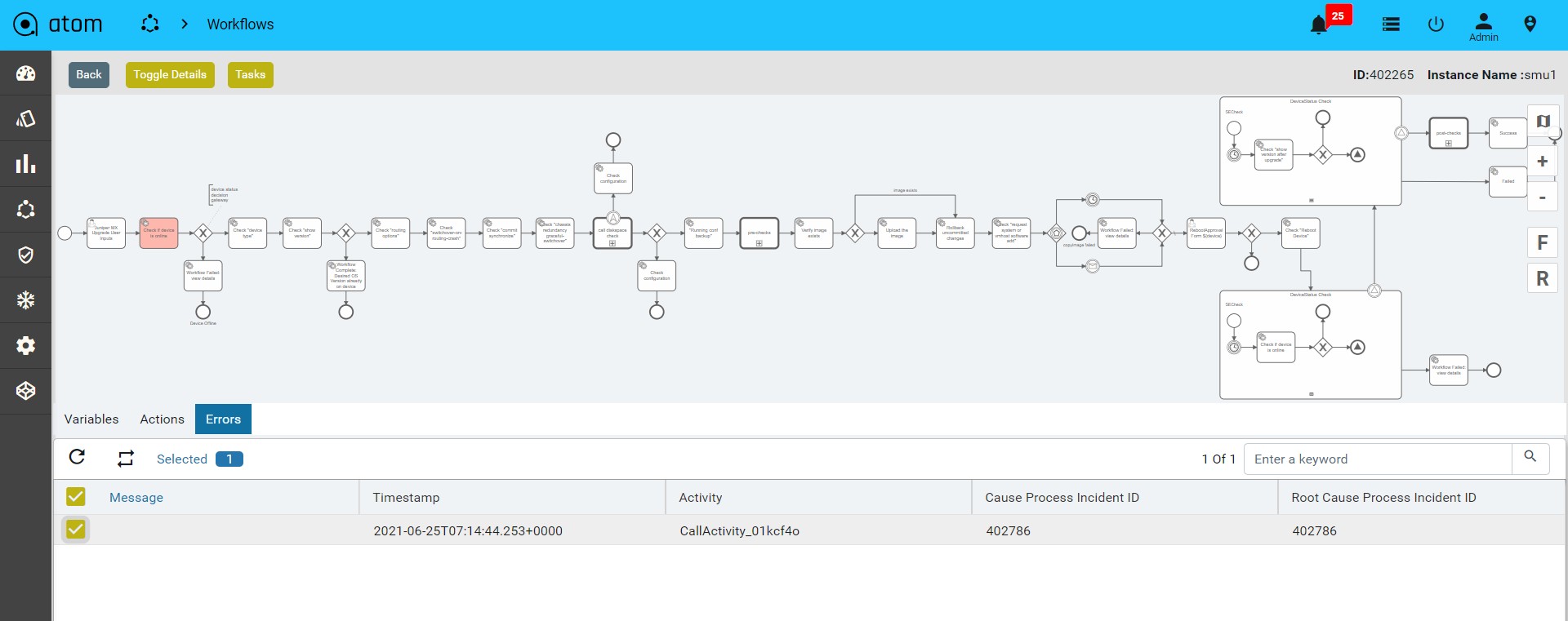
Retry a Failed Job
To resolve an error you can use the Retry button on the top panel. Select the corresponding instance, so the atom-engine will re-trigger this job and increment its retry value in the database.
Workflow Variables
Workflow Instance Variables can be used to add data to workflow runtime state. Various API methods/Service Tasks that change the state of these entities allow updating of the attached variables. In general, a variable consists of a name and a value. The name is used for identification across workflow constructs. For example, if one activity sets a variable named var, a follow-up activity can access it by using this name. The value of a variable is the value held by that particular named variable in the Atom engine for that particular workflow instance context.
To view the workflow variables
- Select the particular workflow instance that is active.
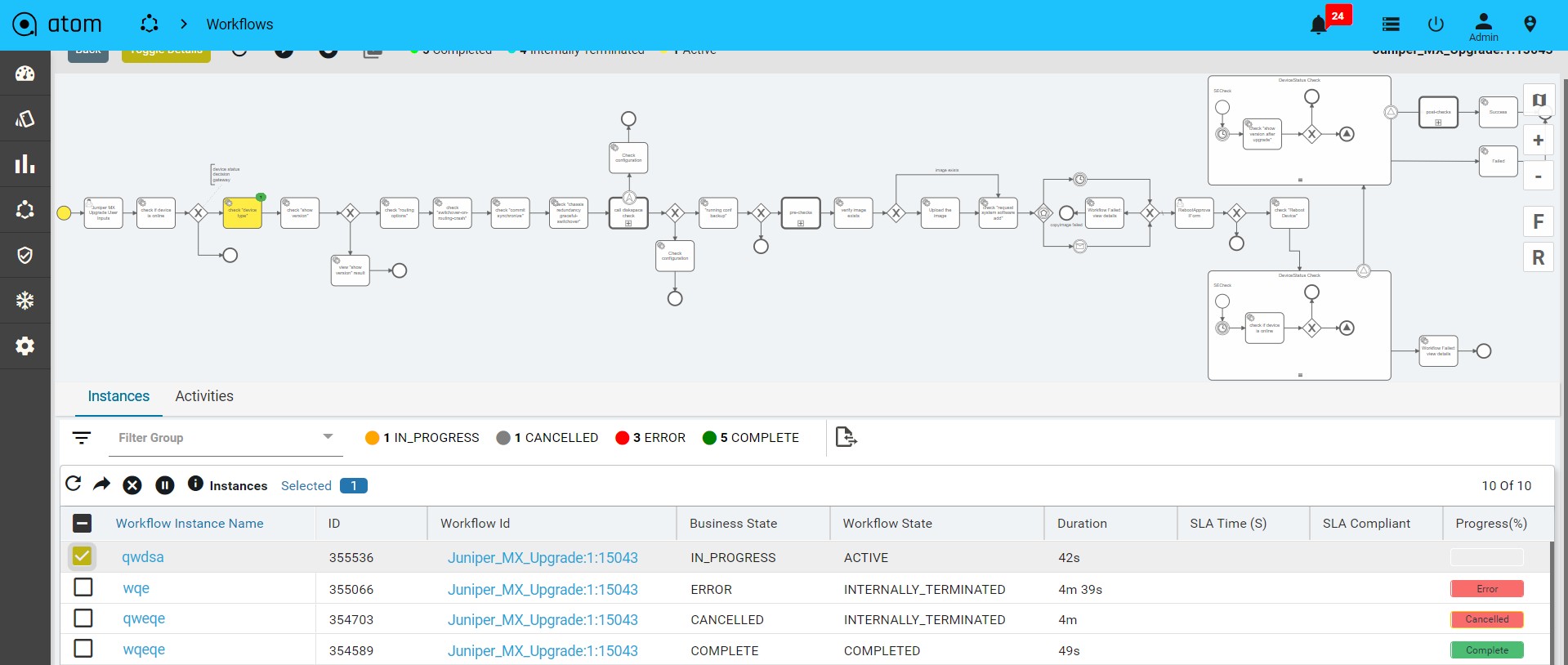
- View the workflow variables in the bottom panel.
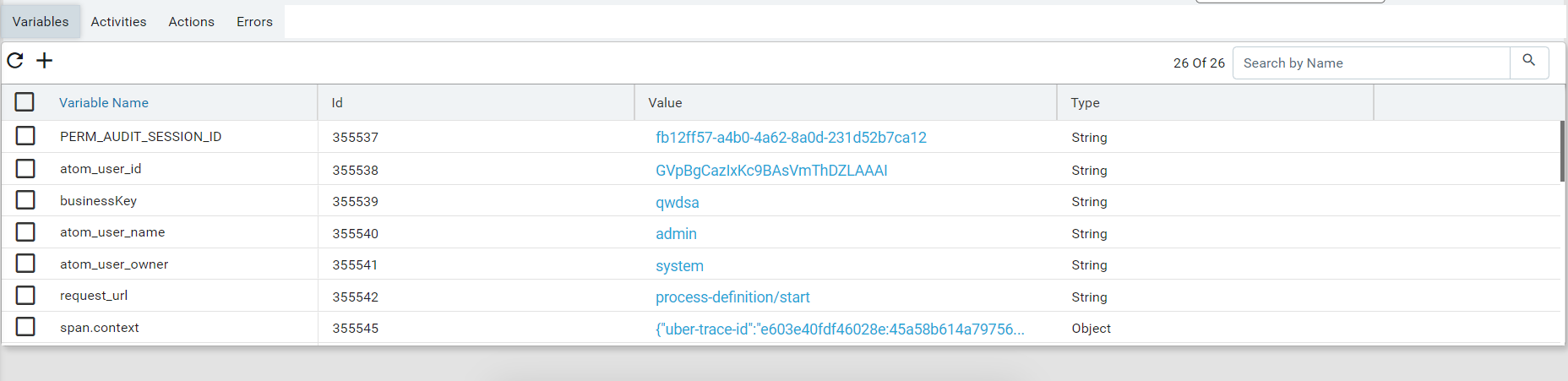
- Users can also edit the variable values during runtime.
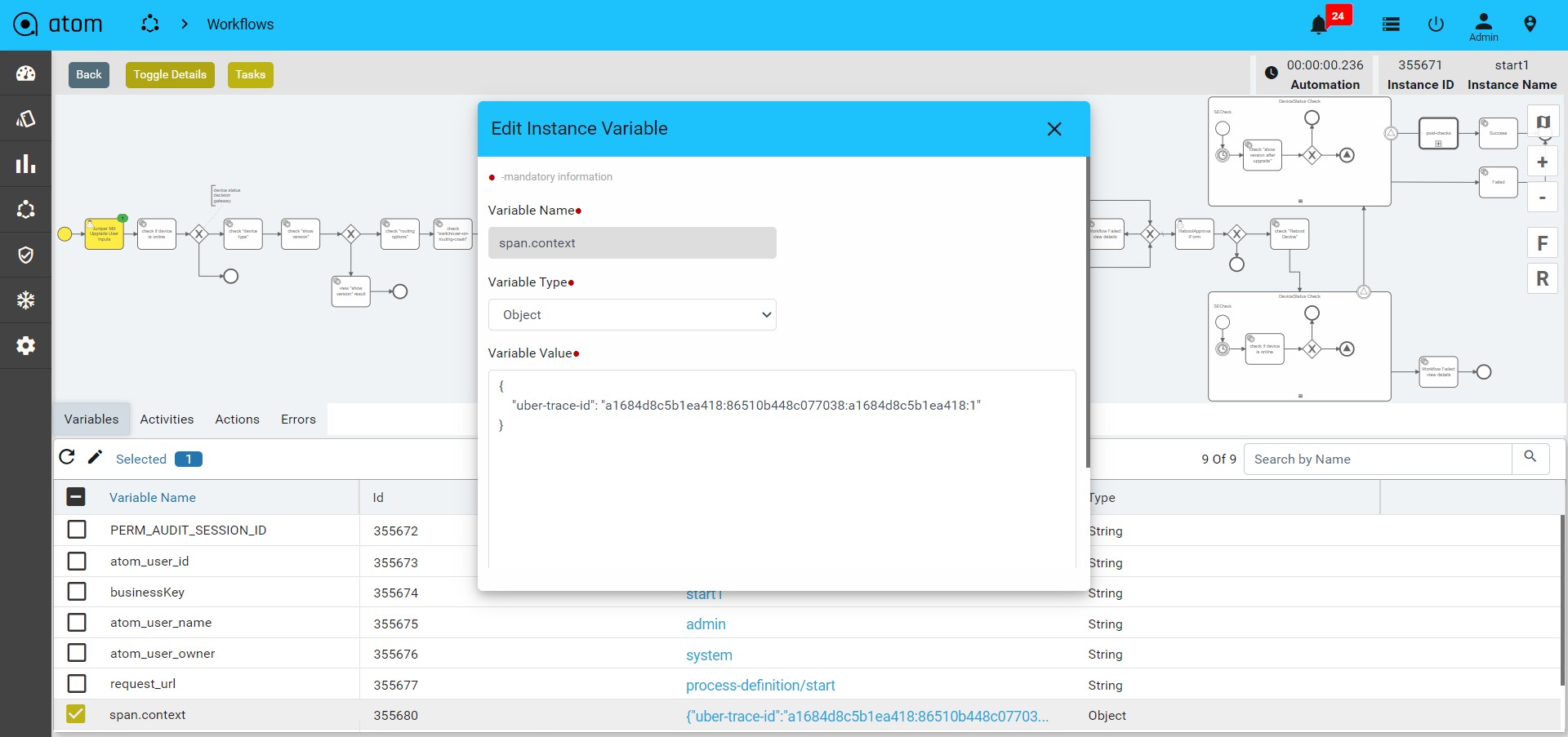
- Alternatively User can compare two variable values and see the difference on the screen.
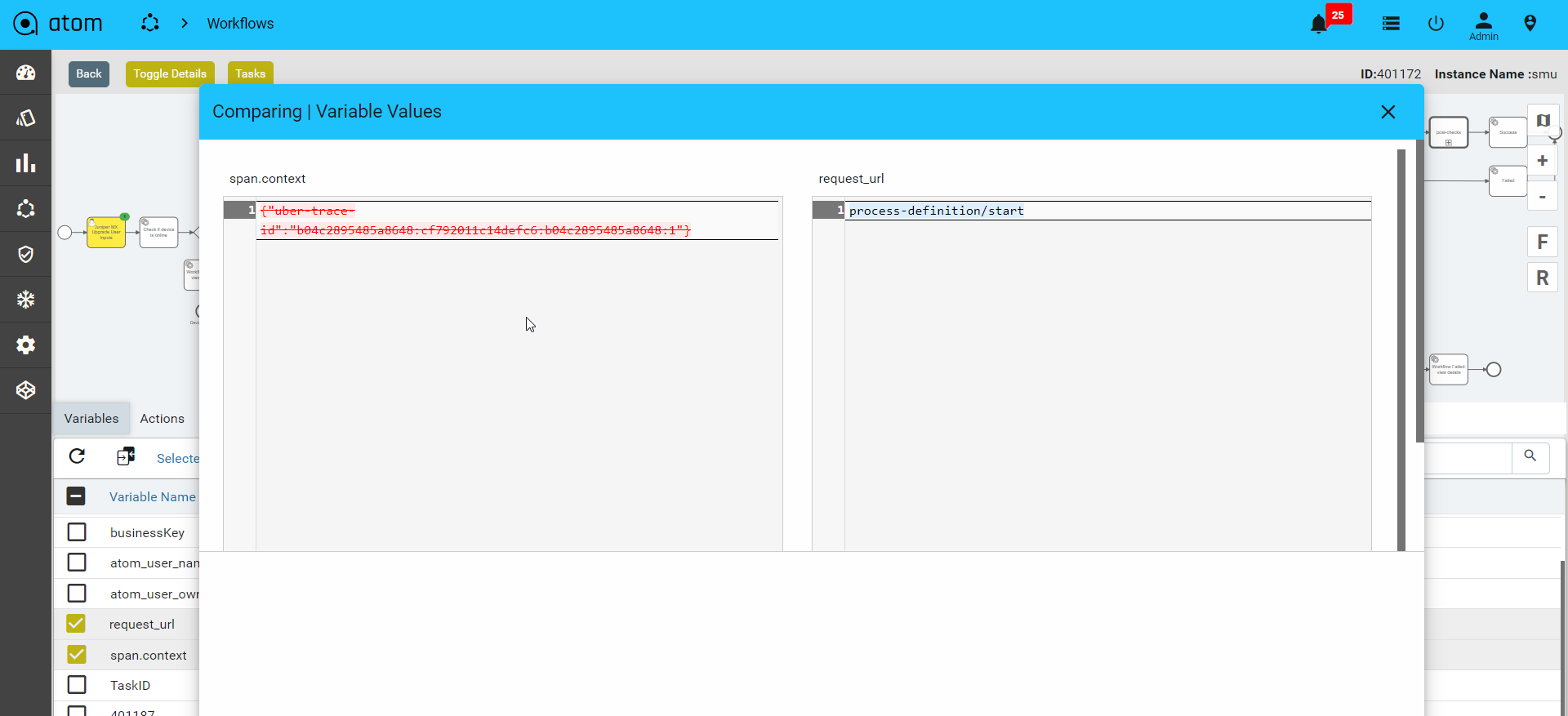
User Inputs:
Some workflows may require the administrator to enter some values at particular stages. Workflow execution will be stalled until the values are entered.
To view if any Action items are pending against a particular workflow instance we can view it under the specific workflow instance view :
For viewing such tasks:
- Select the particular workflow instance that is active.
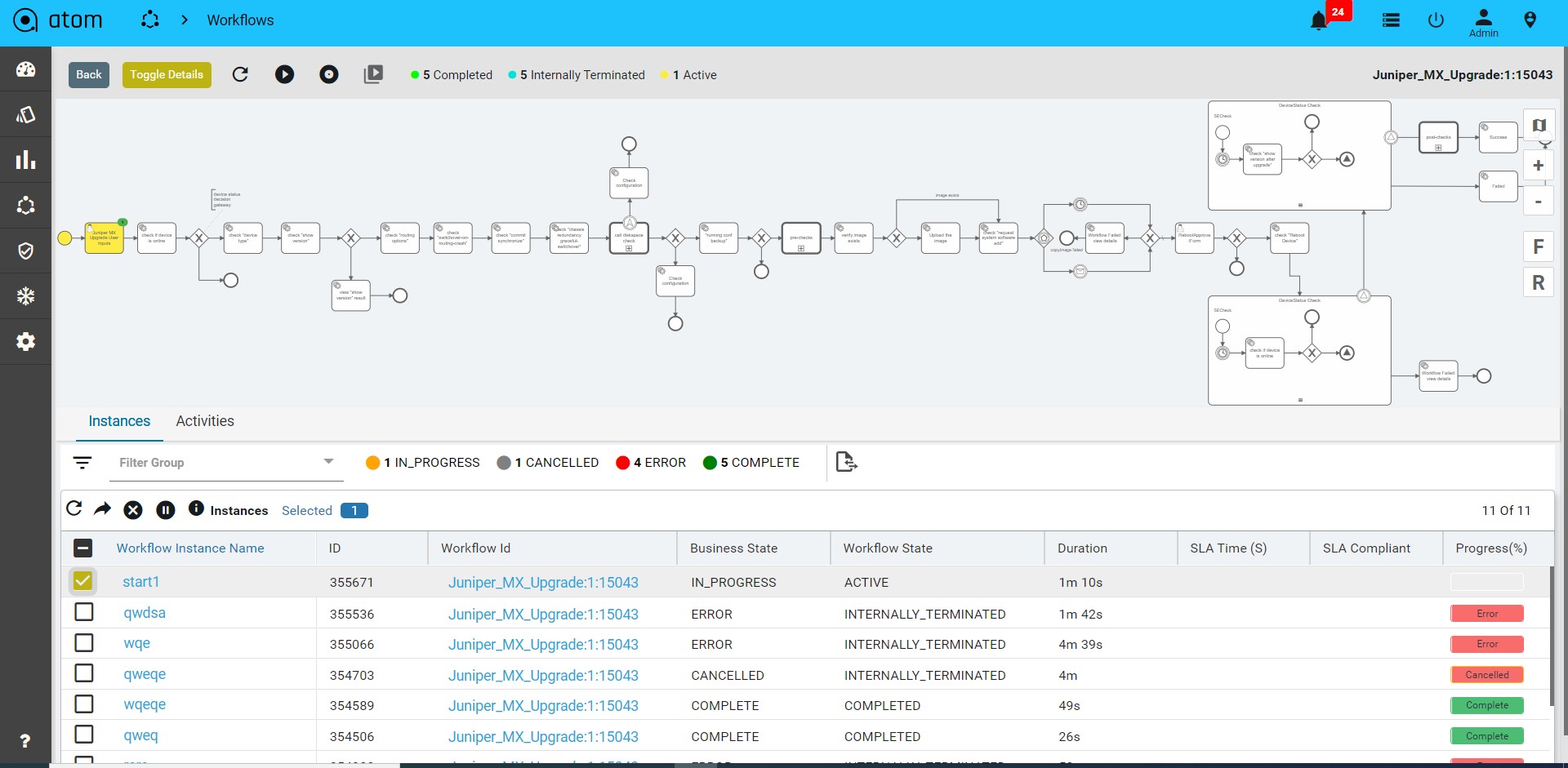
- Once Selected navigate to the action tabs to view all pending action items against this particular workflow instance.
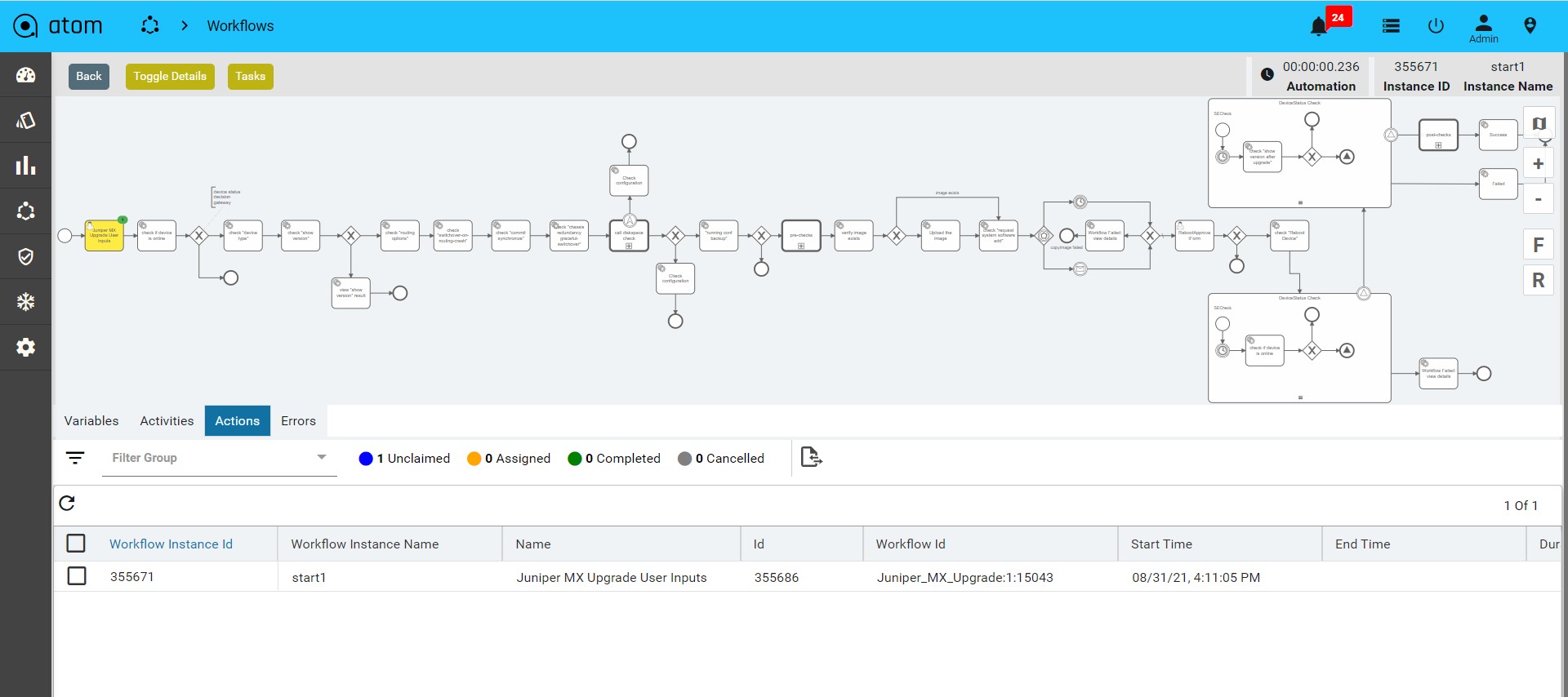
For completing such tasks
- Navigate to Workflows > Actions
- Select the workflow task and click on Claim to claim the task
- Navigate to Workflow > My Actions
- Select the task claimed at step 2 and click on Complete
- Enter values and click on the tick mark
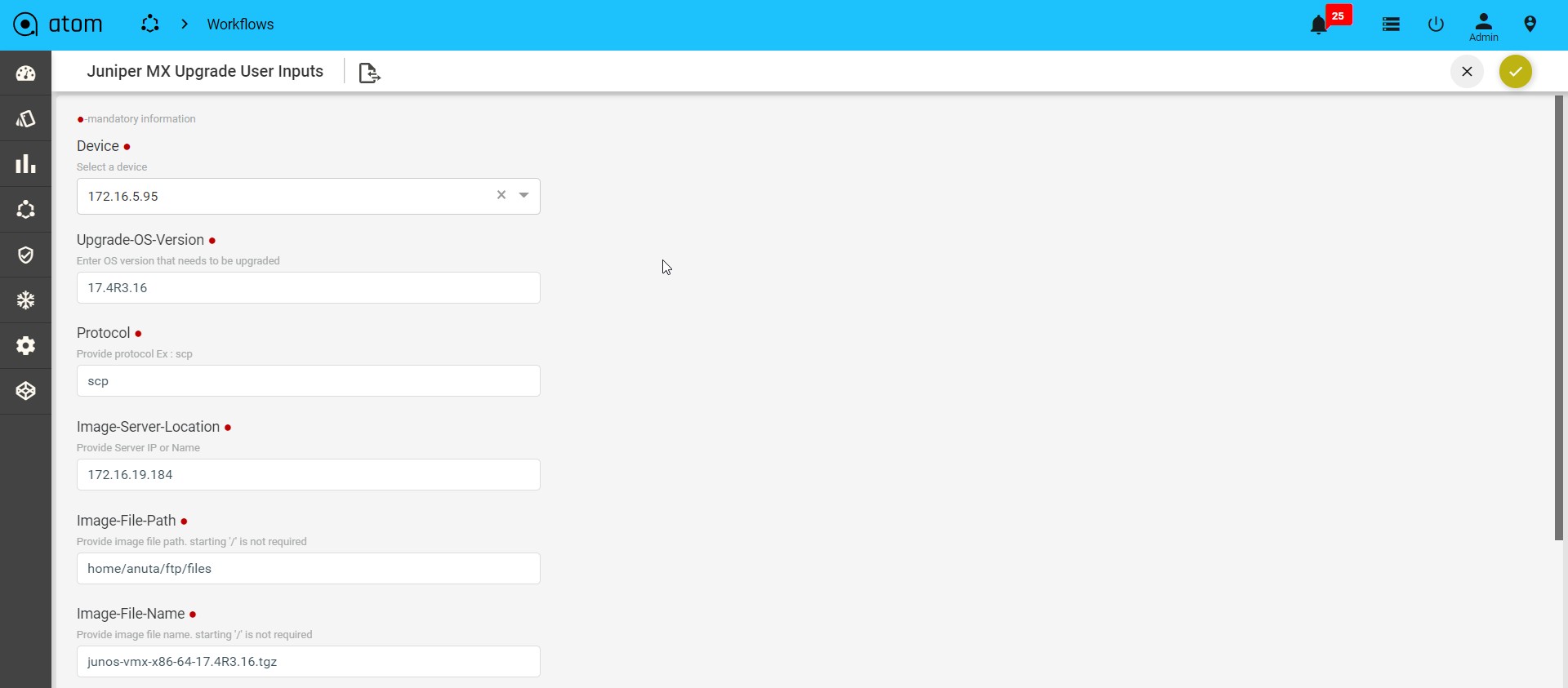
Network Service Automation
Stateful services are developed using ATOM SDK and involve Service model developed in YANG and optional business logic in Python. Such services have a continuous life cycle and undergo multiple changes over a period.
Services can be deployed in two modes –
Greenfield Mode – A user can instantiate the service, a set of network configurations, using the service template. These service templates are rendered from schema files that have been developed as a part of the Service package. ATOM automatically generates and applies relevant configurations on to the devices.
Brownfield Mode – ATOM automatically discovers services running on the device and maps it to the service template. For detailed information about service packages and how to write your own service models, and usage of “maps-to” extension, refer to the “ATOM Platform Guide”.
Ordering Greenfield Services in ATOM:
To order a service, that was modelled earlier, do the following:
- Navigate to Automation > Services
- In the right pane, click Add
- In the ensuing form, enter values for the fields that are displayed.
- Click OK
ATOM automatically generates relevant network configurations.
Note: If “Dry Run” is enabled in the Administration tab, the generated configurations will not be applied to the devices.
Let us take an example of creating an instance of the “L3 Services” in ATOM. The schematic representation of the service is defined in the .yang file (in this case, l3service.yang file). This file is contained in the model folder of the corresponding service package (l3 service package) uploaded as a plugin to ATOM.
- Navigate to Administration > Plugins & Extensions
- Navigate to Automation > Services > l3-services and click on Add
Deploying BSD services in ATOM:
Let us take an example of the deploying the “Application Profiles” service in Brownfield deployment mode:
- Obtain the appropriate service package from Anuta Networks
- Upload the service package into ATOM.
- Navigate to Administration > Deprecated > Services to view the uploaded service package.
- In the Add Application Profiles pane, select the Brownfield Mode as shown below:
- In the Create Application Services form, all the values discovered from the device are populated in the parameters shown below:
Enter values in the fields that have been marked mandatory.
- Click OK after selecting the requisite values in each of the fields.
The commands that are generated in ATOM are not pushed to the device because of the mode of Brownfield deployment.
Transactional control at the Service level
For every service, the admin can control whether the corresponding configurations, generated by ATOM, should be pushed to the device. This gives an admin a granular level of control wherein some services can be sent to the device and a few can be retained on ATOM.
- Navigate to Automation > Services
- Click the service that you want to configure the transaction policies.
- You can either enter the values of the fields or import the values from a template to fill the form.
- In the Create service template,click Transaction Policies > Transaction Policy Configs
screen to set the control at the transaction level as shown:
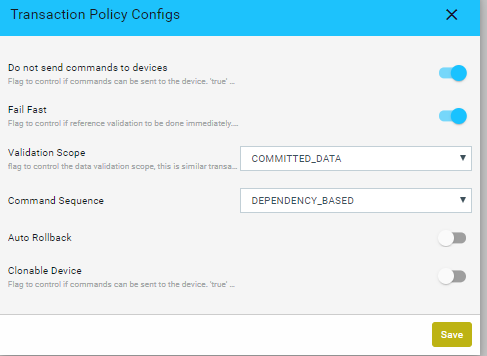
| Option | Type | Description |
| do-not- send-commands- to
–devices |
boolean | Controls whether commands can be sent to the device. devices
Select this option to commit the data to ATOM datastore, but no configuration changes will be applied on the device. Useful for testing or in the case of a brown-field environment to create services. Note: The value set for this option at the transaction policy overrides the value at the global level (in the General Settings) |
| fail-fast | boolean | Controls whether the reference validation should be done immediately.
False: Defers the validation to after ‘commit-task’ state of the transaction |
| validation-scope-type | enum | Controls whether data validation scope is across transactions. This flag is similar to |
|
isolation control in traditional RDBMS, but limited to just data validation.
Allowed values are “COMMITTED_DATA” and “UNCOMMITTED_DATA”. Validation will be done only using the committed data. Current transaction will not see changes done by other parallel transactions Data validation will be done using the uncommitted data. Current transaction will see changes done by other parallel transactions |
|
|
enum | Controls whether the generated commands need to be ordered according to the dependencies specified in the model.
Generated commands will be re-ordered based on the dependencies specified in the data model. Generated commands reflect the order of the requests sent from the client, no re-ordering is done |
The values for following options can be cross-verified before creation of each service
-
- Fail Fast
- Validation Scope
- Command Sequence Policy
- Click the task created for the created service to view the commands generated by ATOM in the Task Details.
In the Task details, click Commands to view the generated commands by ATOM. As the
commands should not be sent to the device, (if do-not-send-commands-to-device option is selected), the status of the commands is set to “TO_BE_PROVISIONED” as shown below:
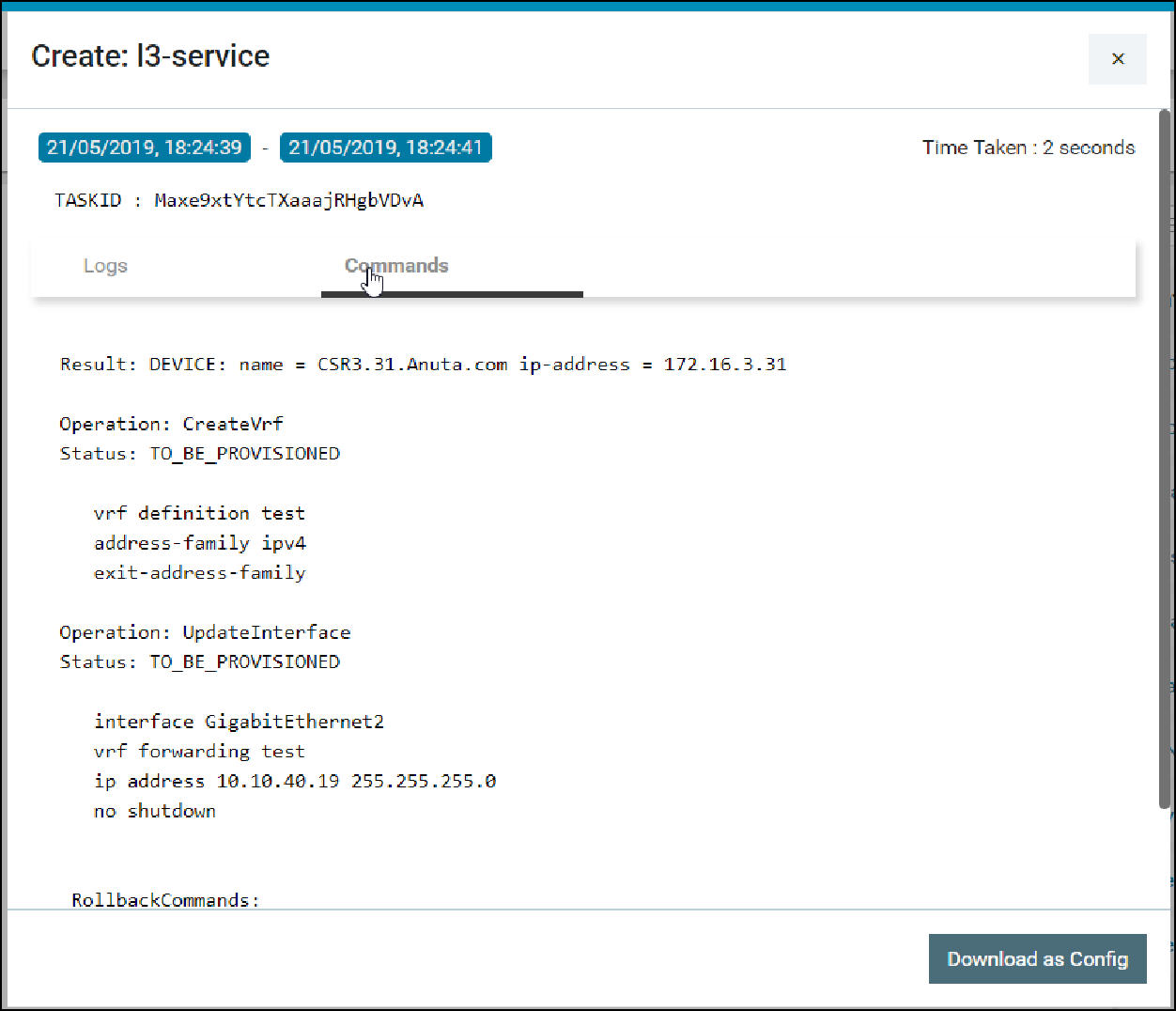
The generated commands can be downloaded and verified with the expected configurations for that service.
Cancelling an ordered Service:
- Select the service and click Delete.
- In the Confirmation window, before selecting the Yes button, click the Transaction Policies.
- Select the option , “Do-not-send-commands-to-devices” in the policy
In the corresponding task generated, in the Task Details pane, click Commands to view the generated commands by ATOM. As the commands should not be sent to the device (if “do not send commands to the device” option selected in the transaction policy config), the status of the command is set to “TO_BE_PROVISIONED”.
Service Approvals
You can create policies for approving creation, deletion or updation of the service configurations on devices. In addition, you can add approvers who must approve the operations defined in the service approval policy. Apart from seeking approvals for services, you can set approvers for any of the operations for any entity in ATOM.
- Navigate to Automation ->Services-> Approvals
- In the right pane, click Add Policy to create the details as shown below:
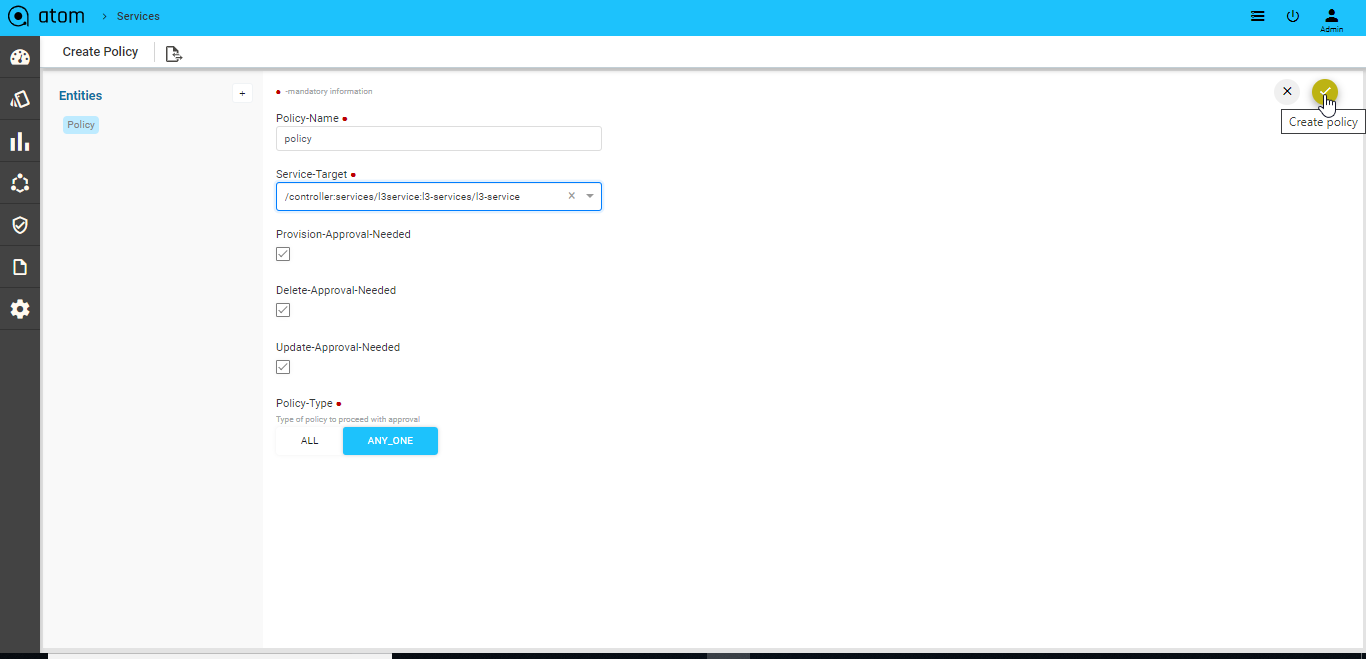
- Navigate to the right pane to add details as described below:
- Policy Name: Enter a name for the approval policy
- Service Target: Enter the path for the object in the data model tree for which approval is required.
For example: If the object of interest is a service, enter the path of the service.
/controller:services/l3service:l3-services, which means that the operation of interest on this managed-cpe -service will be sent to the approver or approvers for their perusal before being pushed to the device.
-
- Provision Approval Needed: Check this option if the user selected as the approver should approve the configurations before they are pushed to the respective device or devices.
- Delete Approval Needed: Check this option if the approver should approve the configurations that are required for deletion of the service configurations from the device or devices.
- Update Approval Needed: Check this option if the admin should approve the configurations that are required to update the service configurations on the device or devices.
- Policy Type: This option enables you to set if approvals are required from a single approver or multiple approvers.
- ALL: The task that is generated as a result of a service operation awaits the approval of all the approvers who have been added for that service .
In the following example, the operation of creating a ‘customer’ needs approval of two approvers, ‘admin’ and ‘User1’. The task is completed successfully after receiving the approval of all the approvers as shown below:
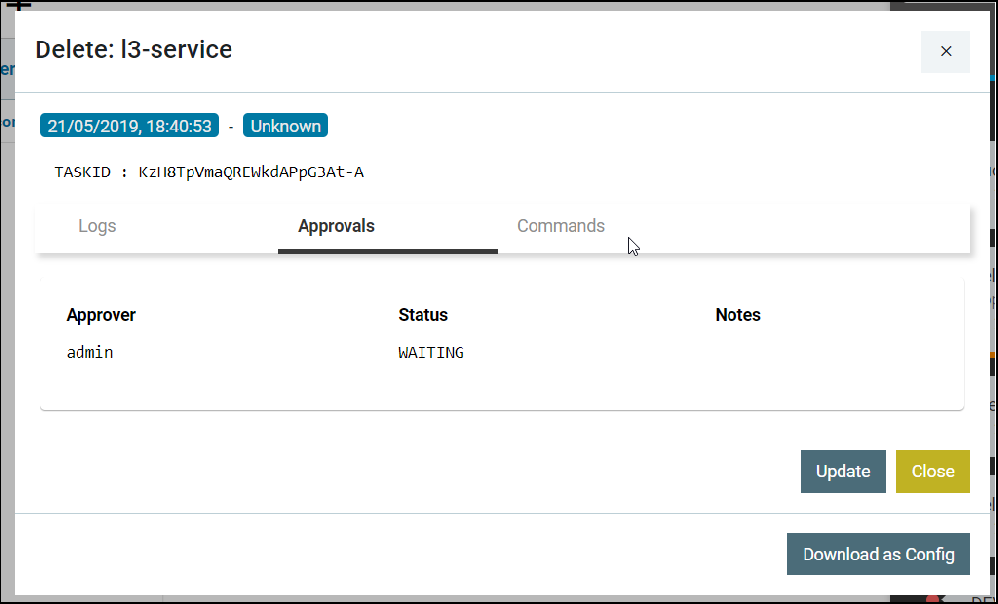
- ANY_ONE: The task generated as a result of a service operation awaits the approval of any of the multiple approvers added for that service.
- Navigate to the left pane to add the tenant users who should approve the configurations generated by ATOM for any of the service operations (create, delete or update ).
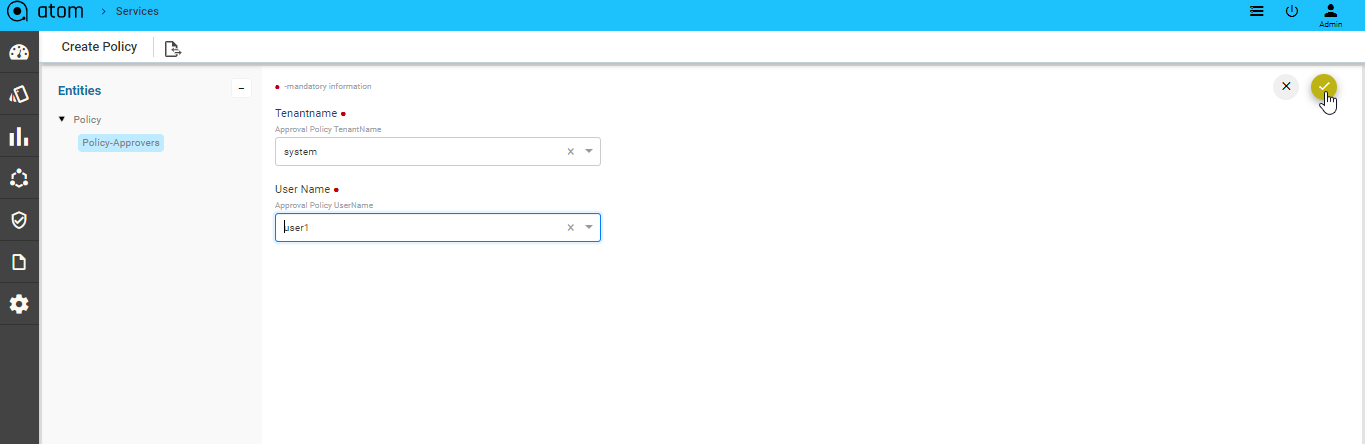
Configuration Drift (Network Services)
Whenever there is a configuration change in the device that does not match with the generated configuration on ATOM, a reconciliation task is generated in ATOM. After viewing the config diff generated, the administrator can decide how to reconcile these config differences so that the device and ATOM are always in sync with respect to the configuration states.
- Navigate to Automation->Services->Reconciliation in the left pane
- In the right pane, click Reconciliation > Entities to view all the reconciliation entities that are generated at the device level and service level.
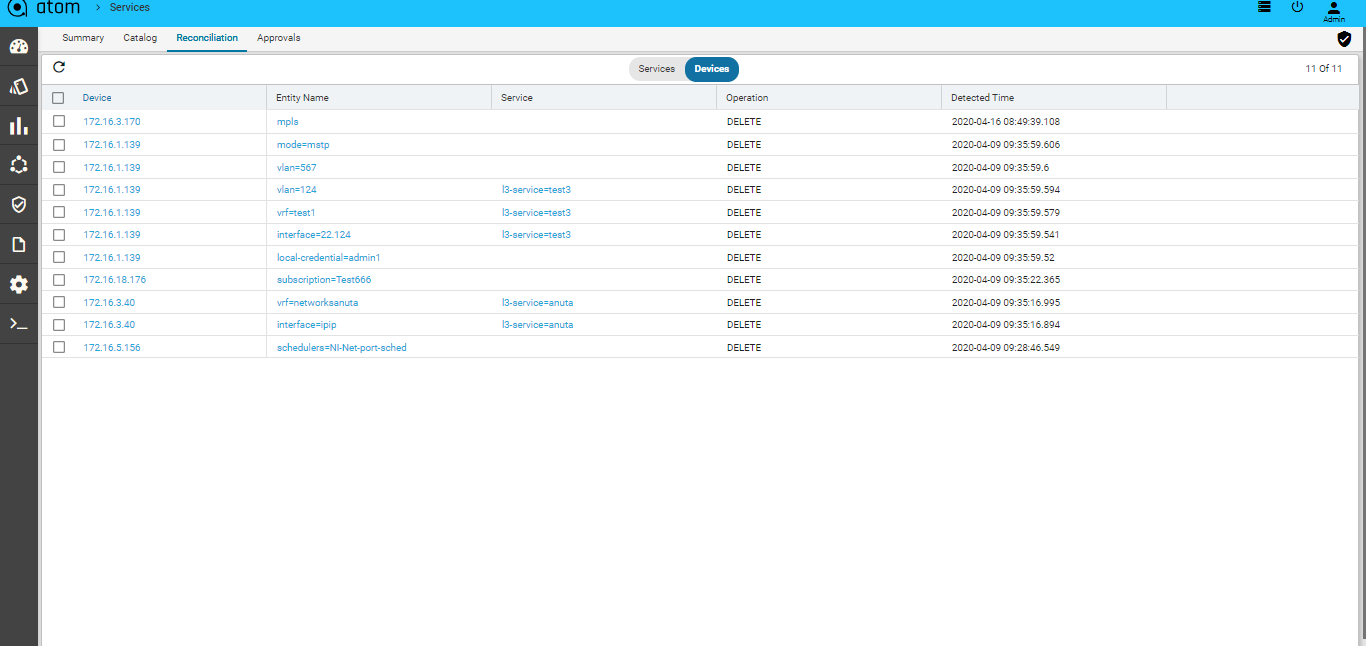
- Double click the reconciliation entity of your choice, to view the Reconciliation details:
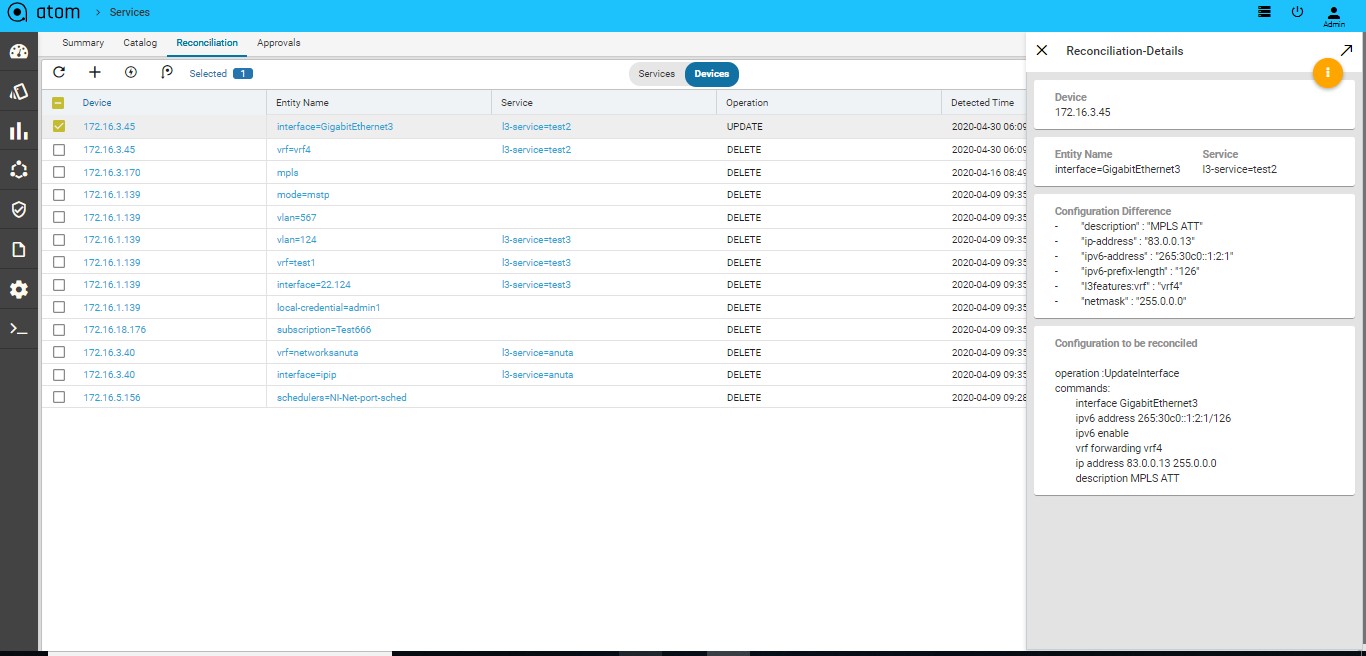
The configuration difference between ATOM and the device is shown on the left pane where as the right pane displays the configurations that should be pushed to the device to reconcile with the state of ATOM.
- Click the Reconciliation Policy to create the policies for reconciling the config differences either with the state of ATOM or with that of the device.
- OVERWRITE SERVER – The generated config diff is pushed to the database of ATOM to reconcile with the state of the device
- OVERWRITE DEVICE – The generated config diff is pushed to the device to reconcile with the state of ATOM.
- WAIT FOR APPROVAL – Select this option if the generated reconciliation entities require a review by an administrator. The generated config diff is sent to an approver who can take the decision of either pushing the configurations to the device or overwriting the ATOM database.
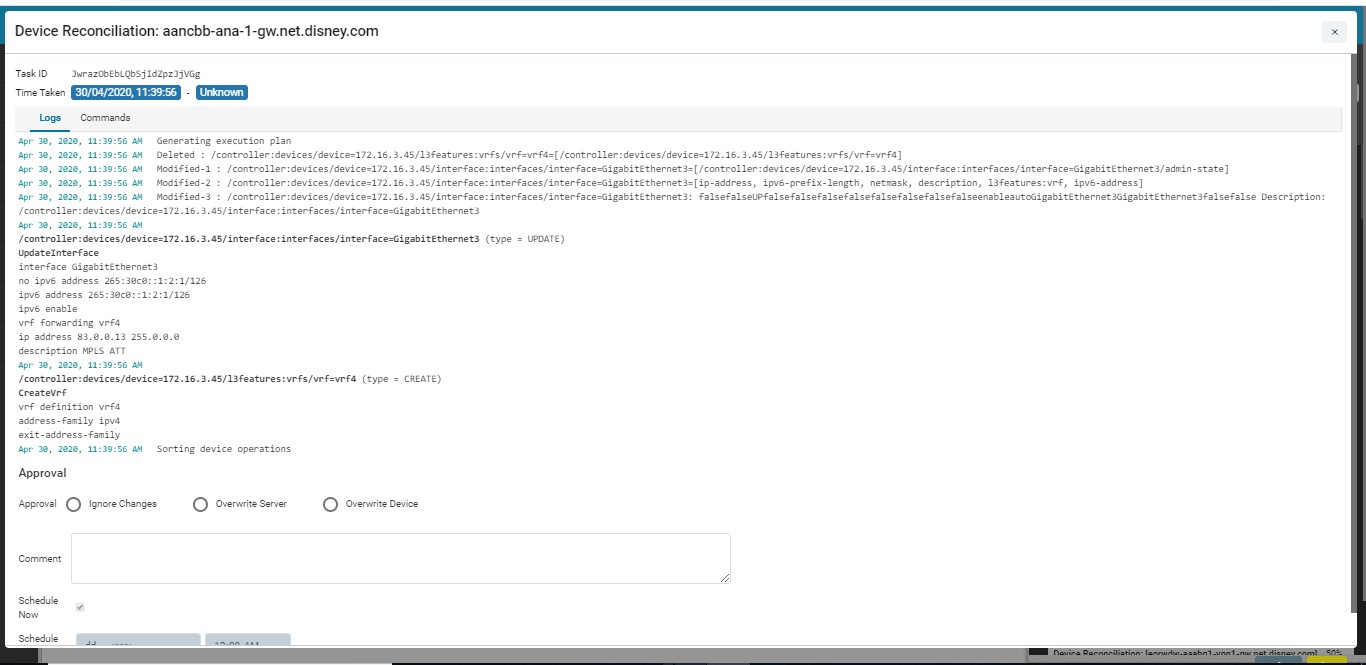
Setting the Global Policy :
The policy configured in this setting will have an impact on all the reconciliation entities generated for all devices.
Setting the Device Policy:
You can set granular control of what needs to be done with the config diff generated by ATOM for a specific device or a set of devices. The policy configured at the global level can be overridden by the device level.
For example, if the global level the policy is set is WAIT FOR APPROVAL but at the device level it is set to OVERWRITE DEVICE, all the reconciliation entities generated in ATOM for that device will be reconciled with the state of ATOM.
Example
Let us understand how service compliance and reconciliation work by taking the service, L3 service” as follows:
- Create a service instance in ATOM
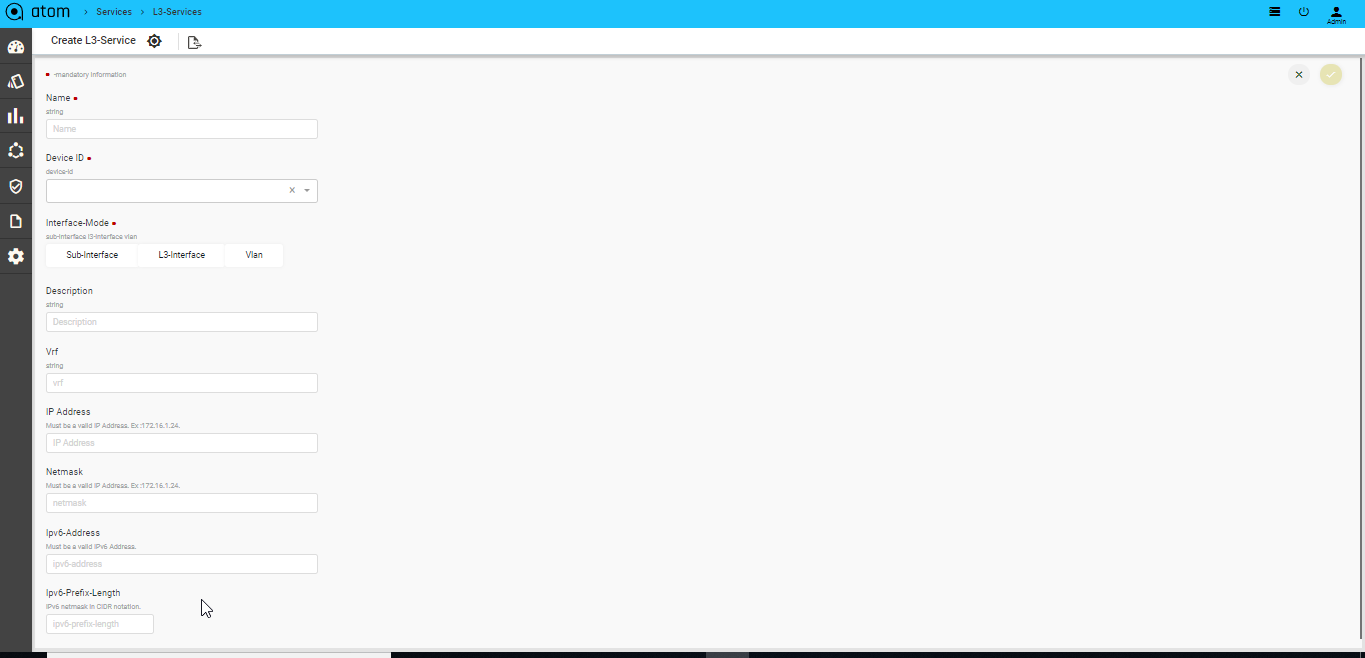
- Login to the device console and delete the “test VRF” from the device
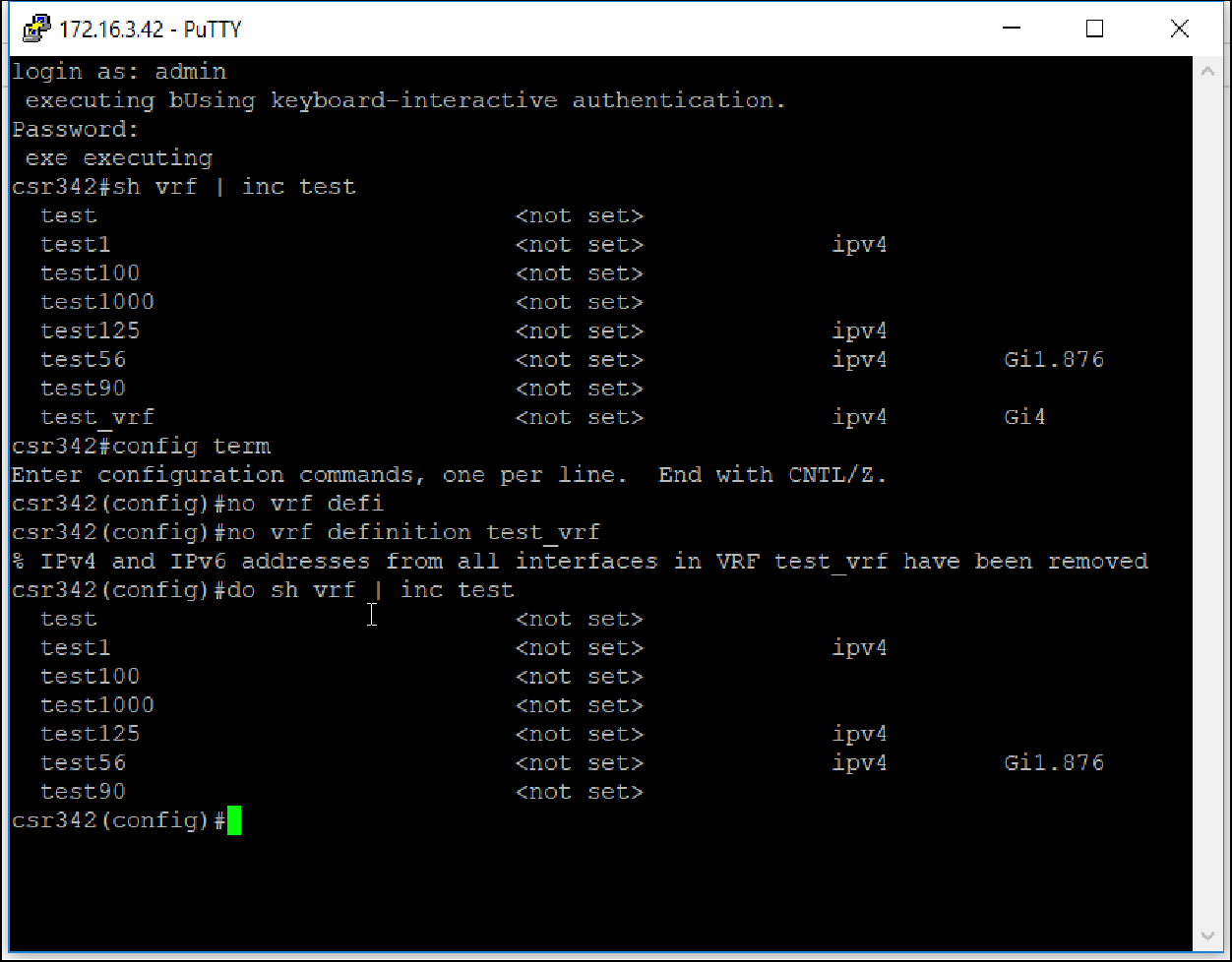
- As there is a config difference between the device and ATOM, a Reconciliation task is triggered in ATOM.
As the config change in the device is related to the created service in ATOM, a Service Inventory task is created.
The Service is marked as “Non Compliant” service as shown in the “Compliance” Dashboard.
You can either resolve the service violation or look at the Reconciliation entities created.
Service Compliance
ATOM helps to detect any configuration deviations in network at the service level. ATOM detects the missing, deleted, violated configurations of the services that have been instantiated in ATOM and sends the reconciliation report.
When a service is instantiated on a device, all the necessary configurations are generated by ATOM and pushed to the device. After the successful creation of the service on the device, ATOM compares the running configuration on the device, compares this with the services that were generated , flags the violations and marks the service as non-compliant.
If there is any service that is non-compliant, navigate to Automation –> Services->Reconciliation->Services
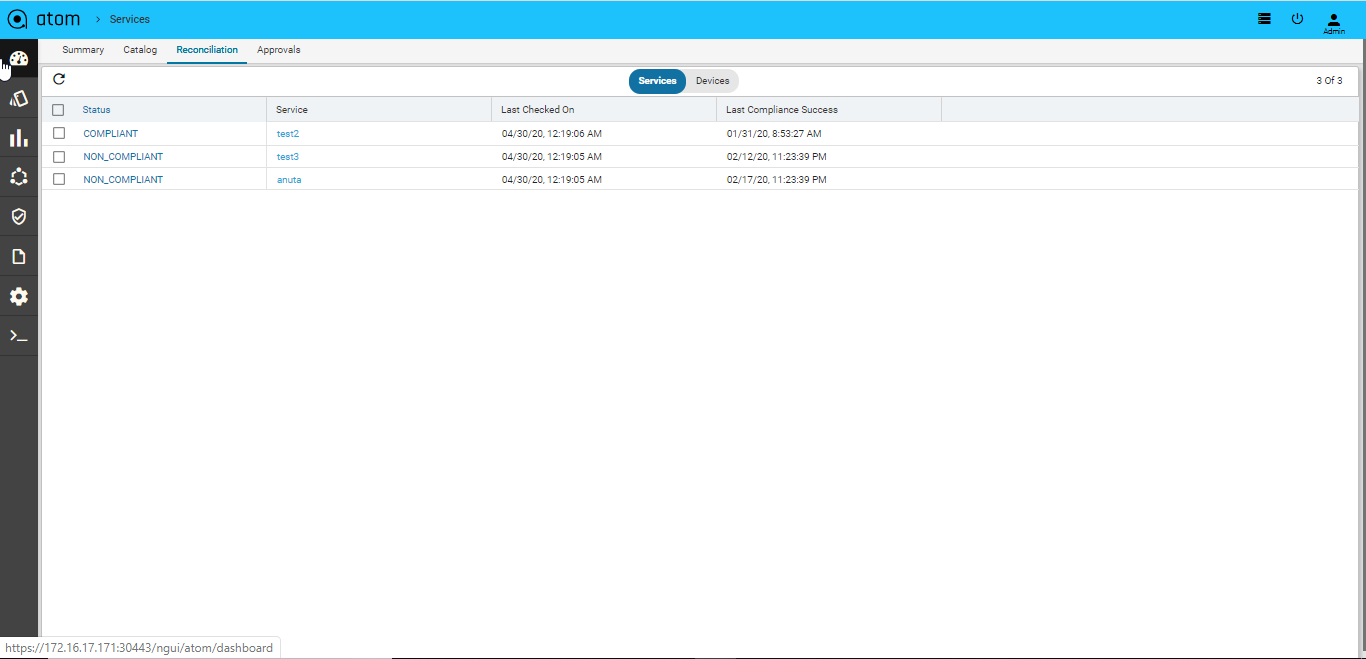
Click Non Compliant Services to view those services
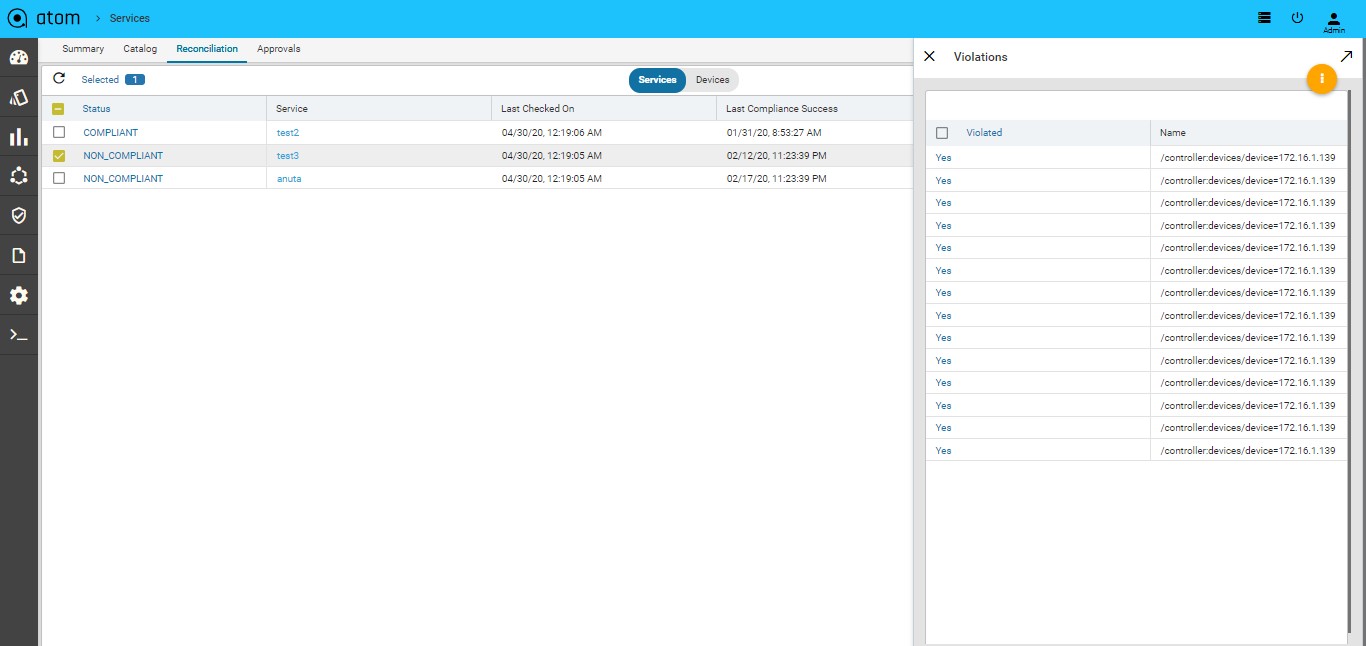
Resolving Service Violations
ATOM generates the config diff, in the service created through ATOM. and pushes the deleted configurations (that were either removed intentionally or accidentally) to the device, thus enabling the administrator to maintain the same state of configuration in both.
- Select Non Compliant Services > Click Resolve Violations
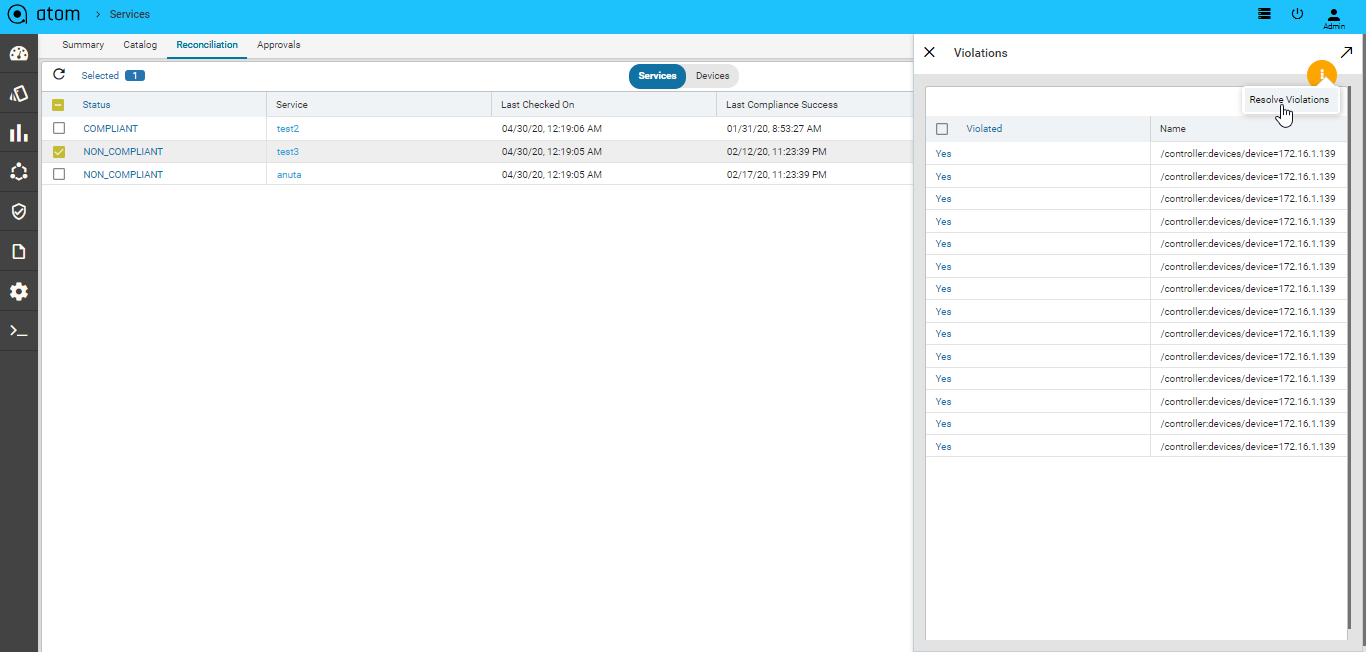
- Click the Task Viewer and look for the task named “RPC Operation: Compliance:fix-service-violations”
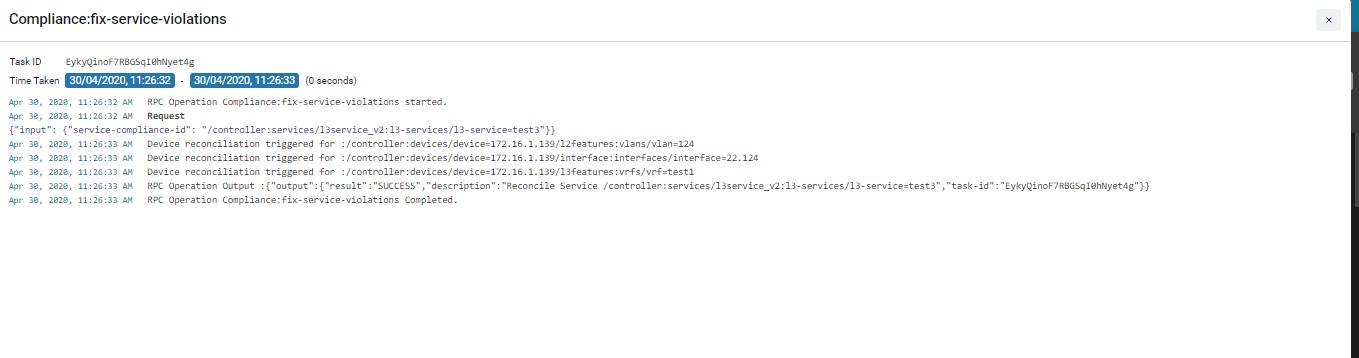
Agents
ATOM Agent handles all device communication which communicates with Other ATOM Components either remotely or locally based on deployment mode.
Each ATOM Agent manages multiple network devices. ATOM agents can be assigned with multiple CIDR blocks to manage the devices. It is used to communicate, collect and monitor the networking devices in your infrastructure using standard protocols. Once the agent collects the data, it gets encrypted and sent to Anuta ATOM Server over an outgoing SSL Connection.
One Agent can typically manage hundreds of devices. However, it depends on many other factors such as device type, data collection, size of the data, frequency etc. Checkout ATOM Agent Hardware requirements for further information.
ATOM Agent Deployment is discussed in detail in “ATOM Agent Deployment Guide”.
Administration
As an administrator, you can manage changes in the ATOM that will affect the behavior of the system and have a global effect on all the components of ATOM.
- “Tasks“ and “Events”
- “Tenants”
- “System“
- “System Manager”
- “Plugins and Extensions”
- “User Management“
- “Tag management”
- “UI Customizations”
- “Troubleshoot”
- “DSL”
- “Deprecated”
- “File Server”
- “About”
Tasks & Events
You can view any activity, “task”that is being executed in ATOM as a result of an user- initiated
action. Tasks are generated during the following operations such as:
- Adding or Deleting Devices
- Executing Jobs
- Validating the resource pool and running the Inventory
- Configuration out -of -sync between the device and ATOM
- Creating or Deleting Networks
- Select any Task and click Details to view the configurations associated with that task.
- You can search for any Task by entering a query in the Search field.
- Select any task and click Cancel to view the task is to be cancelled
- Select any task and click Download Log to view the system related logs and message.
For example, enter “Create” in the Search field, if you want to query for all the Create operations that have been executed so far. All the Create tasks that have been triggered in various operations are displayed as shown below:
- Click Retry when the creation of a Service (during instantiation of the Service) fails due to deficit in the operational resources or during provisioning. 4. Click Task log to view the system related logs and messages
Events
Events represent an important part of an operation or a change in the state of an object in ATOM. For example, an event is generated when a user logins to ATOM. In addition, login attempts to a device using any of the transport types is also displayed.
Select a task and click Details to view the schema of the service, click Commands to view the configurations associated with the service generated by ATOM.
TraceLogs
Trace Logs enables users to end-to-end distributed tracing of a task.User can monitor the performance of the task and latency optimisation can be done. It actually helps users to encounter the root cause analysis. The Tracelog option was enabled in tasks UI and also in tasks and events.
Select any task and click Trace Logs to view the task in distributed tracing.
Trace logs UI can be visualized from jaeger UI, this shows a complete cycle of the task and all the components involved in it.
To Enable TraceLogs Navigate to Administration > User Management > Users
Here select a User and Entities > DLS-Config
- Disable-Tracing: Set true to disable tracing for the user.
- Logging-Validity: Validity of the limited-time logging in seconds.
- Module-Scope: List of the modules that are supported for tracing.
Any: Enables any of the modules selected.
Selected: Enables only selected modules to tracelogs.
Disabled: Selected Module will disabled while tracing.
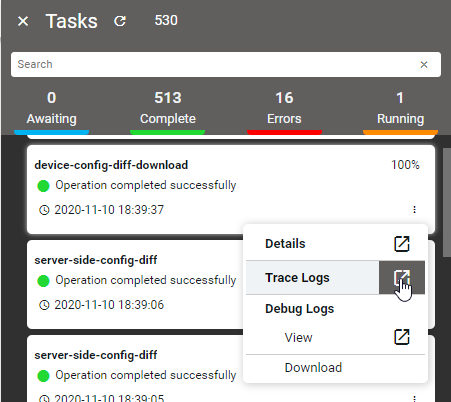
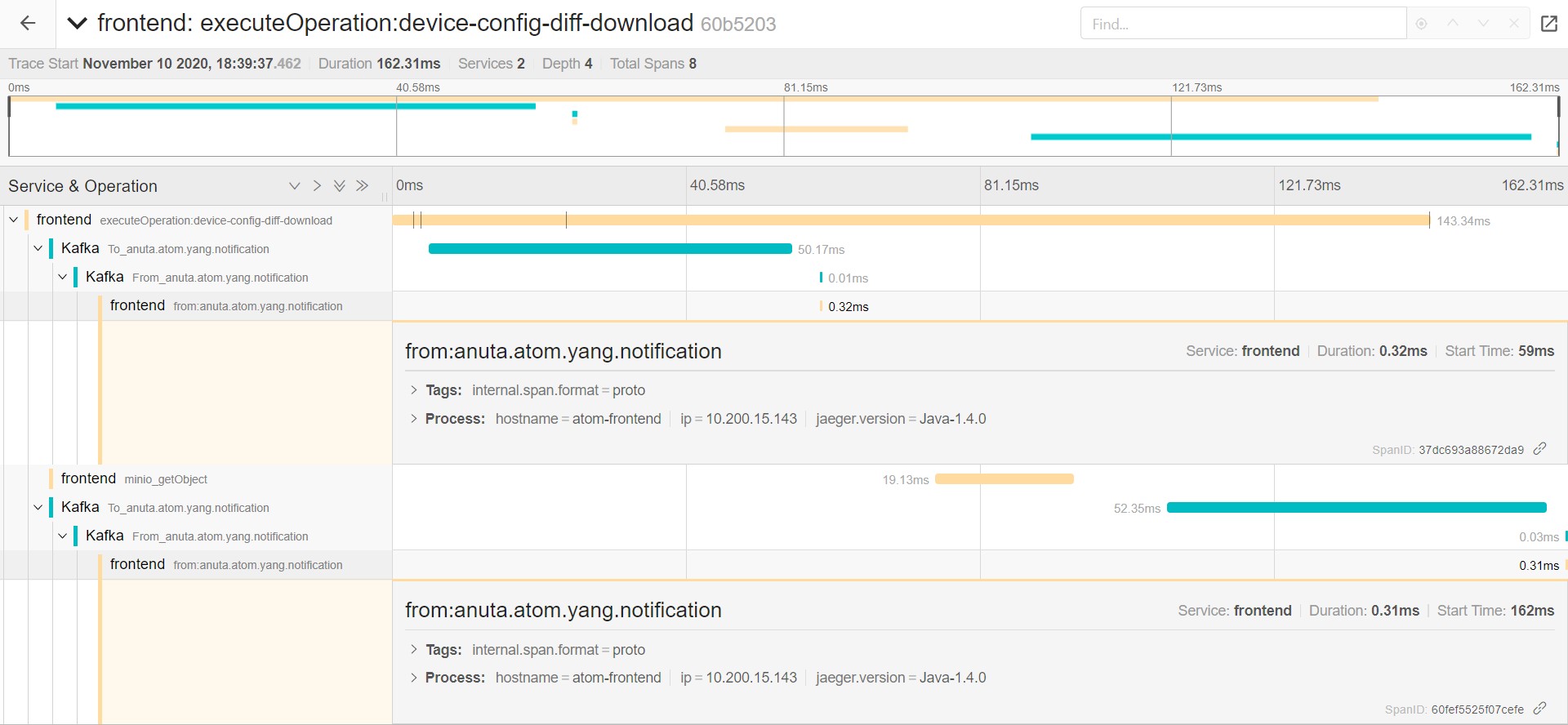
System
As an administrator, you may want to configure or modify the system settings or customize these settings after installing ATOM.
- “Rule Engine“
- “License“
- “General Settings“
- “Look and Feel“
- “Event Summary“
- “Notifications“
- “Message Brokers“
Rule Engine
Rule engine is a functionality in which the user-defined business logic is executed to bring about changes in the state of the resources managed by ATOM. The logic describes the sequence of operations that is associated with data in a database to carry out the rule. You can create rules in the Rule engine for ATOM to handle changes in devices in a maintainable, reusable, extensible way. Rule engines support rules, conditions, priority (based on index), and other functions. Rules can be constructed to serve various functions, some of which are listed below:
- Resources Validation
- Triggering different actions based on some user defined conditions
All the system defined rules available in ATOM as shown in the following snippet:
Click on any rule > Entities of your interest and view the Actions and Conditions associated with that rule.
For example, double click the ‘agent-down-alarm’ rule as shown below:
This rule comes to effect when any of the ATOM Agents goes OFFLINE and the status is set to INACTIVE.


Rule
In addition to the rules that are available by default, you can create a custom rule as per your requirement as described in the following section.
Rules are conditional statements that govern the conduct of business processes. A rule consists of a condition and a set of actions. If that condition is met, and is evaluated as true then the rule engine initiates one or more actions.
A rule is composed of three parts:
- Condition – The condition part is a logical test that, if satisfied or evaluates to true, causes the action to be carried out
- Action – The action part consists of one or more actions that need to be performed when the condition is met.
- Event – The event part specifies the signal that triggers the invocation of the rule. Create Rule:
- Navigate to Administration > System > Rule Engine > Rules
- Click Add Rule and fill the following fields:
- Name: Enter a string that will be used to identify the rule.
- Rule Type: Select the category that the rule should belong to. There are two types of categories available now:
- UNCATEGORIZED
- COMPLIANCE
- Enable: Select this option if the rule should be enabled.
- Rule Context: Enter the context in which the rule has to be triggered:
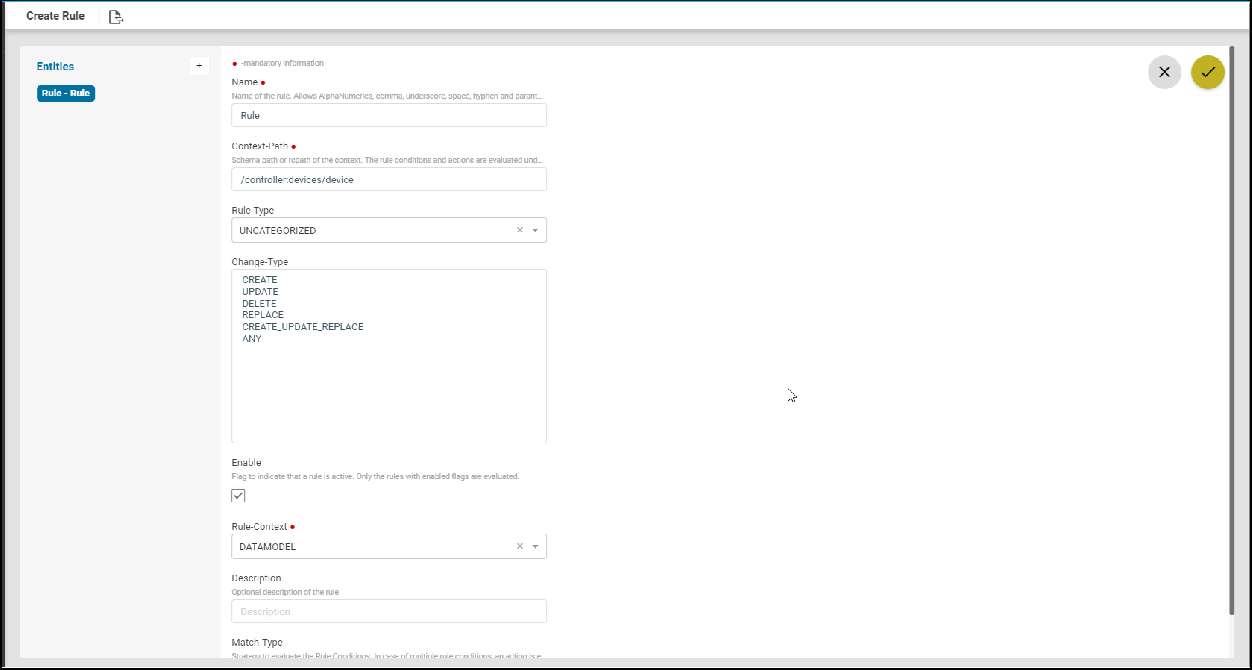
-
-
- DATAMODEL: Select this option if the rule should be triggered on a ATOM managed entity.
- Context path: Example: For this rule to be applicable on the devices, enter the context path as /controller:devices
- EVENT: Select this option if the rule should be triggered in the case of an event generated in ATOM.
- DATAMODEL: Select this option if the rule should be triggered on a ATOM managed entity.
-
- Event Spec: Select from the available event specs in ATOM:
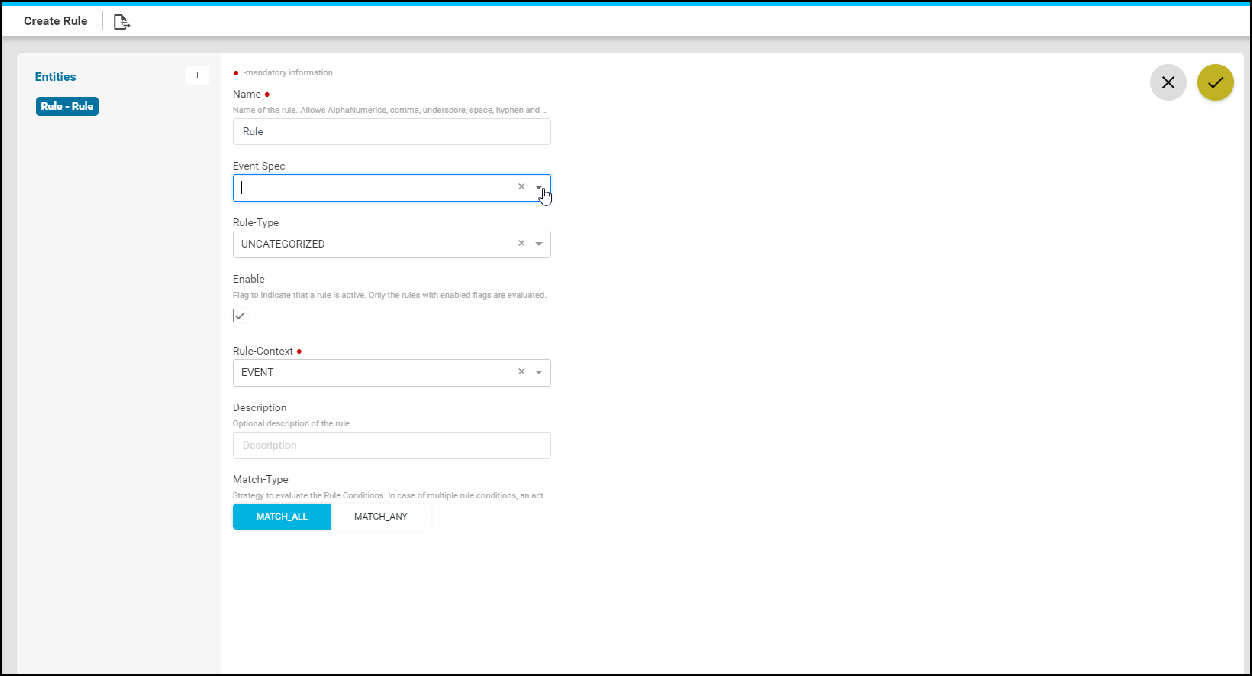
-
- Description: Enter descriptive text for the rule
- Change type The rule engine will check for the conditions defined in the rule when one of the following scenarios listed below:
Change -Type Description
-
-
- CREATE A component is created in ATOM
- UPDATE A component is updated in ATOM
- DELETE A component is deleted from ATOM
-
- Match-Type The conditions can be evaluated on an ANY or ALL basis.
Match-All: . All the conditions will be matched before executing the action.
- Match-Any: Any condition of the condition-set will be matched before executing the action.
Create conditions?
Conditions are statements that should be qualified by the system before subsequent actions can take place. In other words, conditions are what the rule is looking for to trigger an action.
- Navigate to Administration > System > Rule Engine > Add Rule
- In the Create Rule > Select Entity > click on + > conditions >click on + > rule-condition
- In the right pane, enter values in the following fields:
- Index: Enter a unique number as an identifier
-
- Condition-Expression: Enter an expression that should be checked by the rule engine for the condition to be true.
Example: To check for a condition when the device is ONLINE, enter an expression: /controller:devices/device/status == ‘ONLINE’
-
- Description: Enter some text describing the condition.
Create actions?
Actions are operations that will be performed on the entities managed by ATOM once that the condition is evaluated as true by the Rule Engine.
- Navigate to Administration > System > Rule Engine > Add Rule
- In the Create Rule > Select Entity > click on + > Actions
- In the right pane, enter values in the following fields:
- Index: Enter a unique number that will be used as an identifier and also setting the priority
- Type: Select the type of the component that should be acted upon, once the set condition is true.
- Description: Enter a description for the rule-action
- Event-Name: Select the appropriate event-name from the drop-down menu
Licensing & Entitlements
Usage limits in ATOM are enforced through a license file issued by Anuta Networks.
ATOM in Dedicated Mode
License File can be applied at System Level or at Each Tenant. This is applicable to ATOM Cloud Customers using a Silo/Dedicated Instance or an On-Premises instance. Following are the Admin & Tenant privileges:
- Anuta Networks will issue the License
- For On-Premises Deployment – Customer will apply the License
- For ATOM Cloud Deployment – ATOM Cloud Administrator will apply the License
- System Admin will have full access (View, Apply & Usage) to System and Tenant License Files
- Tenant Admin/User will be able to view Available licenses and Usage for Tenant they are assigned to
ATOM in Multi-Tenant or Shared Mode
This is applicable only in ATOM Cloud Following are the Admin & Tenant privileges:
- Anuta Networks will issue the License
- Anuta Cloud Administrator will issue & Apply the License for each Tenant
- System Admin will have full (View, Apply & Usage) access to System and Tenant License Files
- Tenant Admin/User will be able to view Available licenses and Usage for Tenant they are assigned to
Uploading a License
We can upload the license using the upload button. Multiple license files can be uploaded to ATOM. Usage limits are cumulative of all License Files.
License Summary
To view the License Summary & Details – Navigate to Administration > License
License Summary will show the overall summary across all the License Files.

Total Usage(C1): C1 Category Licenses Used vs Allowed
Total Usage(C2): C2 Category Licenses Used vs Allowed
Total Usage(C3): C3 Category Licenses Used vs Allowed
Total Usage(C4): C4 Category Licenses Used vs Allowed
Active licenses: Number of licenses which are active will be shown under active licenses
Expiry date: Farthest expiry date among all the License Files
Below the License Summary, all available License File details are shown as below:
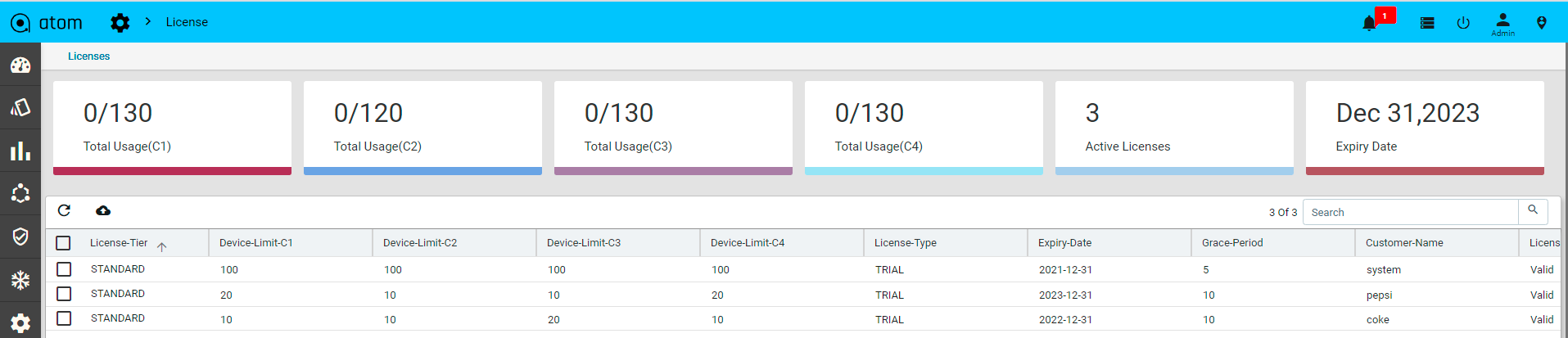
Tenant admin license
General Settings
You can edit and save the change the configuration parameters for each module in ATOM and these global changes are applicable to all the resources contained in each module.
- Go to Administration > System > General Settings
- In the General Settings panel, you can review the default settings of the following options and modify them.
- Click Edit to modify the parameters arranged for each module.
URL Management
- Base URL: This option enables the administrator to set the address (Base URL) for the third-party clients to make API request calls to ATOM server. The format of the Base URL
is http[s]://ip|hostname, where ip is the IP address of the ATOM server and the hostname is the host name of the ATOM server.
- Support URL: Enter the URL of the support to login to the support portal of Anuta Networks
- User Session Timeout: This is the time that you can set for the ATOM server to timeout if no activity takes place in the browser for a specified period of time. The user will be automatically logged out of the session, after the expiry of the specified time.
Alert Monitoring
1.Unwanted-alertlabel-keys: Each alert consists of multiple labels like alert name, app, collections_name etc, out of which some may not be persisted in Atom.
Chart-setting
- Chart-theme: Select the chart theme from drop down,it should show in the monitoring custom chart.
- Chart-refresh-interval: To set the default refresh interval,it should refresh the chart based on the given interval time in this global set.
Device Management
-
- Configuration Retrieval: This option enables the server to retrieve configurations from the devices after each operation. By default, this option is selected.
- Syslog Configuration: This option enables ATOM to configure the device to send syslog events. By default, this option is selected.
- Persist Configuration: This option enables the configurations to persist in the NVRAM of the device after each provisioning.
- Dry Run: This option enables ATOM to push the commands to the device or not. When selected the commands are pushed to the device..
- Auto Retry: Select this option to enable ATOM to try establishing the connection with the device in case the connection is lost initially
- Number of Retries: Enter the number of times that ATOM should try establishing the connection with the device in case of failure.
- Retry Wait Time: Enter the time period that ATOM should wait between subsequent retries.
- Configuration Parsing: This option enables ATOM to parse the configuration retrieved from the device and store the configuration data in the data model maintained in ATOM.
- Configuration Pull Type: This option determines how the mode of retrieving the running configuration from the device
- TFTP_EXPORT – The running configurations are obtained from the TFTP server
- SHOW_COMMAND – The current configuration on the device are obtained by ATOM
-
- Log Running Config: This option enables ATOM to dump the retrieved configurations from the device in the logs obtained for the Config Retrieval Jobs.
- Run-extended-inventory: TConfiguration settings on disabling the extended inventory when device is added
- Generate-config-inventory-event: This option allows ATOM to enable or disable the config inventory event
Service now
1.Snow-instance : To enable service now option to perform the service now workflow 2.Snow-url : To provide the instance id for service-now
- Snow-username : User name for service now 4.Snow-password : Password for service now
Service Management
-
- Service Auto Retry: Select this option if ATOM should retry pushing the configurations to the device in the event of a service failure.
- Service Number of retries: Enter the number of times ATOM should retry sending the configuration after initial failure of the service.
- Service Retry Wait Time: Enter the duration of the time that ATOM should wait before trying to establish a connection with the device again.
- Auto Delete Stale Inv Data: Select this option if all the available “stale” entries should be deleted from ATOM. Stale entries are the configurations that are available in the device and not seen in ATOM. These differences are not due to the service configurations created by ATOM and pushed to the device.
- Delayed Event Buffer Time:
- Service Auto Retry: Select this option if ATOM should retry pushing the configurations to the device in the event of a service failure.
TSDB
1.Retention-period: Retention period of prometheus db 2.Retention-size: Retention period of prometheus db 3.Namespace: Namespace to get the stateful sets and config map 4.Tsdb-url: Url to get metrics
- Workflow-url:The url to get workflow
- Tsdb-config-map-name:The name of the tsdb config map 7.Tsdb-stats-name:The statefulset name of the tsdb server
8.Tsdb-infra-alert-config-map-name:The name of the tsdb config map for system alert 9.Alert-repeat-interval:The repeat interval time of the alerts
- Tsdb-alert-manager-config-map-name:The name of the alert manager config map
SNMP v2 Configurations
-
- Enable Device Audit Trail Mode: Select this option to view all the events generated in ATOM while communicating with the device using the SNMP protocol. SNMP events such as SNMP WALK, GET, DEVICE_LOGIN and DEVICE_COMMAND EXECUTION are captured in ATOM as Events.
- Enable Multi Tenancy: Select this option to enable ownership of the resource. Once this option is enabled, the fields “Owner & Sharedwith” are displayed
- SNMP Configuration Contact: Enter the mailing ID for contacting the admin (support) managing the SNMP server.
- SNMP Configuration Location: Enter the location of SNMP server
- SNMP Community string: Enter the community string required for authentication in SNMPv2 sessions..
SMTP Configurations
You may have to configure an external email server to send email notifications to the ATOM users.
SMTP Mail From: You can set up an external SMTP email server to send email notifications to the ATOM users. To do so, enter values in the fields described below:
- SMTP Host: Enter the name of the server that will send the email.
- SMTP Port: Enter the number of the port that is used to connect to the SMTP host
- SMTP Auth Required: Enable this option is authentication is required to connect to the SMTP Host
- SMTP User Name: Enter the name of SMTP user
- SMTP Password: Enter the password to retrieve the email.
- SMTP Encryption SSL: Select this option if the connection to the SMTP server should use SSL as the authentication method.
- SMTP Encryption TLS: Select this option if the connection to the SMTP server should use TLS as the authentication method
Notification
Email Notifications: Select this option if you wish to be notified via email about changes taking place in the system.
License Expiry Threshold (days): Set the number of days to notify the user that the license is about to expire.
Python Remote Debug
Python Remote Debug: Select this option if you want to allow debugging of the logs in ATOM remotely.
Debug Server Port: Enter the port number of the remote debug server.
Developer Options
Enable Developer Mode: Select this option for the Developer Options to be visible in ATOM.
Using the Developer Options, the admin can view the all the ATOM entities represented in the data model tree, figure out the xpaths of the objects , all the device and service ATOM SDK
System Maintenance
Enable Maintenance Mode: Select this option if the system needs to be suspended for some time during which no operation can be performed on the ATOM VM.All the TASKS running in ATOM should be in “COMPLETE” state before enabling this option.
View Actions
Show Module Prefixes: Enable this option if the module prefixes for child entities on Profile and Action items should be made visible.
Request Sanitization
As an administrator , you can protect the data entered in ATOM from malicious attacks in the form of HTML tags. These tags when injected into the application’s HTML code can make ATOM vulnerable to these attacks and have a large impact as any user of the application can be a target.
The data entered in ATOM can be sanitized based on the
- Security Sanitizer Enabled: Select this option if the sanitization filter should be enabled in ATOM.
- Sanitizer Exclude URL: Enter the tags that should be excluded from filtering. The patterns mentioned here are allowed as values in the text fields in any of the HTML forms used in ATOM. For example, These tags can be added in the exclusion list
-/login,/initialize,/logout,/*.js,/controller:admin-settings$
- Sanitizer Patterns: Enter the patterns that will be used to sanitize the data and should not be allowed as values in any of the fields in any of the text fields in the HTML forms of ATOM.
An appropriate error message is displayed in the webpage when the user inputted data matches with the sanitizer pattern mentioned above.
Password Profile
The parameters required for a password that is used to authenticate logging into ATOM can be
- Password Expiry Days: Enter the number of days for which the set password is valid.
- Password Pattern:
- Password Min Length: Enter the minimum number of characters that should be contained in the password used to authenticate the logging into ATOM.
- Password Max Length: Enter the maximum number of characters that should be contained in a password used to authenticate the logging into ATOM.
Primary container load limit
1.Set the range of container load limit
Workflow
- If true both delete both active and historical instances on package unload,if false, history will be maintained but unload will fail if active instances are there.
Look and Feel
You can change the “look and feel” of ATOM’s GUI by uploading images of your choice to ATOM.
-
- Navigate to Administration > UI Customizations > Look & Feel
- Product Logo: Select the image that you should be displayed as the product logo, visible on all the screens.
- Login Screen Logo: Select the image that should be displayed on the login screen.
- Click Update for the uploaded images to come into effect on the UI or
- Click Defaults to revert to the default images.
- Navigate to Administration > UI Customizations > Look & Feel
Event Summary
ATOM generated events are grouped into different categories, (Alarm, Services and System) with an assigned severity to each category. ATOM maintains an event catalog and decides how and when an event is created and whether to associate an alarm with the event. Events are generated in ATOM through notifications received via the syslog and trap messages, inventory changes, discovery of the devices, changes in the ATOM server itself.
The severity of events can be classified into:
- CRITICAL – Events that demand the immediate attention of the system administrator. They are generally directed at the global (system-wide) level, such as System or
Application. They can also be used to indicate that an application or system has failed or stopped responding.
- WARNING – A warning indicates that a component or application is not in an ideal state and that some further actions could result in a critical error. These can be treated as forewarning of a problem that might occur.
- ERROR – Events that indicate problems, but in a category that does not require immediate attention.
- INFORMATIONAL – Events that pass noncritical information to the administrator.
Not all Events are associated with Alarms. Multiple events can be mapped to the same alarm. All Alarm Events are associated with an alarm that can be either state, CLEARED or ACTIVE.
Notifications
All the events that are triggered in ATOM due to various reasons such as change in the component state, device unreachability, high CPU usage of the system and so on can be notified to subscribers. As an administrator, you can create notifications such that users, message brokers can be notified when an event is triggered.
Subscribers can be added to the events falling in any of these categories:
- Alarm Events
- Internal Events
- System Events
- Resource Events
- Service Events
Each of these categories contain many Events, pre-defined in ATOM. You can create subscribers or the recipients of a particular notification.
- Navigate to Administration > System > Notifications

- In the left pane, click a folder (of your choice). All the events are grouped into different categories
- In the expanded view of the folder, select an Event as shown below:
- In the Events Subscribers pane, click Add to the subscriber to the ATOM generated event.
- In the Create Subscriber (s) screen, choose the type of the Subscriber:
-
- User
- These users are the users created in ATOM . See the section, Creating Users in ATOM
- User
- AMQP Broker
- These are the message brokers where the events generated in ATOM are published. See the section, Creating Message Brokers for more information.
Message Brokers
As an administrator, you can configure a message broker to publish the events generated by ATOM. A message broker can be notified of all events or an event belonging to a specific event type.
In the current implementation of ATOM message brokers, RabbitMQ is the supported AMQP server where ATOM publishes the events and from where any AMQP listener consumes them.
Prerequisites:
Before creating Message Brokers in ATOM, check whether a virtual host exists in RabbitMQ. If there is no existing vHost, create a new virtual host as shown below:
- Login to RabbitMQ and go to the Virtual Hosts tab to add a new vHost
- Add users for the created virtual host
- Create users with required permissions in the vHost Creating Message Brokers in ATOM:
- Navigate to Administration > System > Message Brokers > click Add
- In the Create message broker screen, enter the following fields as described below:
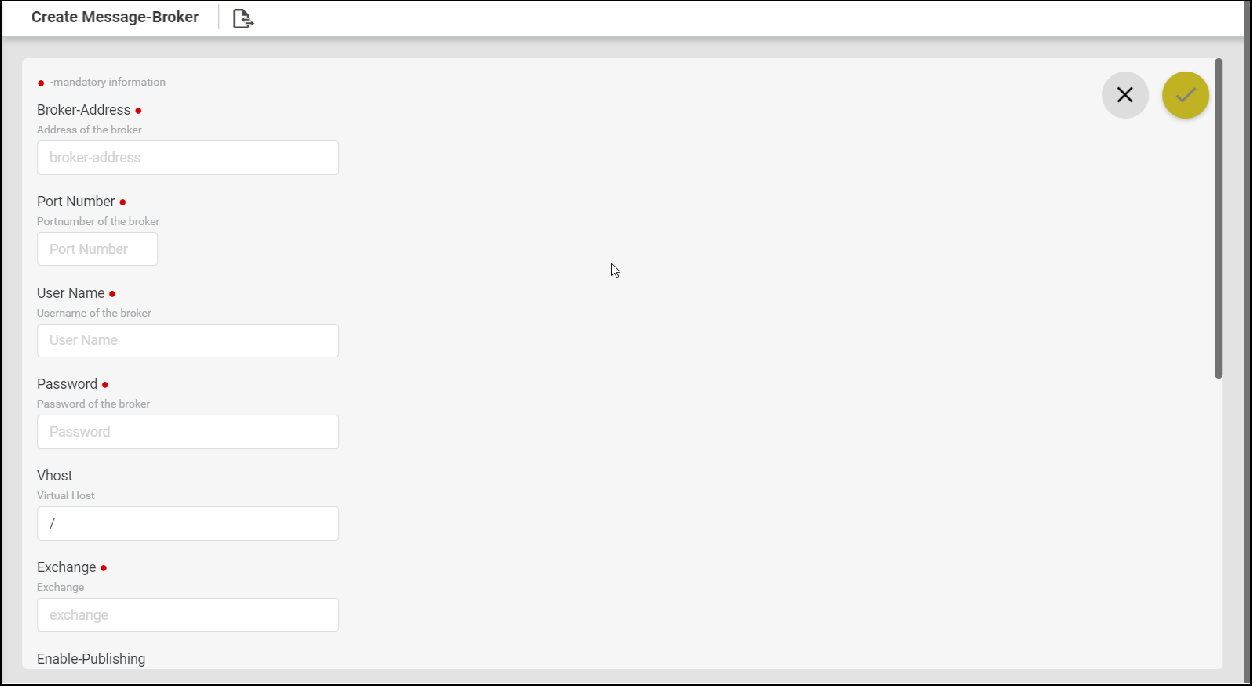
- Broker Address: Enter the IP address of the message broker (AMQP server which in our case is RabbitMQ).
- Port Number: This is the port number used to communicate with ATOM. By default, it is 5673.
- Username and Password: Enter the credentials for logging into the message broker.
- vHost: Enter the virtual host name that was created in RabbitMQ. Refer “Prerequisites” section.
- Exchange: Enter the name of the exchange in the message broker where the events generated in ATOM should be published. The default name is “ATOMNotifications”.
- Enable Publishing: This option enables the administrator to enable or disable sending notifications from ATOM to the exchange. By default, the checkbox is selected, which means that the events can be sent to the broker.
- Connection Status: After saving the Message Broker, this field will be updated to True/False based on the success or failure of connectivity to RabbitMQ
- Click Add to select the events that should be sent to the message broker.
AMQP Listeners
You can create AMQP listeners in ATOM so that the messages (events) published in ATOM can be consumed by them.
In the current implementation of ATOM message brokers, RabbitMQ is the supported AMQP server where ATOM publishes the events and from where any AMQP listener consumes them.
Prerequisites:
- Login to RabbitMQ Message Broker using the appropriate credentials
- Create Queues in RabbitMQ
- Login to RabbitMQ and go to the Queues tab.
- Add a new queue as shown below:
- Bind the Queue with the Exchange in RabbitMQ
- In RabbitMQ, navigate to Exchanges
- An Exchange entry is created in RabbitMQ and connection with ATOM is established
- Select the Exchange, “ATOMNotifications”, created in ATOM and bind the created Queue to the same as follows:
- Verify the messages in RabbitMQ
- Go to Queue > Get messages
- In the Messages field, enter a number for the messages that you want to be displayed.
- Click Get Messages as shown below:
To create the AMQP listener in ATOM, do the following:
- Navigate to Administration > System > AMQP Listeners
- Click Add AMQP Listener in the right pane to create a listener in ATOM
Enter values in the fields in the Create AMQP Listener screen as described below:
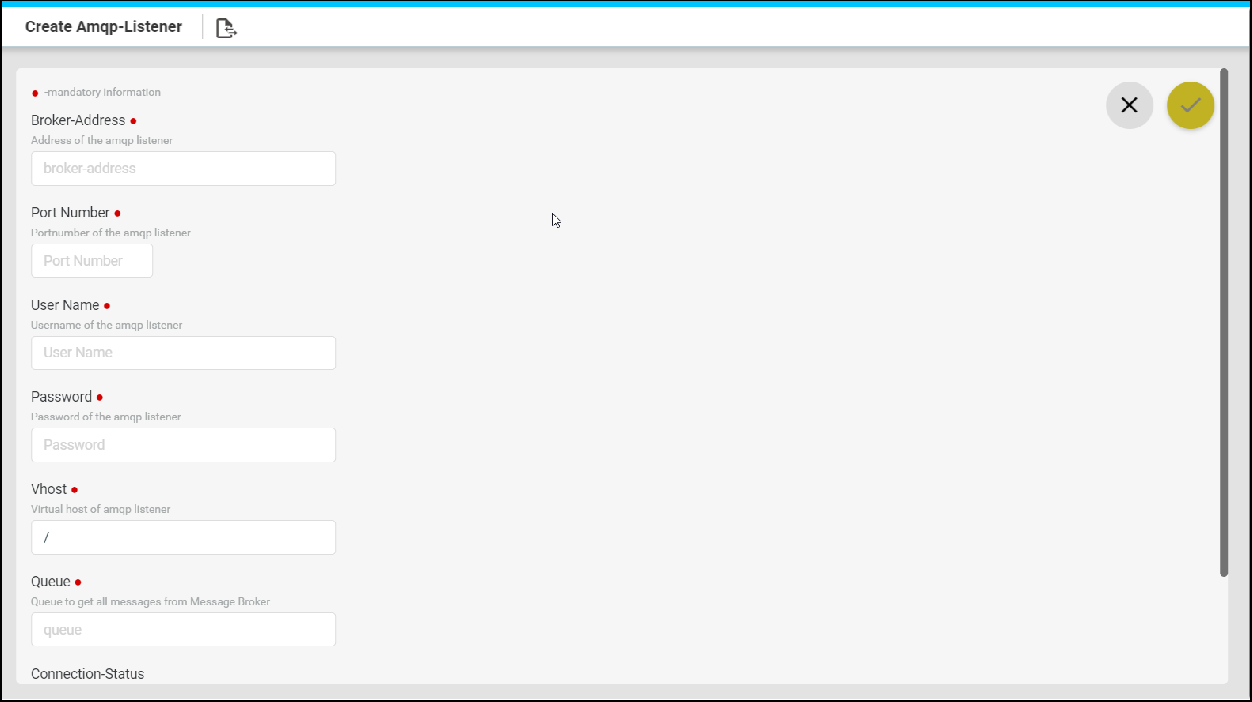
- Broker Address: Enter the IP address of the AMQP server that will receive the notifications from ATOM.
- Port Number: This is the port number that needs to be configured on the message broker to listen into the ATOM notifications.
- Username: Enter the username of the AMQP listener.
- Password: Enter the password to authenticate the AMQP listener.
- vHost: Enter the virtual host name that was created in RabbitMQ
- Queue: Enter the name of the Queue created in the AMQP server (example, RabbitMQ)
- Agent Name: Select the ATOM agent from which the ATOM notifications are generated on a given set of devices. All the notifications created on the device managed by the ATOM agent will be published in the queue.
System Manager
To view the components, microservices and the applications managed by ATOM, navigate to
Administration > System Manager
Dashboard:
View the graphical representation of the connection between the Applications, Components, and the underlying microservices.
Navigate > Administration > System Manager > Dashboard
ATOM Components:
Navigate > Administration > System Manager > Atom components > Atom components
The components, of ATOM, along with their dependencies are displayed as follows:
All Components:
Navigate > Administration > System Manager > Atom components > All components
The components of the Kubernetes cluster that are not owned by Anuta are displayed as follows:
Component Relations:
Navigate > Administration > System Manager > Atom components > Component Relations
All the dependencies between the components can be visualized as follows:
Applications:
Navigate > Administration > System Manager > Atom components > Applications
All the applications served by the underlying Components are displayed as follows:
Component Functions:
Navigate > Administration > System Manager > Atom components > Component Functions
The association of the components between the applications can be visualized as follows:
Deployment Functions:
Navigate > Administration > System Manager > Atom components > Deployment Functions
The following deployment summaries to be displayed
FQDN Agent Settings
Navigate > Administration > System Manager > FQDN Agent Settings
- No need to restart any pod, it should discover any endpoints.
Command : kubectl edit cm -n kube-system coredns
- Content added as below:
anutacorp.com:53 { errors
cache 30
forward . 172.16.100.5
}
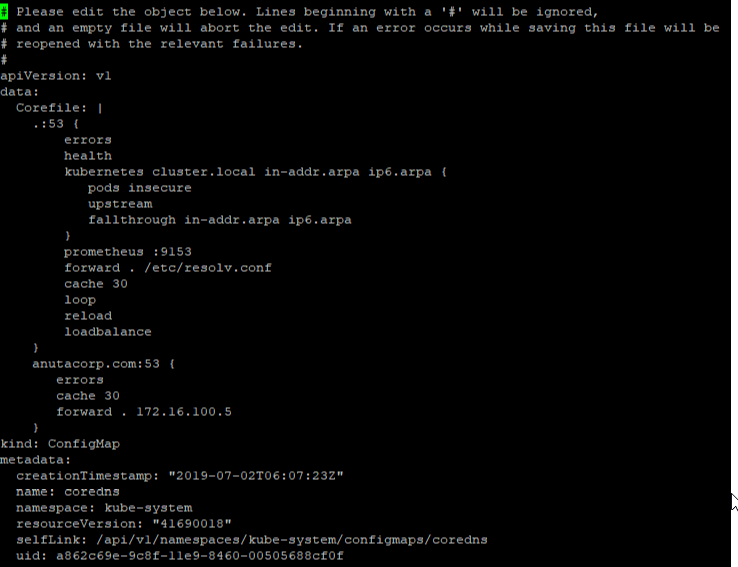
Go to Administration/System Manager/FQDN Agent setting for pattern
Click Add Symbol and Select Default-Domain-Agent and give proper Pattern & Priority
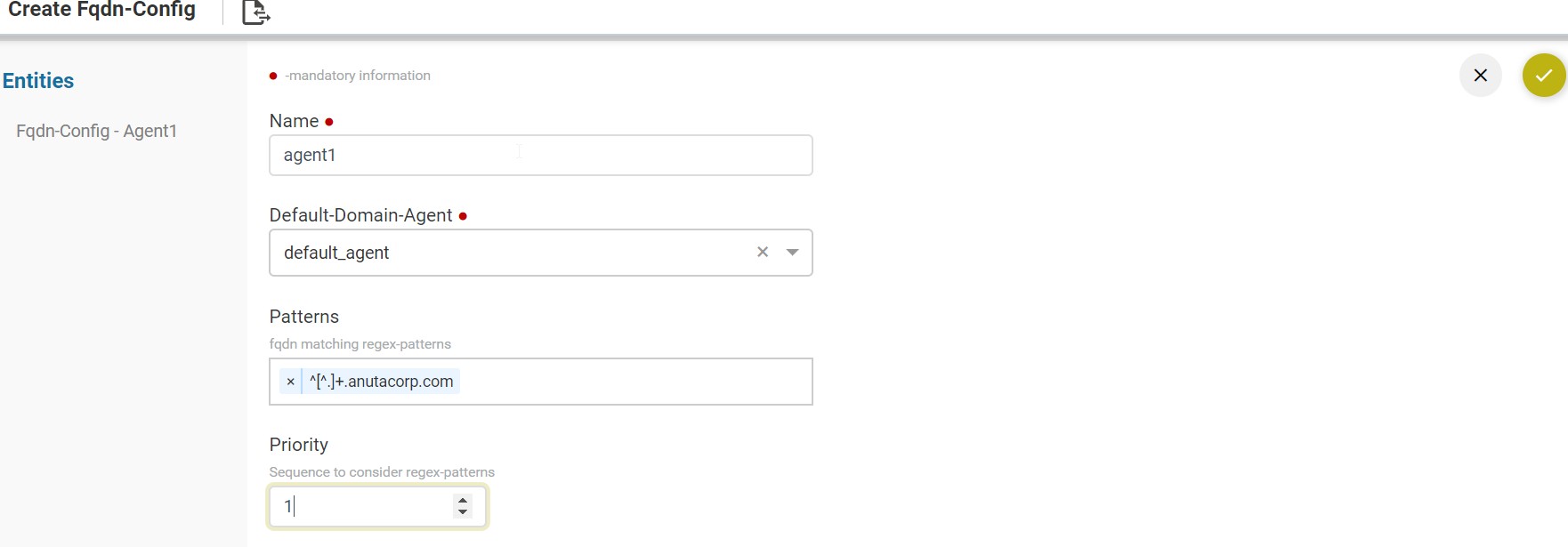
After creating FQDN then go to Entities/Ip-Ranges as shown.
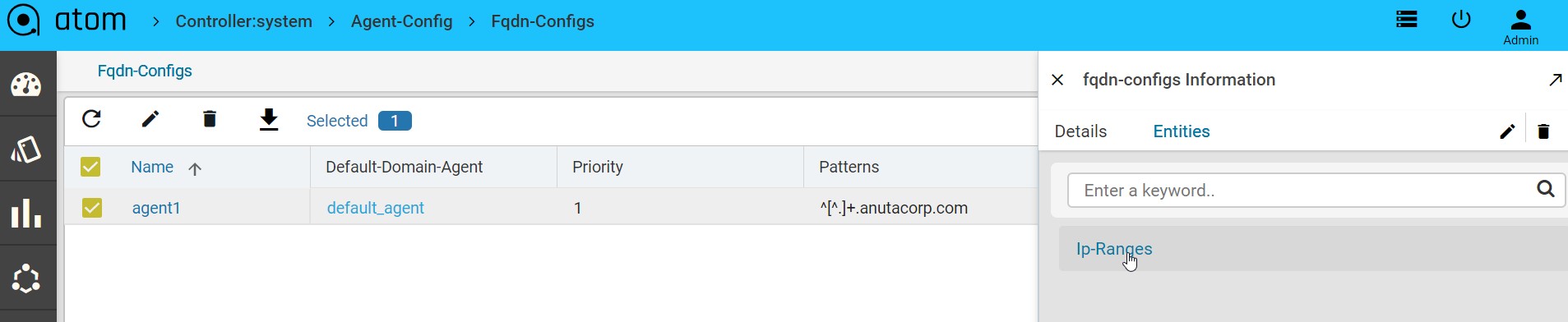
Provide valid IP Ranges and select agent
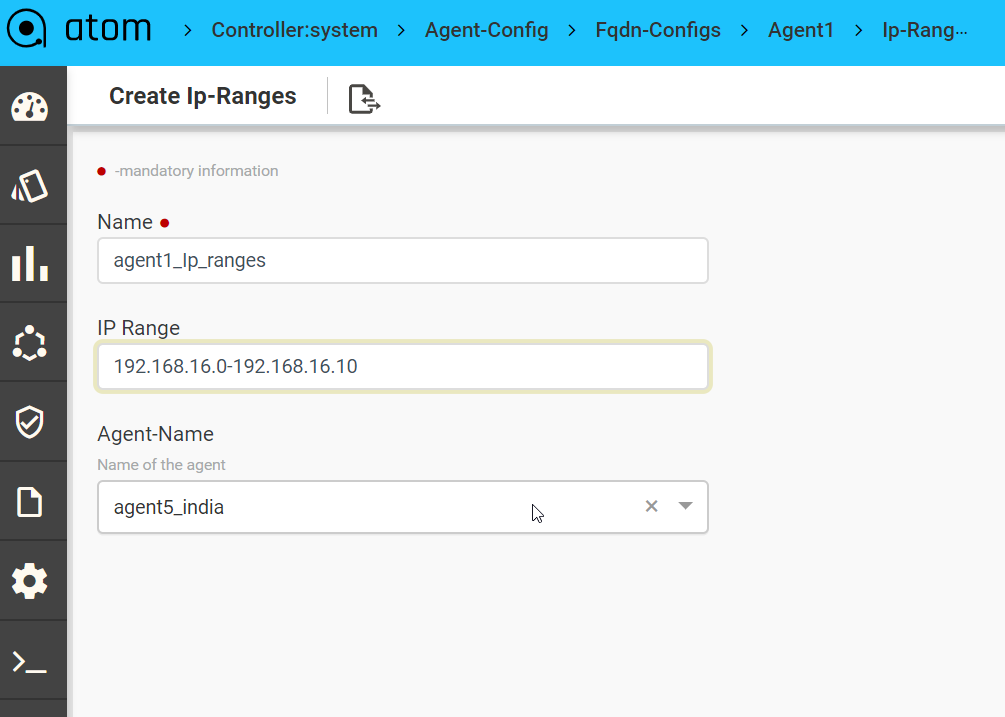
Go to Devices and click add symbol and Provide FQDN-Name to resolve FQDN
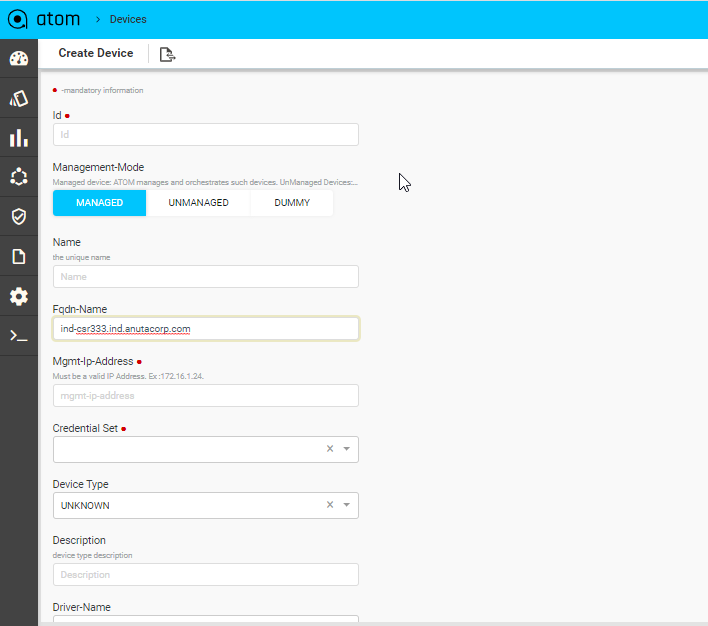
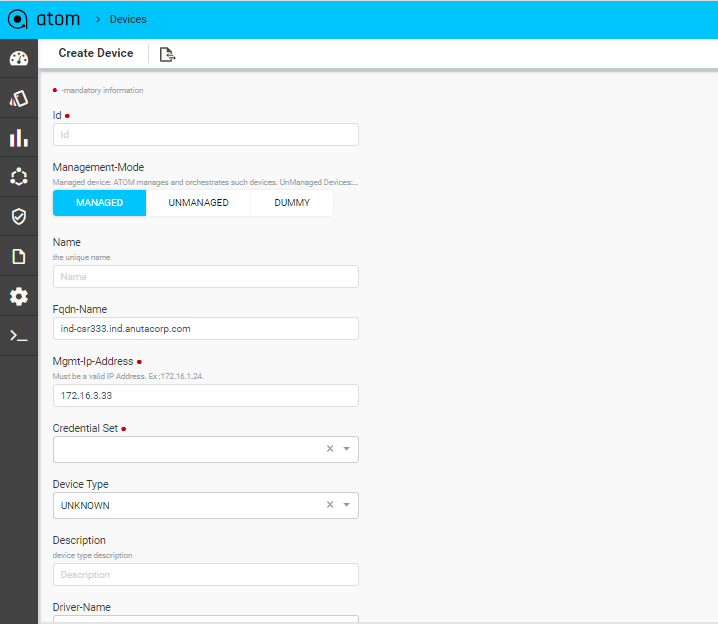
Plugins and Extensions
By utilizing the normalized device abstractions maintained in data stores written in YANG maintained in ATOM, the customers can write their own device models and applications to meet their specific operational needs, thereby utilizing the extensibility of ATOM.
The device and service packages are loaded as bundles or plugins to the ATOM container thereby making them modular. The packages can be installed, updated, or deleted without disrupting the operation of the device.
In addition to modeling the devices and service, you can model the features or network functions required to build a network service. These features thus modeled appear as icons in the feature palette of Service Designer pane of ATOM. The newly added features along with the included associated services can now be used to design the service in ATOM.
Packages
ATOM is packaged with many predefined device packages to enable you to work with many vendor devices. ATOM also provides capability to update the existing device packages and ability to add new device packages
A Device Model contains inventory models, communication model, and notification model that are packaged and uploaded to ATOM. A device package consists of models, a vendor -specific configuration data for all the different devices.
For details about what constitutes a device package and how to write it, refer to examples cited in the guide, “ATOM Platform Guide”.
A Service package contains the services models, service yang files and metadata information. For more information about Service Modeling, refer to examples cited in the guide, “ATOM Platform Guide”.
Package Explorer
Users can manage and get the information of the packages that are currently available in the system. The packages that were uploaded and loaded can be viewed in minio UI.
Navigate to Administration > Plugins & Extensions > Package Explorer
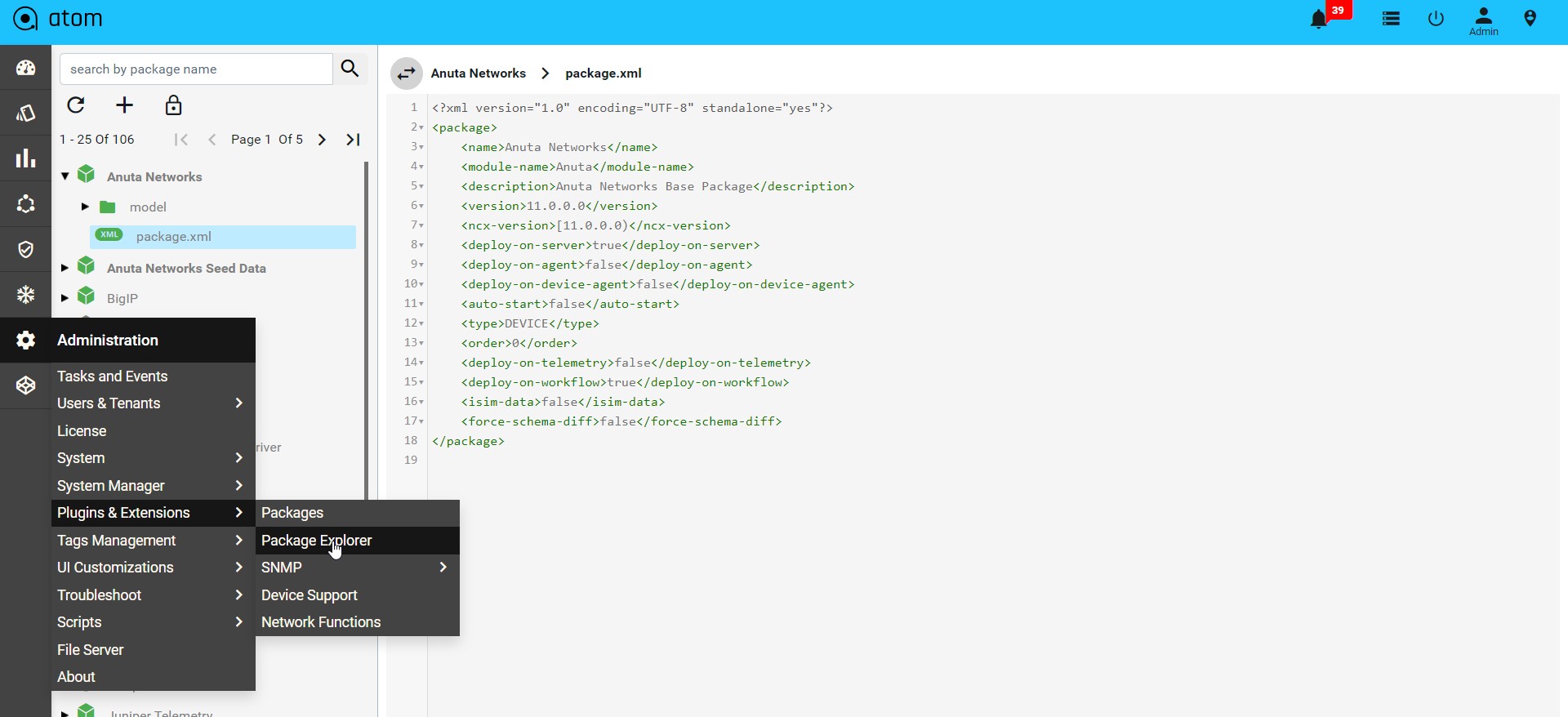
SNMP
Navigate > Administration > Plugins & Extensions > Package > SNMP > SNMP Mibs >Upload
Navigate > Administration > Plugins & Extensions > Package > SNMP > SNMP OID Maps > Add

Navigate > Administration > Plugins & Extensions > Package > SNMP > SNMP Metric Metadata > Add
Device Support
Device Support view allows users to create a new Vendor, Device Type, Device Family, OS Type, Device Capabilities, Terminal Handling Properties etc.,
Managing Tenants
The administrator can make use of ATOM’s multi-tenancy capability to share IT resources
cost-efficiently and securely by creating Tenants. The Tenants share common infrastructure, yet utilize a defined set of highly secure services, with complete isolation from other tenants. The resources managed by ATOM can be securely shared among multiple applications and tenants (businesses, organizations, etc.) that use the resources of the datacenter.
Overview of Multi Tenancy
- Multi-Tenancy – Supported on ATOM On-Premises & ATOM Silo/Dedicated Deployment on ATOM Cloud.
- Tenants (Coke, Pepsi etc.,) are completely isolated from each other.
- Sub-Tenancy – Supported on All ATOM Deployments – On-Premises, ATOM Cloud Silo/Dedicated and also ATOM Cloud Shared.
- Data sharing across sub-tenants (Coke.east, Coke.west, Coke.it etc.,) is controlled by Tenant Admin.
- By Default Data at a higher Level Tenant is Visible to the Sub-Tenants.
- By Default, Data under a sub-tenant is visible to the Tenant
- By Default, Data under a sub-tenant is not visible to other Sub-tenant
- Example – Coke.east owns a resource (credential set or device etc.) and wants to share with sub tenants (Coke.west but not with Coke.it). In this case, ATOM Multi Tenancy Infrastructure provides a facility to share a resource with particular
sub-tenants. Upon sharing the resources as required, each individual ATOM User
interface will provide information on Resource sharing as shown below. This behaviour will be the same across all the resources in ATOM and will not be discussed specifically across features in the user guide.
Sample View of Resource being shared from Coke.east to Coke.west
Mulltitenancy feature is enabled in the system as a result of which every object managed by ATOM can be owned by an admin and shared with multiple users (tenants) simultaneously.
Aided by rules and roles that can be created in ATOM, the administrator can either assign or restrict access to the resources (resource pools, sites, locations, IPAM, devices) managed by ATOM.
All the created resources in ATOM are allocated to the system, the default admin user who is the owner of the resources. These resources managed by ATOM are available to all the Tenants in the system. The administrator can now share the system resources with the required tenant or tenants. From then on, all the resources that are created in each Tenant (parent) are available to only the users (child nodes) of a particular parent.
Root Tenant
‘System’ is the root tenant. Every other tenant is a child or in the child hierarchy of this root. There may be few objects which are kept ‘private’ to the system, meaning, those are not ‘shared’ to child tenants.
Top Level Tenants
Top Level Tenants (referred ‘tenants’ for simplicity) are the immediate children of system nodes. For ex;
System
Company-1 Company-2 Company-3
In the above example, company-1, 2, 3 are top level tenants.
Simple Multi Tenancy
ATOM supports Sub tenancy where a tenant can subdivide their resources into a sub hierarchy. But, when there are no sub tenants in the deployment, it is referred to as ‘Simple Multi Tenancy’.
For ex;
System
Company-1 Company-2 Company-3
In On-Prem deployment, it is up to the customer how they treat the root tenant.
 If they don’t create any child tenants to the system, then, system and customer are synonymous.
If they don’t create any child tenants to the system, then, system and customer are synonymous.
Hierarchical Multi Tenancy
Sub Tenant
A sub tenant is a child [directly or indirectly] of a Top Level [Not root] tenant.
System
Company-1
North South
Company-2 Company-3
Campus-1
In the above example, ‘System’ is the root tenant
Company-1, Company-2, Company-3 are top level tenants
Company-1.north, Company-1.south are sub tenants of Company-1. Company-1.south.campus-1 is a sub tenant of acme.south
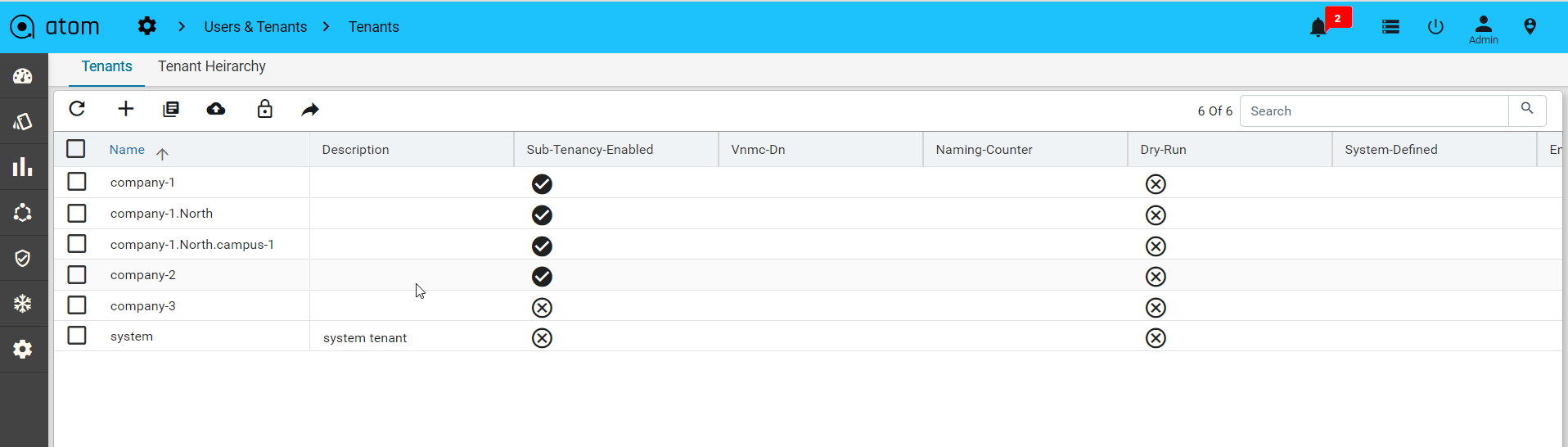
System users
System is the root tenant. System users are those, whose User.owner = ‘system’.
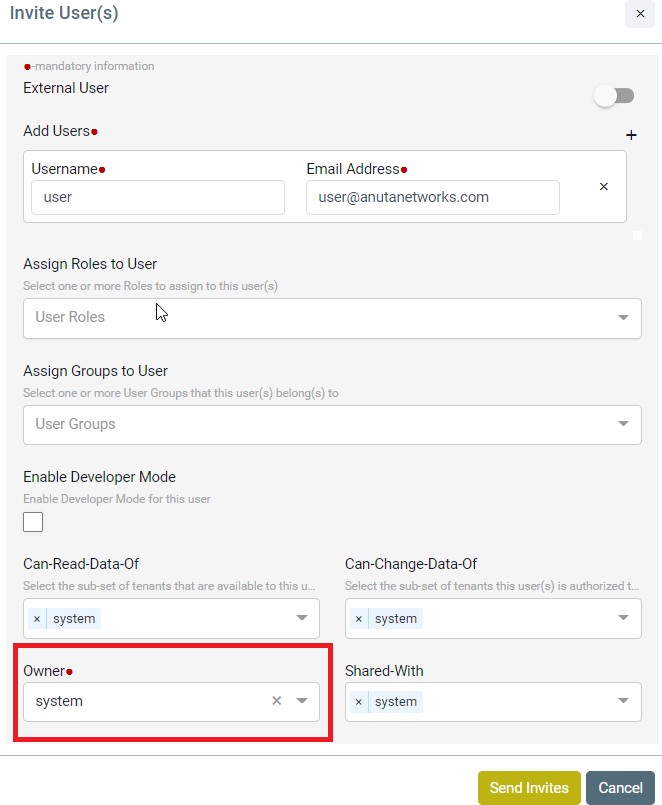
Tenant Users
Tenant users are customer users owned by individual tenants. User.owner != ‘system’
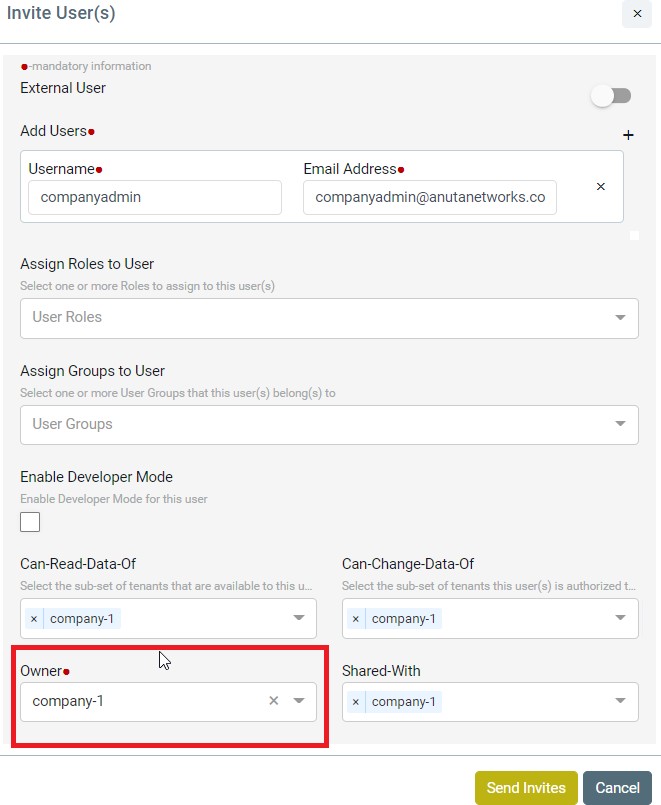
Owner:
Owner is a tenant. And, we use ‘tenant-id’ to identify a tenant.
Tenant-id uses fully qualified names separated with dots, such as, Company-1.south.campus-1.
Multi Tenancy is all about keeping data private to a tenant. This means, data identified by a key can have one copy for each tenant. Suppose, 2 tenants want to bring in the same device-1 ?
That counts to 2 instances with the same key. Clearly object id by itself is not sufficient. Hence, objects are identified by their id and ‘owner’. Object key is formed by object id and owner.
Shared-with:
A resource can be shared with multiple tenants or kept private to the owner.
Sharing of resources applies only when a resource owned by one tenant is to be used by another tenant.
For example, a device owned by tenant-1 is used by a ‘network service’ created by a tenant-2. Sharing across tenants is not supported. but, within a tenant sub hierarchy is supported.
For example, no data is ever shared among the 3 companies of the following hierarchy System
Company-1 Company-2 Company-3
But there is, down the hierarchy sharing allowed. Such as, ‘system’ resources are shared to all the three [and sub tenants, if exist].
If Resource is shared-with system then it is private to system
If Resource is shared-with system.* then it is shared with all the sub tenants.
Concept Of Visibility And Usability
Visibility is the same as ‘Readability’; Whether a resource is visible to a user.
Usability of a resource is with respect to another resource and it is about whether a resource-1 can be referred (in a relation for example) by another resource.
For example,
device-1.credential-set = ‘cred-1’
| # | resource | Owner | |
| 1 | device-1 | Univ.Engg | |
| 2 | cred-1 | Univ.Phy |
Device-1 wants to use ‘cred-1’ in a ‘device.credential-set’ relation.
Currently, to make cred-1 available (visible, usable) to resources of Univ.Engg, you have to share it with that tenant.
| # | resource | Owner | shared-with |
| 1 | device-1 | Univ.Engg | |
| 2 | cred-1 | Univ.Phy | Univ.Engg |
Shared With Variations
System
Company-1
Campus-1
Department-1 Department-2
Campus-2
| Owner | Resource | Shared With | Details |
| Company-1 | R1 | Company-1 | R1 becomes a private object |
| Company-1 | R1 | Company-1, system | A Tenant Resource shared with system [there are a few scenarios where this is useful] |
| Campus-2 | R1 | company1.Camp us-1, company1.Camp us-2 | Sharing with other tenants [in the sub hierarchy] |
| Campus-1 | R1 | Campus-1.* | Using wildcards in sharing-with. R1 will be shared with all sub tenants. Since sub |
| tenants can be added or removed during the life cycle of a deployment, sharing is spread to all the sub tenants available at the time of invocation. |
User.Owner:
User object has an ‘owner’ property, just like any other resource. But, there is a special meaning to ‘user.owner’.
Users need to be authenticated in the system.
Authentication is done with an ‘Identity Provider’, such as an LDAP. Identity Providers are associated with tenants.
So, a user is authenticated against the provider traced via User.owner
User.can-read-data-of And User.can-change-data-of:
A user could be created at a higher level (user.owner) but to limit the user to a subset of tenants there are two properties.
‘can-read-data-of’ controls which tenant data a user can read.
‘can-change-data-of’ controls which tenant data a user can change.
When a top level tenant does not have sub-tenants, user.can-read-data-of will be fixed to the tenant. User.can-change-data-of can be used to disable writes [by omitting a value]. If decided to allow writes , the value will be fixed to the tenant.
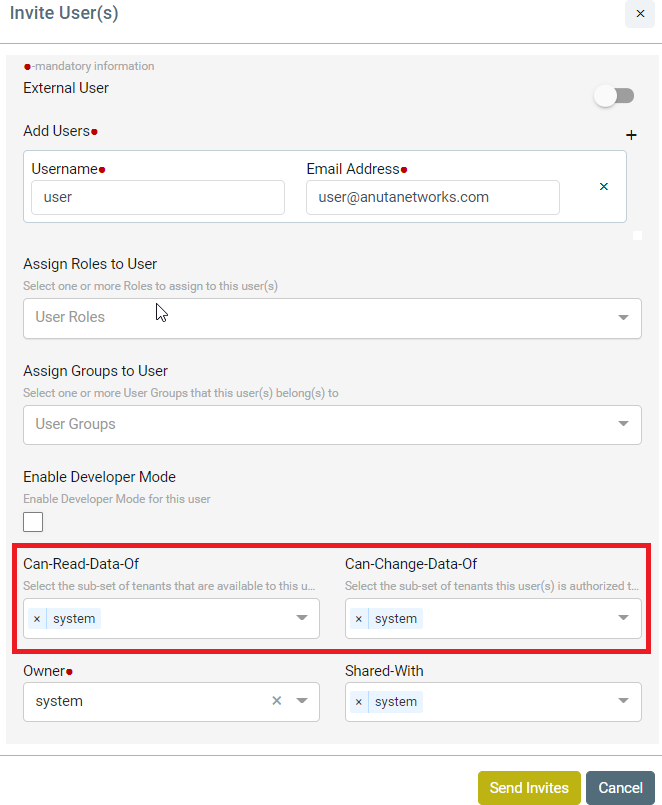
Creating Tenants
Before instantiating a service, there should be at least a single Tenant created in ATOM.
-
- Navigate to Administration > Tenants
- Select the Tenants folder > click Add
- In the Create Tenant screen, enter the following:
- Name: Enter an alphanumeric string of not more than 32 characters
- Description: Enter a description for the Tenant
- TenantId: Enter a unique identifier for the Tenant
- Dry Run: This option does not allow ATOM to send the configurations to the devices while creating services. By default, this option is unselected.
- Select the checkbox to allow ATOM to push the commands on to the devices.
Onboarding Tenants through Keycloak scripts
 Before creating a tenant admin, We need to create a tenant manually in system admin(Ex:Coke). Navigate->Administration->Users and tenants->Tenants:
Before creating a tenant admin, We need to create a tenant manually in system admin(Ex:Coke). Navigate->Administration->Users and tenants->Tenants:
Creating a tenant in Atom UI.
SSH into Master ip of ATOM to run onboard_tenant_lifecycle.py.
Configure like below in master ip.
sudo python onboard_tenant_lifecycle.py -r <tenant name> -c atom -tenant True -realm True -vip <tenant ip>
EX : sudo python onboard_tenant_lifecycle.py -r coke -c atom -tenant True -realm True
-vip 172.16.5.65
Note:: tenant ip which is not pingable.

After running the commands, need to copy the Tenant login URL from TENANT HAPROXY URL : https://172.16.20.95.
After getting the tenant haproxy url , need to connect the keycloak as:
https://172.16.20.90/auth
Login to keycloak using user/password : admin/Secret@123
Create tenant admin
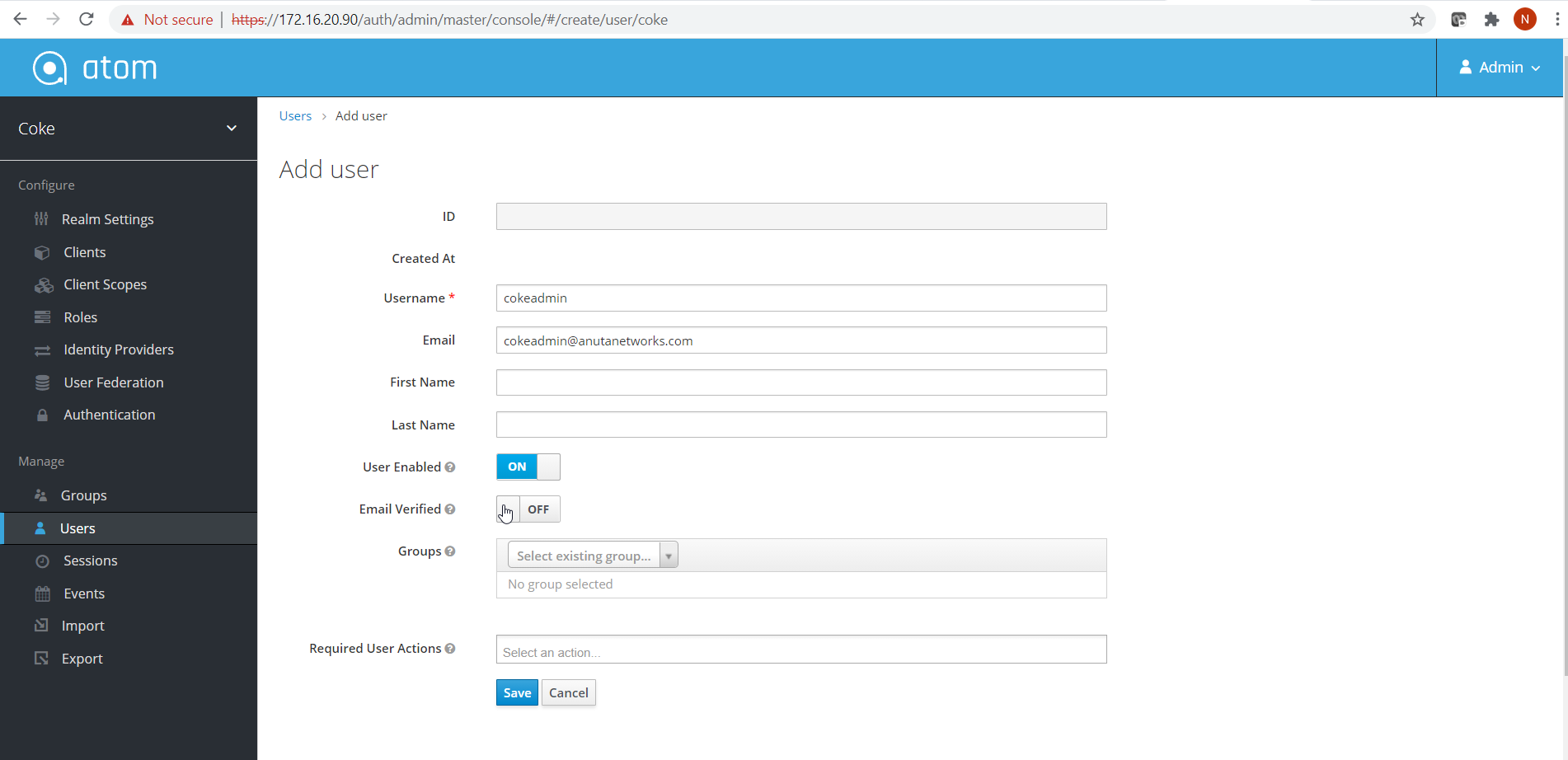
Set the password
Login with tenant admin user
Upload the tenant license in atom
Check the tenant admin UI.
User Management
The control of users and groups is a core element of ATOM system administration.Users can also be grouped (based on the function) to have read permissions, write permissions, execute permissions or any combination of read/write/execute permissions for files owned by that group.
Managing Users in ATOM not only covers creating users but also configuring or assigning the privileges for each user or similar group of users to perform tasks in ATOM. Apart from creating the access or deny permissions in ATOM locally, you can import existing LDAP or AD users into ATOM and extend the necessary permissions to them too.
User management and Authentication works in ATOM as shown in the diagram below. The user information is saved in KeyCloak. OAuth Proxy acts as a gatekeeper checking all the incoming requests and ensuring the requests are coming from an authenticated client. If the proxy sees an non-authentic call, it redirects the request to a login screen served by the identity provider, which is KeyCloak.
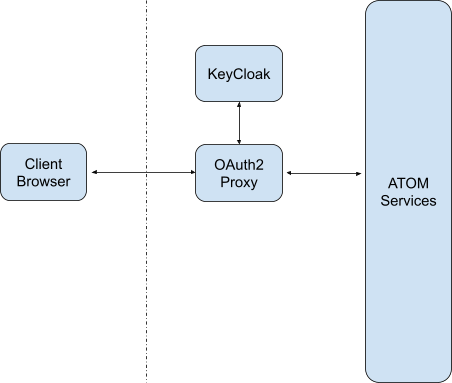
User management in ATOM includes the following:
- “Roles”
- “Creating Authentication Mode Priority”
- “Managing Users”
- “Configuring Access Control”
- “Managing OpenLDAP Users”
- “Managing Active Directory Users”
- “Managing TACACS Users”
Roles
A set of system-defined permissions are grouped into roles and are available in ATOM by default. These roles can be assigned to a user during the creation of users in ATOM.
- ROLE_SYSTEM_ADMIN: Administrator of the root tenant (‘system’). Every other tenant is either a direct child of the system or a sub tenant (descendent) of a top level tenant. System admin is given permission to onboard tenants and manage ‘system’ tenant resources.
- ROLE_TENANT_ADMIN: Is the equivalent of ROLE_SYSTEM_ADMIN (gets blanket permissions on all resources) but limited to resources of the specific tenant (‘user.owner)’ .
- ROLE_USER_ADMIN: Gives all access to user mgmt objects (users, Groups, rbac rules [rule list and everything down] etc), but limited to user.owner.
- ROLE_WORKFLOW_ADMIN: Allows a user all permissions on all workflow resources. This avoids having to create individual workflow permissions.
Note that other permissions (rpc, data node etc) are still needed to be given explicitly,
because this role only covers ‘Workflow resources’ only.
Creating Authentication Mode Priority
Starting from the 5.8.7 release, the admin can set the priority of the authentication modes in ATOM. By setting the priority of the authentication modes, the admin can enable the login failover to another authentication mode, if the first authentication mode (as arranged in the order of priority) fails. ATOM fails to the local authentication mode, if all the authentication modes as defined in the priority list fail.
To create the authentication mode priority in ATOM, do the following:
- Navigate to Administration > Users & Tenants> Authentication Mode Priority in the left pane.
- In the right pane click Add Auth Priority and in the Create Auth Priority screen, click
Entities > auth-modes
- Enter values in the fields as described below:
- Priority: Set the priority for the authentication mode. (1 is the highest priority)
- Authentication Mode – Select the authentication mode from the available authentication modes (TACACS, OpenLDAP, Active Directory and Local)
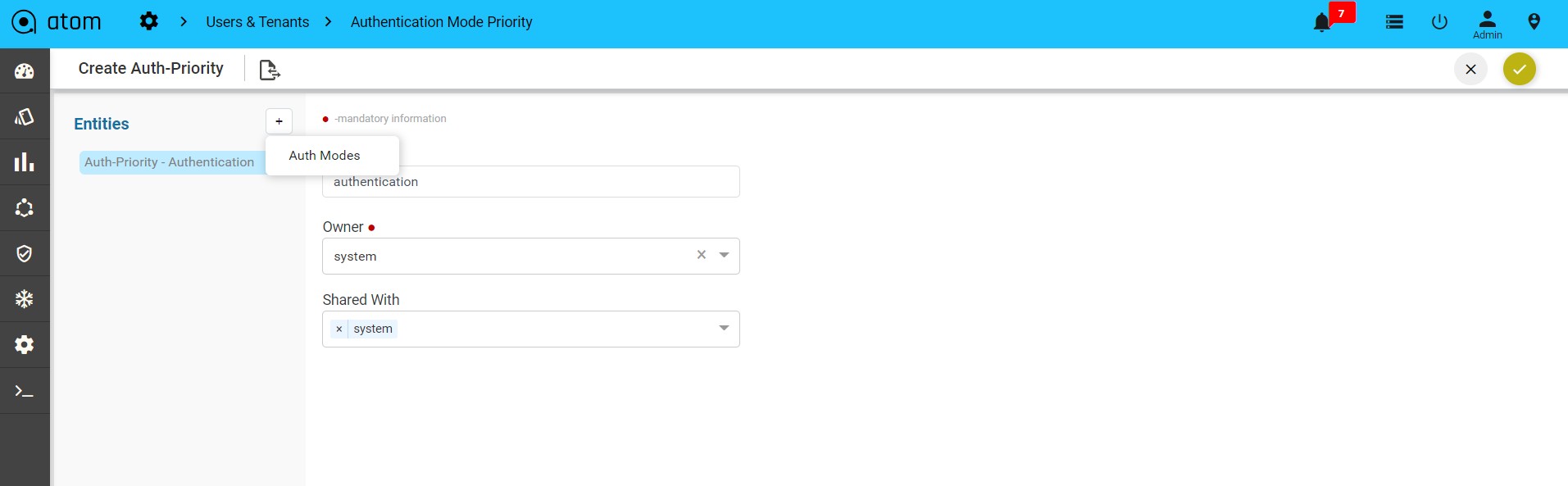
After setting the priority for each of the authentication modes, you can view the list as shown below:
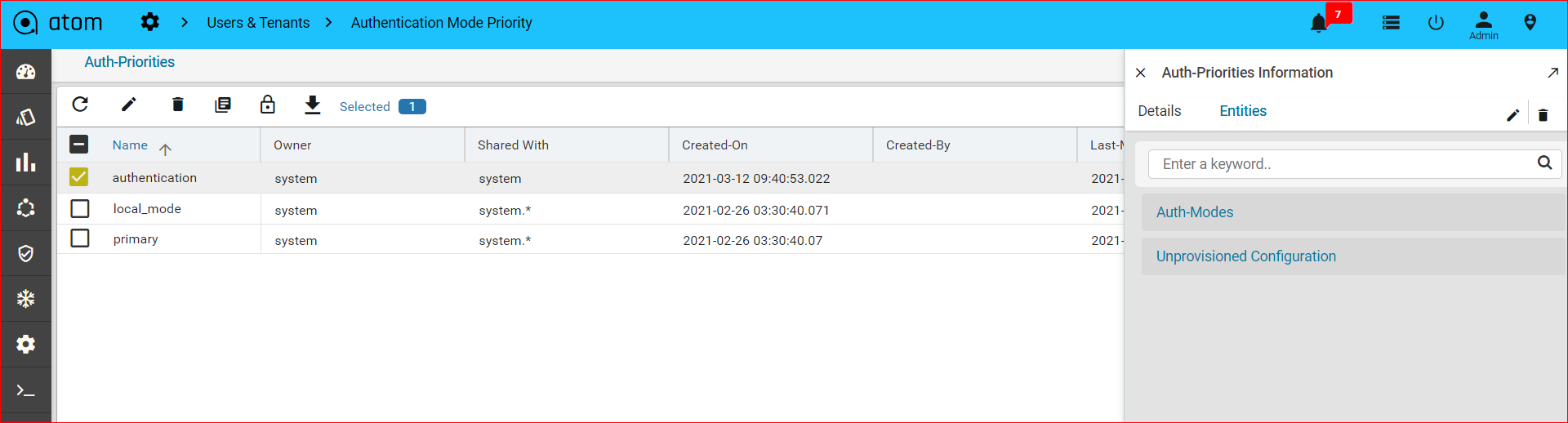
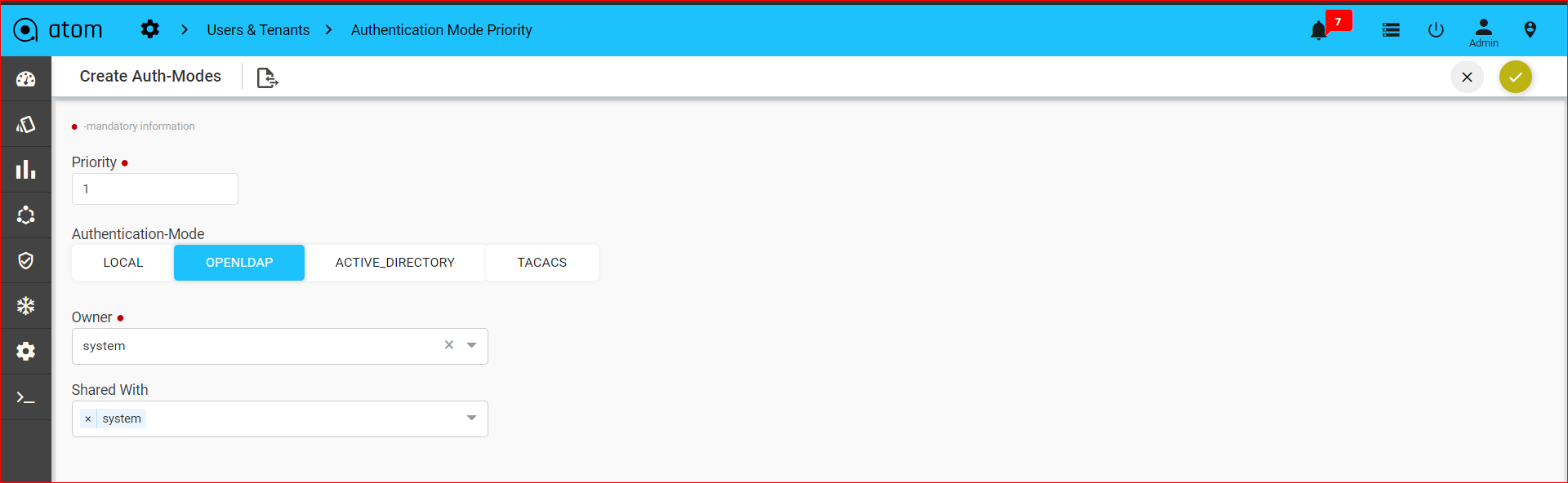
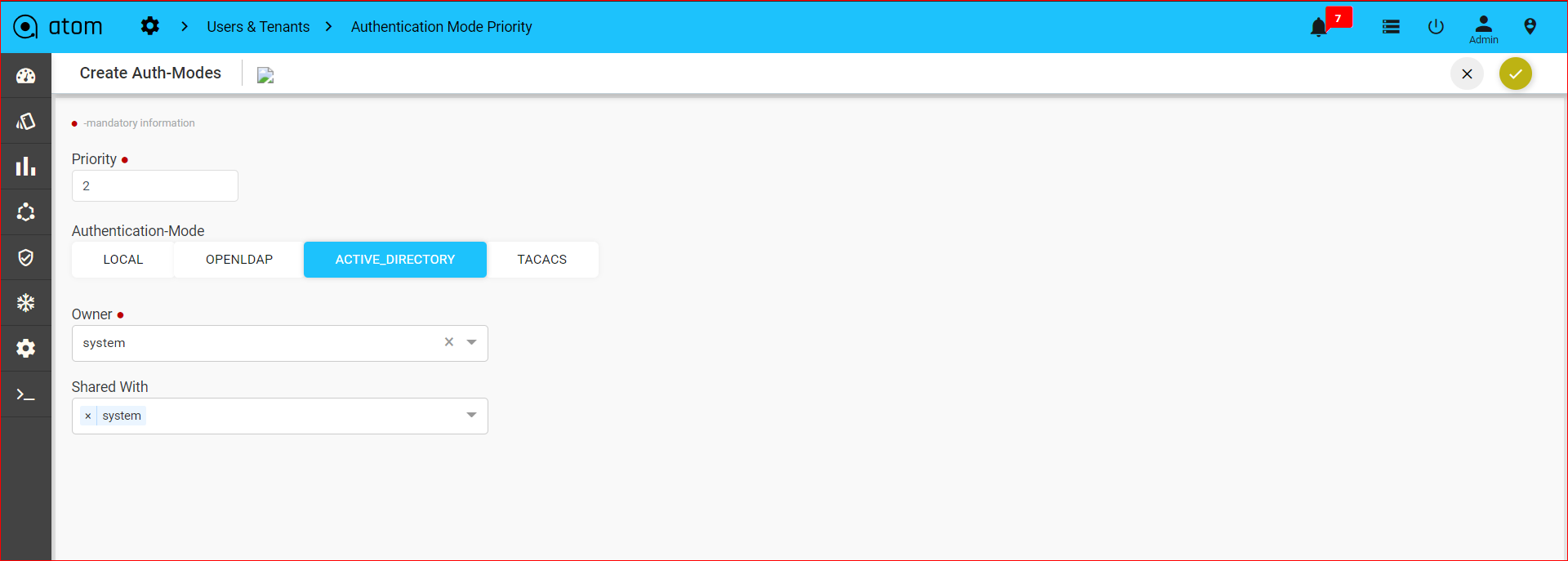
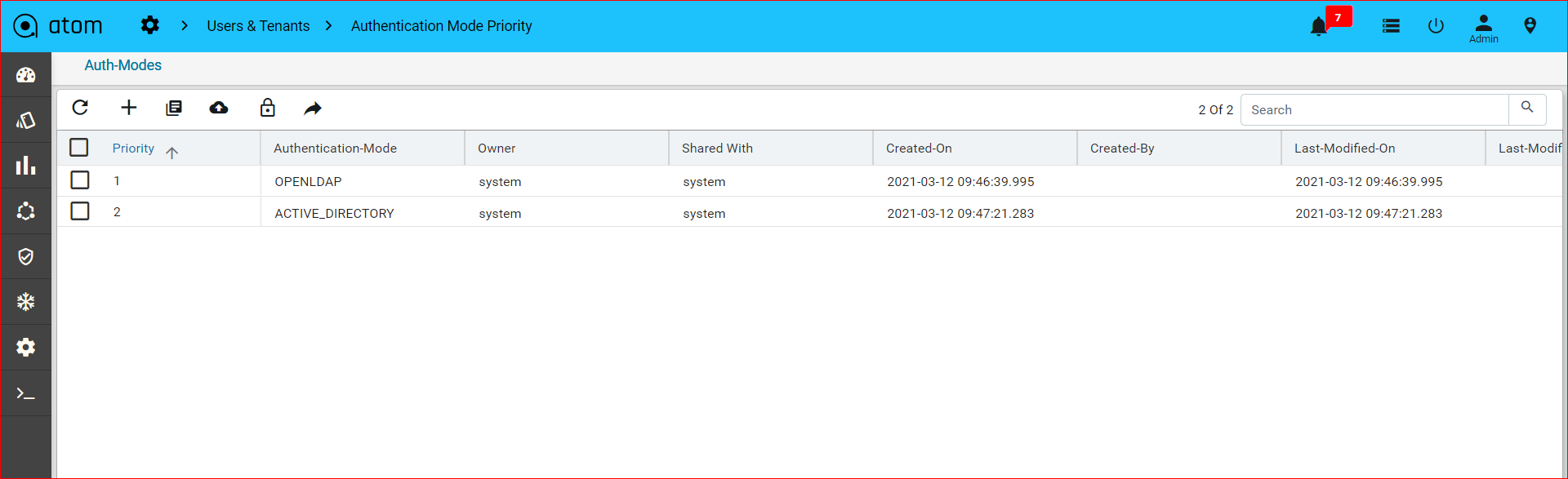
The authentication mode priority thus set can be assigned to a user at the time of creation of the user in ATOM
Managing Users
An Administrator can add local users to ATOM and configure their email accounts to receive notifications from ATOM. Apart from local users, ATOM lets its customers integrate their central authentication servers to streamline the user login process and automate administrative tasks such as user creation and role assignment. User data is synchronized from customer authentication servers into ATOM.
Prerequisite of Adding New User:
Before adding user need to follow the below required steps
Navigate to Administration->System->General setting->Edit->Smtp configuration: You have to configure an email server to send email notifications to the ATOM users.
SMTP Mail From: You can set up an external SMTP email server to send email notifications to
the ATOM users. To do so, enter values in the fields described below:
- SMTP-MAIL-FROM : Sample value like atomdev@anutanetworks.com
- SMTP Host: Sample value like smtp.gmail.com
- SMTP Port: Example 587
- SMTP Auth Required: Enable this option if authentication is required to connect to the SMTP Host
- SMTP User Name: Example atomcloud@anutanetworks.com
- SMTP Password: xxxxxx
- SMTP Encryption SSL: Disable/Enable this option according to your SMTP.
- SMTP Encryption TLS: Select this option if the connection to the SMTP server should use TLS as the authentication method
- SMTP-MAIL-TO: Example atom_qa@anutanetworks.com
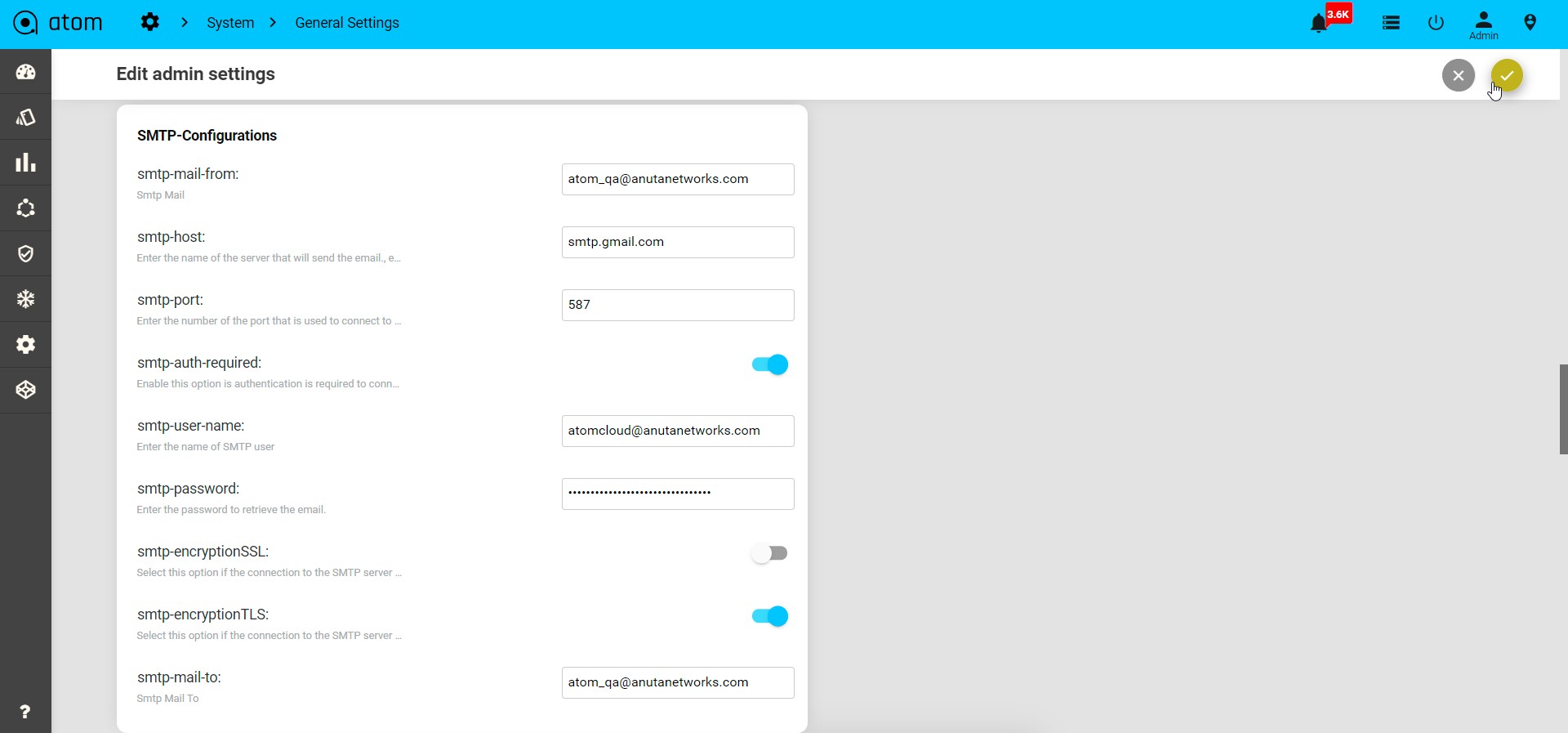
In keycloak admin has to update the smtp settings following the below steps.
 Navigate to keycloak url https://<ATOM-Master-IP>:32443/auth/:
Navigate to keycloak url https://<ATOM-Master-IP>:32443/auth/:- Click On the administration console and it goes to the login page if not given earlier. Enter the user name/password (admin/Secret@123)
- Navigate to Keycloak->System->Realm setting->Emails: Configure the below smtp setting in realm setting and save it.
- Navigate to keycloak->Master->Users->View All Users->Edit admin user: Provide any dummy Email if needed, turn on the flag for “User enabled” and save it.
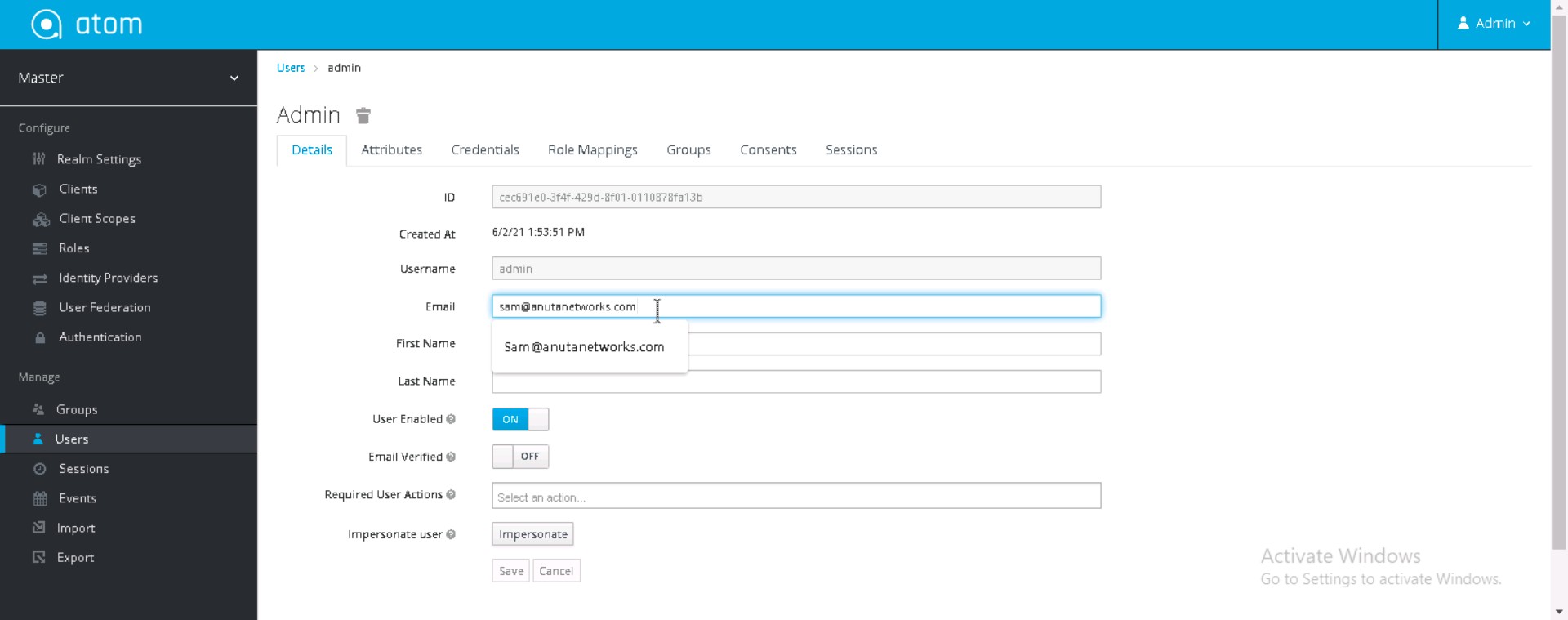
- Navigate to Keycloak->System->Realm Settings->Emails: If we click on test connectivity it should be successful.
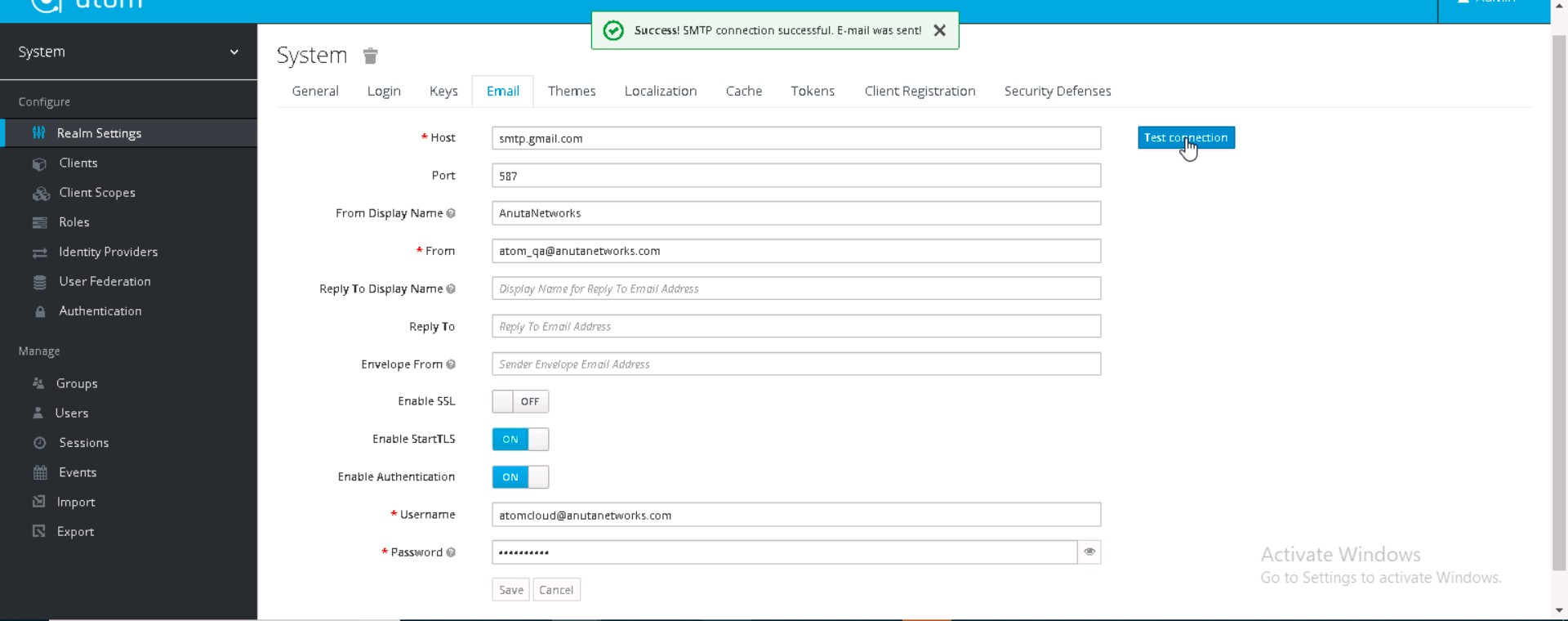
Adding a New User:
To add Users in ATOM, do the following:
-
- Navigate to Administration > Users & Tenants > Users & Roles and click Add.
-
- In the User Invitation screen, enter the values in the following fields:
- External User: Enable this button to create AD, LDAP, or TACACS users in ATOM. When this button is not enabled, a local user is created in ATOM.
- In the User Invitation screen, enter the values in the following fields:
-
-
- Add User: The administrator can invite one or more users to ATOM at once. To add more than one user, click on the + button.
-
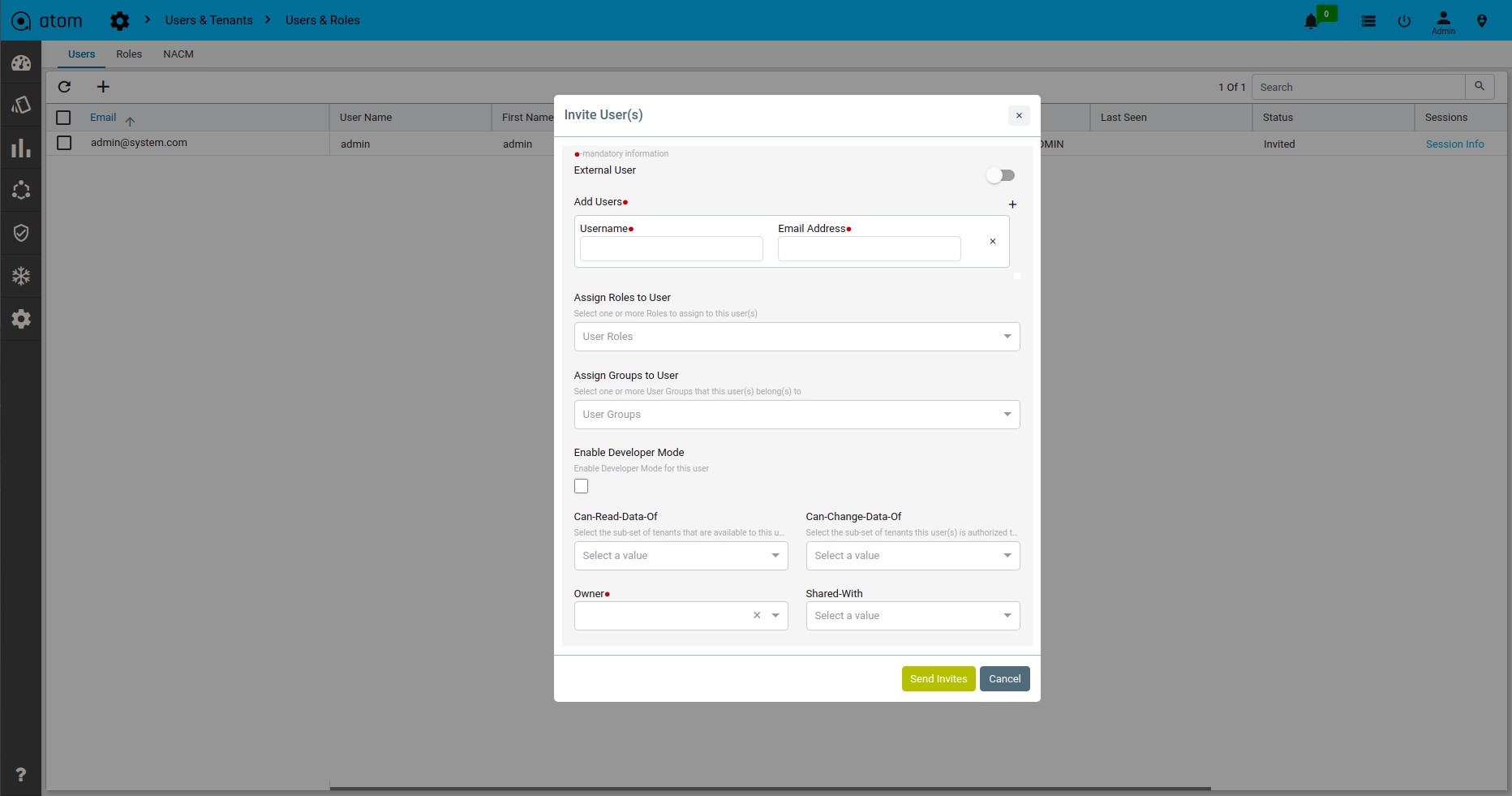
-
-
-
- Username: Enter an alphanumeric string of not more than 36 characters.
-
-
-
-
-
- Email Address: Enter a valid email ID. Invitation emails to join ATOM Cloud will be sent to this address.
- Assign Roles to User: User can be assigned relevant Role(s) from the list of system-defined Roles. Each Role is a set of system-defined permissions given to the user.
- Assign Groups to User: Users can be put into pre-defined Group(s) to apply the access control privileges on them as a whole.
- Enable Developer Mode: In developer mode users have access to many tools to work with Atom platforms.
- Can-Read-Data-Of: Select the tenants, whose data this user can read.
- Can-Change-Data-Of: Select the tenants, whose data this user can change.
- Owner: Select the owner of this user.
- Shared-With: Select the tenants with whom this user should be shared.
-
- If user creation is done, then check the mail sent to the given mail id of the new user created in ATOM for account update.
-

-
- Click on here will take to atom page and it should show new update password options
-
- Set the new password.
-
- Now new ATOM user login can login to atom UI with username/password
-
- Access to the ATOM UI page possible after login with username/password.
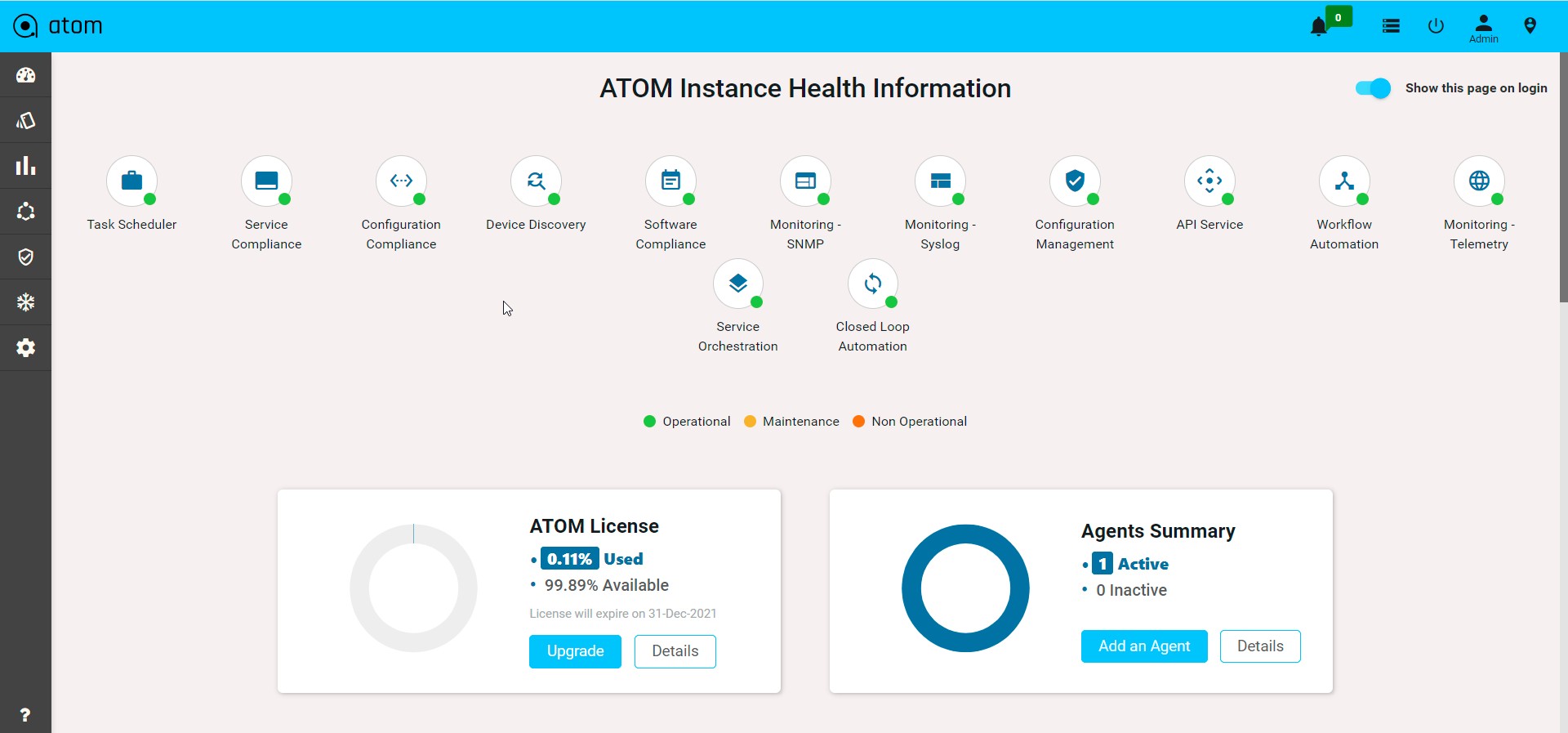
Editing an Existing User:
User details can be edited by selecting an user. When a user is edited, the user is taken to the same form seen for adding a user. However, fields such as Username, Email Address and External User are non-editable as these form the fundamental identifiers for the user.
Resend User Invite:
If the invitation to ATOM Cloud needs to be resent to the user’s email address, the administrator can select the user and click on the resend invite icon.
Block/Unblock User:
At any instance, the administrator can Enable or Disable a user account by this option. When blocked, the user will not be allowed to login to ATOM.
Assigning Role to the User
From the drop-down menu, select the role that should be assigned to the user. These roles are defined earlier as in the section, “Creating Roles”.
Creating SNMPv3 users
SNMPv3 users are required when the users or third party applications require additional authentication and access control provided by SNMPv3.
- Navigate to Administration > Users & Tenants > Add User
- In the Create user screen, click user >entities> snmpv3 in the right pane.
- In the right pane, enter values in the following fields:
-
- Authentication Protocol: Enter the mode of authentication when SNMPv3 is enabled.
- Privacy Protocol: Enter the requisite privacy protocol depending on the selected authentication protocol.
Subscribing to Events
Email notifications can be configured to be sent to the created user when a specific event or events occur in ATOM.
- Navigate to Administration > Users & Tenants > Add User
- In the Create user screen, click user >entities> event subscription in the right pane.
- Fill the values in the fields described below:
- Click Add to subscribe to a specific event or click Add all to add all the events available in ATOM.
An email is triggered and sent to the user when any of the events occur in ATOM.
You can configure the mail to be sent immediately after the occurence of the event or schedule the mail notifications to be sent at periodic intervals as illustrated in the screenshot below:
Workflow-User-Level-Authorization
If it is decided to have user level permissions what should be the default permissions? That question is answered by the global configuration at
/controller:nacm/workflow-policy-for-auto-creation-of-authorization
If it is needed to customize those permissions for a specific user? That question is answered by this model
Using this model you can use 1.enable the user level permissions
- choose to use the global default or customize Here three options are there
DISABLE:: Is the default selection.Using this option you can explicitly disable the auto creation of permission for this user.
ENABLE:Enables global defaults for this user.
READ-ONLY-PERMISSION:Enables the read only permissions out of the global defaults
OVERRIDE-GLOBAL-CONFIG:Enables user level permission creation for this user,and, for those permissions you’re going to specify here, explicitly.
-
- Navigate to Administration > Users & Tenants > Add User
- In the Create user screen, click user >entities>
workflow-user-level-permission-authorization in the right pane.
-
- By default workflow-user-level- authorization is disabled it.
Configuring NACM
By implementing NACM developed by NETCONF, ATOM enables administrators to allow or deny access to protocol operations and data to a set of users. Access Control in ATOM is achieved by a combination of “Rule-list” and “User Groups”. Rules are grouped into Rule-list and users are assigned to User Groups to control access to resources managed by ATOM.
To set the global access control settings in ATOM, do the following:
- Navigate to Administration > Users & Tenants > Users & Roles
- Click Edit to modify the global settings for access control.
As an administrator, you can set the default access control settings which are applicable to all entities in ATOM
-
- Enable NACM: Select this option to set a group of read, write, and execute options that should be applicable by default to all the entities in ATOM.
- Read Default: The default value is “permit” for all the operations/objects(Controls whether read access is granted if no appropriate rule is found particular read request)
- Write Default: The default value is “deny” for all the operations/objects(Controls whether create,update or delete access is granted if no appropriate rule is found particular write request)
- Exec Default: The default value is “permit” for all the operations/objects(Controls whether exec access is granted if no appropriate rule is found particular protocol operation request)
Adding User Groups
You can organize users to groups and apply the access control privileges on them as a whole. To create a User Group:
- Navigate to Administration >Users & Tenants >Users & Roles> click NACM
- In the Details pane, on the right, click Groups > Add Group
- Name: Enter the name for the User Group
- Select a user to this group.
Creating Rule lists
Rule lists are an aggregated list of rules created in ATOM.
- Navigate to Administration > Users & Tenants >Users & Roles> click NACM
- In the Entities pane, on the right, click Rule-list > Add(+)
- Name: Enter the text that will be used as a name for the rule list.
- Select a group (user group) to which the created rules in the Rule list should be assigned.
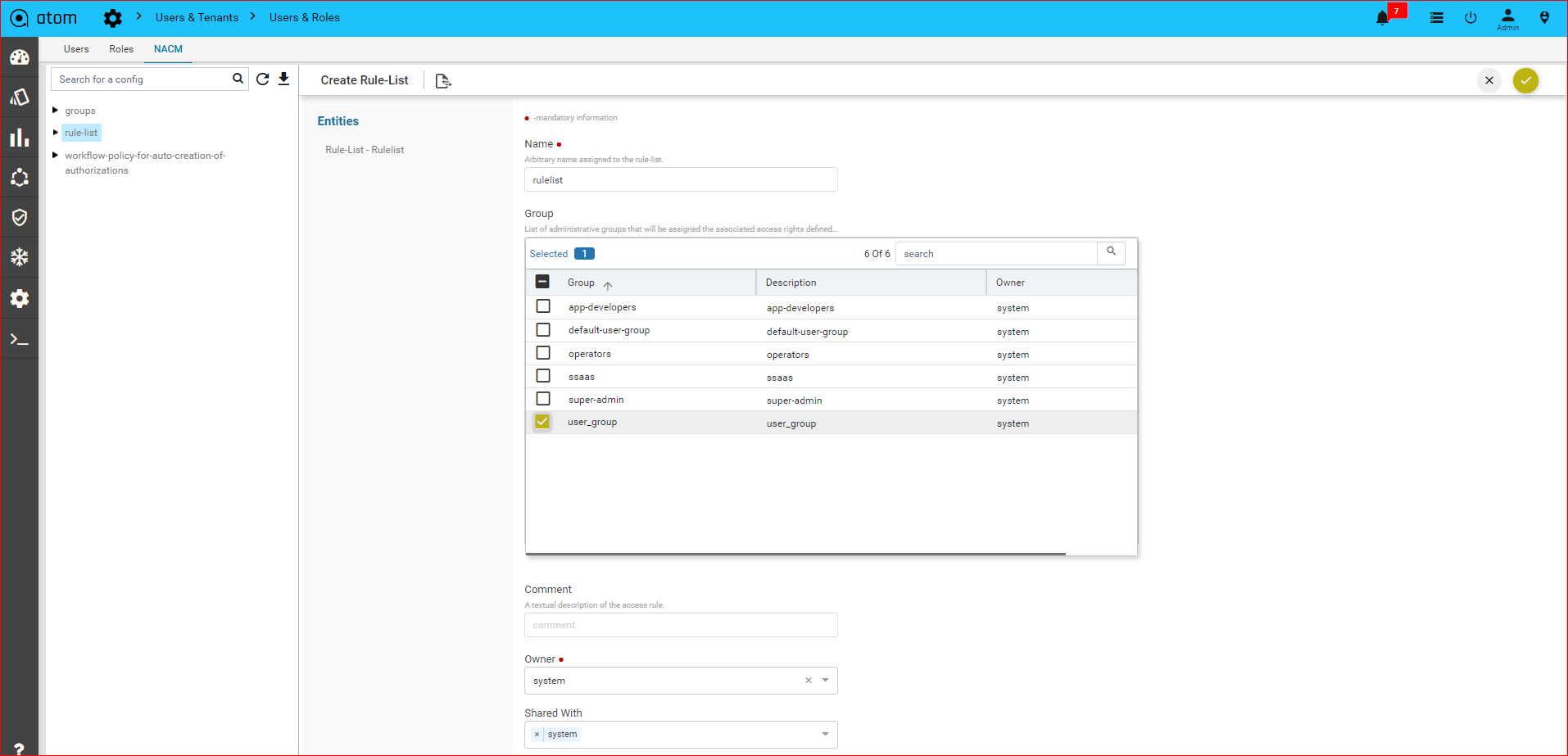
Creating Rule V2:
Rules are the conditions that identify individual objects in the system. Rules also capture whether a user of a network object should be “granted” or “denied” RPC permission.
RPC : Choose a remote procedure call (RPC) on which the access control needs to be applied.
- Click the created Rule-list > Entities > Rule V2 > Add(+)
- In the Create rule screen, enter values in the fields explained below:
Create a Rule v2, “rulev2” to be given the multiple RPCs in drop down Permit-RPC-Exec(Ex:Run device inventory, Extended inventory are etc) and Deny-RPC-Exec(Ex:Topology inventory, run dsl are etc)
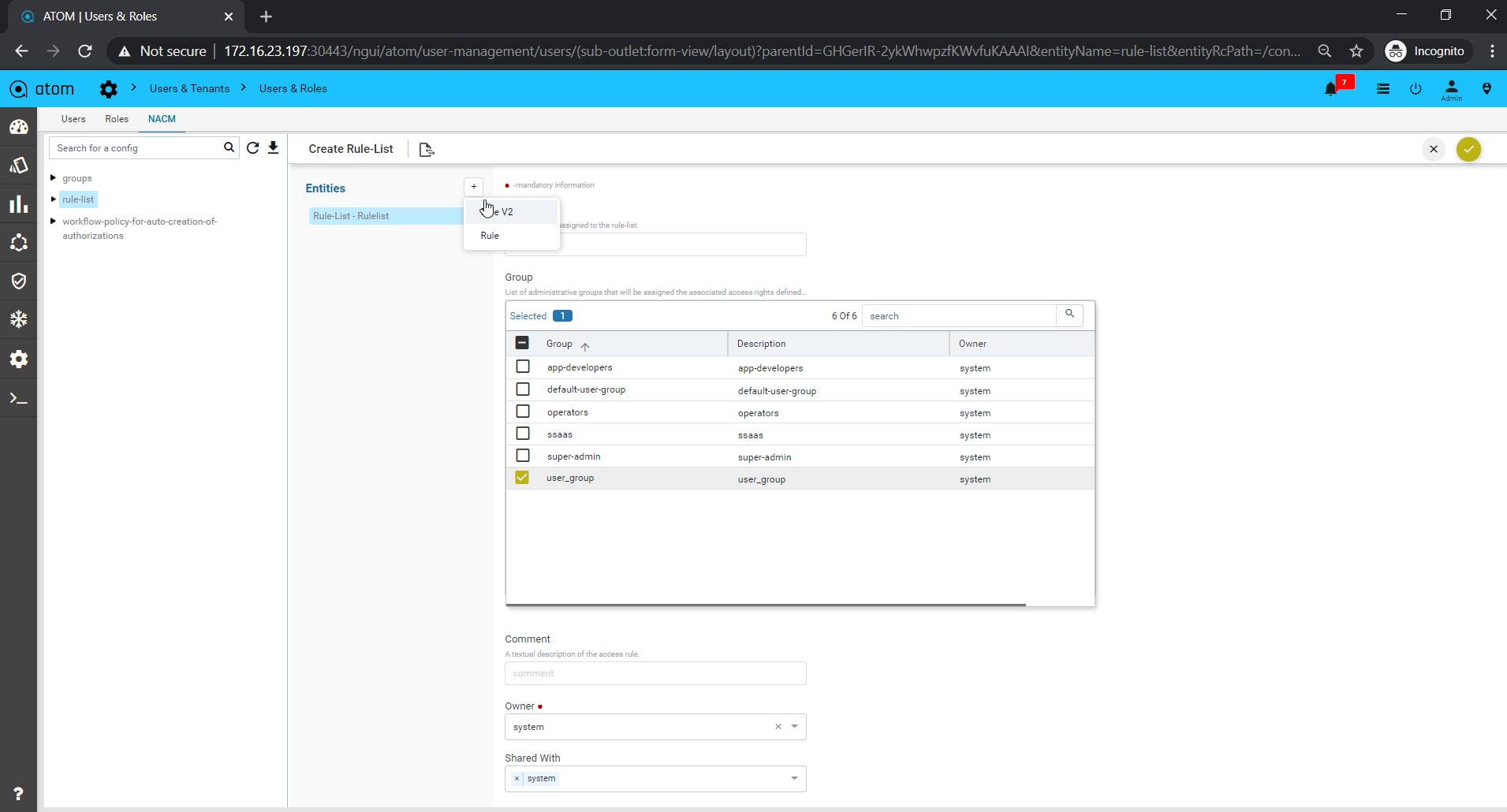
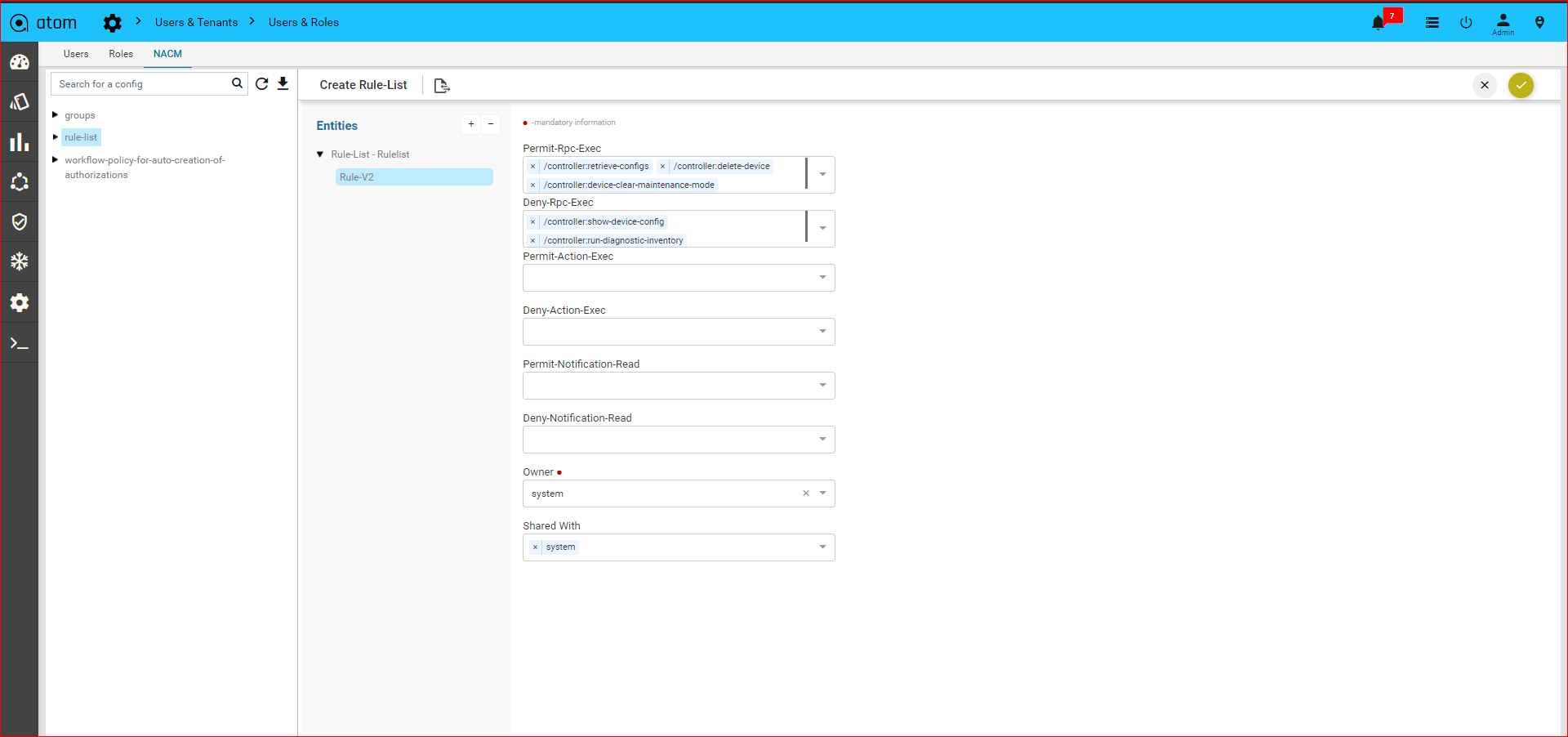
- Select a rule v2 that will be shown the below permit and deny data node,to grant either allow or deny access to the rule determined to match a particular request.
- Permit datanode
- Deny datanode
Click on rule v2 to add(+) permit data node to fill the below details:
- Id :Enter string or number(Ex:2)
- Path : Enter the path of the object in the data tree on which the rule should be applied. This is applicable only for the rule type, ‘data-node’ Select the single or multiple Data node paths
- Access operations : Select any of the operations on the ATOM entity that needs to be controlled.
- * [This symbol indicates all the operations (Create, Update, Delete, Read) are included]
- Create read update delete
- Read create
- Read update
- Read delete
- Various operation to be tested
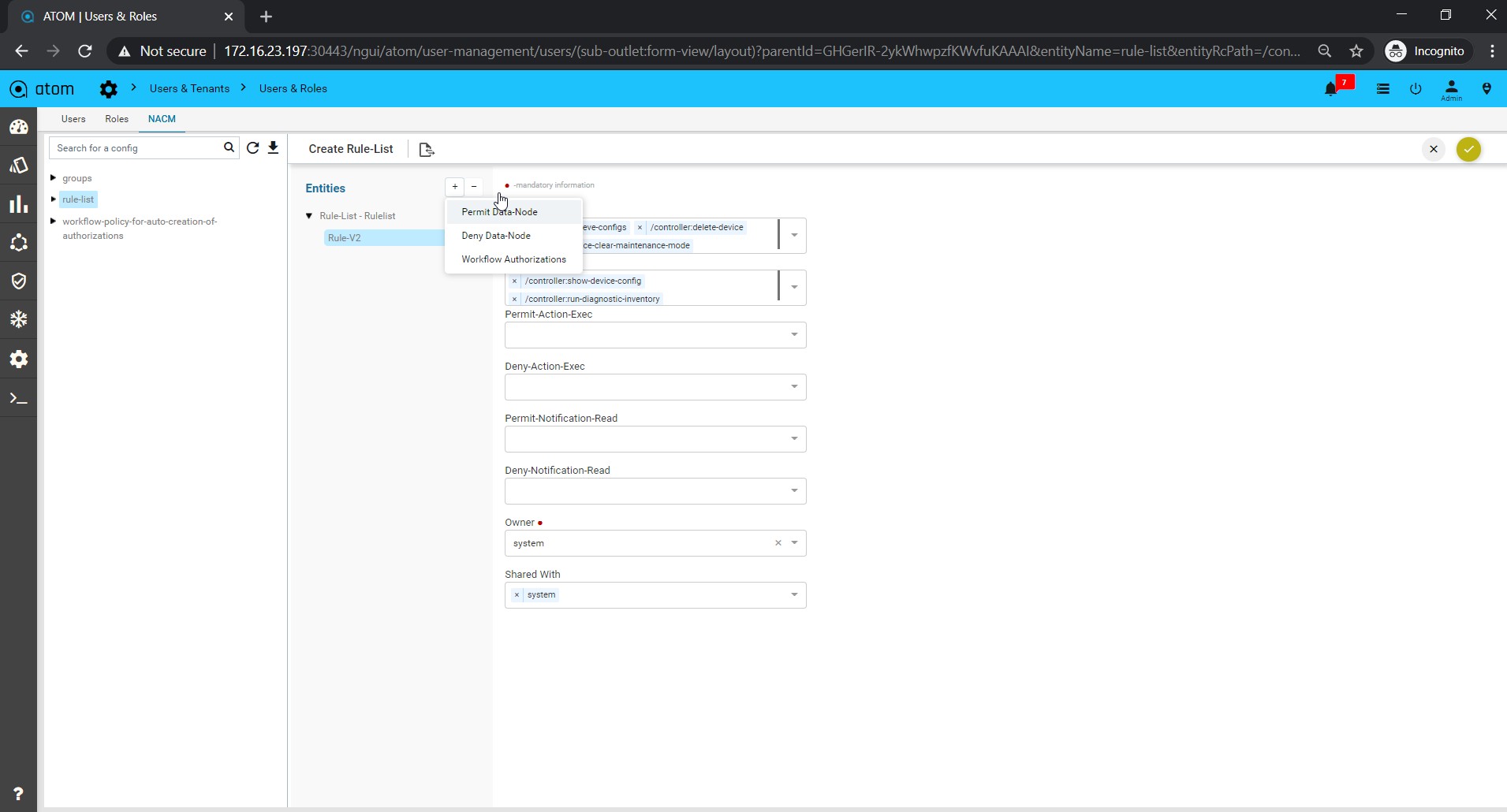
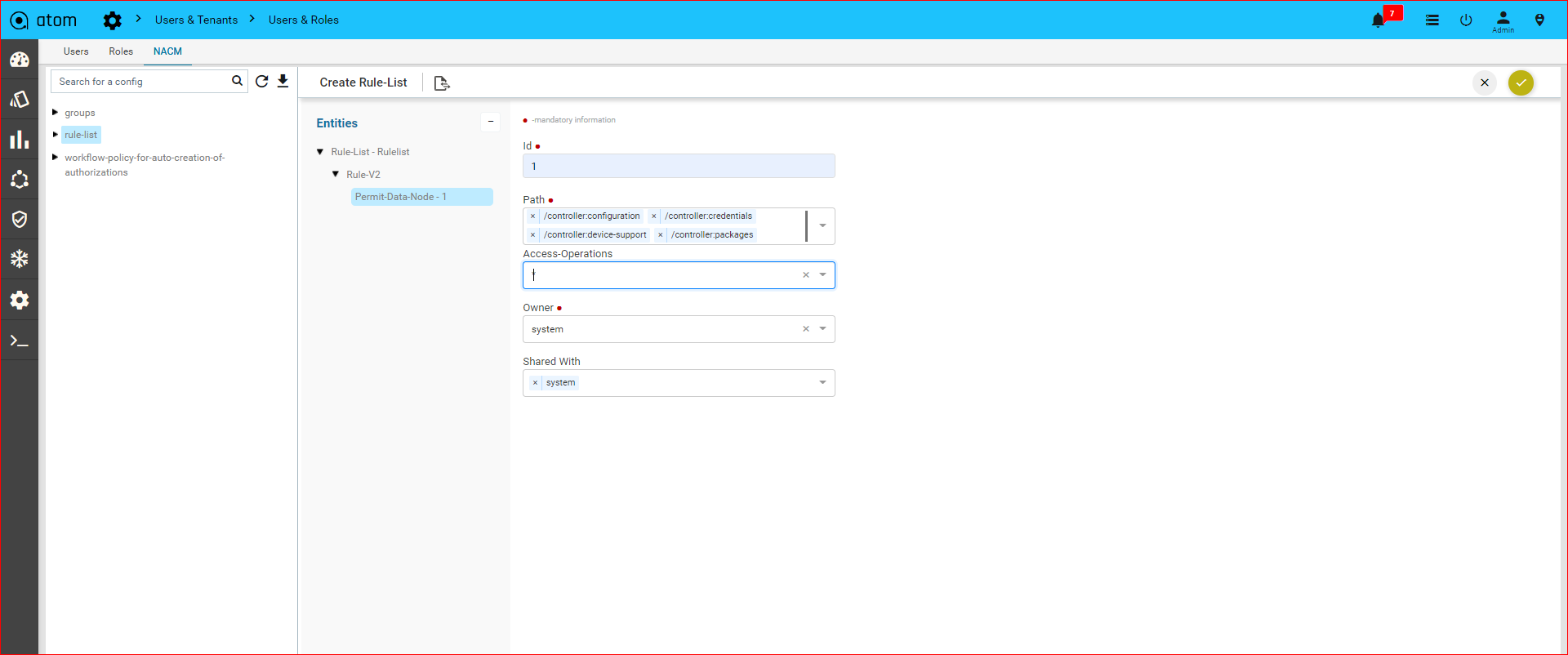
Click on rule v2 to add(+) deny data node to fill the below details:
- Id :Enter string or number(Ex:3)
- Path : Enter the path of the object in the data tree on which the rule should be applied. This is applicable only for the rule type, ‘data-node’ Select the single or multiple Data node paths
- Access operations : Select any of the operations on the ATOM entity that needs to be controlled.
- * [This symbol indicates all the operations (Create, Update, Delete, Read) are included]
- Create read update delete
- Read create
- Read update
- Read delete
- Various operation to be tested
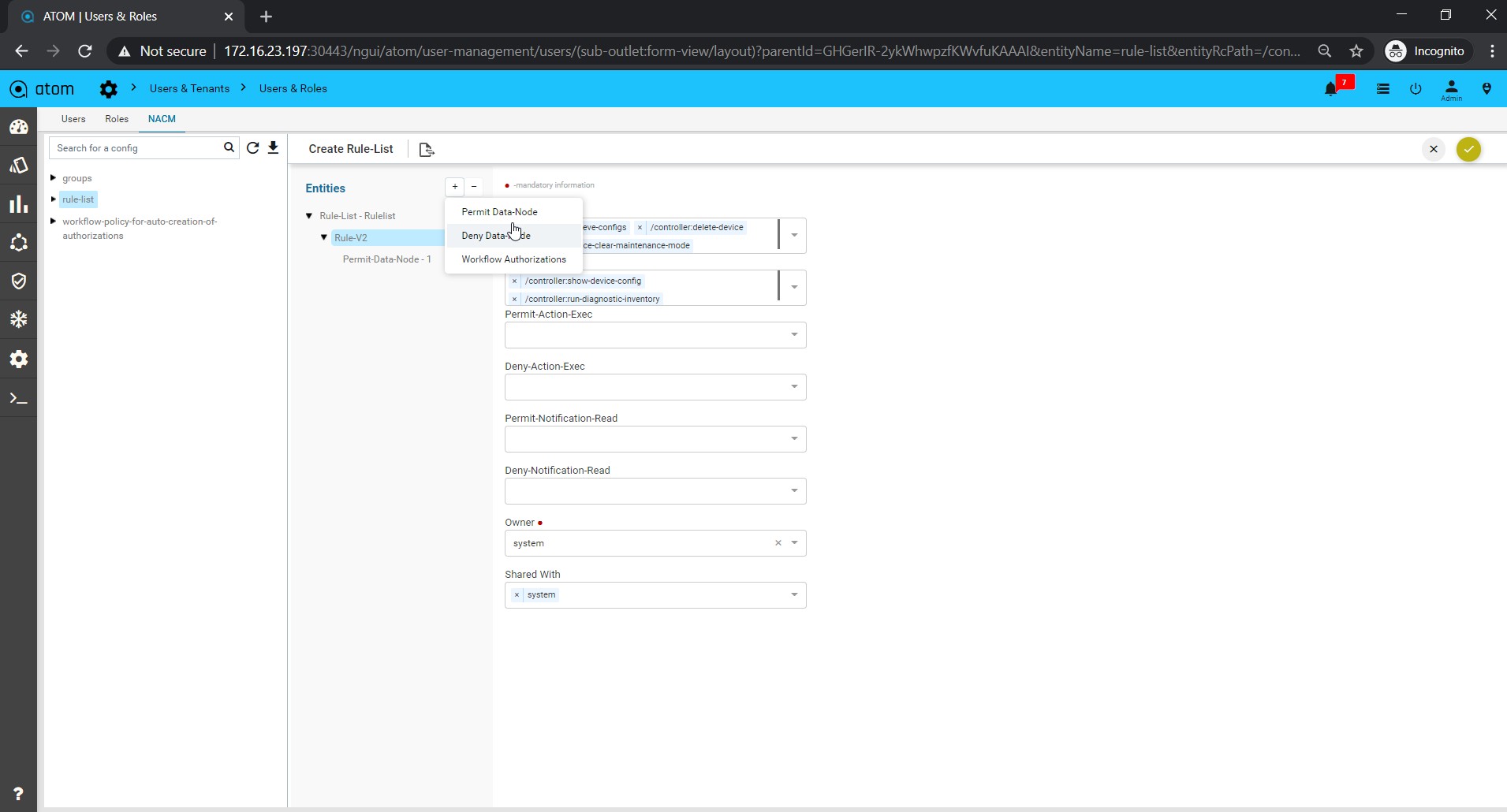
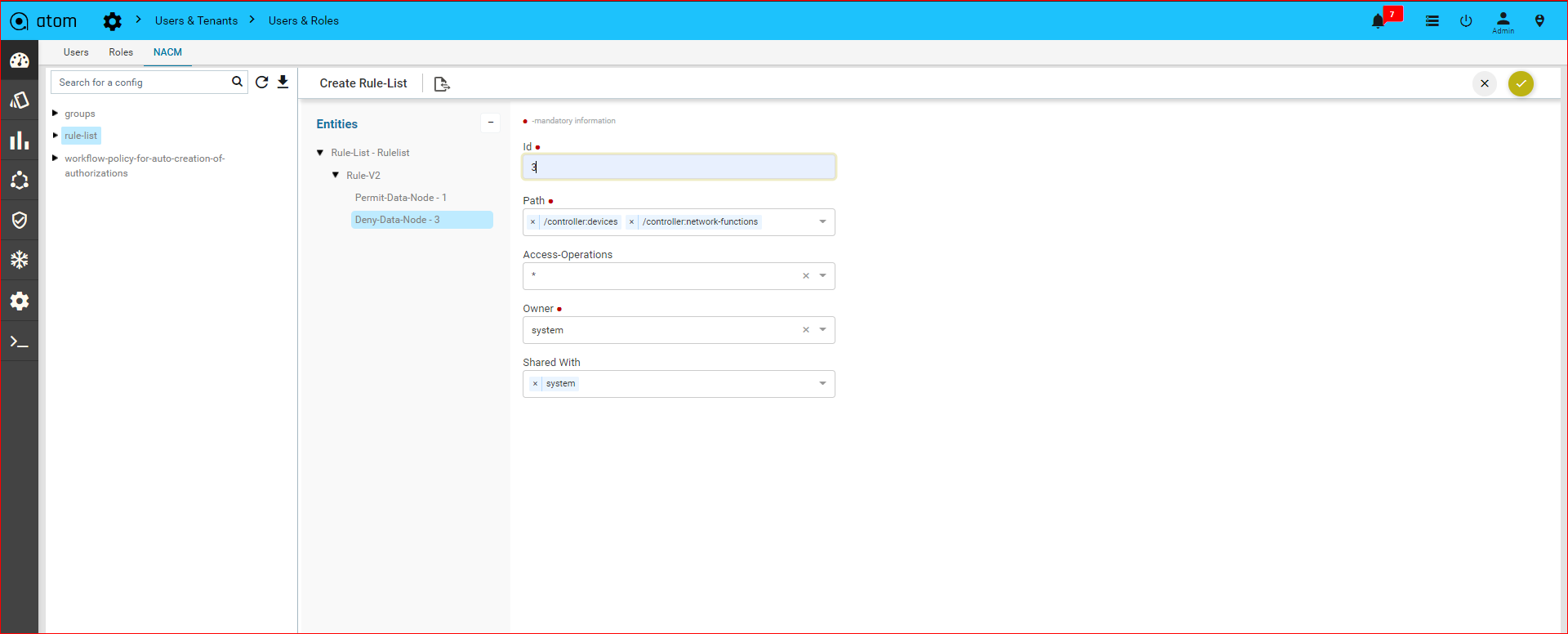
Workflow Authorization under rule v2:
Camunda allows users to authorize access to the data it manages. This makes it possible to configure which user can access which process instances, tasks, etc…If it is needed to customize those permissions for a specific workflow user
Deployment: The option is weather package is upload/load/unload and delete the package Click on Workflow authorization to add(+) to fill the below details for Deployment:
- Id :Id is the hardcoded
- Resource type : Select the resource type is Deployment
- Resource id : Select (*) from resource id drop down to be accessed by all packages or any specific package resource id.
- Grant type:
- Grant:Ranges over users and groups and grants a set of permissions. Grant authorizations are commonly used for adding permissions to a user or group that the global authorization revoked.
- Revoke::Ranges over users and groups and revokes a set of permissions. Revoke authorizations are commonly used for revoking permissions to a user or group that the global authorization grants.
- User group: You can select a subset of groups to mapped it.
- Permissions: A Permission defines the way an identity is allowed to interact with a certain resource. (ALL,Create, Read, Delete)
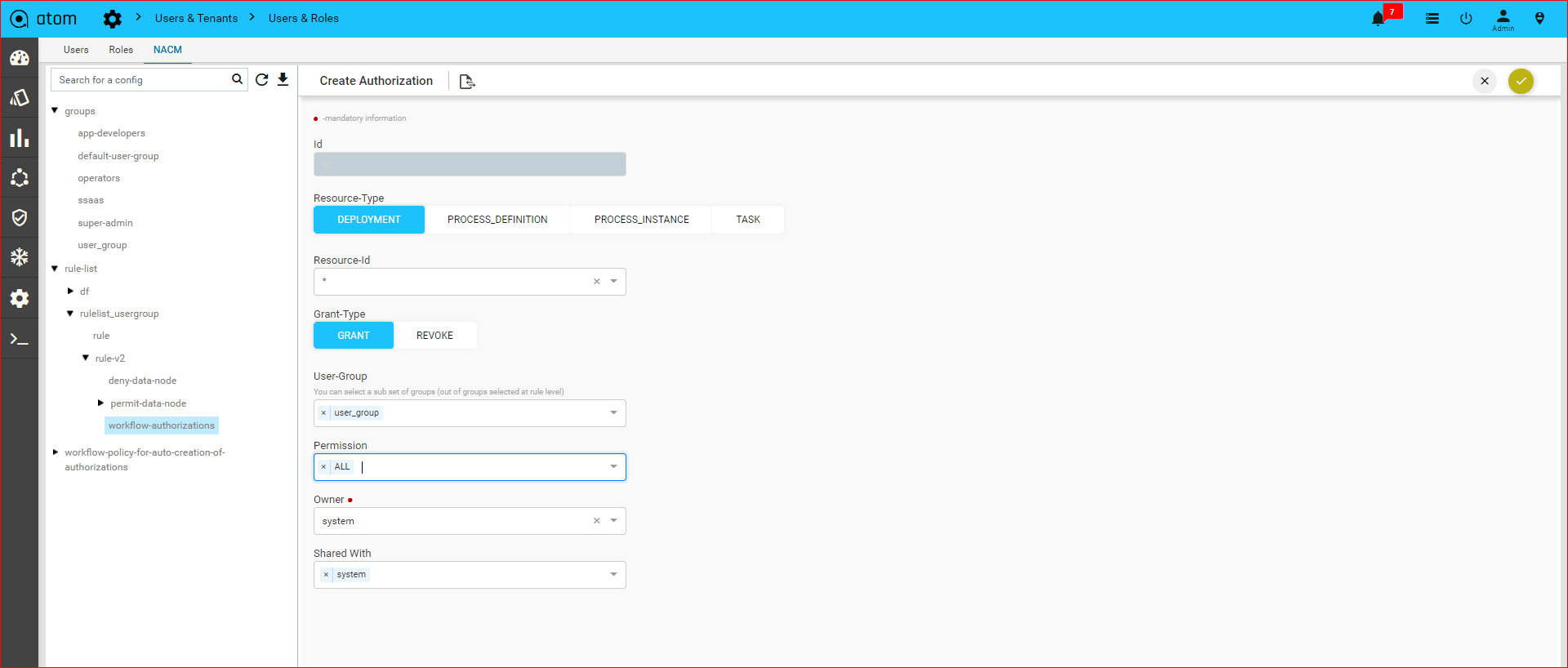
Process definition: This option is access the workflow grid with specific workflow or all based on given process definition
Click on Workflow authorization to add(+) to fill the below details for process definition:
- Id :Id is the hardcoded
- Resource type : Select the resource type is process definition
- Resource id : Select (*) from resource id drop down to be accessed by all workflows or give any specific workflow of resource id.
- Grant type:
- Grant:Ranges over users and groups and grants a set of permissions. Grant authorizations are commonly used for adding permissions to a user or group that the global authorization revoked.
- Revoke::Ranges over users and groups and revokes a set of permissions. Revoke authorizations are commonly used for revoking permissions to a user or group that the global authorization grants.
- User group: You can select a subset of groups to mapped it.
- Permissions: A Permission defines the way an identity is allowed to interact with a certain resource.Choose the various permission (ALL,Create instance, Read, Delete-instance,Update-instance,update-history,Migrate-instance,Update-task-variable, Update-task)
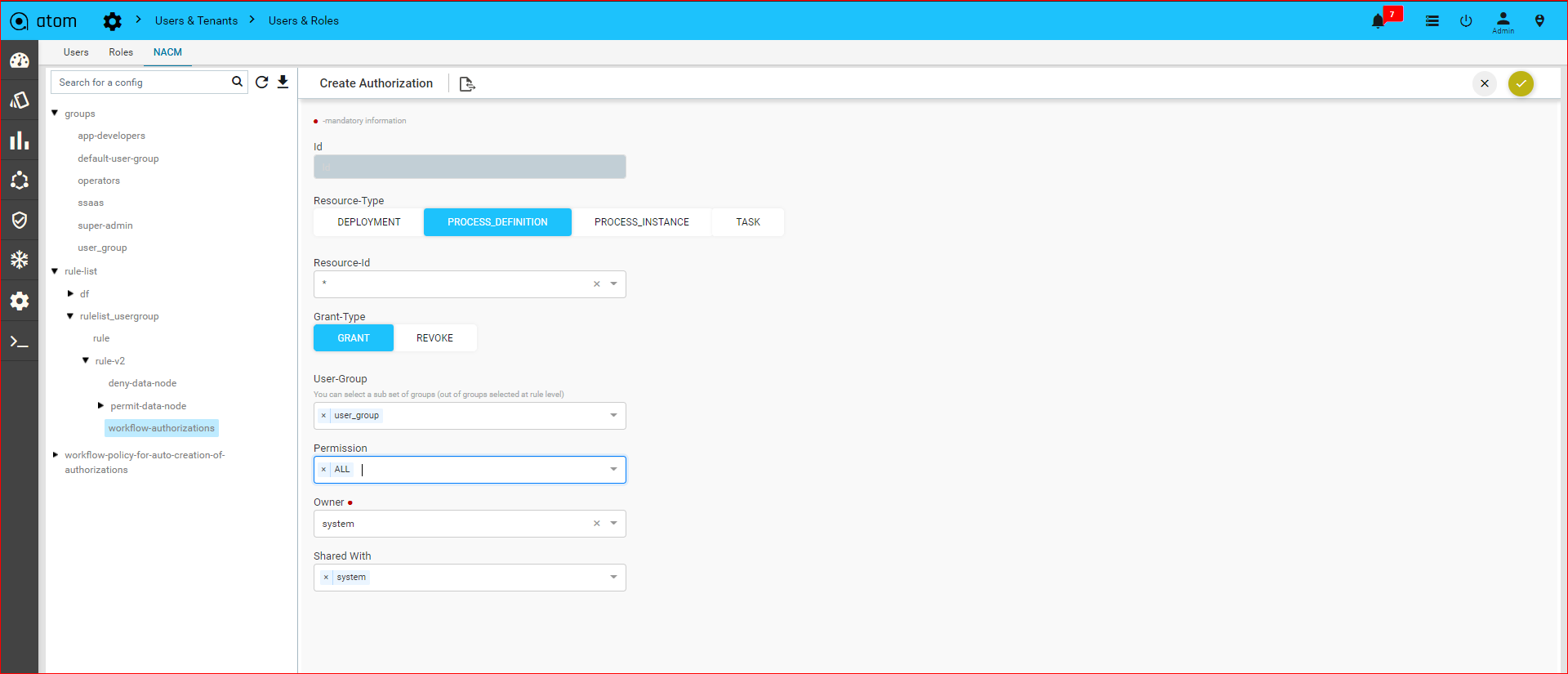
Workflow instance: This option is a workflow instance and is a running instance of a workflow definition.
Click on Workflow authorization to add(+) to fill the below details for Workflow instance
- Id :Id is the hardcoded
- Resource type : Select the resource type is Workflow instance
- Resource id : Select (*) from resource id drop down to be accessed by all workflow instances or any specific workflow instance of resource id.
- Grant type:
- Grant:Ranges over users and groups and grants a set of permissions. Grant authorizations are commonly used for adding permissions to a user or group that the global authorization revoked.
- Revoke::Ranges over users and groups and revokes a set of permissions. Revoke authorizations are commonly used for revoking permissions to a user or group that the global authorization grants.
- User group: You can select a subset of groups to mapped it.
- Permissions: A Permission defines the way an identity is allowed to interact with a certain resource. Choose the various permission(ALL,Create, Update,Read, Delete)
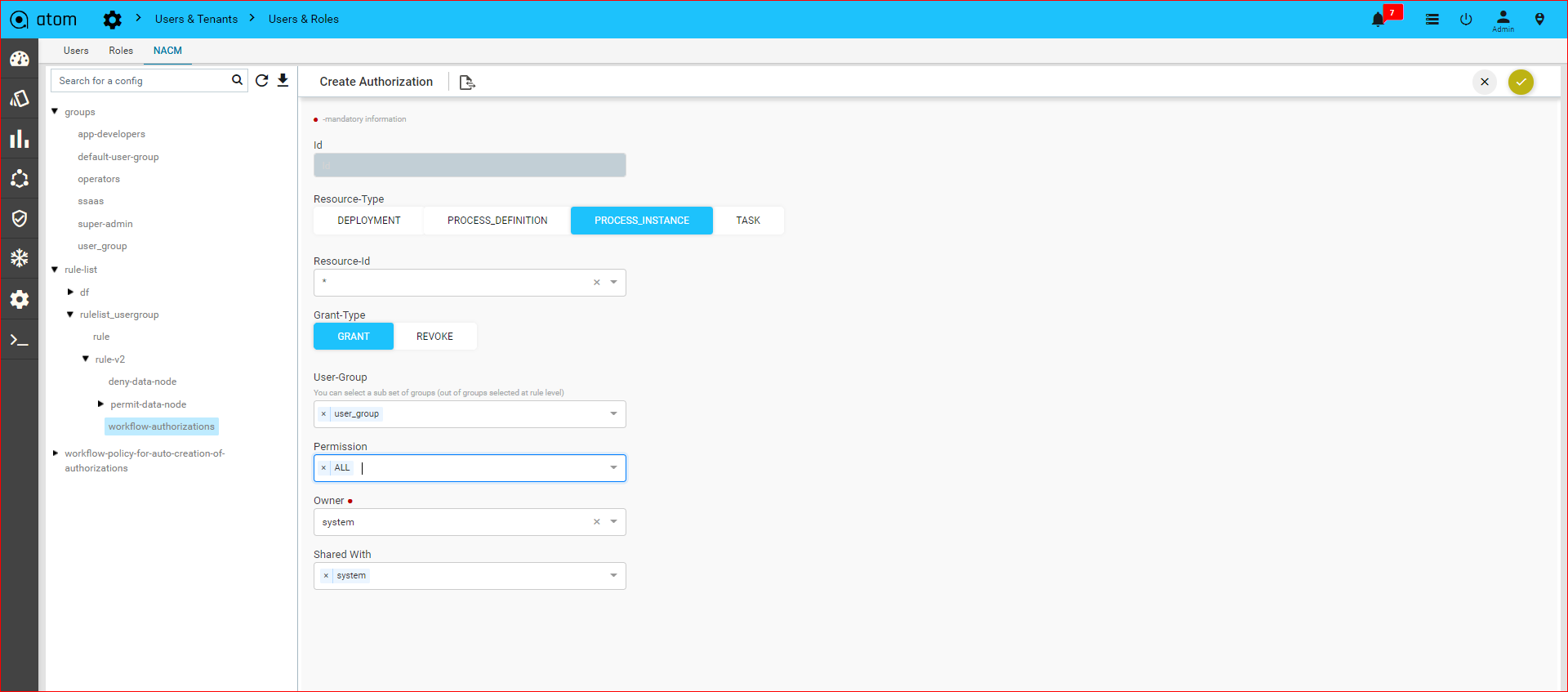
Tasks: This option is a user can perform different actions on a task, like assigning the task, claiming the task or completing the task. If a user has “Update” permission on a task (or “Update Task” permission on the corresponding process definition) then the user is authorized to perform all these task actions
Click on Workflow authorization to add(+) to fill the below details for Task
- Id :Id is the hardcoded
- Resource type : Select the resource type is Task
- Resource id : Select (*) from resource id drop down to be accessed by all workflow tasks or any specific workflow task of resource id.
- Grant type:
- Grant:Ranges over users and groups and grants a set of permissions. Grant authorizations are commonly used for adding permissions to a user or group that the global authorization revoked.
- Revoke::Ranges over users and groups and revokes a set of permissions. Revoke authorizations are commonly used for revoking permissions to a user or group that the global authorization grants.
- User group: You can select a subset of groups to mapped it.
- Permissions: A Permission defines the way an identity is allowed to interact with a certain resource.Choose the various permission(ALL,Create, Update,Read, Delete,Read-History,Task-Assign,Task-Work)
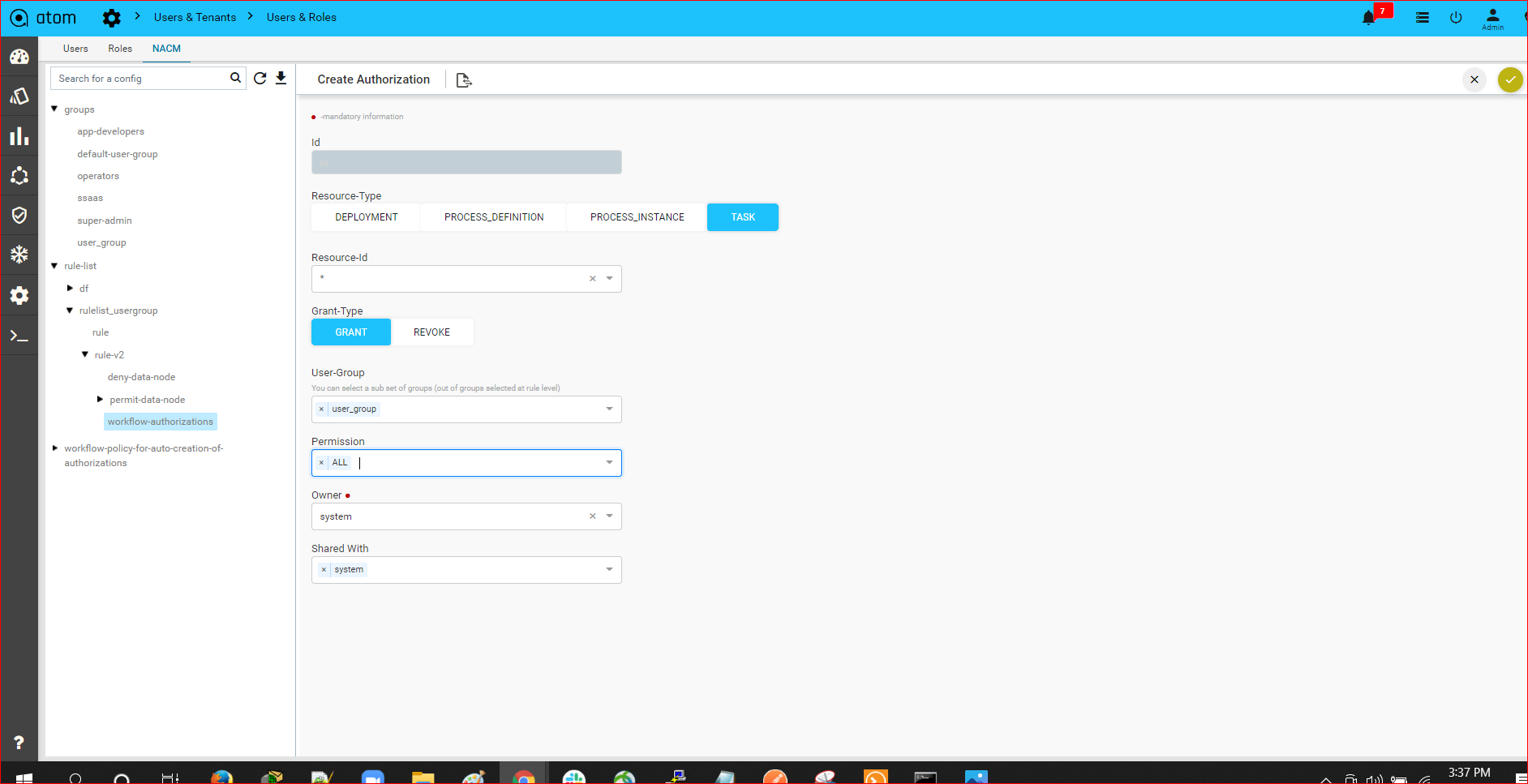
Note:: Need to be given the permit rpc exec in rule v2 based on given workflows & follow the workflow payload
<permit-rpc-exec>/disney_ipv6_api:ipv6-junos-routing</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_api:isis-routing</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_api:servicemodel_update</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_config:append-task-details</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_config:execute-command</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_config:ipv6-addition</permit-rpc-exec>
<permit-rpc-exec>/disney_ipv6_config:ipv6-routing</permit-rpc-exec>
<permit-rpc-exec>/configarchive:config-diff</permit-rpc-exec>
<workflow-authorizations/>
<permit-data-node>
<id>1</id>
<access-operations>read create update delete</access-operations>
<path>/ipam:ipv6-pools</path>
</permit-data-node>
<permit-data-node>
<path>/controller:devices</path>
<id>2</id>
<access-operations>*</access-operations>
</permit-data-node>
</rule-v2>
</rule-list>
<group-level-workflow-authorizations>
<authorization>ID:3585112 GRANT PROCESS_DEFINITION ipv6_configs [ALL]</authorization>
<authorization>ID:3591653 GRANT PROCESS_DEFINITION
interface_ipv6_configuration [ALL]</authorization>
<authorization>ID:3610357 GRANT PROCESS_DEFINITION
ipv6_routing_configuration [ALL]</authorization>
<authorization>ID:3611232 GRANT PROCESS_DEFINITION bgp_peer_configuration [ALL]</authorization>
<authorization>ID:3585054 GRANT PROCESS_INSTANCE * [ALL]</authorization>
Integrating ATOM with Central Authentication Systems
By integrating with central authentication systems such as LDAP, AD or TACACS, the users created in these servers can login to ATOM using their credentials created in their respective servers.
Managing Active Directory Users()
You can import users of Active Directory into ATOM and manage them as other users of ATOM.
For secure communication between the AD server and ATOM, import the security certificate into ATOM.
- Navigate to Administration >Users & Tenants > Active Directory
- In the Create Active Directory screen, enter the following:
- URL: Enter the URL address of the Active Directory(Ex:ldap://172.16.2.223)
- Domain: Enter the name of the domain(Ex:anutadev.com)
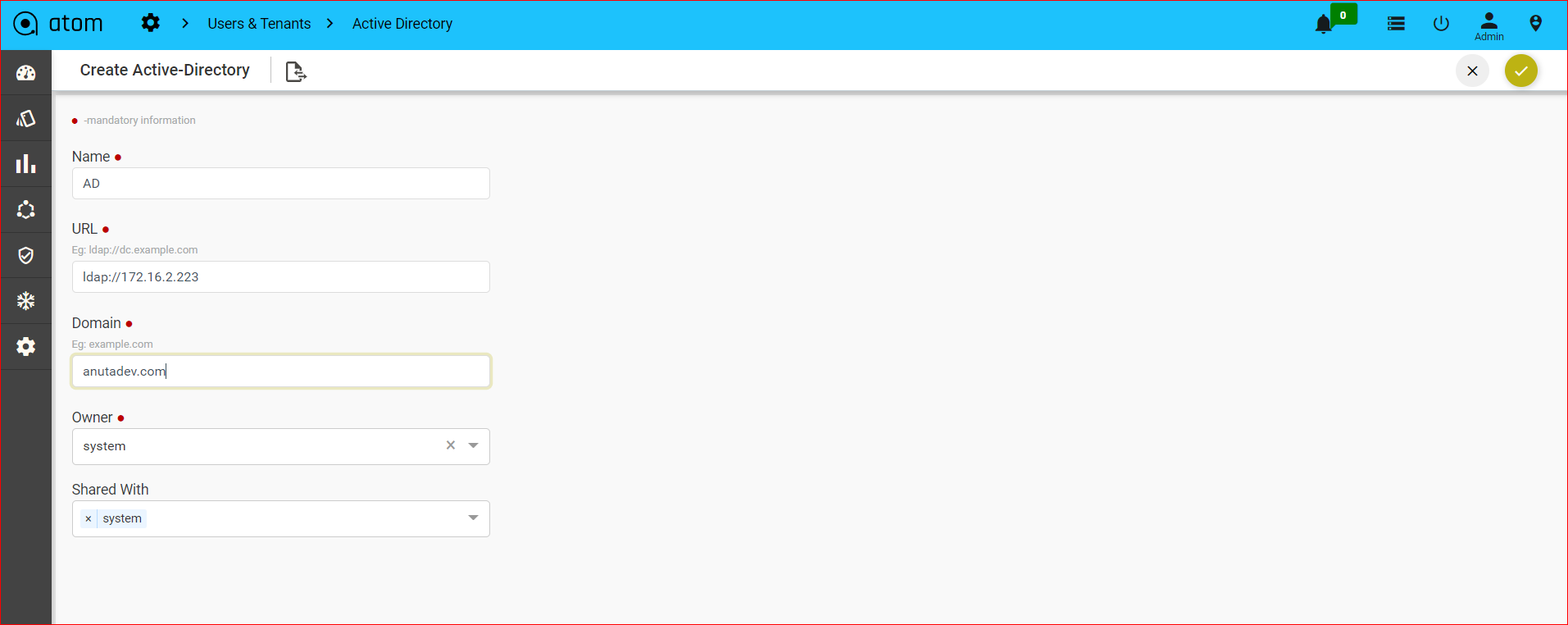
-
- Click Test Connectivity to test the connection between the ATOM and the AD servers.
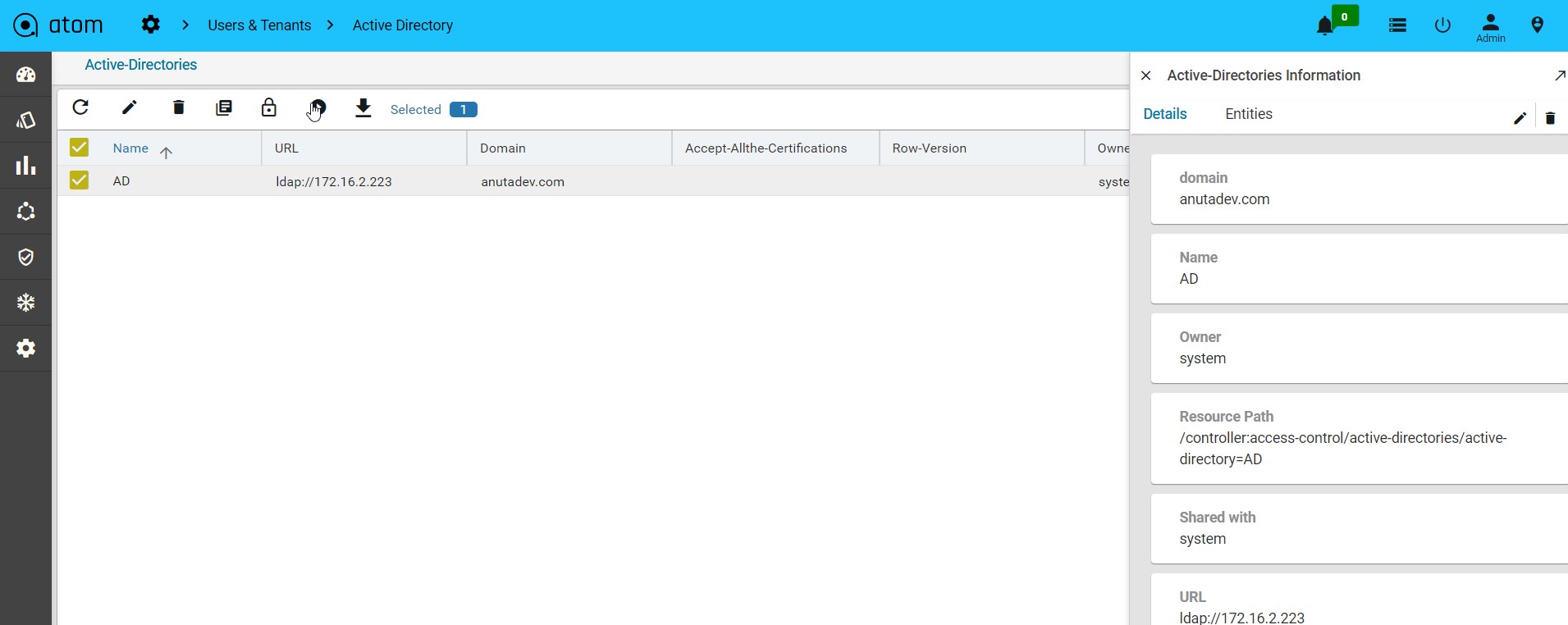
Managing OpenLDAP Users
You can import the existing LDAP users and user groups of a tenant, thus enabling the tenant users to login to ATOM using their LDAP credentials.
Importing OpenLDAP Users:
Before you begin, ensure that the following conditions are met with:
- Users and groups are created in the LDAP server
- OpenLDAP users are created as Tenants in ATOM To create LDAP users in ATOM:
- Navigate to Administration > Users & Tenants > OpenLDAP
- Click Add
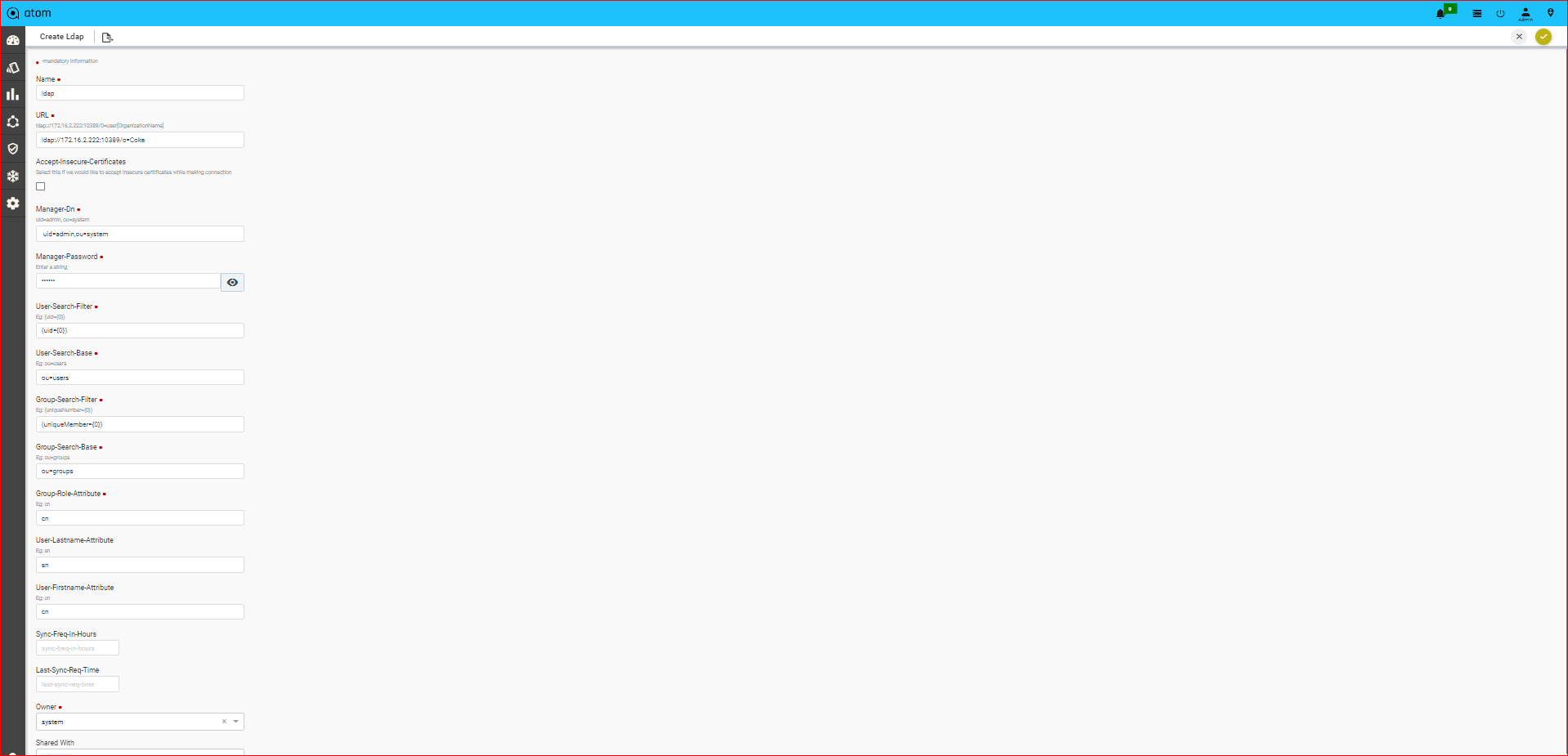
- In the Create OpenLDAP screen, enter the values in the following fields:
- URL: Enter the LDAP URL of the tenant. Include port number and base distinguished name (DN)
Example: “ldap://localhost:10389/o=nCloud”
-
- Manager Dn: Type the distinguished name (DN) of LDAP manager. This manager should have at least read permission.
Example: “uid=admin, ou=system”
-
- Manager Password: Type a password for the entered DN. Example: secret
- User Search Filter: Specify a search filter. This field determines the query to be run to identify the user record. Always include a query in brackets ‘(‘ ‘)’. Example: “(uid={0})”
- User Search Base: Specify a relative DN (from the root/base DN) where users are located. Example: “ou=users”
NOTE: In LDAP, {0} is a placeholder (token) for login user ID.
-
-
- Group Search Filter: This field determines the query to be run to identify the user in a group. Always include a query in brackets ‘(‘ ‘)’. Example: “(uniqueMember={0})”
- Group Search Base: Specify a relative DN (from the root/base DN) where user groups are located. Example: “ou=groups”
- Group Role Attribute: Specify the attribute name of role in a group. Example: “cn”
-
-
-
- User-Lastname Attribute: Attribute that contains user’s last name. Example: “sn”
- User- Firstname Attribute: Attribute that contains user’s first name. Example: “cn”
- Sync-Freq-in-Hours: Type the interval, in hours, at which ATOM should query the AD/LDAP directory to schedule an automatic update.
-
- Last-Syn-Req-Time: The timestamp of the last successful synchronization with the LDAP server is displayed.
After adding the LDAP user in ATOM, click Test Connectivity to check the connectivity between the ATOM server and LDAP server.
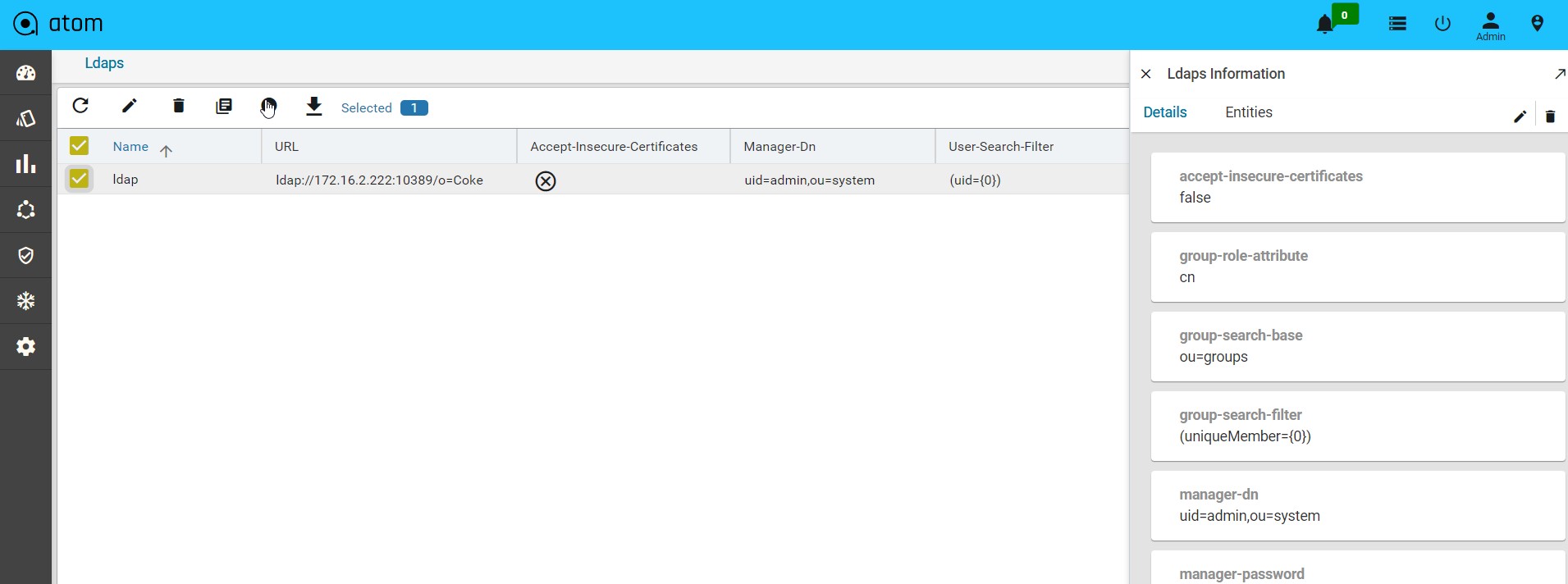
Managing TACACS Users
By integrating TACACS with ATOM, you can achieve a unified authentication system so that the same login credentials (username and password) can be used to access not only for managing network devices but for UNIX and Linux servers too. Therefore, the permissions and privileges to access the devices can be assigned and delegated through ATOM as systems rights.
To integrate the ATOM with TACACS, do the following:
- Navigate to Administration > Users & Tenants > TACACS > Add
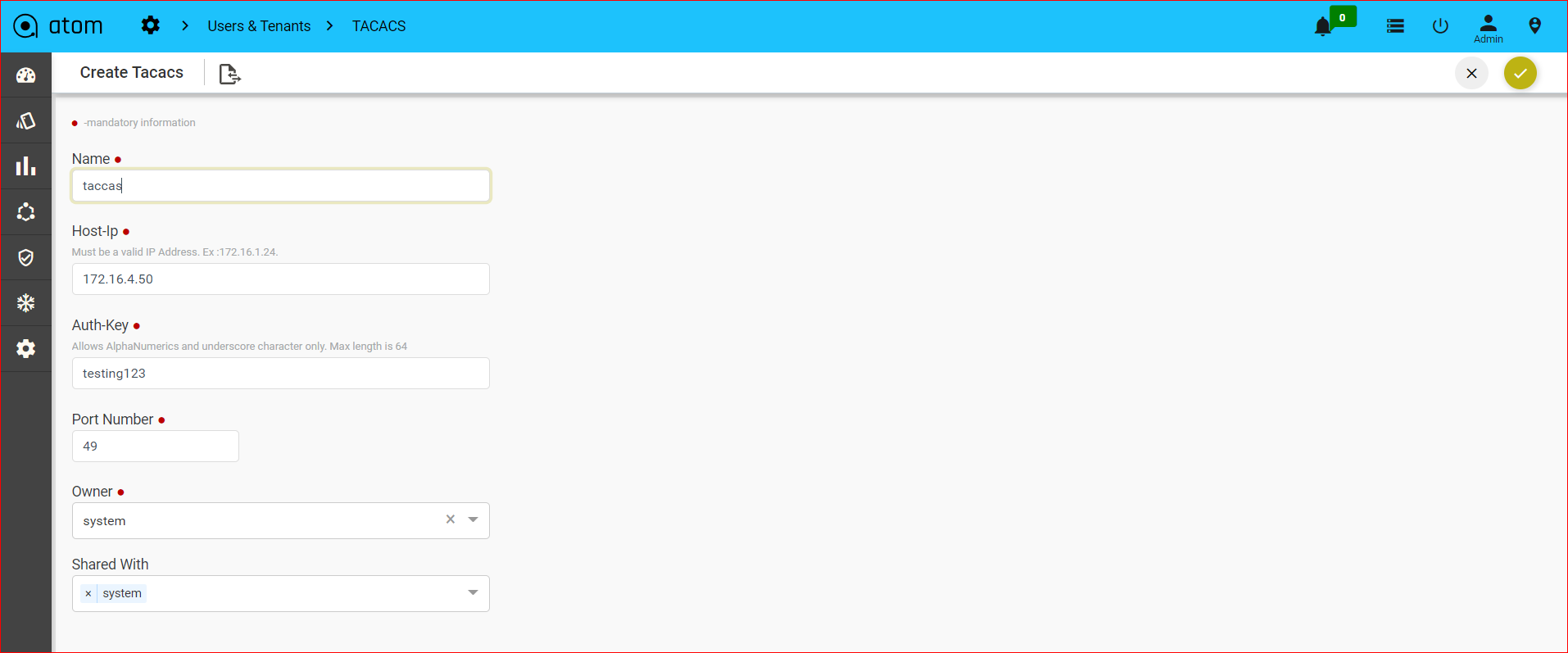
- In the Create TACACS screen, enter values in the following fields:
- Host Name: Enter the IP address of the host, which is hosting the TACACS server(172.16.4.50)
- Auth Key: Enter the key used to specify an encryption key for encrypting and decrypting all traffic between the ATOM server and the TACACS server(testing123)
- Port Number: Enter the TCP port number to be used when making connections to the TACACS+ daemon.The default port number is 49.
- Click the Test Connectivity button to test the connection between the ATOM and the TACACS servers(enter the name and the password to validate this connection).
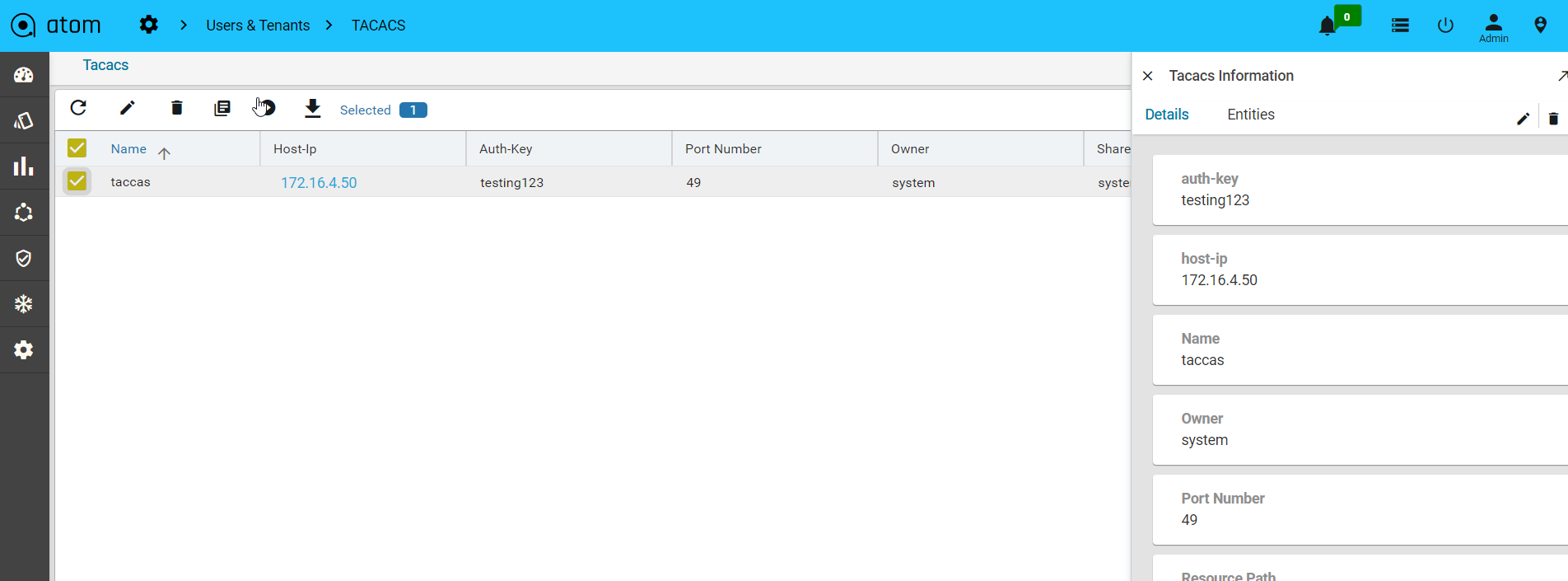
Customizing the Dashboard using DSL
DSL, Domain Specific Language, developed by Anuta can be used for representation and visualization of data derived from the devices managed by ATOM. DSL taps into YANG models, platform or third-party APIs to express code for model pre and post condition specification, rule expressions, rule logic, and RPC implementation logic. Some of the advantages that you can enjoy by implementing DSL are no more manual JAVA or Python code to carry out simple validations, side effect processing, ability to offer richer expressions than xpath 1.0 used by YANG, static analysis of business logic, side- effect analysis, advanced user experience, and ability to change logic on a live system.
Starting from the 7.x release, Dashboard, the landing page of ATOM, is organized into dashlets.
A dashlet is an individual component that can be added to or removed from a dashboard. Each dashlet is a reusable unit of functionality, providing a summary of the feature or the function supported by ATOM and is rendered as a result of the custom queries written in DSL.
You can customize the look of the Dashboard, by adding the dashlets of your choice, and dragging and dropping (the extreme right corner of the dashlet) to the desired location on the dashboard.
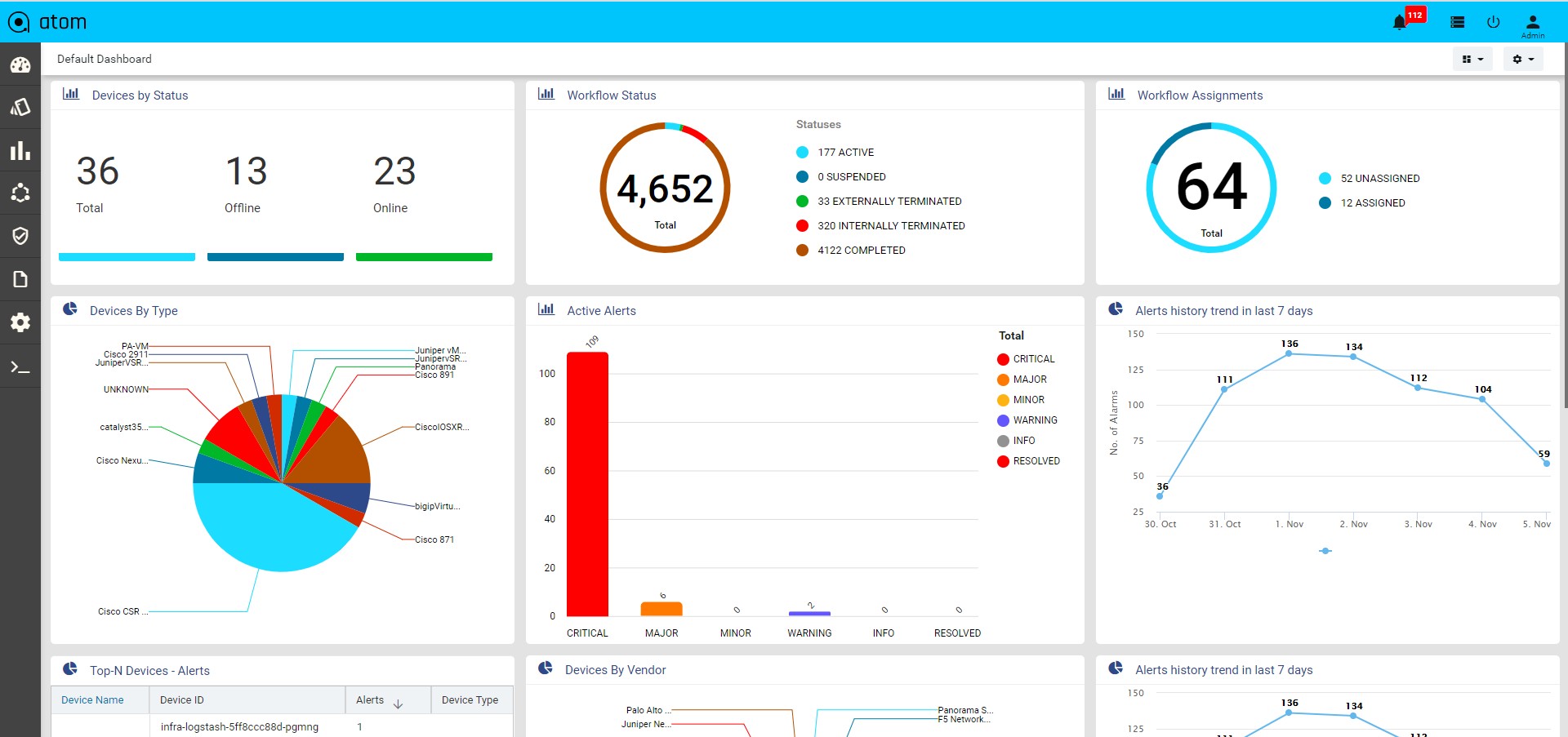
Each dashlet contains the summary or the overview of the feature or the functionality supported by ATOM.
For example, the dashlet “Device” displays the summary of devices managed by ATOM. Some of the statistics that can be of the interest in this dashlet could be as follows:
- Total number of devices
- Number of online devices
- Number of offline devices
These statistics can be gathered by ATOM and displayed in the corresponding dashlet depending on the DSL query written for each of them. For information about writing DSL queries, refer the section, “Writing DSL Queries”
You can save the layout containing the dashlets of your choice and set in a particular order.
Writing DSL Queries
- For writing any new DSL query in the editor, browse to Developer Tools > DSL > DSL Editor.
Sample DSL Query
Below is a sample DSL which will display Total/Offline/Online devices in ATOM as a card layout
- Click to Run button on the top of the editor to check if DSL is working as expected.
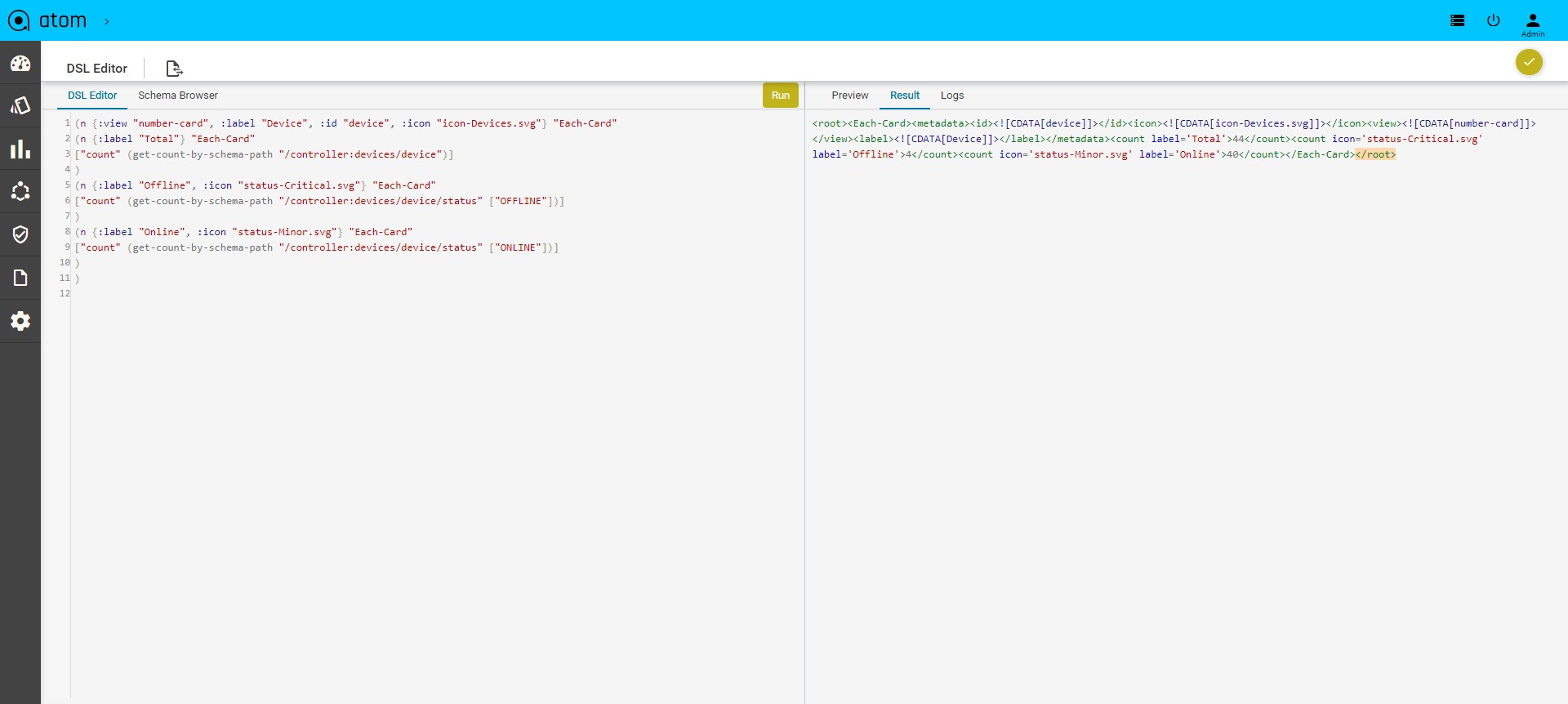
Go to the right pane to view the result.There are three tabs in the right side panel Preview, Result and Logs
-
- Check the Preview of layout (Card,Grid,Pie Grid,Pie Chart) for the DSL in Preview tab.
- XML output of the DSL will be shown in the Result tab
- All errors of the DSL will be listed in the Logs tab in case of any failures.
After the successful execution of a DSL query, you can save and use this as a new Report or incorporate it into Dashboard view. All DSL queries will be saved in Administration > DSL Queries.
Customizing the Dashboard
After the successful execution of DSL query, if you want to incorporate the DSL into Dashboard, browse to Developer Tools > DSL < DSL Queries to view all the queries as shown below:
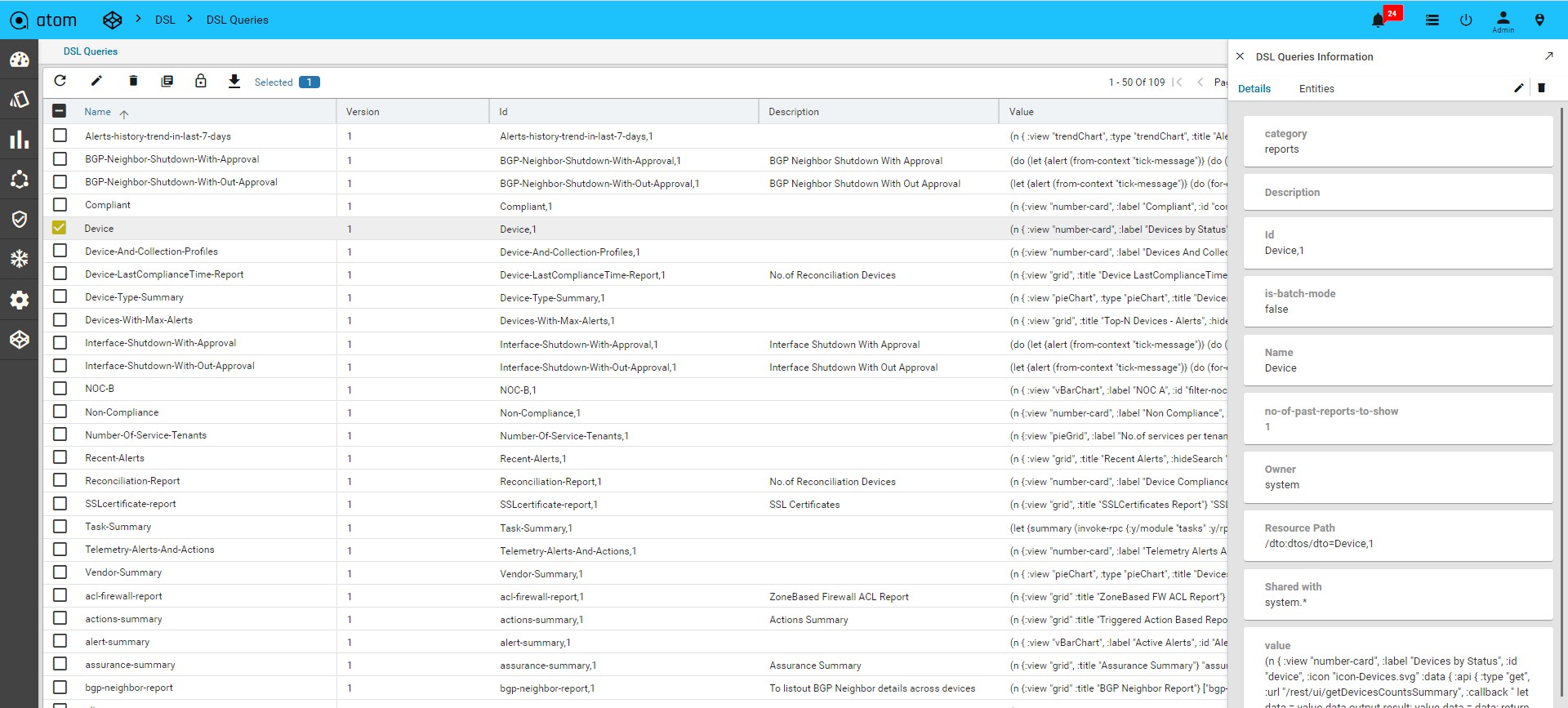
Click on view/download option in dsl query, it can be shown as xml/json/csv/form template.
Include your new DSL and click the Save button on the right side panel of the Editor.
Now you can browse to Dashboard to view the report that has been included (due to the new DSL query that was added) in the Dashboard DSL.
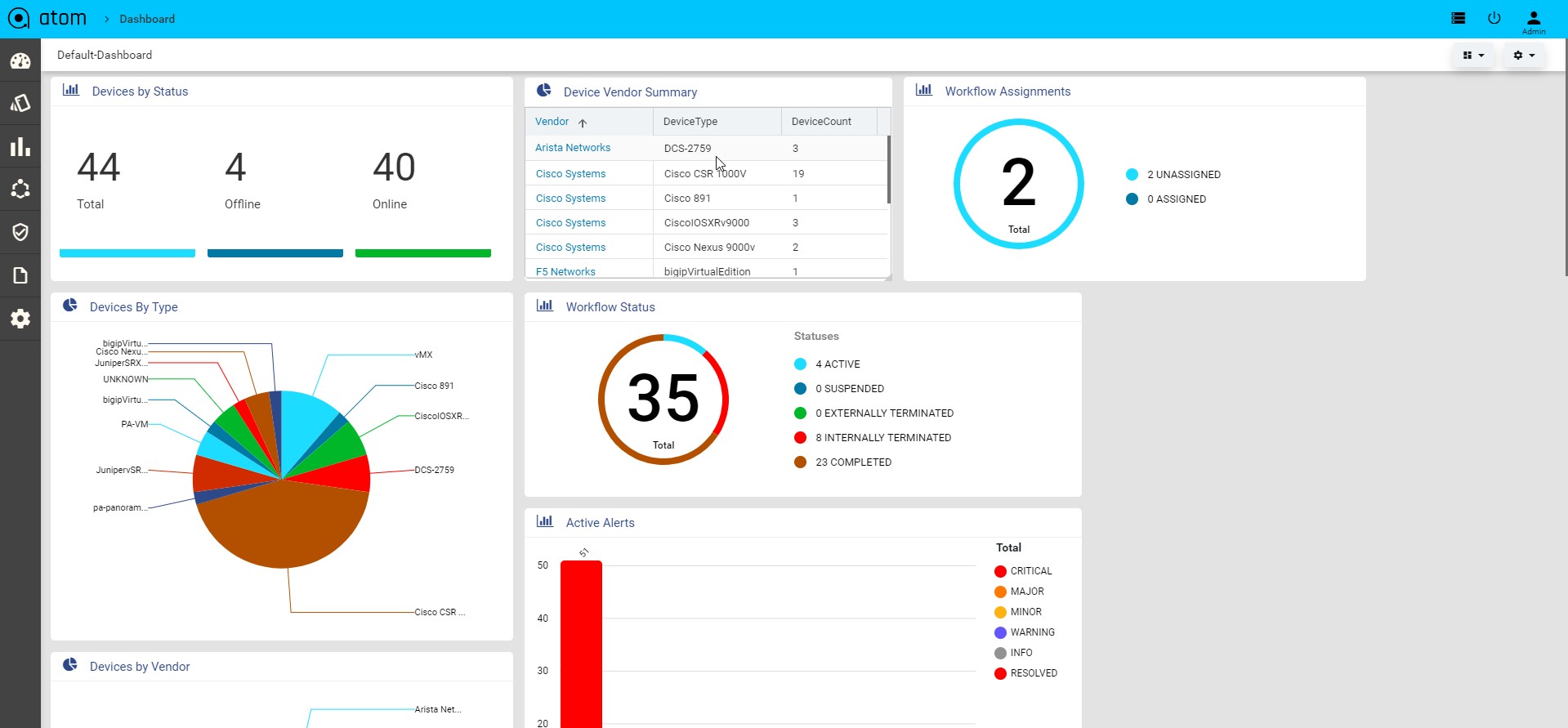
DSL Assignment
The define the dsl assignment is associated with the group and dto is a transfer of the object(to get the navigation menu items after login user).
Navigate > Developer Tools > DSL > DSL Assignment > Add
Tag Management
Navigate > Administration > Tag Management
By creating the tags in global, it should show in create alert rule definition
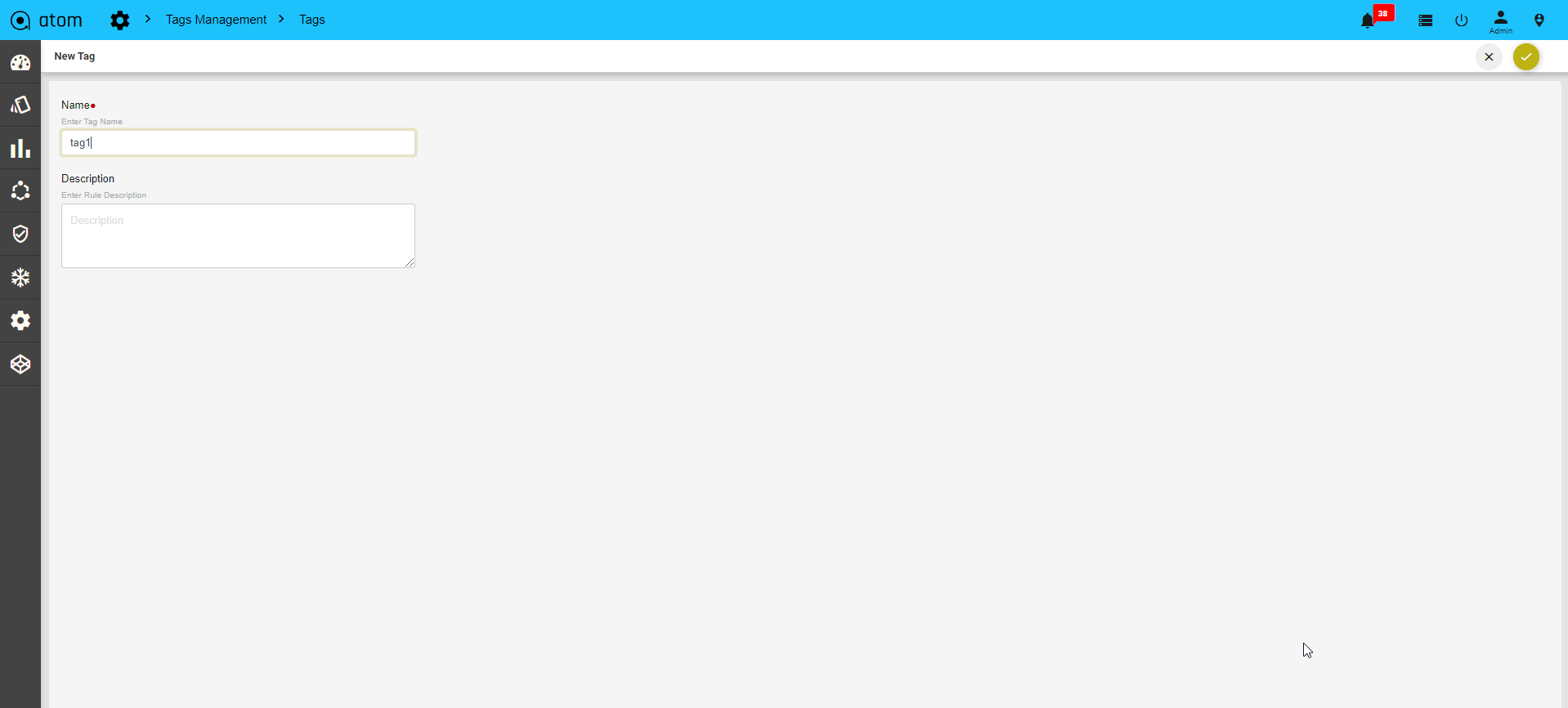
UI Customizations
Customization give control to the user.Customization may involve moving items around an interface to reflect the users’ priorities
- Grid column: Grid columns allows us to select which grid columns can be shown for each entity.Current by default we have one for devices now in grid column.
Navigate > Administration > UI customization > Grid column >Add
- Chart-specs:
A Chart Spec defines the query to be used, variables used in the query and the intended graph type.For example, a chart spec can be written for a TopNUtilizedInterfaces report.The query would use variables for device and the N.
An admin may decide to create two invocations of this chart spec and make them available readily; one for top 5 and one for top 10.Admin can do so by creating 2 chart-invocation payloads and give 25 and 50 for the N value.An end user can run these two different charts out of the box.In addition, end user can tweak the parameter values and explore the graphs.
If a user decides to save the changed chart invocations it is a simple matter of changing the corresponding chart invocation objects.
Navigate > Administration > UI customization > chart -specs >Add
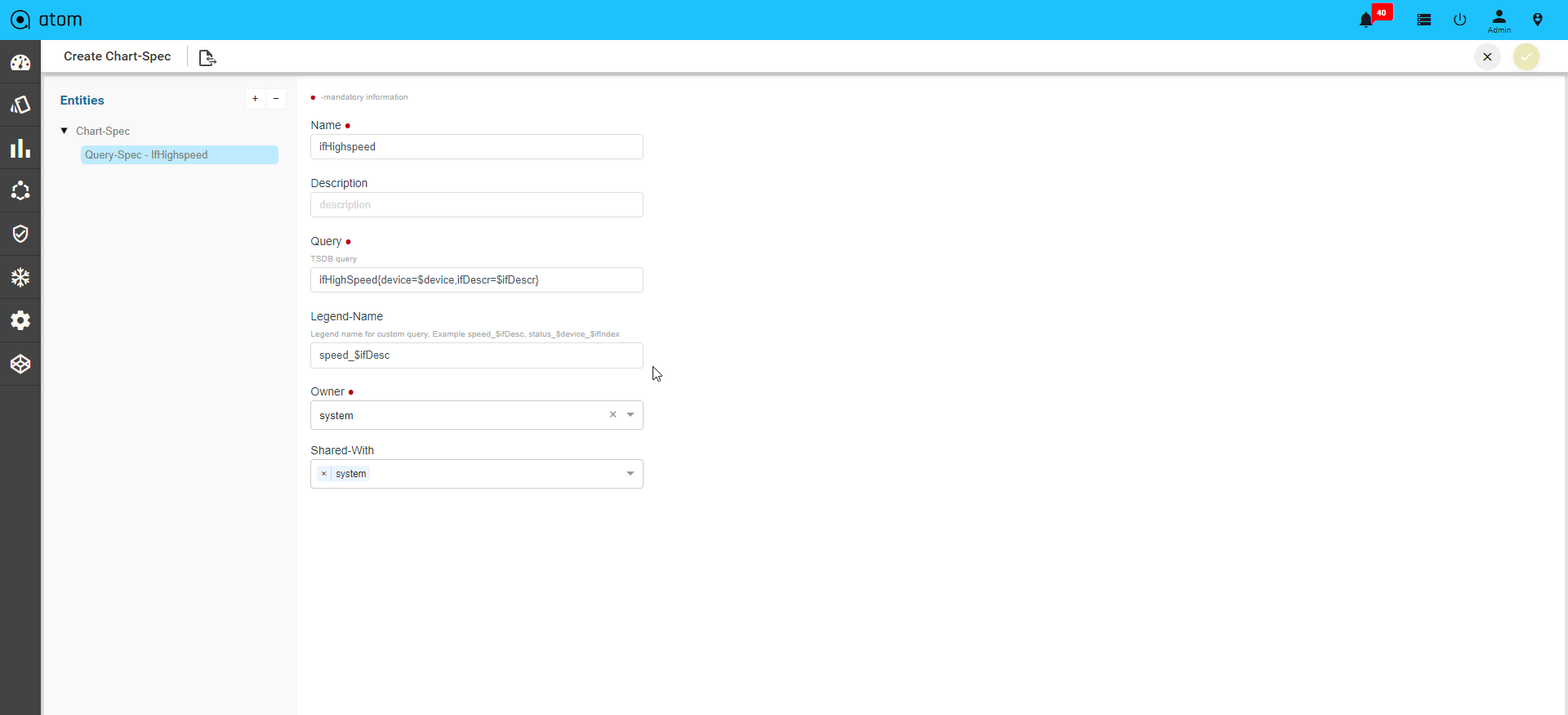
- Chart-Template:
To define the template is a collection of custom charts.create the multiple basic and advanced custom charts can be grouped into one template.it should show the chart graph in monitoring
Navigate > Administration > UI customization > chart -template >Add
- Chart-variables: To define a Variables are useful when the user is writing the queries to build a custom chart.Global variable which can be reusable across multiple charts
Here Two types of variables are Constant and Query,Query type is useful to fetch a list of entities like devices, interfaces etc.and constant is for any static values like bucket interval etc.
Navigate > Administration > UI customization > chart -variables >Add
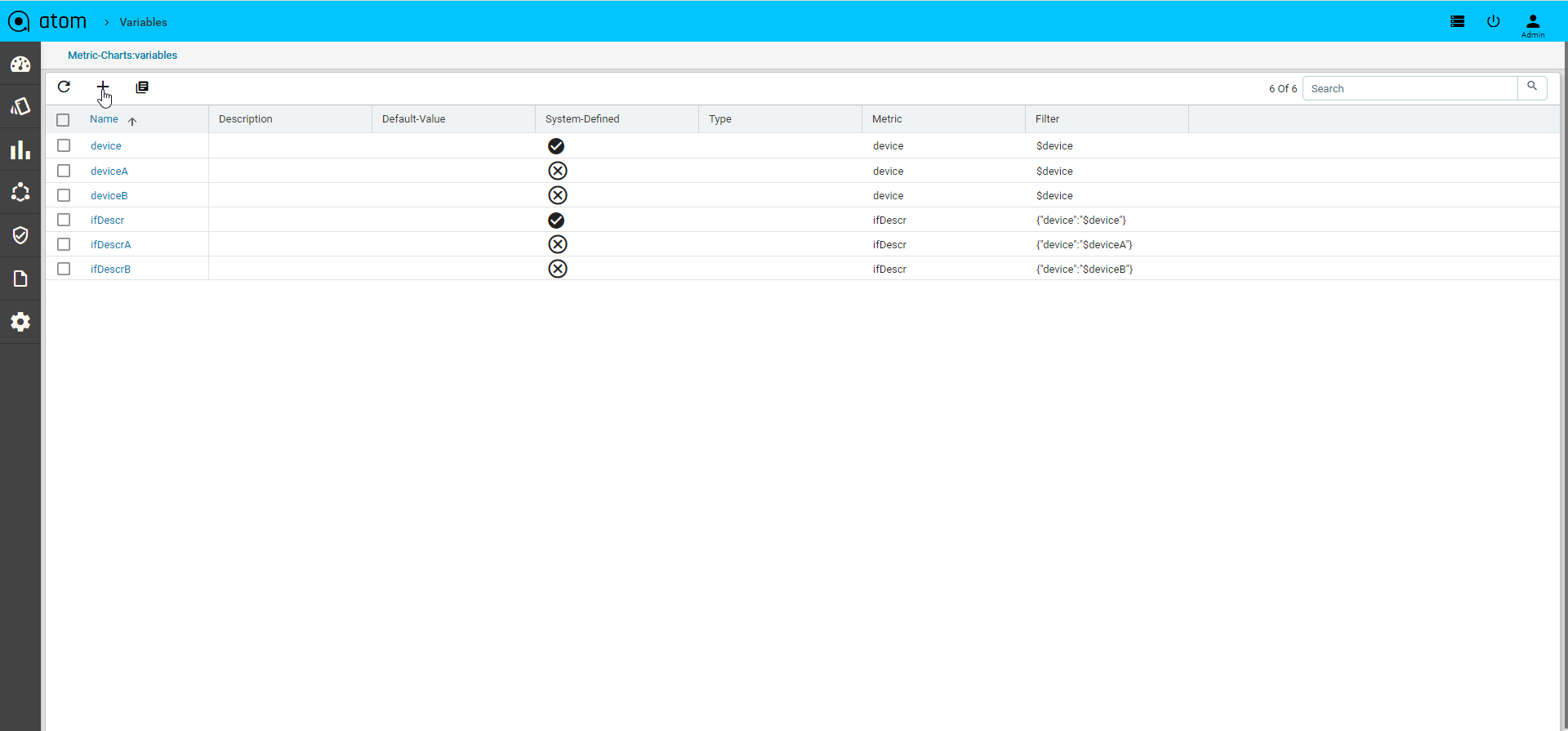
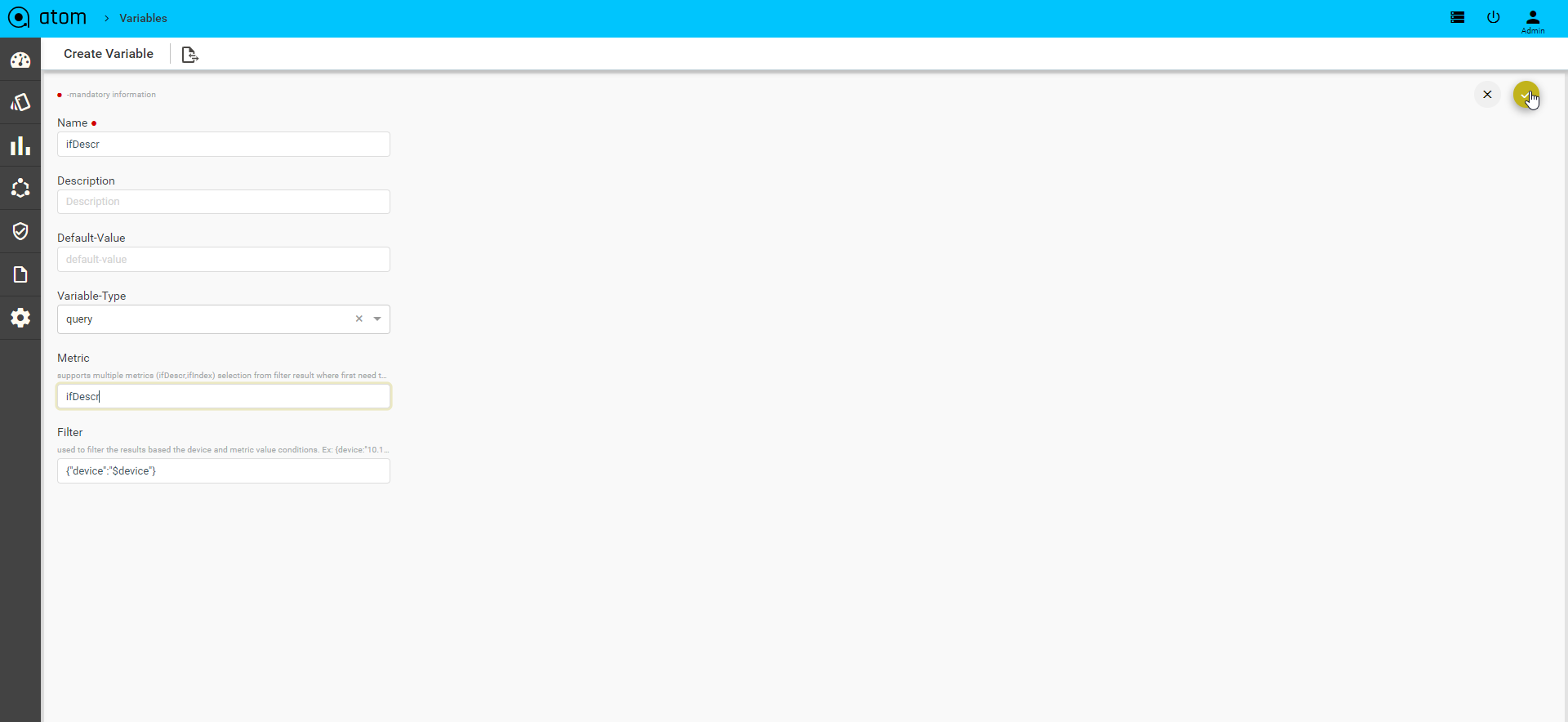
Troubleshoot
From the Troubleshoot tab, the system administrator can perform the following tasks:
-
- “Services & Metrics“
- “Queue Statistics“
- “Device Comm and Inv”
Services & Metrics :
The administrator can view a summary of the health of the server and the associated agents. All the services running on the ATOM server are also displayed here.
- Go to Administration > Troubleshoot > Services and Metrics
- In the left pane, click Servers > Components to view the different categories of the servers running in ATOM.
- Click Servers > System Health in the right pane to view the health of the components of the server.
The health of the associated services is also displayed in the lower pane.
- Click the Servers icon to view the Services in the right pane.
- Select a service that is running and view the Statistics and Events associated with the service in the bottom panel.
Queue Statistics :
ATOM uses a bus to communicate various events between the different ATOM modules or components, thereby providing a view of the activity of the Naas Bus.
-
- Broker Statistics
- Naas Bus Monitor Statistics
Each row represents a particular event that ATOM components publish or subscribe to, thereby help in monitoring the Bus.
Device Comm and Inv
Ping
As an administrator, you can check the reachability of a device from ATOM using Ping Test.
- Navigate to Administration > Troubleshoot > Device Comm & In > Ping Test
- To create a Ping Test, fill the fields described below:
- IP Address: Enter the IP address of a device that needs to be verified for its reachability.
- Packet Count: Enter the number of ICMP Echo request messages to be sent.
- Time Out (sec): Specify a value for the time for which the ping command should wait for each reply.
SNMP
SNMP Tests You can test if SNMP devices are responding correctly to SNMP queries. By default, SNMP v2c is supported.
- Navigate to Administration > Troubleshoot > Device Comm & In > SNMP
- To create an SNMP test, fill the following fields:
-
- Device Name: Enter the name of the device
- SNMP Operation: Choose an appropriate SNMP operation from the drop- down menu:
- GET
- GET NEXT
- GET BULK
- WALK
- SNMP OID: Enter the OID of the SNMP device
Config Parser
This utility helps you check the parsed output of any running configuration of any device. By doing so, you can verify the extent to which ATOM supports the config parsing for a given running configuration. All the parsed configuration can also be visualized in the supported data models in ATOM.
- Navigate to Administration > Troubleshoot > Device Comm & Inv > Config Parse
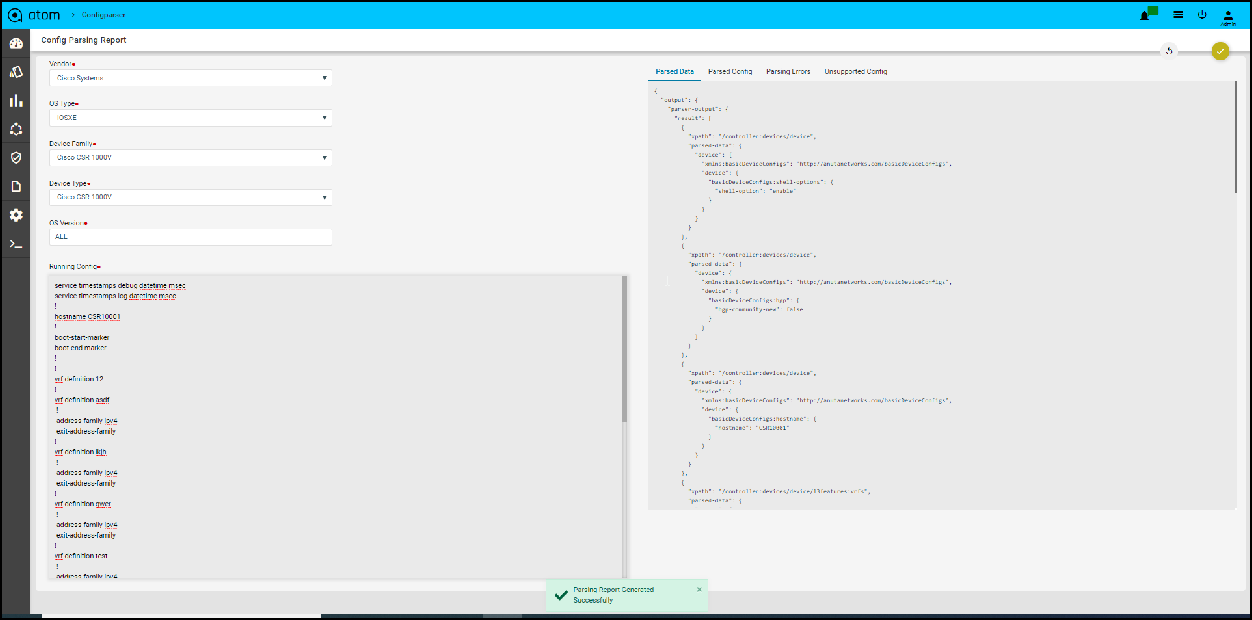
- Select the device family details for which the config parsing support needs to be verified in ATOM:
-
- Vendor: Select the vendor from the supported vendor list in ATOM
- OS Type: Select the OS type for the device vendor for which the config parsing needs to be checked
- Device Family: Select the device family that the device belongs to
- Device Type: Select the type of the device belonging to the selected device family
- OS Version: Select the version of the OS
- In the Running Config pane, paste the running configuration of the device for which config parsing needs to be verified
- Click Submit to generate the Config Parsing Report The results of the Report can be viewed in the right pane as
-
- Parsed Data: The configuration, which is parsed in ATOM, for which the data model is available can be viewed in this tab.
- Parsed Configurations: The running configuration that is parsed into blocks by ATOM can be viewed in this tab.
- Parsing Errors: The parsed configuration derived in ATOM but with errors can be viewed in this tab.
- UnSupported Configurations: The running configuration for which there is no parsing support available in ATOM can be viewed in this tab
File Server
File server helps users to upload and can also down the packages related to the services or any workflow if any user wants to save a package in the repository.
Navigate to Administration > File Server and click on the add button.
Name: Enter a name of the package
Choose File: Upload a package or a file which needs to be saved.
About
Navigate > Administration > About